HTTP 请求走私
是什么?
HTTP请求走私是一种干扰网站处理从一个或多个用户接收的HTTP请求序列的方式的技术。
HTTP请求走私最早是在2005年记录的,最近由PortSwigger对该主题的研究重新流行起来。
通常我们理解的 HTTP 请求是独立的,但是自 HTTP/1.1 以来,已经广泛支持通过单个基础 TCP 或 SSL/TLS 套接字发送多个 HTTP 请求。该协议非常简单:HTTP请求简单地紧挨着放置,服务器解析请求标头以计算出每个请求结束的位置以及下一个请求开始的位置。这通常会与HTTP流水线混淆,HTTP流水线是一种稀有的子类型,对于本文所述的攻击而言并不是必需的。
就其本身而言,这是无害的。但是,现代网站由许多系统链接组成,所有系统都通过HTTP进行通信。这种多层体系结构接收来自多个不同用户的HTTP请求,并通过单个TCP / TLS连接路由它们:
这意味着突然之间,后端与前端就每个消息的结束位置达成一致至关重要。否则,攻击者可能能够发送模糊的消息,该消息被后端解释为两个不同的HTTP请求:
这使攻击者能够在下一个合法用户的请求开始时添加任意内容。在整个本文中,被走私的内容将被称为“前缀”,并以橙色突出显示。
让我们想象一下,前端优先考虑第一个content-length标头,而后端优先考虑第二个content-length标头。从后端的角度来看,TCP流可能类似于:
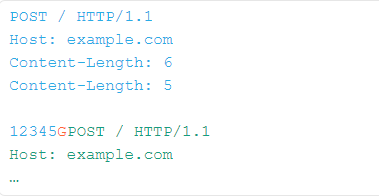
在后台,前端将蓝色和橙色数据转发到后端,后端在发出响应之前仅读取蓝色内容。 这会使后端套接字充满橙色数据。 当合法的绿色请求到达时,它最终会附加到橙色内容上,从而导致意外的响应。
在此示例中,注入的 G 将破坏绿色用户的请求,并且他们很可能会得到 Unknown method GPOST 的响应。
在现实生活中,双重 Content-Length 技术很少起作用,因为许多系统明智地拒绝具有多个 Content-Length 标头的请求。 相反,我们将使用 chunked encoding 来攻击系统-这次我们有了 RFC 2616 规范:
If a message is received with both a Transfer-Encoding header field and a Content-Length header field, the latter MUST be ignored.
由于该规范隐式允许同时使用 Transfer-Encoding:chunked 和Content-Length 来处理请求,因此很少有服务器拒绝此类请求。 每当我们找到一种在链中的一台服务器中隐藏 Transfer-Encoding 标头的方法时,它都会退回到使用 Content-Length 的方式,并且可以使整个系统不同步。
您可能对分块编码不太熟悉,因为 Burp Suite 之类的工具会自动将分块的请/响应缓冲到常规消息中,以便于编辑。在分块消息中,主体由0个或更多块组成。 每个块均由块大小,后跟换行符(\r\n)和块内容组成。消息以大小为0的块终止。下面是使用块编码的简单去同步攻击:
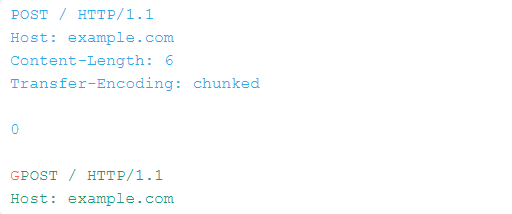
我们没有在这里隐藏任何代码,因此,此漏洞利用将主要在前端根本不支持分块编码的系统上起作用-这种行为在使用内容交付网络(CDN)Akamai的许多网站上都可见。 更新:尽管尚未发布任何公共咨询,但Akamai已经部署了修复程序。
如果是后端不支持分块编码,则需要翻转偏移量:

