计算与软件工程作业四
代码规范复审(附截图)
1.作业链接:https://www.cnblogs.com/sunsijiao/p/12461182.html

2.作业链接:https://www.cnblogs.com/cdinzz/p/12459432.html

3.作业链接:https://www.cnblogs.com/liziye/p/12443639.html

4.作业链接:https://www.cnblogs.com/li-lingling/p/12372967.html

5.作业链接:https://www.cnblogs.com/li-lingling/p/12455057.html
6.作业链接:https://www.cnblogs.com/liziye/p/12372753.html

7.作业链接:https://www.cnblogs.com/wanghuiru/p/12460279.html

8.作业链接:https://www.cnblogs.com/wanghuiru/p/12397287.html

整体看法
很多代码没有进行注释,所以这就降低了代码的可读性,在之前的作业中,我也犯过这样的错误。另外,同学们的作业比之前更规范了。细节之处处理的很好。但是还有一些作业没有满足要求,例如没有进行单元测试。而代码复审恰巧给了我们这样一个机会,通过别人发现自己的错误与不足,也通过别人提高自己。
结对编程
| 作业要求 | https://edu.cnblogs.com/campus/jssf/infor_computation17-31/homework/10534 |
|---|---|
| 课程目标 | 体验开发中的两人合作,提高个人编程技巧,增加合作经验 |
| 参考文献 | https://www.cnblogs.com/wendy980514/p/12609399.html?from=groupmessage https://blog.csdn.net/huilan_same/article/details/52944782 |
| 此作业在哪个具体方面帮我实现目标 | 从别人身上学习合作的经验和编程技巧 |
| 作业正文 | https://i-beta.cnblogs.com/posts/edit;postId=12611135 |
要求:两人自由组队进行结对编程
1.实现一个简单而完整的软件工具(中文文本文件人物统计程序):针对小说《红楼梦》要求能分析得出各个人物在每一个章回中各自出现的次数,将这些统计结果能写入到一个csv格式的文件。
2.进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
3.进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
4.使用源代码管理系统 (GitHub, Gitee, Coding.net, 等);
5.针对上述形成的软件程序,对于新的文本小说《水浒传》分析各个章节人物出现次数,来考察代码。
·将上述程序开发结对编程过程记录到新的博客中,尤其是需要通过各种形式展现结对编程过程,并将程序获得的《红楼梦》与《水浒传》各个章节人物出现次数与全本人物出现总次数,通过柱状图、饼图、表格等形式展现。
·《红楼梦》与《水浒传》的文本小说将会发到群里。
注意,要求能够分章节自动获得人物出现次数
程序代码
print("红楼梦人物出场次数:")
import jieba #jieba库的应用
excludes = {"什么","一个","我们","那里","你们","如今","说道","知道","起来","姑娘","这里","出来","他们","众人","自己",
"一面","只见","怎么","两个","没有","不是","不知","这个","听见","这样","进来","咱们","告诉","就是","东西",
"袭人","回来","大家","只是","只得","不敢","这些"
}
#列出需要删除的干扰词汇,在多次运行中不断添加来修正
txt = open("D:\红楼梦.txt","r",encoding='utf-8').read()
# 打开txt文件,格式是utf-8
words = jieba.lcut(txt)
#利用jieba库将红楼梦的所有语句分成词汇
counts = {}
#创建的一个空的字典
for word in words:
if len(word) == 1: #删去长度为1的词
continue
elif word == "老太太":
rword = "贾母"
elif word == "太太":
rword = "王夫人"
else:
rword = word
counts[word] = counts.get(word,0) + 1
#如果字典中没有这个名字则创建,如果有就计数加一
for word in excludes:
del counts[word]
#删除干扰词
items = list(counts.items())
#把保存[姓名:个数]的字典转换成列表
items.sort(key=lambda x:x[1],reverse = True)
#对上述列表进行排序,'True'是降序排列
for i in range(10):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
#输出前十个结果
此代码来源于网上。
测试代码
import unittest
from red2 import *
class MyTestCase(unittest.TestCase):
def setUp(self):
print("测试开始")
def test_something(self):
txt_path = 'redstone.txt'
items = list()
for i in range(12):
items.append([name_list[i], name_list_count[i]])
self.assertEqual(items, NameCount().getNameTimesSort(name_list,txt_path))
def tearDown(self):
print("测试结束")
if __name__ == '__main__':
unittest.main()
人物统计
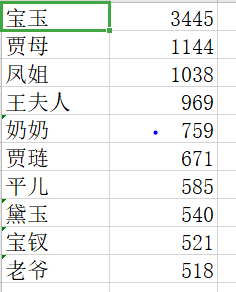

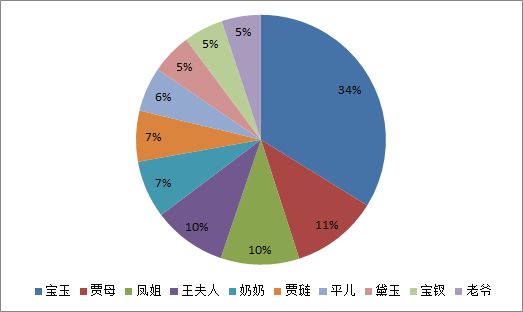

运行截图
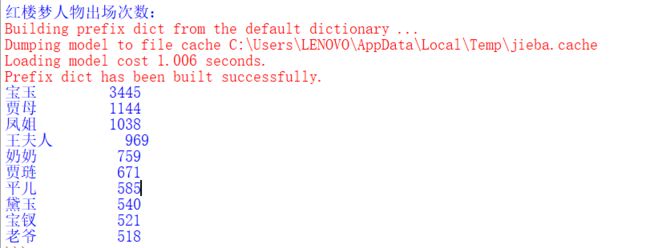
出现的问题

通过不断查阅资料发现,出现这种情况可能是因为没有安装jieba库

查阅资料后安装jieba成功
总结
通过大量查阅资料发现使用python语言最为方便,但是之前并未学过这个语言以及它的使用方法,所以我先安装了Windows x86-64 executable installer,了解使用方法(https://zhinan.sogou.com/guide/detail/?id=316513561610),但是安装后,IDLE并不能正常使用,出现无法连接子库的情况,查阅资料发现是因为没有关闭防火墙,之后李同学查阅大量资料正确安装了python软件。通过远程控制我的电脑进行代码的完善和进行单元测试。
水浒传同理。
目前对于python这门语言和软件的具体使用方法认识尚浅,运用的并不熟练。
但是python语言也有自身的优势,相对易学,Python标准库很庞大,python有可定义的第三方库可以使用。它可以帮助你处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。“功能齐全”。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
码云链接:https://gitee.com/if_evening/hlm