Group Replication
[TOC]
关于 Group Greplication
- 异步复制
- 半同步复制
- Group Replication
Group Replication 是组复制,不是同步复制,但最终是同步的,更确切地说,事务以相同顺序传递给所有组成员,但它们执行并不同步,接受事务被提交之后,每个成员以自己的速度提交。
异步复制
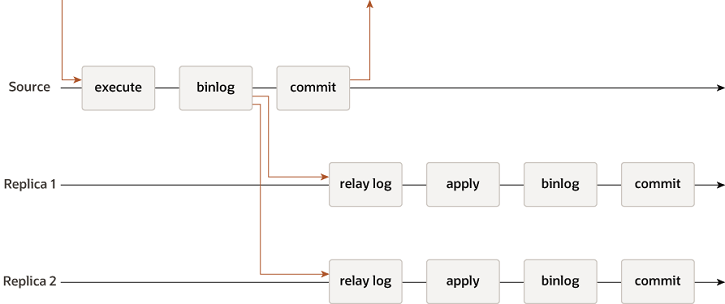
半同步复制
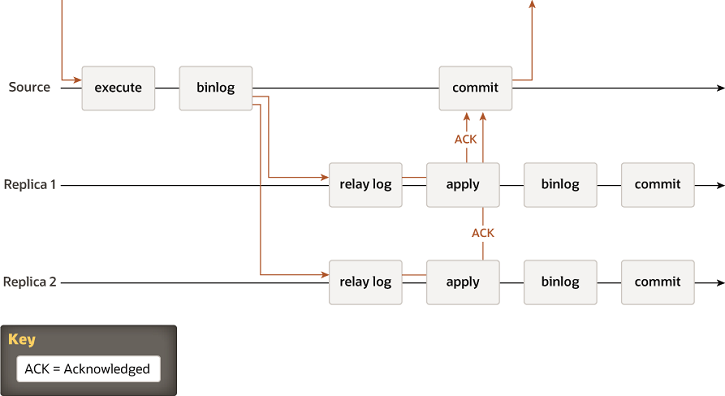
Group Replication
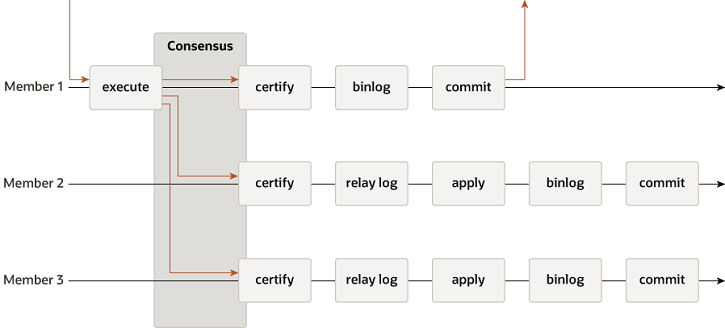
此图没有包含 Paxos 消息等信息
Group Replication 要求
- InnoDB
- Primary Key
- IPv4,不支持 IPv6
- Network Performance
- log_bin = binlog
- log_slave_update = ON
- binlog_format = ROW
- GTID
- master_info_repository = TABLE、relay_log_info_repository = TABLE
- transaction_write_set_extraction = XXHASH64
- Multi-threaded Appliers (slave_parallel_type、slave_parallel_workers、slave_preserve_commit_order)
- 当前环境要存在 root@localhost 用户,INSTALL PLUGIN 时要使用 root@localhost 创建和检查 _gr_user@localhost
Group Replication 限制
- binlog_checksum = NONE
- Gap Locks : 认证过程(The certification process)不考虑 Gap locks,因为Gap locks信息在InnoDB外不可用,详细参考 Gap Locks
- 除非应用程序依赖 REPEATABLE READ,否则建议 READ COMMITTED,因为 InnoDB 在 READ COMMITTED 没有 Gap locks,InnoDB本身冲突检测和Group Replication 分布式冲突检测协同工作
- Table Locks and Named Locks : 认证过程(The certification process)不考虑表锁 [ Section 13.3.5, “LOCK TABLES and UNLOCK TABLES Syntax 和命名锁 GET_LOCK()
-
Savepoints Not Supported(5.7.19 已经支持) - SERIALIZABLE Isolation Level 多主模式不支持
- Concurrent DDL versus DML Operations(并发DDL与DML操作) : 多主模式下,同一对象在不同成员并发执行DDL和DML语句,可能造成脑裂数据不一致
- 级联约束外键 多主模式不支持,外键约束可能导致多主模式组成的级联操作造成检测不到的冲突,导致组内成员数据不一致。单主模式不受影响。
group_replication_enforce_update_everywhere_checks=ON
- Very Large Transactions : 产生足够大的GTID内容的个别事务可能导致组通信中的故障,该GTID内容足够大,无法通过网络在组合成员之间复制5秒钟以内。为避免此问题,尽可能多地尝试限制交易的大小。例如,将使用LOAD DATA INFILE的文件拆分成更小的块。
常见问题
-
一个 MySQL Group Replication 最大成员数是多少?
9个
-
MySQL Group Replication 组内成员怎么通信?
通过 P2P TCP 连接,参数 group_replication_local_address 设置,IP要求所有成员可访问,仅用于组内成员内部通信和消息传递
-
group_replication_bootstrap_group 参数有什么用?
MySQL Gropu Replication 创建组并做为初始化种子,第二个加入的成员需要向引导成员请求动态更改配置,以便加入到组中。
二种情况下使用:
- 创建初始化 Group Replication时
- 关闭并重新启动整个组时
-
如果配置恢复过程?
可以通过 CHANGE MASTER TO 语句预配置组恢复通道
-
可以通过组复制横向扩展写负载?
可以通过组内不同成员之间传播无冲突的事务来横向扩展写。
-
相同工作负载,对比简单复制,需要更多的CPU和宽带?