这项技术在很多系统上都可以使用,但是我们可以通过使 Transfer-Encoding 标头更难发现来利用更多功能,从而使一个系统看不到它。这可以通过使用服务器 HTTP 解析中的差异来实现。以下是一些请求示例,其中只有一些服务器可以识别 Transfer-Encoding:chunked 标头。 在此研究过程中,每种方法均已成功用于至少一个系统:
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Transfer-Encoding:[tab]chunked
GET / HTTP/1.1
Transfer-Encoding: chunked
X: X[\n]Transfer-Encoding: chunked
Transfer-Encoding
: chunked
如果前端服务器和后端服务器都拥有这些怪癖,那么这些怪癖都是无害的,否则就构成了重大威胁。有关更多技术,请查看regilero正在进行的研究。我们将很快使用其他技术来查看实际示例.
怎么发现和利用?
请求走私背后的理论很简单,但是不受控制的变量的数量以及我们对前端背后发生的事件的完全缺乏可见性会导致复杂化。
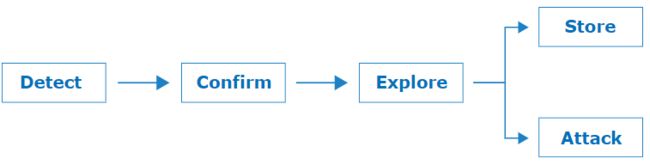
Detect
检测请求走私漏洞的明显方法是发出一个模棱两可的请求,然后发出一个正常的“受害者”请求,然后观察后者是否得到了意外响应。 但是,这极易受到干扰。 如果另一个用户的请求在我们的受害者请求之前命中了中毒的套接字,那么他们将获得损坏的响应,我们将不会发现此漏洞。 这意味着在流量很大的实时站点上,如果不利用过程中的大量真实用户,就很难证明存在请求走私行为。 即使在没有其他流量的站点上,您也会冒由终止连接的应用程序级怪癖引起的误报的风险。
为了解决这个问题,作者开发了一种检测策略,该策略使用一系列消息使脆弱的后端系统挂起并超时连接。 该技术几乎没有误报,可以抵制可能导致误报的应用程序级怪癖,而且最重要的是几乎没有影响其他用户的风险。
假设前端服务器使用 Content-Length 标头,而后端使用 Transfer-Encoding 标头。这种定位简称为 CL.TE。 我们可以通过发送以下请求来检测潜在的请求走私:

由于较短的 Content-Length ,前端将仅转发蓝色文本,而后端将在等待下一个块大小时超时。这将导致明显的时间延迟。
如果两个服务器都处于同步状态(TE.TE 或 CL.CL),则该请求将被前端拒绝,或者被两个系统无害处理。 最后,如果以相反的方式发生同步(TE.CL),则由于无效的块大小'Q',前端将拒绝该消息而无需将其转发到后端。 这样可以防止后端套接字中毒。
我们可以使用以下请求安全地检测 TE.CL 取消同步:
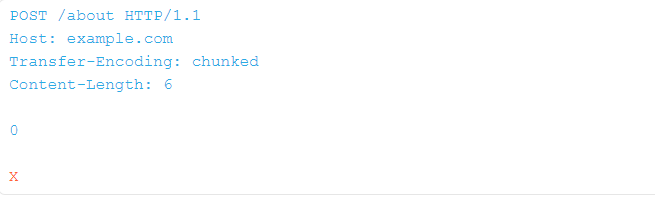
多亏了终止的 0 块,前端只能转发蓝色文本,而后端将超时,等待 X 到达。
如果反同步发生在其他方向(CL.TE),则此方法将使X毒化后端套接字,从而可能损害合法用户。 幸运的是,通过始终先运行先前的检测方法,我们可以排除这种可能性。
这些请求可以调整为针对标头解析中的任意差异,并通过HTTP Request Smuggler(用于帮助应对此类攻击的开源Burp Suite扩展)自动识别请求走私漏洞。 现在,它们还用于Burp Suite的核心扫描仪中。 尽管这是服务器级别的漏洞,但是单个域上的不同终结点经常被路由到不同的目的地,因此,该技术应单独应用于每个终结点。
Confirm
在这一点上,您已经竭尽所能,而不会对其他用户产生副作用。但是,许多客户不愿意在没有进一步证据的情况下认真对待报告,所以这就是我们要得到的。展示请求走私的全部潜力的下一步是证明后端套接字中毒是可能的。为此,我们将发出一个旨在毒化后端套接字的请求,然后发出一个希望成为毒害受害者的请求,从而明显改变响应。
如果第一个请求导致错误,则后端服务器可以决定关闭连接,丢弃中毒的缓冲区并破坏攻击。通过针对旨在接受POST请求的端点并保留任何预期的GET/POST参数来尝试避免这种情况。
一些站点具有多个不同的后端系统,前端会查看每个请求的方法,URL和标头,以确定将其路由到何处。如果将受害者请求路由到与攻击请求不同的后端,则攻击将失败。因此,“攻击”和“受害者”请求最初应尽可能相似。
如果目标请求如下所示:

然后,尝试 CL.TE 套接字中毒的样子如下:

如果攻击成功,则受害者请求(绿色)将得到404响应。
TE.CL 攻击看起来很相似,但是需要一个封闭块,这意味着我们需要自己指定所有标头并将受害人请求放置在正文中。 确保前缀中的 Content-Length 略大于主体:

