需求 : 要抓取大量行业文章。
于是想到之前的WebCollector 。
github 主页https://github.com/CrawlScript/WebCollector
构思:需要保存数据 到数据库 等
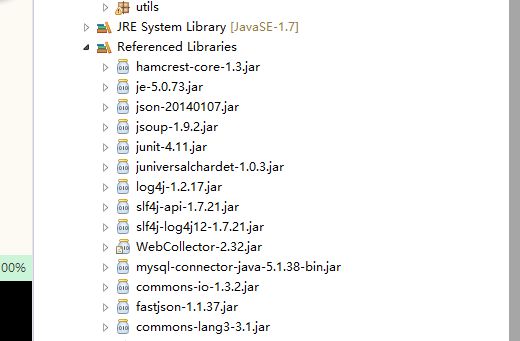
所以需要 数据库连接的jar 包以及一些便于使用的。最终项目引用的jar包:
public class NewsCrawler2 extends BreadthCrawler {
/**
* @param crawlPath
* crawlPath is the path of the directory which maintains
* information of this crawler
* @param autoParse
* if autoParse is true,BreadthCrawler will auto extract links
* which match regex rules from pag
*/
public NewsCrawler2(String crawlPath, boolean autoParse) {
super(crawlPath, autoParse);
/* start page */
this.addSeed("http://news.hfut.edu.cn/list-1-1.html");
/* fetch url like http://news.hfut.edu.cn/show-xxxxxxhtml */
this.addRegex("http://news.hfut.edu.cn/show-.*html");
/* do not fetch jpg|png|gif */
this.addRegex("-.*\\.(jpg|png|gif).*");
/* do not fetch url contains # */
this.addRegex("-.*#.*");
}
public void visit(Page page, CrawlDatums next) {
String url = page.getUrl();
/* if page is news page */
if (page.matchUrl("http://news.hfut.edu.cn/show-.*html")) {
/* we use jsoup to parse page */
Document doc = page.getDoc();
/* extract title and content of news by css selector */
String title = page.select("div[id=Article]>h2").first().text();
String content = page.select("div#artibody", 0).text();
System.out.println("URL:\n" + url);
System.out.println("title:\n" + title);
System.out.println("content:\n" + content);
/* If you want to add urls to crawl,add them to nextLink */
/*
* WebCollector automatically filters links that have been fetched
* before
*/
/*
* If autoParse is true and the link you add to nextLinks does not
* match the regex rules,the link will also been filtered.
*/
// next.add("http://xxxxxx.com");
}
}
public static void main(String[] args) throws Exception {
NewsCrawler2 crawler = new NewsCrawler2("crawl", true);
crawler.setThreads(50);
crawler.setTopN(100);
// crawler.setResumable(true);
/* start crawl with depth of 4 */
crawler.start(4);
//.setResumable(true);
/*
* 设置是否为断点爬取,如果设置为false,任务启动前会清空历史数据。 如果设置为true,会在已有crawlPath(构造函数的第一个参数)的基础上继
* 续爬取。对于耗时较长的任务,很可能需要中途中断爬虫,也有可能遇到 死机、断电等异常情况,使用断点爬取模式,可以保证爬虫不受这些因素
* 的影响,爬虫可以在人为中断、死机、断电等情况出现后,继续以前的任务 进行爬取。断点爬取默认为false
*/
}
}
这是给的例子。
笔记
1解析部分:
public void visit(Page page, CrawlDatums next) 中解析
获取meta 信息
html 中
则
Document doc = page.getDoc();
String category = doc.head().select("meta[property=og:type]").first().attr("content");
根据 div 的id 或者 class 来获取元素
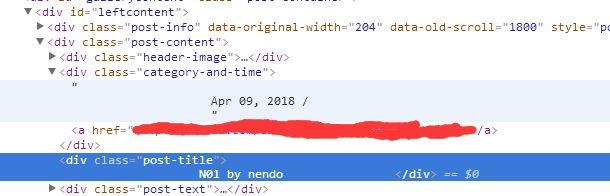
String title_and_author = page.select("div[id=leftcontent]").select("[class=post-title]").text();
获取 图片连接 //选择div[id=leftcontent] 中的图片,图片class=image.