组内各个成员要不断交互,成员数更多对成员数少要求更多的宽带(9>3),为了保证组内同步和消息传递,会占用更多CPU和内存
-
可以跨广域网部署吗?
可以,但是每个成员之间网络必须可靠,为了高性能需要低延时、高宽带,如网络丢包导致重传和更高端到端延时,吞吐量和延时都会受影响
在延时大、带宽窄的网络环境,提高 Paxos对网络适应,做了压缩和多个本地事务封装一个数据包的优化 Section 17.9.7.2, “Message Compression”
当组内成员通信往返时间 (RTT) 为2秒或更长时,可能会遇到问题,因为内置故障检测机制可能会错误的触发
-
当出现临时连接问题时,成员能自动重新加入组吗?
取决连接问题:
- 连接问题暂时的,恢复足够快,故障检测还没检测到就进行了重新连接,则不会移除
- 如果长时间连接问题,故障检测器最终检测到问题,该成员被移除,当恢复后,需要手工加入(或脚本自动加入)
-
什么时候从组内移除成员?
当某个成员无响应时(崩溃或网络问题),系统会检测到故障,其他成员把它从组配置中移除,创建一个不包含该成员的新配置
当一个成员明显的延时怎么处理?
当一个成员明显延时,没有定义何时从组中自动移除成员的策略,要找到延时原因并修复它或从组中删除该成员,否则触发"流量控制",那么整个组的也将变慢。(流量控制可配置)
-
在怀疑组中存在问题时,组中是否有某个特定成员负责触发重新配置组?
没有。
任何成员都可以怀疑组中存在问题,所有成员需要(自动)对"某个成员故障"达成一致的意见,有一个成员负责触发重新配置,从组中将故障成员移除,具体哪个成员不可配置。
Can I use Group Replication for sharding?
How do I use Group Replication with SELinux?
How do I use Group Replication with iptables?
How do I recover the relay log for a replication channel used by a group member?
单独的通信机制
GR 使用 Slave 的通道,只是使用通过执行线程(Applier Thread)来执行 Binlog Event,并没有使用通道传输 Binlog Event。
没有使用异步复制的 Binlog Event,也没有使用 MySQL 服务端口通信,而是创建一个独立 TCP 端口通信,各个 MySQL 服务器睥 Group Replication 插件通过这个端口连接在一起,两两通信
Binlog Event 多线程执行
GR 插件自动创建一个通道 group_replication_applier (channel) 来执行接收到的 Binlog Event,当加入组时,GR 插件自动启动 group_replication_applier 通道的执行线程(Applier Thread)
-- 手工调整这个通道执行线程
START SLAVE SQL_THREAD FOR CHANNEL 'group_replication_applier';
STOP SLAVE SQL_THREAD FOR CHANNEL 'group_replication_applier';
基于主键的并行执行
SET GLOBAL slave_parallel_type = 'LOGICAL_CLOCK';
SET GLOBAL slave_parallel_workers = N;
SET GLOBAL slave_preserve_commit_order = ON;
GR 的 LOGCAL_CLOCK 与异步复制的算法不同,GR 并发策略的逻辑时间是基于主键计算出来的,比异步复制基于锁计算出来的逻辑时间的并发性要好很多
基于主键并行复制特点
- 若两个事务更新同一行,则要按顺序执行,否则就可以并发
- DDL 不能和任务事务并发,必须等待它前面所有事务执行完才能开始执行,后面的事务也要必须等等 DDL 执行完才能执行
为什么配置 slave_preserve_commit_order
并发执行时,不管两个事务 Binlog Event 是不是同一 session 产生,只要满足上面的特点就会并发,因此同一 session 里的事务可能被安排并发执行,会导致后执行的事务先被提交的情况,为了保证同一个 session 的事务按照顺序提交,必须配置此参数,保证 Applier 上执行事务的提交顺序和 源 MySQL 一致
Paxos 协议优点
- 不会脑裂 [有疑问,原主从环境有脑裂 P363] ???
- 冗余好,保证 Binlog 至少被复制超过一半成员,只要同时宕机成员不超过一半不会导致数据丢失
- 保证只要 Binlog Event 没有被传输到半数以上成员,本地成员不会将事务的 Binlog Event 写入 Binlog 文件和提交事务,从而保证宕机的服务器不会有组内在线不存在的数据,宕机的服务器重启后,不再需要特殊处理就可以加入组
服务模式
- 单主模式 (默认模式)
- 多主模式
-- 设置多主模式
SET GLOBAL group_replication_single_primary_mode = OFF;
如果使用多主模式,需要加入组之前将此变量置为 OFF,服务模式不能在线切换,必须组内所有成员退出组,然后重新初始化要使用的模式,再把其他成员加进来
单主模式
- Primary Member
- Secondary Member
自动选举 && Failover
- 初始化的成员自动选举为 Primary Member
- Failover:group_replication_member_weight (5.7.20 更新)单主模式权重,先判断权重大的为新 Primary,若一样大,对所有在线成员的 UUID 排序,选最小的为 Primary Member,复制正常进行,但要注意,客户端获取 Primary Memory 的 UUID,然后连接新的 Primary Memory
# 任何成员查询 Primary Member 的 UUID
show global status like 'group_replication_primary_member';
or
SELECT * FROM performance_schema.global_status WHERE variable_name = 'group_replication_primary_member';
读写自动切换
成员加入默认为 "只读" 模式,只有选取为 Primary Member 才会是 "写" 模式
SET GLOBAL super_read_only = 1;
SET GLOBAL super_read_only = 0;
缺点
- Failover 后,客户端根据 UUID 判断是不是 Primary Member
多主模式
自增字段
-- 原 MySQL 自增变量
SET GLOBAL auto_increment_offset = N;
SET GLOBAL auto_increment_increment = N;
# Group Replicaion 组复制自增步长,默认为 7,最大节点为 9
SET GLOBAL group_replication_auto_increment_increment = N;
注意:
a. 如果 server-id 为 1、2、3 配置,就不需要额外配置,但若 server-id不为 1、2、3 则需要配置 auto_increment_increment、auto_increment_offset若没有配置 auto_increment_increment、auto_increment_offset,则自动将 group_replication_auto_increment_increment 和 server-id 设置到 auto_increment_increment、auto_increment_offset 上
b. auto_increment_increment 尽量设置大于或等于成员数,最好大于,因为方便以后增加节点,扩展时再改变自增比较麻烦
优点
- 当一个成员故障,只有一部分连接失效,应用影响小
- 当关闭一个 MySQL 节点时,可以先将连接平滑转移到其他机器上再关闭这个节点,不会瞬断
- 性能好 [有待评估] ???
