recurrent-search-framework 专注于解决递归式搜索问题。
前言:recurrent-search刚刚成型,欢迎有兴趣的大家参考和讨论,如其中发现有 性能、需求或其他问题,一定要告知我,大家一起完善,或者github都可以。
该项目github地址:https://github.com/zhengzhanpeng/recurrent-search-framework
什么是递归式搜索?
就好比我们从电脑里搜索文件时,那么我们通常指定一个根目录,然后以这个目录向下依次搜索,因为这个目录下可能有文件夹,那么我们就需要搜索这个文件夹下的目录。这就是递归式搜索,当然它不单是指搜索电脑文件,它可以是任何递归形式的搜索。
recurrent-search 要解决的问题
- 搜索时是否需要起多个线程搜索
- 并发搜索时如何让线程安全停下来
- 搜索时如何指定Timeout 使搜索指定时间后能返回结果
- 怎样安全的保存有必要缓存的搜索结果以方便下次利用
- 当搜索到指定数量的值后 如何停止线程返回结果
- ......
如何使用?
如果你有一个需要递归搜索的任务,那么就可以使用recurrent-search帮你解决实现。
首先,你需要实现SearchModel这个接口,这个接口内有一个search()方法,这个方法指明了你搜索单次所返回的结果,就拿搜索电脑里的文件来说,相当于只搜索当前目录下是否有正确的结果类型和可以被继续搜索的类型。
SearchModel 的接口定义如下:
public interface SearchModel {
MessageOfSearched search(KeyT keySearch, PathT canBeSearched);
}
那么桌面搜索的SearchModle就好像这样:
public class DesktopSearchModel implements SearchModel {
@Override
public MessageOfSearched search(String key, String path) {
File[] childFiles = getAllChildFile(path);
List trueResults = getTrueResults(key, childFiles);
List paths = getPaths(childFiles);
MessageOfSearched messageOfSearched = new MessageOfSearched(trueResults, paths);
return messageOfSearched;
}
private File[] getAllChildFile(String canBeSearched) {
File file = new File(canBeSearched);
return file.listFiles();
}
private List getTrueResults(String keySearch, File[] childFiles) {
if (childFiles == null) {
return new ArrayList<>();
}
return Arrays.stream(childFiles)
.filter(objectOfTest -> isTrueObject(keySearch, objectOfTest)).collect(Collectors.toList());
}
private List getPaths(File[] childFiles) {
if (childFiles == null) {
return new ArrayList<>();
}
return Arrays.stream(childFiles)
.filter(objectOfTest -> objectOfTest.isDirectory())
.map(objectOfTest -> objectOfTest.getPath()).collect(Collectors.toList());
}
}
它只实现了search()方法,告诉了我们搜索单个目录的结果是什么。其余的算法只需要交给recurrent-search去帮我们完成。
那么现在你就可以使用recurrent-search来做递归搜索了。如下:
public class App {
public static void main(String[] args) {
SearchModel searchModel = new DesktopSearchModel();
List rootSearch = new ArrayList<>();
rootSearch.add("D:\\");
EntirelySearch search = new ConcurrentEntirelySearch(searchModel, rootSearch);
List list = search.getResultsUntilEnoughOrOneTimeout("README.html", 3, 5, TimeUnit.SECONDS);
System.out.println("------find size:" + list.size());
list.forEach(file -> System.out.println(file.getPath()));
}
}
如上main方法中使用recurrent-search从D盘根目录开始搜索文件名为README.html的文件。它的执行条件是当搜索达到3个合理文件时或者当获取下一个合理文件等待时间超过5秒时返回搜索结果。
上述例子只是搜索情况中的一种,recurrent-search提供了多种多样的执行条件用来选择。
recurrent-search还提供了多种调度策略,为了应对不同的搜索情况,比如:搜索时单次搜索时间较长时、有一些结果可能经常会被搜索时、搜索目录可能会经常变动等。
recurrent-search 中的 boxSearch 与 openSearch模式
recurrent-search 分为boxSearch和openSearch两种搜索模式。
boxSearch 的含义是:我们把搜索空间看为由一个或多个盒子组成,使用时我们首先指定要去搜索的盒子,然后recurrent-search就会从这几个盒子里面搜索我们要获取的结果。
openSearch 的含义是:我们的搜索空间是开放的,每次搜索时我们要指明我们去哪里搜索,它就会沿着我们指明的路径开始逐个搜索。
由这两种模式展开分别形成了下面两种接口继承关系:
boxSearch:
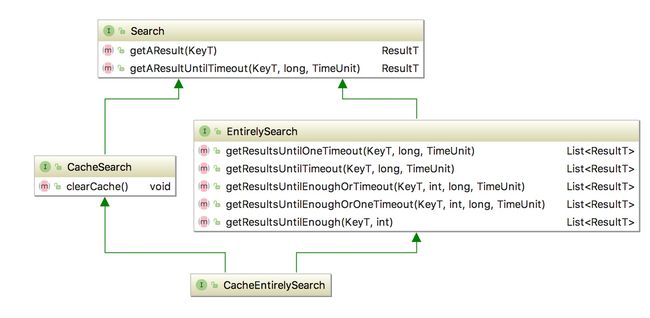
openSearch:
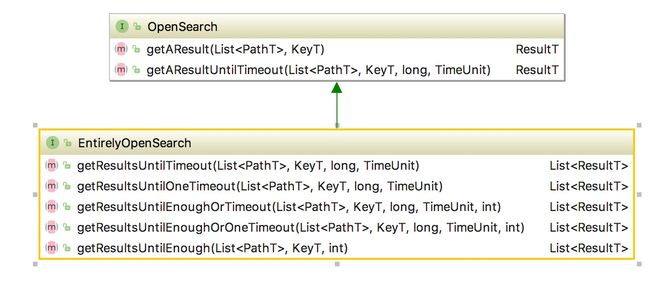
这两种模式都是围绕如何获取结果展开的,线程调用、如何安全取消线程等都在实现类里考虑。
这些接口主要是声明了都需要哪些获取结果的方式,如下:
-
getAResult():获取一个结果,在没有获取到结果之前一直保持阻塞状态。 -
getAResultUntilTimeout():获取一个结果,在没有获取到结果并且没有超时之前一直保持阻塞状态。如因超时返回则会抛出TimeoutException的异常。
-
getResultsUntilOneTimeout(): 获取多个结果,一直到获取下一个结果超时时返回。 -
getResultsUntilTimeout(): 获取多个结果,一直到总的时间超时时返回。
-
getResultsUntilEnough():获取指定数量的结果,在数量足够之前一直保持阻塞。 -
getResultsUntilEnoughOrTimeout(): 获取指定数量的结果,在数量足够或总的时间超时之前一直保持阻塞。 -
getResultsUntilEnoughOrOneTimeout(): 获取指定数量的结果,在数量足够或获取下一个结果超时之前一直保持阻塞。 - 注:以上任何一种情况都会在搜索完毕后返回。
以上这些就是recurrent-search 中获取结果的所有方式,这些应该可以包含绝大多数情况了。
recurrent-search 的实现类
这里简单说下recurrent-search的实现类的一些特性
-----openSearchImpl
