一、基本概念
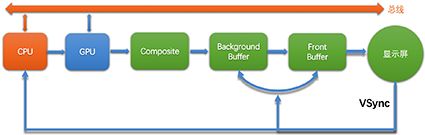
Android系统每隔16ms发出VSYNC信号,触发对UI进行渲染,如果每次渲染都成功,这样就能够达到流畅的画面所需要的60fps,这也意味着程序的大多数操作都必须在16ms内完成。如果无法完成,则发生丢帧,上一帧画面被重复显示,造成卡顿的视觉。

从整个视图渲染流程看:
Surfaceflinger由init启动的独立进程,提供合成视图的系统服务。如果Surfaceflinger挂掉,会重启zygote。
在Surfaceflinger的init方法中,实例化了HWComposer和两个EventThread。
HWComposer:负责输出硬件产生或软件模拟的Vsync信号。
EventThread:负责分发vsync到Choreographer和SurfaceFlinger。其中mEventThread对应Choreographer;而mSFEventThread:对应SurfaceFlinger。
VSYNC信号主要的两个订阅者:SurfaceFlinger 和 Choreographer。
SurfaceFlinger:接收信号执行合成Layer流程。
Choreographer:接收信号来控制同步处理输入(Input)、动画(Animation)、绘制(Draw)三个UI操作。
Choreographer通知应用层绘制、SurfaceFlinger负责合成视图、两者之前加上了一定的offset,这样能保证两者步调一致。
在这个过程中,CPU负责把视图加工为多边形和纹理。GPU负责把多边形和纹理做栅格化处理,成为送显的像素数据。
二、造成卡顿的原因
应用层面:
1 视图层面的问题
包括layout层级太深View太多、View太复杂、重复绘制、ListView没优化、动画设计不合理等等。
这是遇到卡顿问题首先需要排查的,部分问题可以通过开发阶段的coding规范来避免的。
1)layout层级太深View太多:可以通过Lint来检测,优化:通过合理容器的使用,优先减少层级,其次减少View数目,能重用的尽量重用。
2)View太复杂:如果是自定义View,那还是从视图太深、View太多两个层面来考虑优化。如果是成熟的View:比如WebView、VideoView这种重量级的View,尽量复用和管理好生命周期。
3)重复绘制:通过Settings中打开GPU过度绘制 & GPU呈现模式可以了解当前视图层级关系,当然这部分与前面两点也是分不开的,最基本的要注意移除xml中非必须背景。
4)ListView优化,这部分主要是convertView的复用,能减少View的创建;ViewHolder的使用,减少View的find和赋值,加快加载速度;分页加载:控制一次加载的数据量,这样加载速度会快,内存压力也相对小。
5)动画:合理设计动画,能不用帧动画尽量不用,因为图片比较占内存,尤其是数量多的时候。另外针对属性动画,同一个view的一系列动画,可以使用Keyframe+PropertyValuesHolder组合方式达到只使用一个ObjectAnimator,多个view的动画用AnimatorSet进行动画组合和排序。
2 消息相关耗时
我们都知道,耗时操作放到子线程做,通过handle返回主线程更新UI。但是消息本身也是会耗时的,主要分两方面:1)消息本身执行耗时, 2)消息执行被delay。消息本身执行耗时那就是主线程耗时,消息执行被delay,在messageQueue中,由于之前的Message太多或者执行时间过长,导致当前需更新UI的操作得不到及时处理,尤其是16.6ms硬性标准下,一旦delay必然丢帧。
3 主线程耗时
这部分我要说的并不是在主线程做耗时操作了,而是站在CPU调度的角度来看耗时问题,也就是说,比如主线程有500ms的耗时,要么Running了多久,是否存在Sleeping和Uninterruptible sleep等状态,这段时间内CPU被抢占了压根就没腾出功夫来执行你这操作。如果有现场的话,通过抓systrace能比较明显看出来。
4 Input事件本身耗时