缺点
- 自增步长要大于成员数,防止以后扩展麻烦
- 不支持串行(SERIALIZABLE) 隔离等级,单节点通过锁实现
- 不支持外键级联操作
# 当为 True,当发现上面 2 个不支持就会报错,单主模式下为必须为 OFF
group_replication_enforce_update_everywhere_checks = TRUE
- DDL 语句并发执行的问题
多主复制,通过冲突检测来辨别冲突事务,再回滚,5.7 的 DDL 不是原子操作无法回滚,因此 GR 没到 DDL 做冲突检测,如果 DDL 和有冲突的语句发生在不同成员,可能导致数据不一致.
所以必须执行 DDL 前必须将有冲突的事务迁移到一台机器上执行
- DBA 维护时要注意防止脑裂 ???
当维护节点 s3时,从DNS下线s3,但在执行 stop group_replication时,因为DNS缓存,要注意应用长链接或短链接是否继续连接此实例。(普通用户不受影响,注意用户权限)
# super 用户查看 read_only 并 stop group_replication,super_read_only 由 ON -> OFF,read_only 一直是 ON
localhost.(none)>show variables like '%read_only%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_read_only | OFF |
| read_only | ON |
| super_read_only | ON |
| tx_read_only | OFF |
+------------------+-------+
4 rows in set (0.00 sec)
localhost.(none)>stop group_replication;
Query OK, 0 rows affected (8.15 sec)
localhost.(none)>show variables like '%read_only%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_read_only | OFF |
| read_only | ON |
| super_read_only | OFF |
| tx_read_only | OFF |
+------------------+-------+
4 rows in set (0.00 sec)
# 普通用户登陆测试
mysql -utest_user -ptest_user -hlocalhost -S /tmp/mysql6666.sock test
mysql> insert into t_n values(1,'test1');
ERROR 1290 (HY000): The MySQL server is running with the --read-only option so it cannot execute this statement
# Super 用户测试
mysqlha_login.sh 6666
localhost.(none)>use test;
Database changed
localhost.test>insert into t_n values(1,'test1');
Query OK, 1 row affected (0.00 sec)
# 怎么加入 Group Replication,可参考(组成员事务不一致)
多主模式思考
写请求可以分发多个成员上
控制 DDL,当有 DDL 执行时,所有写请求转移到同一台 MySQL 机器 [这个实现有点复杂]
-
折中方案,多主模式当单主模式使用
- 与单主模式比较,去掉 Failover 主从切换
- 解决 DDL 冲突问题,防止脑裂
- 一套 GR 为多应用提供服务,多应用不同的数据,没有冲突
-- Session 1: A Member
BEGIN
INSERT INTO t1 VALUES(1);
-- Session 2: B Member
TRUNCATE t1;
-- Session 1:
COMMIT;
----> 2 个 session 事务执行顺序不同
-- SESSION 1:
INSERT INTO t1 VALUES(1);
TRUNCATE t1;
-- SESSION 2:
TRUNCATE t1;
INSERT INTO t1 VALUES(1);
配置 Group Replication
必要配置
复制用户
SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%' IDENTIFIED BY 'rpl_pass';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;
每个节点都要单独配置,如果 MySQL 初始化已经创建,则可以省略此步
连接到哪个成员上去复制,是由 Group Replication插件随机选择,因为为 group_replication_reocvery 配置的用户每个成员上都要存在
如果没有 SET SQL_LOG_BIN = 0,认为有非组内事务,START GROUP_REPLICATION; 失败,需要 set global group_replication_allow_local_disjoint_gtids_join=ON;
my.cnf 配置
# my.cnf
server_id = 1
log_bin = binlog
relay_log = relay-log
gtid_mode = ON
enforce_gtid_consistency = ON
binlog_format = ROW
transaction-isolation = READ-COMMITTED
binlog_checksum = NONE
master_info_repository = TABLE
relay_log_info_repository = TABLE
log_slave_update = ON
slave_parallel_type = LOGIAL_CLOCK
slave_parallel_workers = 8
slave_preserve_commit_order = ON
# Group Replication
plugin-load = group_replication.so
transaction_write_set_extraction = XXHASH64
loose-group_replication_group_name = 93f19c6c-6447-11e7-9323-cb37b2d517f3
loose-group_replication_start_on_boot = OFF
loose-group_replication_local_address = 'db1:3306'
loose-group_replication_group_seeds = 'db2:3306,db3:3306'
group_replication_ip_whitelist = '10.0.0.0/8'
loose-group_replication_bootstrap_group = OFF
# loose-group_replication_single_primary_mode = OFF # Trun off Single primary
# loose-group_replication_enforce_update_everywhere_checks = ON # Multi-Primary Mode (静态)
loose-group_replication_transaction_size_limit = 52428800 # 5.7.19 Configures the maximum transaction size in bytes which the group accepts
# loose-group_replication_unreachable_majority_timeout
report_host = '域名'
report_port = 3306
loose-group_replication_flow_control_applier_threshold = 250000
loose-group_replication_flow_control_certifier_threshold = 250000
在现有初始化环境配置 MGR
# For Group Replication
transaction-isolation = READ-COMMITTED
binlog_checksum = NONE
master_info_repository = TABLE
relay_log_info_repository = TABLE
plugin-load = group_replication.so
transaction_write_set_extraction = XXHASH64
loose-group_replication_group_name = 33984520-8709-11e7-b883-782bcb105915
loose-group_replication_start_on_boot = OFF
loose-group_replication_local_address = '10.13.2.29:9999'
loose-group_replication_group_seeds = '10.13.2.29:9999,10.77.16.197:9999,10.73.25.178:9999'
loose-group_replication_bootstrap_group = OFF
