上一章的 小全栈任务“番茄post”【1】拆分里程碑 最后,预料到接下来采用的将是增量模型的软件开发模型。每一个增量都会经历针对该增量的分析、设计、编码、测试、交付阶段。“里程碑”便不失需求分析的意味。到了这一章,针对“番茄post”做概要设计;鉴于我们对项目的初始探索,这次概要设计将是一个简化版,没有详细的文档作为内容沉淀。
1
随着软件的规模越来越大、结构越来越复杂、开发工具落后、软件开发管理困难而复杂等历史原因,在十九世纪六十年代中期爆发了众所周知的软件危机。为了解决问题,在 1968、1969 年连续召开的两次著名的北大西洋公约组织(NATO)会议时,提出了软件工程的概念。
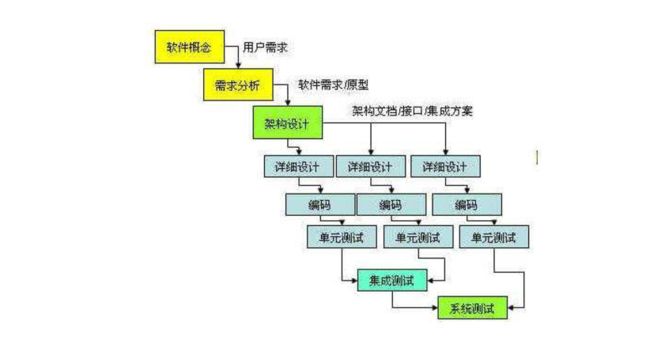
概要设计是软件工程中所占比例很重的环节,在这个实践过程中不仅将软件工程的知识与数据库、VB 以及数据结构等知识相结合的知识交叉地带,更是软件设计的关键,为下一阶段的详细设计做参考。
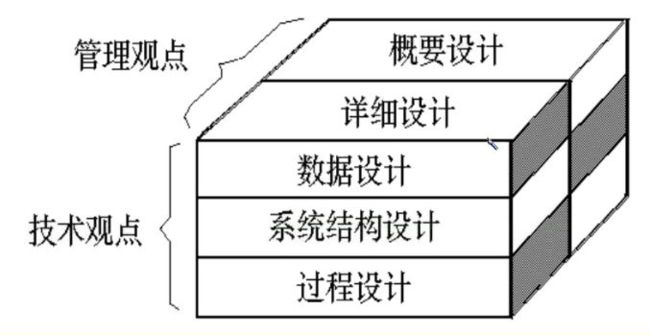
设计软件结构的具体任务是:将一个复杂系统按功能进行模块划分、建立模块的层次结构及调用关系、确定模块间的接口及人机界面等。数据结构设计包括数据特征的描述、确定数据的结构特性、以及数据库的设计。显然,概要设计建立的是目标系统的逻辑模型,与计算机无关。知识错综复杂,这里闲谈而至仅作点醒之笔。
2
鉴于我们对原型图制作的不熟程度,寻找几款市面上基于番茄工作法的软件以作番茄学习,寻找几款市面上的社区软件以作借鉴。
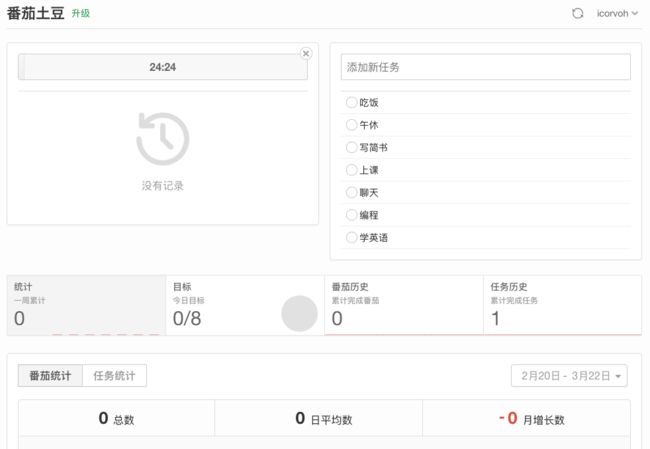
番茄土豆
番茄土豆见名知意,是对番茄工作法和 todo-list 的一次结合尝试,美观大方,简洁如宾。功能上除了将刚刚提到的番茄工作法和 todo-list 结合之外,也有每日 8 个番茄目标、番茄统计和番茄历史等功能。同时,番茄土豆在各大 PC 端、Web 端、移动端乃至谷歌插件,都有相应的访问入口。
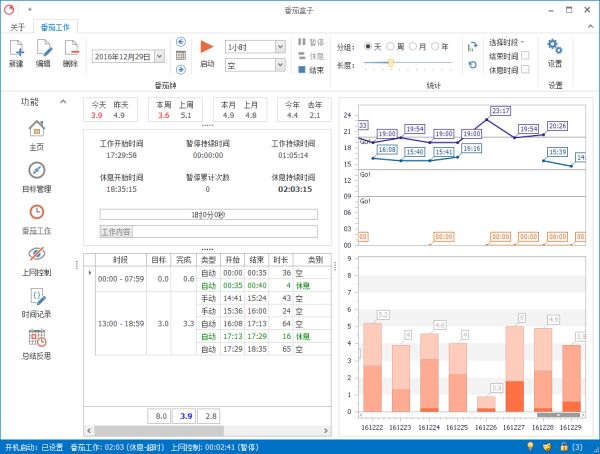
番茄盒子
Windows 平台的免费项目番茄盒子也毫不逊色,除了对番茄工作内容的记录、分析之外还有上网控制,时间记录等功能,是一款功能强大的自我管理软件。所谓“上网控制”,指在用户主动设定想要克制住自己不去访问的网站后,将在该段时间无法浏览这类网站,并在开启“强力监控”的情况下,无法修改设置甚至关闭、卸载软件也无法后悔。
番茄钟 for ios
作为一个移动端的基于番茄工作法来培养用户专注力、提高工作效率的软件,番茄钟的界面够简洁,功能足够丰富。可以分享自己的番茄数据和查看排行榜,拥有了一定的社交属性,值得借鉴。
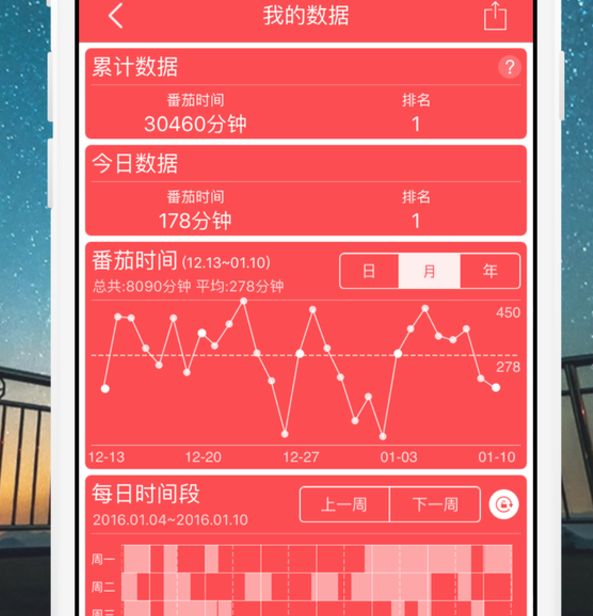
、知乎
不用多多介绍,和知乎应该是很多网客喜欢去的地方,作为社交性平台,这些社区的首页、关注页里的很多哲学思维值得迭代中的“番茄post”原型图吸收。
3
回顾主题,这里我们将共同探讨并快速画出“番茄post”的原型图、组件图、数据结构图和事件列表至白板上,以确定一个明确的、共同的开发目标。
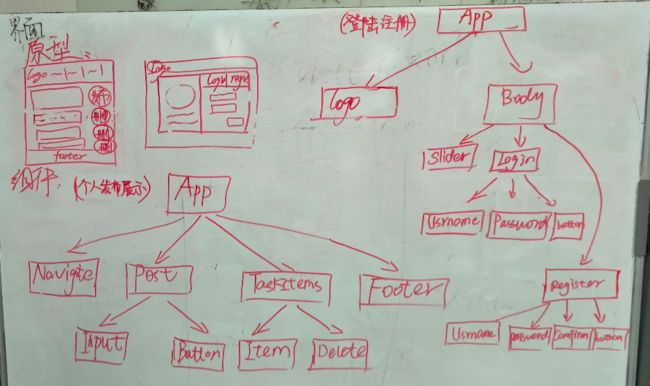

可见,对“番茄post”作出的简化版概要设计这一阶段,是里程碑的具体,也是接下来详细设计阶段的铺垫。
更多内容,持续更新中~。