openSearchImpl包下目前只有一个实现类:ConcurrentEntirelyOpenSearch
它的实现如下:
public class ConcurrentEntirelyOpenSearch implements EntirelyOpenSearch {
private static final int NOT_LIMIT_EXPECT_NUM = 0;
private static final int NOT_HAVE_TIMEOUT = 0;
private static final long MAX_WAIT_MILLI = 3*1000*60;
private final SearchModel searchModel;
private final ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
private final ExecutorService getService = Executors.newCachedThreadPool();
public ConcurrentEntirelyOpenSearch(SearchModel searchModel) {
this.searchModel = searchModel;
}
......
}
它的搜索方式是并行搜索的,每次调用getResult*()时都会并行的去搜索可能的结果,当搜索完成或者超时时它会停掉当前正在搜索的线程,并返回已搜索到的结果。
超时取消线程并返回的实现
在目前的实现类里面,超时时的取消策略共分为两种,一种是通过BolckingQueue的poll(),另一种是通过Future的get()来实现取消。前者适用于OneTimeout的情况,而后者则用于Timeout的情况。
这里说明下为什么不用Java内的Timer去实现定时,首先Timer在执行定时任务时只会创建一个线程。如果某个任务的执行时间过长,那么将破坏其他TimerTask的定时精确性。其次它的另一个问题是,如果TimerTask抛出了一个未检查的异常,Timer线程并不捕获异常,它会错误的认为整个Timer都被取消了,所以后面的TimerTask也不会被执行。
通过BolckingQueue实现如下:
@Override
public List getResultsUntilEnoughOrOneTimeout(List pathList, KeyT keyT, long timeout, TimeUnit unit, int exceptNum) {
SearchParameter parameter = createSearchRuleBeforeSearch(keyT, timeout, unit, exceptNum);
startSearch(parameter, pathList);
ArrayList list = putResultUntilOneTimeoutOrEnough(parameter);
return list;
}
private ArrayList putResultUntilOneTimeoutOrEnough(SearchParameter parameter) {
ArrayList list = new ArrayList<>();
boolean isNotTimeout = true;
boolean isNotEnough = true;
try {
while (isNotTimeout && isNotEnough) {
ResultT resultT = parameter.resultQueue.poll(parameter.timeout, parameter.unit);
if (Objects.nonNull(resultT)) {
list.add(resultT);
continue;
}
isNotTimeout = false;
isNotEnough = isEnough(parameter.exceptNum, list);
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
parameter.searchService.shutdownNow();
}
return list;
}
如上只包含了关键部分代码,在putResultUntilOneTimeoutOrEnough方法内通过poll()指定超时时限来确定是否超时。
通过Future实现如下:
@Override
public List getResultsUntilEnoughOrTimeout(List pathList, KeyT keyT, long timeout, TimeUnit unit, int exceptNum) {
final List list = new ArrayList<>();
SearchParameter parameter = createSearchRuleBeforeSearch(keyT, timeout, unit, exceptNum);
startSearch(parameter, pathList);
addResultToListWithTiming(list, parameter);
return list;
}
private void addResultToListWithTiming(List list, SearchParameter parameter) {
final Future cancelFuture = submitAddResultToList(list, parameter);
timingCancel(parameter, cancelFuture);
}
private Future submitAddResultToList(List list, SearchParameter parameter) {
return getService.submit(() -> {
boolean isNotEnough = true;
while (isNotEnough) {
ResultT result = takeResultFromQueue(parameter);
Optional.ofNullable(result).ifPresent(r -> list.add(r));
isNotEnough = !isEnough(parameter.exceptNum, list);
}
});
}
private void timingCancel(SearchParameter parameter, Future cancelFuture) {
try {
cancelFuture.get(parameter.timeout, parameter.unit);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
} finally {
cancelFuture.cancel(true);
parameter.searchService.shutdownNow();
}
}
如上,它通过获取结果时Executor返回的Future调用get()来实现。
-----boxSearchImpl
boxSearchImpl包下有两个实现类:ConcurrentEntirelySearch和ConcurrentCacheEntirelySearch
首先是ConcurrentEntirelySearch,它的实现如下:
public class ConcurrentEntirelySearch implements EntirelySearch {
private final List rootCanBeSearch;
private final ConcurrentEntirelyOpenSearch openSearch;
public ConcurrentEntirelySearch(SearchModel searchModel, List rootCanBeSearch) {
this.rootCanBeSearch = rootCanBeSearch;
this.openSearch = new ConcurrentEntirelyOpenSearch<>(searchModel);
}
...