# loose-group_replication_enforce_update_everywhere_checks = ON # Multi-Primary Mode
loose-group_replication_transaction_size_limit = 52428800 # 5.7.19 Configures the maximum transaction size in bytes which the group accepts
group_replication_ip_whitelist = '10.0.0.0/8'
# loose-group_replication_single_primary_mode = OFF
report_host = '10.13.2.29'
report_port = 8888
配置说明:
开启 Binlog、Relaylog
开启 GTID 功能
设置 ROW 格式的 Binlog
禁用 binlog_checksum (MySQL 5.7.17 不支持带 checksum Binlog Event)
要使用多源复制,必须使用将 Slave 通道(Channel) 的状态信息存储到系统表
开启并行复制
-
开启主键信息采集
GR 需要 Server 层采集更新数据的主键信息,被 HASH 存储起来,支持两种 HASH 算法:XXHASH64、MURMUR32,默认 transaction_write_set_extraction = OFF,所以要使用 Group Replication 每张表都要有主键,否则更新数据时会失败
一个组内的所有成员必须配置相同的 HASH 算法
plugin-load = 'group_replication.so' 相当执行 INSTALL PLUGIN group_replication SONAME "group_replication.so";
group_replication_group_name =
设置 Group Replication Name,可以通过 select uuid(); 获得 group_replication_start_on_boot = OFF MySQL 启动时,不自动启动 Group Replication
group_replication_local_address =
group_replication_group_seeds =
- 当多个 Server 同时加入组时,确保使用已经存在组的成员,不要使用正在申请加入组的成员,不支持创建组的时候同时加入多个成员
- 从当前view随机选取数据源成员通信,当多个成员进入组时,同一 Server几乎不会重复选择,如果访问失败则自动连接新的数据源成员,一直达到连接重试限制(group_replication_recovery_retry_count = 10 可动态修改),恢复线程将被中止并报错
- 恢复程序不会在每次尝试连接数据源(donor)后休眠,仅当对所有可能的数据源进行尝试无果后才休眠(group_replication_recovery_reconnect_interval = 60 秒 可动态修改)
增强数据源节点切换 Enhanced Automatic Donor Switchover
- 已清除数据:如果所选择的数据源成员,在恢复过程中所需某数据已经删除,则会出现错误,恢复程序检测到此错误并重新选择新的数据源成员
- 重复数据:当新成员加入已经包含一些与所选择数据源成员相冲突的数据,恢复过程中报错,这可能新成员存在一些错误的事务。有人认识可能恢复应该失败退出,而不是切换另一个数据源成员,但在异构集群中一些成员共享冲突事务,有些没有,当错误发生时,恢复可以选择另一个数据源成员(donor)
- 其他错误:如果任何线程恢复失败(接收或应用线程失败),则会出现错误,恢复程序在组内选择一个新的数据源成员(donor)
在一些持续故障或短暂的故障时,恢复程序自动重试到相同或新的数据源成员(the same or a new donor)
- group_replication_ip_whitelist =
- group_replication_bootstrap_group = OFF 如果为 ON 告诉 Group Replication 插件,它是组内第一个成员,要做初始化,初始化后改为 OFF
只在 Group Replication 初始化时或整个组崩溃后恢复的情况下使用,当多个 Server 配置此参数,可能人为造成脑裂
- group_replication 变量加上 "loose" ,则可写入 my.cnf 配置文件中
加载 Group Replication 插件
安装插件
# 加载插件
INSTALL PLUGIN group_replication SONAME 'group_replication.so';
# 启用插件
START GROUP_REPLICATION;
> 将 MySQL 加入一个存在的 Group Replication 组或将它初始化为组内第一个成员
# 停用插件
STOP GROUP_REPLICATION;
> 将 MySQL 从一个 Group Replication 组内移除
初始化组
INSTALL PLUGIN group_replication SONAME "group_replication.so";
SET GLOBAL group_replication_group_name = "93f19c6c-6447-11e7-9323-cb37b2d517f3"; # 可以 select uuid(); 生成
SET GLOBAL group_replication_local_address = "dbaone:7777";
SET GLOBAL group_replication_bootstrap_group = ON ;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group = OFF ;
新成员加入
INSTALL PLUGIN group_replication SONAME "group_replication.so";
SET GLOBAL group_replication_group_name = "93f19c6c-6447-11e7-9323-cb37b2d517f3"; # 可以 select uuid(); 生成
SET GLOBAL group_replication_local_address = "127.0.0.1:7777";
SET GLOBAL group_replication_group_seeds = "db2:7777";
change master to master_user = 'replica',master_password='eHnNCaQE3ND' for channel 'group_replication_recovery';
START GROUP_REPLICATION;
注:如果在 my.ncf 已经配置,这里初始化和新成员加入有些步骤就不需要做了
初始化:
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group = OFF
新成员加入
change master to master_user = 'replica',master_password='eHnNCaQE3ND' for channel 'group_replication_recovery';
START GROUP_REPLICATION;
注:
- 当新成员加入,首先从其他节点,把它加入之前的数据复制过来,这些数据不能通过 Group Replication 通信协议进行复制,而是使用 group_replication_recovery 异步复制通道(Channel)
- 要保证 Binlog 一直存在,否则需要数据初始化,将数据恢复到最近的时间点再加入组 ???(wait 测试)
- 连接到哪个成员上去复制,是由 Group Replication插件随机选择,因为为 group_replication_reocvery 配置的用户每个成员上都要存在
- 在启动 group_replication_recovery 之前,Group Replication 会自动为其配置 MASTER_HOST、MASTER_PORT
- 当一个成员加入时,会收到组内其他成员的配置信息,包括主机名和端口,主机名和端口是从 全局只读变量 hostname、port 获取,如果hostname 无法解析成IP或网络中使用网络地址映射,group_replication_recover 通道无法正常工作
- /etc/hosts 配置所有成员的主机名和IP地址对应关系
- 配置 MySQL report_host、report_port,Group Replication 会优先使用此参数
Group Replication 网络分区
当有多个节点意外故障,法定人数可能会丢失,导致大多数成员从组内被移除。
例如5个成员的GR,若同时3个成员突然没有消息,大多数成员仲裁的规则被破坏,因为不能实现仲裁,事实上剩下的2个成员不能辨别其他3个server是否崩溃或网络分隔成独立的2个server,因此该组不能重新配置。
如果有成员主动退出,那么它会告知组进行重新配置。实际上,一个将要离开的成员告知其他成员,它将要离开,其他成员可以重新配置组,保持组内成员关系一致,并重新计算仲裁数,如果5个成员,如果3个成员一个接一个离开组,总数从5->2,同样的时间,确保法定人数。
检测分区
正常情况,组内每个成员均可通过 performance_schema.replication_group_members 查询所有成员状态,每个成员的状态,也是视图中所有成员共同决议的。