- Hello,我是韩亦乐,现任本科软工男一枚。软件工程专业的一路学习中,我有很多感悟,也享受持续分享的过程。如果想了解更多或能及时收到我的最新文章,欢迎订阅我的个人微信号:韩亦乐。我的个人主页中,有我的订阅号二维码和 Github 主页地址;我的知乎主页 中也会坚持产出,欢迎关注。
- 本文内部编号经由我的 Github 相关仓库统一管理;本文可能发布在多个平台但仅在上述仓库中长期维护;本文同时采用【知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议】进行许可。

最早拥有排序概念的机器出现在 1901 至 1904 年间由 Hollerith 发明出使用基数排序法的分类机,此机器系统包括打孔,制表等功能,1908 年分类机第一次应用于人口普查,并且在两年内完成了所有的普查数据和归档。
Hollerith 在 1896 年创立的分类机公司的前身,为电脑制表记录公司(CTR)。他在电脑制表记录公司(CTR)曾担任顾问工程师,直到1921年退休,而电脑制表记录公司(CTR)在1924年正式改名为IBM。
---- 摘自《维基百科 - 插入排序》
期中已到,期末将至。《算法设计与分析》的“预习”阶段藉此开始~。在众多的算法思想中,如果你没有扎实的数据结构的功底,不知道栈与队列,哈希表与二叉树,不妨可以从排序算法开始练手。纵观各类排序算法,常见的、经典的排序算法将由此篇引出。
排序算法的输出必须遵守的下列两个原则:
- 输出结果为递增序列(递增是针对所需的排序顺序而言)
- 输出结果是原输入的一种排列、或是重组

十大经典的排序算法及其时间复杂度和稳定性如上表所示。判断一个排序算法是否稳定是看在相等的两个数据排序算法执行完成后是否会前后关系颠倒,如若颠倒,则称该排序算法为不稳定,例如选择排序和快速排序。
排序前:(4, 1) (3, 1) (3, 7)(5, 6)
排序后:(3, 1) (3, 7) (4, 1) (5, 6) (稳定,维持次序)
排序后:(3, 7) (3, 1) (4, 1) (5, 6) (不稳定,次序被改变)
00.交换两个整数的值
接下来十个经典排序算法的详细探讨缺少不了交换两个整数值的掌握,这里回顾一下其中三种方交换法:用临时变量交换两个整数的值(SwapTwo_1)、不用第三方变量交换两个整数的值(SwapTwo_2)、使用位运算交换两个整数的值(SwapTwo_3)。其中用临时变量交换两个整数的值效率最高,后俩者只适用于内置整型数据类型的交换,并不高效。
void SwapTwo_1 (int *a, int* b) {
int temp;
temp = *a;
*a = *b;
*b = temp;
}
void SwapTwo_2 (int *a, int *b) {
*a = *a + *b;
*b = *a - *b;
*a = *a - *b;
}
void SwapTwo_3 (int *a, int *b) {
*a ^= *b;
*b ^= *a;
*a ^= *b;
}
01. 冒泡排序(BubbleSort)
先不说公司面试笔试,大学实验室的纳新题里最常有的就是冒泡排序。冒泡排序重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。由于它的简洁,冒泡排序通常被用来对于程序设计入门的学生介绍算法的概念。