如果该站点处于活动状态,则另一个用户的请求可能会在您之前打中毒的套接字,这将使您的攻击失败并可能使该用户不高兴。 结果,此过程通常需要几次尝试,而在人流量大的站点上可能需要数千次尝试。 请保持谨慎和克制,并在可能的情况下定位登台服务器。
Explore
现在我们已经确定套接字中毒是可能的,下一步是收集信息,以便我们可以进行有根据的攻击。
前端通常会附加和重写HTTP请求标头(例如 X-Forwarded-Host 和X-Forwarded-For),以及许多自定义名称,这些名称通常很难猜测。 我们的走私请求可能缺少这些标头,这可能导致意外的应用程序行为和失败的攻击。
幸运的是,有一个简单的策略可以使我们部分拉开帷幕,并获得对这些隐藏标题的可见性。 这使我们可以通过手动添加标头来恢复功能,甚至可以发起进一步的攻击。
只需在目标应用程序上找到一个反映POST参数的页面,对参数进行混洗,使所反射的参数位于最后,然后稍微增加Content-Length,然后走私产生的请求:
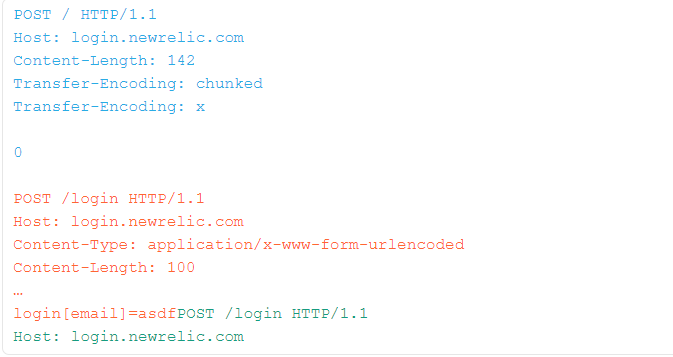
绿色请求将在登录到login [email]参数之前由前端重写,因此当它反射回去时,它将泄漏所有内部标头:
Please ensure that your email and password are correct.
Exploit
当可以使用内部API时,将其直接分解是一件很不错的事情,但是这并不是我们唯一的选择。 我们还可以对浏览目标网站的每个人发起多种攻击。
为了确定我们可以对其他用户应用的攻击,我们需要了解我们可以中毒哪种类型的请求。 从“确认”阶段重复进行套接字中毒测试,但是要反复调整“受害者”请求,直到它类似于典型的GET请求为止。 您可能会发现只能使用某些方法,路径或标头中毒请求。 另外,请尝试从其他IP地址发出受害者请求-在极少数情况下,您可能会发现只能中毒来自同一IP的请求。
最后,检查网站是否使用网络缓存; 这些可以帮助绕过许多限制,增强我们对资源中毒的控制,并最终使请求走私漏洞的严重性成倍增加。
如何判断是否有CDN?
使用 dig 或 nslookup 命令查看域名,看是否返回多个ip,或 cname 里有cdn。
使用 多地 ping ,看是否返回多个 ip。
Store
如果应用程序支持编辑或存储任何类型的文本数据,则利用将非常容易。 通过在受害者的请求之前加上精心设计的存储请求,我们可以使应用程序保存他们的请求并将其显示给我们-然后窃取任何身份验证Cookie/Header。
使用此技术的唯一主要“陷阱”是,您将丢失在“&”之后出现的所有数据,这使得很难从表单编码的POST请求中窃取主体。 我花了一段时间尝试通过使用替代请求编码来解决此限制,并最终放弃了,但是我仍然怀疑这是有可能的。
Attack
能够将任意前缀应用于其他人的响应也为攻击提供了另一条途径:触发有害响应。
使用有害响应的主要方法有两种。 最简单的方法是发出“攻击”请求,然后等待其他人的请求击中后端套接字并触发有害响应。 一个更棘手但更强大的方法是自己发出“攻击”和“受害者”请求,并希望通过Web缓存保存对受害者请求的有害响应,并将其提供给其他任何使用相同URL的人-Web 缓存中毒。
Upgrading XSS
Grasping the DOM
CDN Chaining
'Harmless' responses
由于走私请求使我们能够影响对任意请求的响应,因此一些通常无害的行为变得可以利用。例如,即使是谦虚的开放重定向,也可以通过将原网站导入的JavaScript重定向到恶意域来破坏帐户。
使用307代码的重定向特别有用,因为在发出POST请求后收到307的浏览器会将POST重新发送到新的目的地。这可能意味着您可以使不知情的受害者将他们的纯文本密码直接发送到您的网站。
经典的开放式重定向本身很常见,但是有一个变体在整个Web上很普遍,因为它源于Apache和IIS中的默认行为。人们通常认为它是无害的,并且几乎每个人都忽略了它,因为没有像请求走私这样的伴随漏洞,它的确是没有用的。如果您尝试访问不带斜杠的文件夹,则服务器将使用主机头中的主机名通过重定向响应来追加斜杠:
一些比较好的中文文章
https://xz.aliyun.com/t/6878
https://paper.seebug.org/1048/#5
一些现实世界的例子
https://hackerone.com/reports/498052
参考链接:
https://portswigger.net/web-security/request-smuggling
https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn