
前言
之前写了不少 Flink 文章了,也有不少 demo,但是文章写的时候都是在本地直接运行 Main 类的 main 方法,其实 Flink 是支持在 UI 上上传 Flink Job 的 jar 包,然后运行得。最开始在第一篇 《从0到1学习Flink》—— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门 中其实提到过了 Flink 自带的 UI 界面,今天我们就来看看如何将我们的项目打包在这里发布运行。
准备
编译打包
项目代码就拿我之前的文章 《从0到1学习Flink》—— Flink 写入数据到 ElasticSearch 吧,代码地址是在 GitHub 仓库地址:https://github.com/zhisheng17/flink-learning/tree/master/flink-learning-connectors/flink-learning-connectors-es6 ,如果感兴趣的可以直接拿来打包试试水。
我们在整个项目 (flink-learning)pom.xml 所在文件夹执行以下命令打包:
mvn clean install
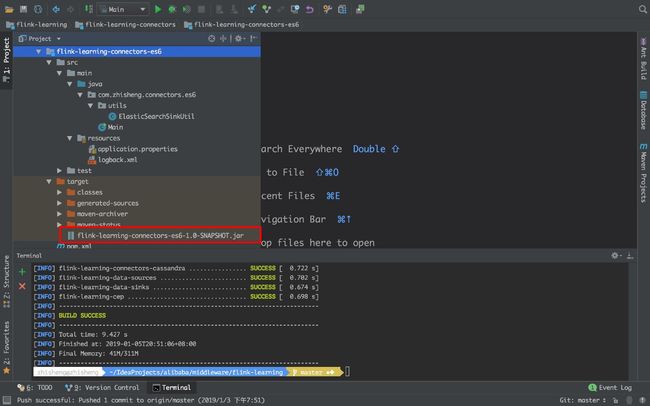
然后你会发现在 flink-learning-connectors-es6 的 target 目录下有 flink-learning-connectors-es6-1.0-SNAPSHOT.jar 。
启动 ES
注意你的 Kafka 数据源和 ES 都已经启动好了, 清空了下 ES 目录下的 data 数据,为了就是查看是不是真的有数据存入进来了。
提交 jar 包
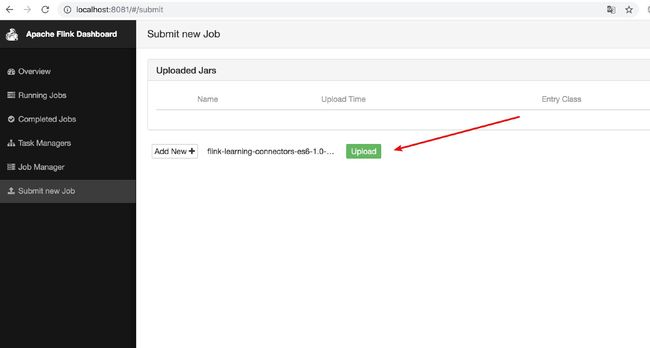
将此文件提交到 Flinkserver 上,如下图:

点击下图红框中的"Upload"按钮:
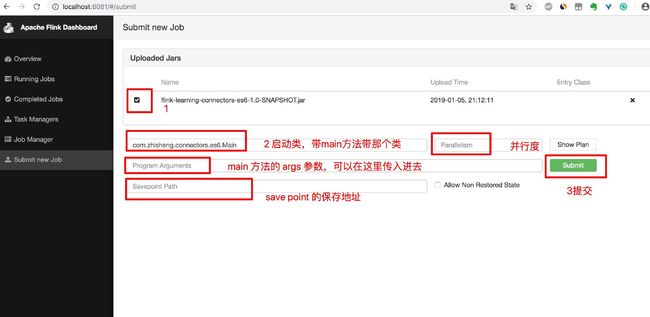
如下图,选中刚刚上传的文件,填写类名,再点击"Submit"按钮即可启动 Job:
查看运行结果
如下图,在 Overview 页面可见正在运行的任务:

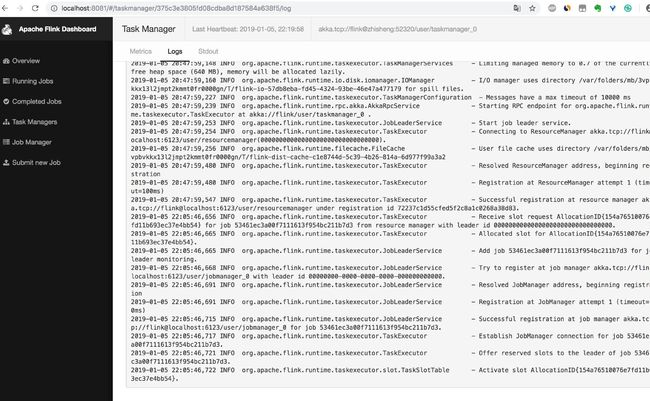
你可以看到 Task Manager 中关于任务的 metric 数据
、日志信息以及 Stdout 信息。
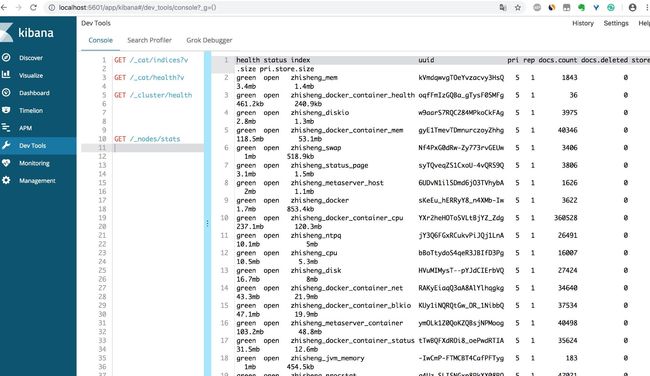
查看 Kibana ,此时 ES 中已经有数据了:
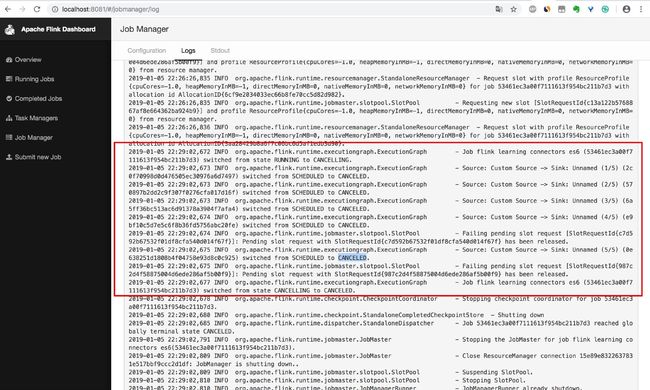
我们可以在 flink ui 界面上的 overview cancel 这个 job,那么可以看到 job 的日志:

总结
本篇文章写了下如何将我们的 job 编译打包并提交到 Flink 自带到 Server UI 上面去运行,也算是对前面文章的一个补充,当然了,Flink job 不仅支持这种模式的运行,它还可以运行在 K8s,Mesos,等上面,等以后我接触到再写写。
本文原创地址是: http://www.54tianzhisheng.cn/2019/01/05/Flink-run/ , 未经允许禁止转载。
关注我
微信公众号:zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号了。你可以加我的微信:zhisheng_tian,然后回复关键字:Flink 即可无条件获取到。

更多私密资料请加入知识星球!

Github 代码仓库
https://github.com/zhisheng17/flink-learning/
以后这个项目的所有代码都将放在这个仓库里,包含了自己学习 flink 的一些 demo 和博客。
相关文章
1、《从0到1学习Flink》—— Apache Flink 介绍
2、《从0到1学习Flink》—— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、《从0到1学习Flink》—— Flink 配置文件详解
4、《从0到1学习Flink》—— Data Source 介绍
5、《从0到1学习Flink》—— 如何自定义 Data Source ?
6、《从0到1学习Flink》—— Data Sink 介绍
7、《从0到1学习Flink》—— 如何自定义 Data Sink ?
8、《从0到1学习Flink》—— Flink Data transformation(转换)
9、《从0到1学习Flink》—— 介绍Flink中的Stream Windows
10、《从0到1学习Flink》—— Flink 中的几种 Time 详解
11、《从0到1学习Flink》—— Flink 写入数据到 ElasticSearch
12、《从0到1学习Flink》—— Flink 项目如何运行?
13、《从0到1学习Flink》—— Flink 写入数据到 Kafka
14、《从0到1学习Flink》—— Flink JobManager 高可用性配置
15、《从0到1学习Flink》—— Flink parallelism 和 Slot 介绍
16、《从0到1学习Flink》—— Flink 读取 Kafka 数据批量写入到 MySQL