[图片上传失败...(image-9172dd-1509644584398)]](http://upload-images.jianshu.io/upload_images/2558748-990f8de3fbdbb50d.gif?imageMogr2/auto-orient/strip)
上图可见,冒泡排序算法的运作如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
通俗来讲,整个冒泡排序就是通过两次循环,外层循环将此轮最大(小)值固定到此轮尾部,内层循环“冒泡”比较相邻的两个元素并决定是否交换位置。
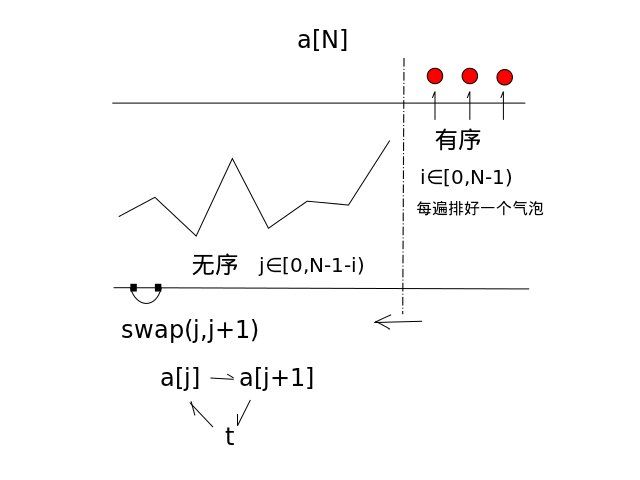
从上图也可理解冒泡排序如何将每一轮最大(小)值固定到此轮尾部:尾部总为有序状态,前面无序状态区根据大小规则冒泡向后方传递最值。
/*
* 冒泡排序。每次外循环将最值固定到数组最后
* @param: {int []} arr
* @param: {int} len
* @return null;
*/
void BubbleSort (int arr[], int len) {
int i, j, temp;
for (int i = 0; i < len - 1; i++) {
// 每趟 i 循环将最大(小)值固定到最后一位
for (int j = 0; j < len - 1 - i; j++) {
// 每趟 j 循环循环没有被固定到后方的数字
if (arr[j] > arr[j + 1]) {
// arr[j] < arr[j + 1] 代表从小到大排序
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
更多十大经典排序算法请戳我的 Github 仓库 @LeetCode-C
02. 选择排序(SelectionSort)
选择排序首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
选择排序的主要优点与数据移动有关。如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对n个元素的表进行排序总共进行至多n-1次交换。在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。

上图左下角和右上角可以分别看做排序序列起始位置(已排序区)和排序序列末尾(未排序区),左下角一直稳定更新,但选择排序不稳定,即排序后曾经相同的两个元素的前后位置关系可能会发生颠倒。
/*
* 选择排序。每次外循环选择最值固定到数组开始
* @param: {int []} arr[]
* @param: {int} len
* @return null;
*/
void SelectionSort (int arr[], int len) {
int i, j, temp, min;
for (i = 0; i < len - 1; i++) {
min = i;
for (j = i + 1; j < len - 1; j++) {
if (arr[min] > arr[j]) {
// 只需找到最小的值的位置后一次性替换
min = j;
}
temp = arr[min];
arr[min] = arr[i];
arr[i] = temp;
}
}
}
更多十大经典排序算法请戳我的 Github 仓库 @LeetCode-C