如果存在网络分隔,表内访问不到的成员状态是 “UNREACHABLE”,由 Group Replicaion 内置的本地故障检测器完成。
As such, lets assume that there is a group with these 5 servers in it:
- Server s1 with member identifier 199b2df7-4aaf-11e6-bb16-28b2bd168d07
- Server s2 with member identifier 199bb88e-4aaf-11e6-babe-28b2bd168d07
- Server s3 with member identifier 1999b9fb-4aaf-11e6-bb54-28b2bd168d07
- Server s4 with member identifier 19ab72fc-4aaf-11e6-bb51-28b2bd168d07
- Server s5 with member identifier 19b33846-4aaf-11e6-ba81-28b2bd168d07
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | ONLINE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | ONLINE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
5 rows in set (0,00 sec)
# 当同时3个成员失去联系 (s3、s4、s5),此时在s1上查看
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | UNREACHABLE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | UNREACHABLE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | UNREACHABLE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
5 rows in set (0,00 sec)
解除分隔
解决
- 停止 s1、s2 的组复制或完成停了实例,找到其他三个成员停止的原因,然后重新启动组复制(或服务)
- group_replication_force_members 强制这个参数列表成员组成 Group,其实成员移出组 (谨慎操作,防止脑裂)
强制组成员配置
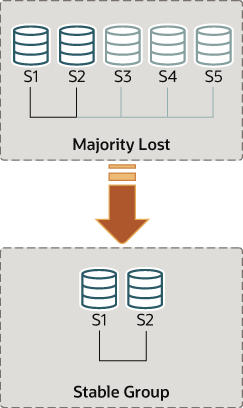
假设只有 s1、s2 在线,s3、s4、s5 意外离开并不在线,可以强制让 s1、s2组成一个组 (membership)
group_replication_force_members 被视为最后补救措施,一定小心使用,仅当多数成员导致不能仲裁时使用,如果被滥用,可能导致脑裂和阻塞整个系统
确定 s3、s4、s5 一定不在线,不可访问,如果这三个成员分区隔离(因为占大多数),强制 s1、s2组成新组,造成人为脑裂
# s1 查看
mysql> SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 1999b9fb-4aaf-11e6-bb54-28b2bd168d07 | 127.0.0.1 | 13002 | UNREACHABLE |
| group_replication_applier | 199b2df7-4aaf-11e6-bb16-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
| group_replication_applier | 199bb88e-4aaf-11e6-babe-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | 19ab72fc-4aaf-11e6-bb51-28b2bd168d07 | 127.0.0.1 | 13003 | UNREACHABLE |
| group_replication_applier | 19b33846-4aaf-11e6-ba81-28b2bd168d07 | 127.0.0.1 | 13004 | UNREACHABLE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
5 rows in set (0,00 sec)
# 检查s1、s2 Group Replication 通信地址 group_replication_local_address
mysql> SELECT @@group_replication_local_address;
+-----------------------------------+
| @@group_replication_local_address |
+-----------------------------------+
| 127.0.0.1:10000 |
+-----------------------------------+
1 row in set (0,00 sec)
mysql> SELECT @@group_replication_local_address;
+-----------------------------------+
| @@group_replication_local_address |
+-----------------------------------+
| 127.0.0.1:10001 |
+-----------------------------------+
1 row in set (0,00 sec)
# 强制重新配置组成员 s1 (127.0.0.1 只是列表,真实环境要看变量 group_replication_local_address)
SET GLOBAL group_replication_force_members="127.0.0.1:10000,127.0.0.1:10001";
# 检查 s1
mysql> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | b60907e7-4ab6-11e6-afb7-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
2 rows in set (0,00 sec)
# 检查 s2
mysql> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | b5ffe505-4ab6-11e6-b04b-28b2bd168d07 | 127.0.0.1 | 13000 | ONLINE |
| group_replication_applier | b60907e7-4ab6-11e6-afb7-28b2bd168d07 | 127.0.0.1 | 13001 | ONLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
2 rows in set (0,00 sec)
多主模式
多主模式不支持在线更改。
my.cnf 与单主模式配置不同
loose-group_replication_single_primary_mode = OFF
loose-group_replication_enforce_update_everywhere_checks = ON # start group_replication后不可修改
auto_increment_increment =
auto_increment_offset =
auto_increment_increment、auto_increment_offset 如果不配置,auto_increment_offset 使用 server_id,auto_increment_increment 使用group_replication_auto_increment_increment(默认为7)
多主模式,变量 group_replication_primary_member 为空
localhost.(none)>show global status like 'group_replication_primary_member';
+----------------------------------+-------+
| Variable_name | Value |
+----------------------------------+-------+
| group_replication_primary_member | |
+----------------------------------+-------+
1 row in set (0.00 sec)
read_only、super_only_only 均为 OFF
localhost.(none)>show variables like '%read_only%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_read_only | OFF |
| read_only | OFF |
| super_read_only | OFF |
| tx_read_only | OFF |
+------------------+-------+
4 rows in set (0.00 sec)
监控
# 存储组内成员的基本信息,任何一个成员,都能看到此信息
SELECT * FROM performance_schema.replication_group_members