Elements imgs = page.select("div[id=leftcontent]").select("[class=image]");
System.err.print("imgs count=" + imgs.size());
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
System.err.println("imgSrc" + imgSrc);
}
通用的是:
Elements imgs2 = page.select("main[id=leftcontent]").select("img[src]");
保存文本 txt 换行"\r\n"
String txtcontent = page.getUrl() + "\r\n" + title + "\r\n" + author + "\r\n" + date + "\r\n" + category
+ "\r\n" +description;
2 添加代理、User-Agent
重写getResponse
@Override
public HttpResponse getResponse(CrawlDatum crawlDatum) throws Exception {
/* 设置代理服务器 */
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress("127.0.0.1", 8087));
//HttpRequest hr = new HttpRequest(crawlDatum, proxy );
HttpRequest hr = new HttpRequest(crawlDatum, null);
// hr.setProxy(proxy);
hr.setUserAgent(getusergent());
return hr.getResponse();
}
private static String[] agentarray = { "Mozilla/5.0 (compatible, MSIE 10.0, Windows NT, DigExt)",
"Mozilla/4.0 (compatible, MSIE 7.0, Windows NT 5.1, 360SE)",
"Mozilla/4.0 (compatible, MSIE 8.0, Windows NT 6.0, Trident/4.0)",
"Mozilla/5.0 (compatible, MSIE 9.0, Windows NT 6.1, Trident/5.0),",
"Opera/9.80 (Windows NT 6.1, U, en) Presto/2.8.131 Version/11.11",
"Mozilla/4.0 (compatible, MSIE 7.0, Windows NT 5.1, TencentTraveler 4.0)",
"Mozilla/5.0 (Windows, U, Windows NT 6.1, en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Macintosh, Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh, U, Intel Mac OS X 10_6_8, en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Linux, U, Android 3.0, en-us, Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (iPad, U, CPU OS 4_3_3 like Mac OS X, en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/4.0 (compatible, MSIE 7.0, Windows NT 5.1, Trident/4.0, SE 2.X MetaSr 1.0, SE 2.X MetaSr 1.0, .NET CLR 2.0.50727, SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (iPhone, U, CPU iPhone OS 4_3_3 like Mac OS X, en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"MQQBrowser/26 Mozilla/5.0 (Linux, U, Android 2.3.7, zh-cn, MB200 Build/GRJ22, CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1" };
public static String getusergent() {
Random rand = new Random();
return agentarray[rand.nextInt(agentarray.length)];
}
3.数据库部分
在mysql 中创建 表
选定数据库
执行sql
CREATE TABLE `test` (
`key` INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
`id` INT(11) UNSIGNED NOT NULL,
`title` VARCHAR(255) NOT NULL,
`author` VARCHAR(255) NOT NULL,
`date` VARCHAR(255) DEFAULT NULL,
`category` VARCHAR(255) DEFAULT NULL,
`header_image` VARCHAR(255) DEFAULT NULL,
`content_image` VARCHAR(5000) NOT NULL,
`content` TEXT DEFAULT NULL,
`content_zh` TEXT DEFAULT NULL,
`website` VARCHAR(255) DEFAULT NULL,
`url` VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (`key`)
) ENGINE=INNODB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
手动把MYSQL 的connection jar包配置加进去。
创建对象 对应字段 getset方法
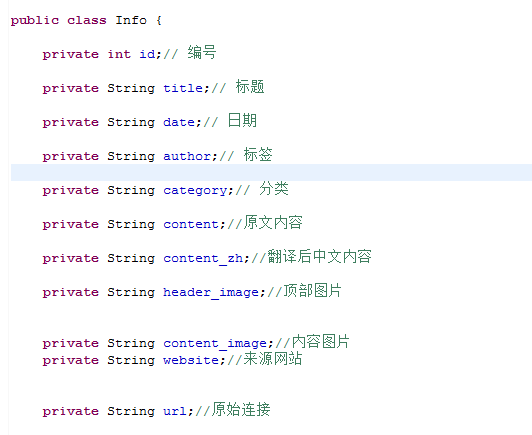
创建 数据库操作dao
public class Dao {
private Connection conn = null;
private Statement stmt = null;
public Dao() {
try {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/webmagic?user=root&password=000000&autoReconnect=true";
