Zookeeper 我想大家都不陌生,在很多场合都听到它的名字。它是 Apache 的一个顶级项目,为分布式应用提供一致性高性能协调服务。可以用来做:配置维护、域名服务、分布式锁等。有很多开源组件,尤其是中间件领域,使用 Zookeeper 作为配置中心或者注册中心。它是 Hadoop 和 HBase 的重要组件,是 Kafka 的管理和协调服务,是 Dubbo 等服务框架的注册中心等。
原理
在介绍高可用部署前,我们先了解下 Zookeeper 的基本知识,这对充分理解它的高可用部署非常重要。
架构
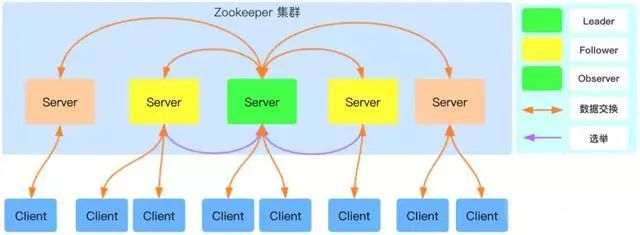
下图是 Zookeeper 的架构图,ZooKeeper 集群中包含 Leader、Follower 以及 Observer 三个角色:
- Leader:负责进行投票的发起和决议,更新系统状态,Leader 是由选举产生;
- Follower: 用于接受客户端请求并向客户端返回结果,在选主过程中参与投票;
- Observer:可以接受客户端连接,接受读写请求,写请求转发给 Leader,但 Observer 不参加投票过程,只同步 Leader 的状态,Observer 的目的是为了扩展系统,提高读取速度。
Client 是 Zookeeper 的客户端,请求发起方。
高可用
Zookeeper 系统中只要集群中存在超过一半的节点(这里指的是投票节点即非 Observer 节点)能够正常工作,那么整个集群就能够正常对外服务
基于此,如果想搭建一个能够允许 N 台机器 down 掉的集群,那么就要部署一个由 2*N+1 台服务器构成的 ZooKeeper 集群。
因此,如果部署了 3 个 Zookeeper 节点(非 Observer),则如果至少有 2个节点可用则整个集群就可用,意味着 1 个节点故障,不影响 Zookeeper 集群对外提供服务;如果部署了 5 个节点,意味着 2 个节点同时故障,Zookeeper 集群依然能够正常对外提供服务。
Zookeeper 集群部署的节点(非 Observer)数一般为奇数个
部署的节点数一般为奇数个,这里不是说不能为偶数个。例如如果部署了 4 个节点,这意味着需要 4/2+1 = 3 个节点正常,集群才能正常对外服务,即可以容忍 1 个节点故障,但是这个部署 3 个节点,其实效果是一样的,也就是说部署偶数个,从高可用方面来说只是浪费了 1 台机器而已。
部署
既然只要 Zookeeper 集群中存在超过一半的节点能够正常工作,集群就能够正常服务,那 Zookeeper 如果想要 Zookeeper 高可用岂不是很简单,是不是多部署几个节点不就好了呢?
多部署节点就高可用了?
多部署节点,貌似确实是能够增强可用性,但是这里还需要考虑以下两个问题:
- 多增加节点对性能和写可用性有影响 增加节点,意味了能够容忍非正常节点数更多,听起来高可用是更高了。但是,节点数越多意味着 Leader 发出的提案需要更多的节点(半数以上)来接受提案,这必然增加提案 commit 的耗时,也就意味着对写请求的性能以及可用性影响比较大。因此,对于正常的业务系统来说需要完美的权衡利弊,来调整节点的个数。
- 需要考虑容灾需求 部署还得结合容灾要求,需要能在机房故障,地区故障时整个 Zookeeper 集群是否能正常对外提供服务。
机房容灾
如果要保证在整个机房出现故障的情况下,保证 Zookeeper 集群的高可用,是要对 Zookeeper 做跨机房部署的。
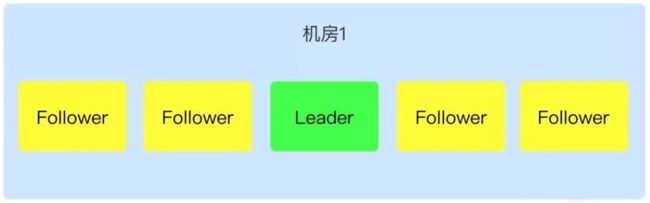
单机房
我们先看下单机房部署情况下,下图是单个机房 5 个节点的部署情况。在单机房部署的情况下是不能做到机房容灾的,一旦机房出现问题,整个 Zookeeper 集群就不能对外工作。
单机房部署还需考虑所选的节点应该尽量不在同一个宿主机,不同机柜,避免多个节点同时出现问题。
同城双机房
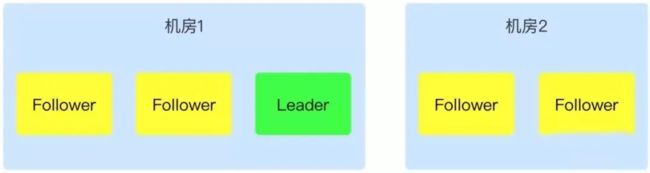
既然单机房做不到机房容灾,那双机房呢?