状态有五种
* OFFLINE:当MySQL Group Replication 没有启用时
* RECOVERING: 当 MySQL Group Replication 启动后,首先设置为 RECOVERING,开始复制加入前的数据
* ONLINE:当 RECOVERING 完成后,状态为 ONLINE,开始对外提供服务
* ERROR: 当本地成员发生错误后,Group Replication 无法工作时,当前成员状态会变成 ERROR (组内正常成员可能看不到 ERROR 成员)
* UNRECAHABLE: 当网络故障或其他成员宕机时,其他成员的状态会被设置为 UNREACHABLE
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| group_replication_applier | 817b0415-661a-11e7-842a-782bcb479deb | 10.55.28.64 | 6666 | ONLINE |
| group_replication_applier | c745233b-6614-11e7-a738-40f2e91dc960 | 10.13.2.29 | 6666 | ONLINE |
| group_replication_applier | e99a9946-6619-11e7-9b07-70e28406ebea | 10.77.16.197 | 6666 | ONLINE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
3 rows in set (0.00 sec)
# 存储本地成员详细信息,每个成员只能查询到自己的详细信息
SELECT * FROM performance_schema.replication_group_member_stats # 跟多主模式冲突检测相关
localhost.(none)>SELECT CHANNEL_NAME,VIEW_ID,MEMBER_ID FROM performance_schema.replication_group_member_stats ;
+---------------------------+----------------------+--------------------------------------+
| CHANNEL_NAME | VIEW_ID | MEMBER_ID |
+---------------------------+----------------------+--------------------------------------+
| group_replication_applier | 14997660180761984:11 | e99a9946-6619-11e7-9b07-70e28406ebea |
+---------------------------+----------------------+--------------------------------------+
1 row in set (0.00 sec)
# 当新成员加入时,首先通过异步通道(Channel) group_replication_recovery 把加入组之前组内产生的数据同步过来,这个通道状态信息和其他异步复制通道一样,通过此表来监控。
# Group Replication 的通道不会在 SHOW SLAVE STATUS 显示
SELECT * FROM performance_schema.replication_connection_status
localhost.(none)>SELECT CHANNEL_NAME,GROUP_NAME,THREAD_ID,SERVICE_STATE FROM performance_schema.replication_connection_status;
+----------------------------+--------------------------------------+-----------+---------------+
| CHANNEL_NAME | GROUP_NAME | THREAD_ID | SERVICE_STATE |
+----------------------------+--------------------------------------+-----------+---------------+
| group_replication_applier | 93f19c6c-6447-11e7-9323-cb37b2d517f3 | NULL | ON |
| group_replication_recovery | | NULL | OFF |
+----------------------------+--------------------------------------+-----------+---------------+
# Group Replication 通过 group_replication_applier 通道来执行 Binlog_Event,group_replication_applier 跟其他异步通道一样可以通过此表来查询
SELECT * FROM performance_schema.replication_applier_status
+----------------------------+---------------+-----------------+----------------------------+
| CHANNEL_NAME | SERVICE_STATE | REMAINING_DELAY | COUNT_TRANSACTIONS_RETRIES |
+----------------------------+---------------+-----------------+----------------------------+
| group_replication_applier | ON | NULL | 0 |
| group_replication_recovery | OFF | NULL | 0 |
+----------------------------+---------------+-----------------+----------------------------+
2 rows in set (0.00 sec)
# Group Replication 线程的状态信息
SELECT * FROM performance_schema.threads
* thread/group_rpl/THD_applier_module_receiver
* thread/group_rpl/THD_certifier_broadcast
* thread/group_rpl/THD_recovery
SELECT * FROM mysql.`slave_master_info`
SELECT * FROM mysql.`slave_relay_log_info`
replication 相关视图
SELECT * FROM performance_schema.replication_group_members;
SELECT * FROM performance_schema.replication_group_member_stats;
SELECT * FROM performance_schema.replication_applier_configuration;
SELECT * FROM performance_schema.replication_applier_status;
SELECT * FROM performance_schema.replication_applier_status_by_coordinator;
SELECT * FROM performance_schema.replication_applier_status_by_worker;
SELECT * FROM performance_schema.replication_connection_configuration;
SELECT * FROM performance_schema.replication_connection_status;
参考:
mysql-group-replication-monitoring
官方文档 group-replication-monitoring
Group Replication 原理
MGR 事务执行过程
事务执行过程
- 本地事务控制模块
- 成员间的通信模块
- 全局事务认证模块
- 异地事务执行模块
Flow Control
MySQL Group Replication: understanding Flow Control
问题处理
1. 网络中断/分区处理
可以参考 Quest for Better Replication in MySQL: Galera vs. Group Replication
当一个成员因为为网络问题被清除 Group Replication,需要手工处理,当网络恢复不能自动加入,PXC是可以的
error log 日志显示如下
2017-07-14T11:58:57.208677+08:00 0 [Note] Plugin group_replication reported: '[GCS] Removing members that have failed while processing new view.'