03. 插入排序(InsertionSort)
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用 in-place
排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。

一般来说,插入排序都采用 in-place 在数组上实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤 2~5
如果比较操作的代价比交换操作大的话,可以采用二分查找法来减少比较操作的数目。该算法可以认为是插入排序的一个变种,称为二分查找插入排序。这里先不做涉及。
/*
* 插入排序。前面有序的数字循环向后留给满足条件的第一个无序数字
* @param: {int []} arr
* @param: {int} len
* @return null;
*/
void InsertionSort (int arr[], int len)
{
int i, j, temp;
for (i = 1; i < len; i++) {
// 与已排序的数逐一比较,大于 temp 时,该数向后移
temp = arr[i];
// 如果将赋值放到下面的for循环内, 会导致在第10行出现 j 未声明的错误
j = i - 1;
for (; j >= 0 && arr[j] > temp; j--) {
// j 循环到-1时,由于短路求值,不会运算 arr[-1]
arr[j + 1] = arr[j];
}
arr[j + 1] = temp;
// 被排序数放到正确的位置
}
}
更多十大经典排序算法请戳我的 Github 仓库 @LeetCode-C
04. 希尔排序(ShellSort)
希尔排序按其设计者希尔(Donald Shell)的名字命名,该算法由1959年公布。希尔排序也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
希尔排序通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了(此时插入排序较快)。
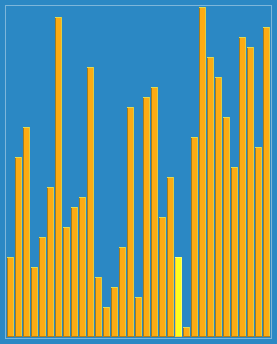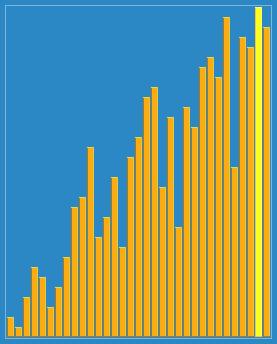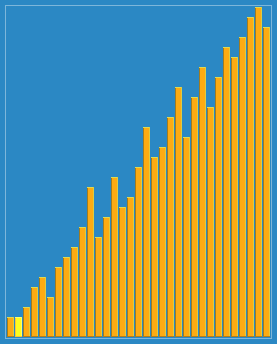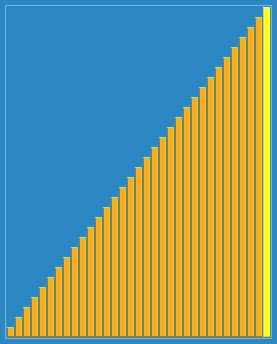
步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为插入排序,这就保证了数据一定会被排序。
已知的最好步长序列是由 Sedgewick 提出的(1, 5, 19, 41, 109,...),这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序要快,甚至在小数组中比快速排序和堆排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
/*
* 希尔排序。
* @param: {int []} arr
* @param: {int} len
* @return null;
*/
void ShellSort(int arr[], int len) {