如下图在“机房 1”部署 3 个节点,“机房 2”部署 2 个节点,总共 5 个节点的 Zookeeper 集群,这能做到机房容灾吗?任意一个机房故障,集群都能正常对外提供工作吗?
其实,还是不行的。假如“机房 2”故障,“机房 1”正常,这种情况下,因为“机房 1”存在 3 个节点,大于半数,因此还是能够正常工作的;但是,假如“机房 1”故障,那存活节点数只有 2 个,整个集群是不能正常工作的。
因此,Zookeeper 双机房部署,是不能够做到机房容灾的。
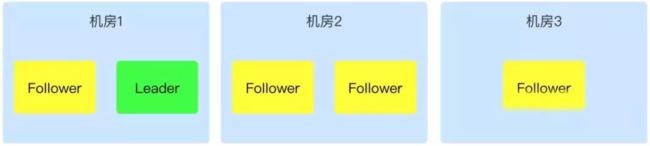
同城三机房
我们再来看看三机房部署,三机房部署,是能够做到机房容灾的。还是以 5 个节点的集群为例:
如下图,在“机房 1”、“机房 2”同时部署 2 个节点,而“机房 3” 部署 1 个节点。在任意一个机房故障的情况下,都能满足正常节点数大于半数及以上,所以能够保证机房容灾。
异地容灾
仅仅做到机房级别的容灾,对于一般的业务应该就够了,不过目前很多公司采用的是两地三中心模式,蚂蚁金服甚至做到了三地五中心。在这种情况下,我们的 Zookeeper 集群应该如何部署呢?
两地三中心
“两地三中心”即生产数据中心、同城灾备中心、异地灾备中心建设方案。这种模式下,两个城市的三个数据中心互联互通,如果一个数据中心发生故障或灾难,其他数据中心可以正常运行并对关键业务或全部业务实现接管。
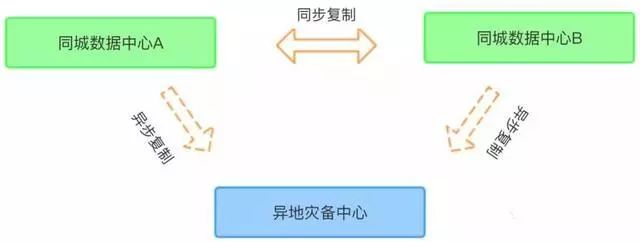
在两地三中心的的模式下,Zookeeper 集群的部署有哪些考量呢?
如下图,一般两地三中心采用的是下面这种部署方式。在“地区 1”有两个同城数据中心,“中心 1”和“中心2”,在异地“地区 2” 有一个异地中心“中心 1”。这里你可能有两个疑问:
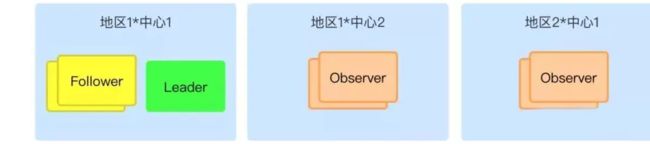
- 为什么投票节点(Follower 和 Leader)都放在“地区 1 中心 1”,而不是按照三机房类似的方案在三个中心都进行部署呢?
- 这里是因为由于异地之间的物理距离比较长,网络传输时延比较大,导致集群的投票节点的决策时间比较长,进而影响写性能。试想一下,如果两地选用的是北京和上海两座城市,走专线网络延时约 30ms,在写数据时,需要半数节点同意提案,一个写请求才能成功。因此,一次写成功的时间会比较长。 另外,异地之间的网络比较复杂,很容易出现集群重新选举,导致整个集群不可用,而且选举时间会比较长。 因此,一般只在一个中心内做到三机房部署,其他中心都是用 Observer 节点,可以看出,部署上 Zookeeper 集群无法做到异地容灾的。
- 为什么引入了 Observer 节点?
- Observer 能很好的对 Zookeeper 集群进行扩展,Observer 可以提供 Client 读写,但不参与投票。因此,Observer 节点对集群不影响投票耗时,也不影响集群选举。另外,加入 Observer 对读性能是一个很大的提升。
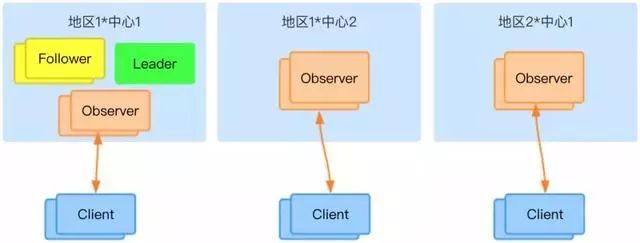
三中心优化
为了保护集群,在三个中心都部署上 Observer 节点,而 Client 只与 Observer 机点进行交互,用这种方式可以降低投票节点的工作负载,降低 Leader 和 Follower 的不稳定性,从而提高整个集群的稳定性和可用性。
总结
Zookeeper 的高可用在部署上也是有很多考量的,Zookeeper 集群在部署上可以做到机房容灾,但是做不到异地容灾。另外,为了提升集群的扩展性和稳定性,可以引入 Observer 节点,提升读性能,保护 Leader 与 Follower 节点。
共同进步,学习分享
欢迎大家关注我的公众号【风平浪静如码】,海量Java相关文章,学习资料都会在里面更新,整理的资料也会放在里面。
觉得写的还不错的就点个赞,加个关注呗!点关注,不迷路,持续更新!!!