2017-07-14T11:58:57.273764+08:00 0 [Note] Plugin group_replication reported: 'getstart group_id 6c6c3761'
2017-07-14T11:58:57.274693+08:00 0 [Note] Plugin group_replication reported: 'getstart group_id 6c6c3761'
2017-07-14T11:59:00.531055+08:00 0 [Note] Plugin group_replication reported: 'state 4330 action xa_terminate'
2017-07-14T11:59:00.531314+08:00 0 [Note] Plugin group_replication reported: 'new state x_start'
2017-07-14T11:59:00.531338+08:00 0 [Note] Plugin group_replication reported: 'state 4257 action xa_exit'
2017-07-14T11:59:00.531365+08:00 0 [Note] Plugin group_replication reported: 'Exiting xcom thread'
2017-07-14T11:59:00.531365+08:00 0 [Note] Plugin group_replication reported: 'Exiting xcom thread'
2017-07-14T11:59:00.531401+08:00 0 [Note] Plugin group_replication reported: 'new state x_start'
当前节点状态
SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| group_replication_applier | 817b0415-661a-11e7-842a-782bcb479deb | 10.55.28.64 | 6666 | ERROR |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
1 row in set (0.00 sec)
处理步骤:
localhost.(none)>start group_replication;
ERROR 3093 (HY000): The START GROUP_REPLICATION command failed since the group is already running.
localhost.(none)>stop group_replication;
Query OK, 0 rows affected (11.35 sec)
localhost.(none)>start group_replication;
Query OK, 0 rows affected (5.53 sec)
localhost.(none)>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| group_replication_applier | 817b0415-661a-11e7-842a-782bcb479deb | 10.55.28.64 | 6666 | ONLINE |
| group_replication_applier | c745233b-6614-11e7-a738-40f2e91dc960 | 10.13.2.29 | 6666 | ONLINE |
| group_replication_applier | e99a9946-6619-11e7-9b07-70e28406ebea | 10.77.16.197 | 6666 | ONLINE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
3 rows in set (0.00 sec)
2. 组成员事务不一致
被隔离成员,有不是 Group Replication 组内的事务,默认是不能加入到 Group,若人为可知是一致性,可强制加入,谨慎使用
localhost.(none)>stop group_replication;
localhost.(none)>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | c745233b-6614-11e7-a738-40f2e91dc960 | 10.13.2.29 | 6666 | OFFLINE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
1 row in set (0.00 sec)
localhost.test>create table t2 (id int primary key ,name varchar(10));
Query OK, 0 rows affected (0.01 sec)
localhost.test>show variables like '%read_only%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_read_only | OFF |
| read_only | OFF |
| super_read_only | OFF |
| tx_read_only | OFF |
+------------------+-------+
4 rows in set (0.00 sec)
localhost.test>start group_replication;
ERROR 3092 (HY000): The server is not configured properly to be an active member of the group. Please see more details on error log.
error 日志
2017-07-14T15:00:14.966294+08:00 0 [Note] Plugin group_replication reported: 'A new primary was elected, enabled conflict detection until the new primary applies all relay logs'
2017-07-14T15:00:14.966366+08:00 0 [ERROR] Plugin group_replication reported: 'This member has more executed transactions than those present in the group. Local transactions: 5860d02e-4b55-11e7-8721-40f2e91dc960:1-788,
93f19c6c-6447-11e7-9323-cb37b2d517f3:1-16,
c745233b-6614-11e7-a738-40f2e91dc960:1 > Group transactions: 5860d02e-4b55-11e7-8721-40f2e91dc960:1-788,
93f19c6c-6447-11e7-9323-cb37b2d517f3:1-16'
2017-07-14T15:00:14.966383+08:00 0 [ERROR] Plugin group_replication reported: 'The member contains transactions not present in the group. The member will now exit the group.'
2017-07-14T15:00:14.966366+08:00 0 [ERROR] Plugin group_replication reported: 'This member has more executed transactions than those present in the group. Local transactions: 5860d02e-4b55-11e7-8721-40f2e91dc960:1-788,
93f19c6c-6447-11e7-9323-cb37b2d517f3:1-16,
c745233b-6614-11e7-a738-40f2e91dc960:1 > Group transactions: 5860d02e-4b55-11e7-8721-40f2e91dc960:1-788,
93f19c6c-6447-11e7-9323-cb37b2d517f3:1-16'
2017-07-14T15:00:14.966383+08:00 0 [ERROR] Plugin group_replication reported: 'The member contains transactions not present in the group. The member will now exit the group.'
2017-07-14T15:00:14.966392+08:00 0 [Note] Plugin group_replication reported: 'To force this member into the group you can use the group_replication_allow_local_disjoint_gtids_join option'
2017-07-14T15:00:14.966473+08:00 88181 [Note] Plugin group_replication reported: 'Going to wait for view modification'
2017-07-14T15:00:14.968087+08:00 0 [Note] Plugin group_replication reported: 'getstart group_id 6c6c3761'
2017-07-14T15:00:18.464227+08:00 0 [Note] Plugin group_replication reported: 'state 4330 action xa_terminate'
2017-07-14T15:00:18.464840+08:00 0 [Note] Plugin group_replication reported: 'new state x_start'
2017-07-14T15:00:18.464875+08:00 0 [Note] Plugin group_replication reported: 'state 4257 action xa_exit'
2017-07-14T15:00:18.465367+08:00 0 [Note] Plugin group_replication reported: 'Exiting xcom thread'
2017-07-14T15:00:18.465382+08:00 0 [Note] Plugin group_replication reported: 'new state x_start'
2017-07-14T15:00:23.486593+08:00 88181 [Note] Plugin group_replication reported: 'auto_increment_increment is reset to 1'
2017-07-14T15:00:23.486642+08:00 88181 [Note] Plugin group_replication reported: 'auto_increment_offset is reset to 1'
2017-07-14T15:00:23.486838+08:00 88211 [Note] Error reading relay log event for channel 'group_replication_applier': slave SQL thread was killed
2017-07-14T15:00:23.487244+08:00 88208 [Note] Plugin group_replication reported: 'The group replication applier thread was killed'
强制加入,一定要确定不会导致数据不一致,谨慎操作
localhost.test>SET GLOBAL group_replication_allow_local_disjoint_gtids_join = ON ;
Query OK, 0 rows affected (0.00 sec)
localhost.test>start group_replication;
Query OK, 0 rows affected (2.26 sec)
localhost.test>SET GLOBAL group_replication_allow_local_disjoint_gtids_join = OFF ;
Query OK, 0 rows affected (0.00 sec)
localhost.test>show variables like '%read_only%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_read_only | OFF |