conn = DriverManager.getConnection(url);
stmt = conn.createStatement();
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.err.println(e.toString());
} catch (SQLException e) {
e.printStackTrace();
System.err.println(e.toString());
}
}
public int add(Info info) {
System.err.println(info.toString());
try {
String sql = "INSERT INTO `webmagic`.`test` (`id`, `title`, `author`,`date`, `category`, `header_image`, `content_image`, `content`,`content_zh`, `website`, `url`) VALUES (?,?, ?, ?, ?, ?, ?,?,?, ?, ?);";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, info.getId());
ps.setString(2, info.getTitle());
ps.setString(3, info.getAuthor());
ps.setString(4, info.getDate());
ps.setString(5, info.getCategory());
ps.setString(6, info.getHeader_image());
ps.setString(7, info.getContent_image());
ps.setString(8, info.getContent());
ps.setString(9, info.getContent_zh());
ps.setString(10, info.getWebsite());
ps.setString(11, info.getUrl());
return ps.executeUpdate();
} catch (SQLException e) {
System.out.println(e.toString());
e.printStackTrace();
}
return -1;
}
}
其中两部分要注意:
1.mysql连接的 语句 ip+port ,数据库名,用户密码,
当时直接网上抄,竟然是3307 端口,坑了一把。
2.插入SQL 要依次对应上 数据库 和数据库中的表名。
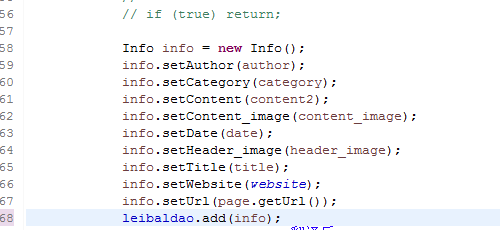
最后在解析数据之后,创建要保存的对象实例。使用dao的实例的add方法添加进去 保存到数据库。
4.其他
- 同一个网站 页面可能有多种 样式,要对比区分,做到兼容。
2.采用设计模式归类 能是结构更清晰,工厂模式、代理模式。
5.补充
2018年4月25日 17:10:41
1.对于 img :src 和img srcset 的曲折路程
部分图片可以直接解析 imgsrc 但是默认不是 质量最佳的图
如


round 1
有些是 默认最佳的图,有些是默认最后一个。于是一开始 就选定srcset中最后一个
代码:
Elements gallery_items = page.select("div[id=gallery-1]").select("[class=gallery-item]");
for (Element item : gallery_items) {
String[] srcset = item.select("[class=attachment-medium size-medium]").attr("abs:srcset").split(",");
// do smt
String url_0 = srcset[srcset.length - 1];
String imgurl = url_0.substring(0, url_0.lastIndexOf(".") + 5).trim();// 考虑到 .jpeg的格式
}
round 2
然后结果却发现 部分图还是很小,结果却发现 竟然有部分 最佳质量图并不是 在srcset 中最后一个,对比发现,大尺寸的图往往是没有 最后的那个尺寸后缀,于是 考虑找到 最短那个就是最佳的图:
if (srcset.length > 0) {
int p = srcset.length - 1;
for (int i = 0; i < srcset.length; i++) {
if (srcset[i].length() < srcset[p].length()) {
p = i;// 记录地址长度最短坐标
}
}
round 3
结果发现还是有部分 很小,对比发现,srcset 中连接都是带尺寸的,大尺寸是800*1280 最大,长度也比别的长了一点,于是还要考虑到 最短长度不是一个的时候。
// 如果 最短的不是最后一个 则下错了 要重新下
if (p != srcset.length - 1) {
// 如果最短的 有共同的长度 其他的 则需要判断最长的
if (p > 0 && srcset[p].length() == srcset[p - 1].length()) {
for (int i = 0; i < srcset.length; i++) {
if (srcset[i].length() > srcset[p].length()) {
p = i;// 记录地址长度最长
}
}
}
else if (p == 0 && srcset[0].length() == srcset[p + 1].length()) {
for (int i = 0; i < srcset.length; i++) {
if (srcset[i].length() > srcset[p].length()) {
p = i;// 记录地址长度最长
}
}
}
String url_0 = srcset[p];
- 部分加载更多使用ajax 没有明确的页码
wordpress 框架 可以直接在分类后加上/page/页码
在这种默认分类 页的head 中有 next 页的 连接

获取和解析方法:
Document doc = page.getDoc();
Elements kwMetas = doc.head().select("link[rel=next]");
String nexturl= "";
if (kwMetas != null && !kwMetas.isEmpty()) {
Element kwMate = kwMetas.first();
nexturl= kwMate.attr("href");
next.add(nexturl);
System.err.println("href---->" + nexturl);
}