}
它内部有一个openSearch的成员变量,因为这个类的功能跟EntirelyOpenSearch这个接口的功能很相似,所不同只是ConcurrentEntirelySearch 指定的范围是final的。
有人可能会说,那为什么不把这两个写在一起。我的观点是,我觉得这样更像是一种约定,或者是一种规则,觉得分为两个类要好一些,之后再仔细琢磨琢磨。
boxSearchImpl下的每个实现类都必须指定private final List的值。每次查询任一结果,都会从这个根目录开始搜寻。
其次是ConcurrentCacheEntirelySearch的实现如下:
public class ConcurrentCacheEntirelySearch implements CacheEntirelySearch {
private static final int NOT_LIMIT_EXPECT_NUM = 0;
public static final int NOT_HAVE_TIMEOUT = 0;
private final SearchModel searchModel;
private final EfficientCacheCompute>> cacheResults;
private final ExecutorService searchService;
private final ExecutorService gitService;
private final List rootCanBeSearched;
public ConcurrentCacheEntirelySearch(SearchModel searchModel, List rootCanBeSearched) {
this.searchModel = searchModel;
this.cacheResults = EfficientCacheCompute.createNeedComputeFunction(this::methodOfHowSearch);
this.searchService = Executors.newCachedThreadPool();
this.gitService = Executors.newCachedThreadPool();
this.rootCanBeSearched = rootCanBeSearched;
}
private ConcurrentCacheEntirelySearch(SearchModel searchModel, List rootCanBeSearched, ExecutorService searchService) {
this.searchModel = searchModel;
this.searchService = searchService;
this.rootCanBeSearched = rootCanBeSearched;
this.gitService = Executors.newCachedThreadPool();
this.cacheResults = EfficientCacheCompute.createNeedComputeFunction(this::methodOfHowSearch);
}
public ConcurrentCacheEntirelySearch(SearchModel searchModel, List rootCanBeSearched, ExecutorService searchService, ExecutorService gitService) {
this.searchModel = searchModel;
this.searchService = searchService;
this.gitService = gitService;
this.rootCanBeSearched = rootCanBeSearched;
this.cacheResults = EfficientCacheCompute.createNeedComputeFunction(this::methodOfHowSearch);
}
public static ConcurrentCacheEntirelySearch createHowAppointSearchExecutor(SearchModel searchModel, List rootCanBeSearched, ExecutorService searchService) {
return new ConcurrentCacheEntirelySearch(searchModel, rootCanBeSearched, searchService);
}
public static ConcurrentCacheEntirelySearch createHowAppointSearchExecutorAndGitExecutor(SearchModel searchModel, List rootCanBeSearched, ExecutorService searchService, ExecutorService gitService) {
return new ConcurrentCacheEntirelySearch(searchModel, rootCanBeSearched, searchService, gitService);
}
......
}
ConcurrentCacheEntirelySearch是基于缓存的并发搜索实现类。如果基于缓存,则需要考虑的情况就很多,所以他的构造方式就有四种,不同的构造方式主要是针对它的searchService和gitService的实现来考虑的。这两个变量都是ExecutorService,我们所采取的策略就大不相同了。
因为它是基于缓存的,它的cache是通过WeakReference去存储,尽可能的保证内存不会溢出。(采用WeakReference的类 会在虚拟机每次gc时被回收掉)
另外用BlockingQueue去存储缓存的结果,这样可以保证适时获取被搜索到的值。
最后
recurrent-search-framework刚刚写好,肯定还有许多不足需要改进,希望大家以后发现问题能多多交流,最好是可以在github上issues,你也可以pull request你的解决办法。