| read_only | ON |
| super_read_only | ON |
| tx_read_only | OFF |
+------------------+-------+
4 rows in set (0.00 sec)
3. 大事务导致组成员被移除或切换
测试如下,在 5.7.17、5.7.18 都有此问题,fix 5.7.19 加了一个限制大事务的参数 group_replication_transaction_size_limit #84785
# 单主模式 5.7.18
CREATE TABLE `kafkaoffset_api_log` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`developer` varchar(20) NOT NULL DEFAULT '' ,
ctime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'request api time',
PRIMARY KEY (`id`),
KEY idx_time(ctime,developer)
);
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 1 row affected (0.01 sec)
Records: 1 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 8 rows affected (0.01 sec)
Records: 8 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 16 rows affected (0.00 sec)
Records: 16 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 32 rows affected (0.01 sec)
Records: 32 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 64 rows affected (0.00 sec)
Records: 64 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 128 rows affected (0.00 sec)
Records: 128 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 256 rows affected (0.02 sec)
Records: 256 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 512 rows affected (0.02 sec)
Records: 512 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 1024 rows affected (0.05 sec)
Records: 1024 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 2048 rows affected (0.08 sec)
Records: 2048 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 4096 rows affected (0.17 sec)
Records: 4096 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 8192 rows affected (0.33 sec)
Records: 8192 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 16384 rows affected (0.62 sec)
Records: 16384 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 32768 rows affected (1.09 sec)
Records: 32768 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 65536 rows affected (2.29 sec)
Records: 65536 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 131072 rows affected (5.00 sec)
Records: 131072 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 262144 rows affected (8.44 sec)
Records: 262144 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select devloper,now() from kafkaoffset_api_log;
ERROR 1054 (42S22): Unknown column 'devloper' in 'field list'
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 524288 rows affected (15.79 sec)
Records: 524288 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
Query OK, 1048576 rows affected (36.33 sec)
Records: 1048576 Duplicates: 0 Warnings: 0
localhost.test>insert into kafkaoffset_api_log(developer,ctime) select developer,now() from kafkaoffset_api_log;
ERROR 3101 (HY000): Plugin instructed the server to rollback the current transaction.
# 当前成员
localhost.test>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
| group_replication_applier | 817b0415-661a-11e7-842a-782bcb479deb | 10.55.28.64 | 6666 | ERROR |
+---------------------------+--------------------------------------+-------------+-------------+--------------+
1 row in set (0.00 sec)
# 其他成员
localhost.test>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| group_replication_applier | c745233b-6614-11e7-a738-40f2e91dc960 | 10.13.2.29 | 6666 | ONLINE |
| group_replication_applier | e99a9946-6619-11e7-9b07-70e28406ebea | 10.77.16.197 | 6666 | ONLINE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
2 rows in set (0.00 sec)
因为执行大事务,在内存分配、网络宽带开销上面,导致故障检测触发使成员处于不可访问状态。
解决:5.7.19 引进一个参数 group_replication_transaction_size_limit ,默认是0,是没有限制,需要根据 MGR 工作负载设置比较合理的值。
# 恢复组成员
localhost.test>stop group_replication ;
Query OK, 0 rows affected (5.67 sec)
localhost.test>start group_replication;
Query OK, 0 rows affected (2.40 sec)
localhost.test>SELECT * FROM performance_schema.replication_group_members;
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| group_replication_applier | 817b0415-661a-11e7-842a-782bcb479deb | 10.55.28.64 | 6666 | ONLINE |
| group_replication_applier | c745233b-6614-11e7-a738-40f2e91dc960 | 10.13.2.29 | 6666 | ONLINE |
| group_replication_applier | e99a9946-6619-11e7-9b07-70e28406ebea | 10.77.16.197 | 6666 | ONLINE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
3 rows in set (0.00 sec)
- 没有主键的表
localhost.test>create table t1(id int,name varchar(10));
Query OK, 0 rows affected (0.02 sec)
localhost.test>insert into t1 values(1,'test1');
ERROR 3098 (HY000): The table does not comply with the requirements by an external plugin.
localhost.test>alter table t1 add primary key(id);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
localhost.test>insert into t1 values(1,'test1');
Query OK, 1 row affected (0.00 sec)
error log
2017-08-22T19:19:38.693424+08:00 4521 [ERROR] Plugin group_replication reported: 'Table t1 does not have any PRIMARY KEY. This is not compatible with Group Replication'
MySQL Change log
1、5.7.20
group_replication_member_weight,默认50,范围[0-100], 单主模式增加权重参数,以前是 uuid 最小选举为新的 Primary,现在先判断权重大的为新的Primary,如果权重相同,再 uuid 最小为新的 Primary
STOP GROUP_REPLICATION 时,以前 stop group replication 还可以接受事务,现在为立刻 super_read_only 生效,对集群一致性更好的保障
STOP GROUP_REPLICATION 时,mgr 通讯停止了,但异步通道没有停止,5.7.20以后异步通道也停止
参考 group_replication_force_members 加上限制,只有多数成员不可达时,才可以使用
-
server_uuid 不可能与 group_replication_group_name 相同
自动化兼容
监控
- 所有节点 group_replication_single_primary_mode 值不同
- 单主模式下,切库上下线域名ip
mysql> show variables like 'group_replication_single_primary_mode';
+---------------------------------------+-------+
| Variable_name | Value |
+---------------------------------------+-------+
| group_replication_single_primary_mode | ON |
+---------------------------------------+-------+
1 row in set (0.00 sec)
- 检查组成员不一致 performance_schema.replication_group_members
-
备份
mb 备份
innobackupex 备份
扩容
slave 扩容 (stop group_replication)
innobackupex 扩容
参考
MySQL High Availabilitywith Group Replication - 宋利兵 IT大咖说
Group Replication: The Sweet and the Sour
MySQL Group Replication: A Quick Start Guide