在Android整个Input体系中有三个重要的成员:Eventhub,InputReader,InputDispatcher。它们分别担负着各自不同的职责,Eventhub负责监听/dev/input产生Input事件,InputReader负责从Eventhub读取事件,并将读取的事件发给InputDispatcher,InputDispatcher则根据实际的需要具体分发给当前手机获得焦点实际的Window,最终交给ActivityThread通过消息来处理。
系统角度:
InputDispatcher分发事件给Window这个过程是跨进程通信,获取对应window本身可能存在耗时。
应用角度:
客户端接收事件的消息本身又可能存在耗时和delay的情况,这又回到消息耗时的范畴了。
5 持锁耗时
这属于业务逻辑层面的问题,最简单的就是主线程死锁,亦或是主线程在等锁,然后当前锁被其他线程持有在做耗时操作等等。
6 频繁GC
我们知道,执行GC操作的时候,所有线程的任何操作都会需要暂停,等待GC操作完成之后,其他操作才能够继续运行。通常来说,单个的GC并不会占用太多时间,但是大量不停的GC操作则会显著占用帧间隔时间(16ms)。如果在帧间隔时间里面做了过多的GC操作,那么自然其他类似计算,渲染等操作的可用时间就变得少了。
导致GC频繁执行有两个原因:
1)内存抖动,在memory monitor里能很明显看出来,短时间内创建大量对象然后又迅速被释放。

比如:在一个方法里for循环拼接String。会产生大量废弃的String对象,短时间内又会被回收,所以容易造成抖动,可以用StringBuilder/StringBuffer来替代,它们实现是动态数组,初始长度128,不够用了通过arraycopy来增加长度。对象统一管理,不会短时间内造成短时间内大量创建和销毁的问题,同时append与+相比更安全。
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
2)瞬间产生大量的对象会严重占用Young Generation的内存区域,当达到阀值,剩余空间不够的时候,也会触发GC。即使每次分配的对象占用了很少的内存,但是他们叠加在一起会增加Heap的压力,从而触发更多其他类型的GC。这个操作有可能会影响到帧率,并使得用户感知到性能问题。
系统层面:
1 内存原因
在系统内存非常低的情况下,常规经验是:MemAvailable 低于MemTotal 1/10的情况下,容易出现内存引起的卡顿,原因无非就是在内存低的情况下内核在分配内存时,很难从物理内存(伙伴系统)直接拿到合适大小的页面,此时会触发回收操作,如内存整理(compact)、回收匿名页(swap)、回收文件页(dirty=回写,clean=丢弃)等操作。这些回收操作较慢,因此耗时。这个过程主要体现在新启一个应用,zygote fork进程申请内存的时候。
2 系统服务持锁耗时
应用binder call请求系统服务,一般来说,系统服务如AMS、WMS对应的方法,一上来先不管三七二十一,就是一把大锁,很多情况下,特定的操作会造成持锁耗时的情况,具体问题具体分析。
3 CPU调度问题
这类情况不太多见,但是也是存在的。在某个绘制周期中,CPU被抢占,无法及时开始绘制操作。这分几部分来看,首先是不是被某个进程抢占的,比如dex2oat。或者看这段时间CPU使用率非常高,但是可能是大核跑满了,但是小核相对比较闲,这属于系统调度有问题等等。
例如:dex2oat发生的时候,占用所有有CPU(默认策略是有多少个核,就启动多少个线程),会将原文件中的dex文件抽出来,逐个指令的判断,然后进行翻译,并生成大量的中间内容,这些在memory当中是保存不下的,所以采用了swap机制, memory越少,越容易发生交换,所以还可能引起IO上的瓶颈。
可以设置系统属性:dalvik.vm.bg-dex2oat-threads 和 dalvik.vm.dex2oat-threads ,这两个系统属性是分别设置在前后台执行dex2oat限制的线程数,对应8核CPU来说,比如设置前后台分别为4,这样dex2oat执行时间会变长,但是卡顿会被缓解。
当然还有一种情况是,当手机温度过高,导致CPU降频,也会出现系统卡顿。
本文只是对卡顿分析提供一点不成熟的小思路。随着学习的深入,我会持续更新。
文中牵涉到的布局和重复绘制相关的内容可以参考我的文章:布局优化
文中牵扯到的相关性能优化工具可以参考我的系列文章:性能优化工具篇总结