int gap, i, j;
int temp;
for (gap = len >> 1; gap > 0; gap >>= 1) {
// gap 为间隔,每次间隔折半
for (i = gap; i < len; i++) {
// 循环该轮数组后半段
temp = arr[i];
for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap) {
// 根据当前 grap 间隔和条件进行插入排序前的后移
arr[j + gap] = arr[j];
}
// 插入到当前位置
arr[j + gap] = temp;
}
}
}
更多十大经典排序算法请戳我的 Github 仓库 @LeetCode-C
05. 归并排序(MergeSort)
归并排序是创建在归并操作上的一种有效的排序算法,效率为 O(n log n)。1945年由约翰·冯·诺伊曼首次提出。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。
归并操作(merge),也叫归并算法,指的是将两个已经排序的序列合并成一个序列的操作。归并排序算法依赖归并操作。
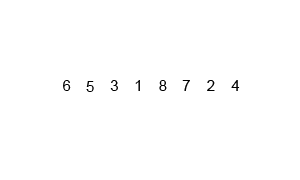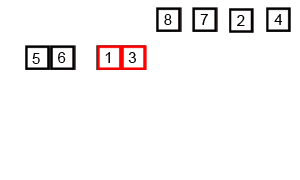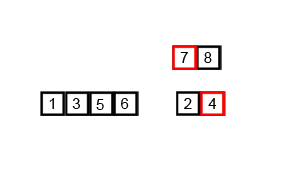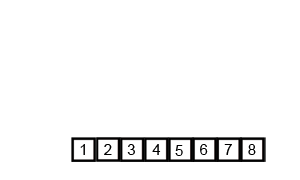
归并排序用迭代法和递归法都可以实现,迭代法的算法步骤为:
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针到达序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
递归法的算法步骤为:
- 将序列每相邻两个数字进行归并操作,形成 floor(n/2) 个序列,排序后每个序列包含两个元素
- 将上述序列再次归并,形成 floor(n/4) 个序列,每个序列包含四个元素
- 重复步骤 2,直到所有元素排序完毕
/*
* 归并排序。迭代版
* @param: {int []} arr
* @param: {int} len
* @return null;
*/
void MergeSort_1 (int arr[], int len) {
int* a = arr;
int* b = (int*) malloc(len * sizeof(int));
int seg, start;
for (seg = 1; seg < len; seg += seg) {
for (start = 0; start < len; start += seg + seg) {
int low = start, mid = Min (start + seg, len), high = Min(start + seg + seg, len);
int k = low;
int start1 = low, end1 = mid;
int start2 = mid, end2 = high;
while (start1 < end1 && start2 < end2)
b[k++] = a[start1] < a[start2] ? a[start1++] : a[start2++];
while (start1 < end1)
b[k++] = a[start1++];
while (start2 < end2)
b[k++] = a[start2++];
}
int* temp = a;
a = b;
b = temp;
}
if (a != arr) {
int i;
for (i = 0; i < len; i++)
b[i] = a[i];
b = a;
}
free(b);
}
int Min(int x, int y) {
return x < y ? x : y;
}
/*
* 归并排序。递归版
* @param: {int []} arr
* @param: {const int} len
* @return null;
*/
void MergeSort_2 (int arr[], const int len) {
int reg[len];
merge_sort_recursive(arr, reg, 0, len - 1);
}
void merge_sort_recursive (int arr[], int reg[], int start, int end) {
if (start >= end)
return;
int len = end - start, mid = (len >> 1) + start;
int start1 = start, end1 = mid;
int start2 = mid + 1, end2 = end;
merge_sort_recursive(arr, reg, start1, end1);
merge_sort_recursive(arr, reg, start2, end2);
int k = start;
while (start1 <= end1 && start2 <= end2)
reg[k++] = arr[start1] < arr[start2] ? arr[start1++] : arr[start2++];
while (start1 <= end1)
reg[k++] = arr[start1++];
while (start2 <= end2)
reg[k++] = arr[start2++];
for (k = start; k <= end; k++)
arr[k] = reg[k];
}
总结【上】
这篇文章“十大经典排序算法及其 C 语言实现【上】”引出了十大经典算法的前五个并用 C 语言实践:冒泡排序、选择排序、插入排序、希尔排序和归并排序,并作出了充足的图文解释。即将推出的“十大经典排序算法及其 C 语言实现【下】”将对剩下五个经典算法快速排序、堆排序、计数排序、桶排序、基数排序作出完善,尽请期待~。

- Hello,我是韩亦乐,现任本科软工男一枚。软件工程专业的一路学习中,我有很多感悟,也享受持续分享的过程。如果想了解更多或能及时收到我的最新文章,欢迎订阅我的个人微信号:韩亦乐。我的个人主页中,有我的订阅号二维码和 Github 主页地址;我的知乎主页 中也会坚持产出,欢迎关注。
- 本文内部编号经由我的 Github 相关仓库统一管理;本文可能发布在多个平台但仅在上述仓库中长期维护;本文同时采用【知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议】进行许可。