上这个博文分析的挺好:
http://www.jianshu.com/p/aad5aacd79bf
下面是我自己关注的一些点而已:
ConnectionPool : 连接池
相同地址的连接, 有可能会复用.
首先注意到的是SynchronousQueue的使用, 这是一个同步队列, 没有容量, 如果同时有多个或者一个线程往队列中添加数据, 那么都会阻塞, 不管是一个还是多个线程, 知道有一个消费者线程会从队列中取(poll)数据, 这是根据是否公平的设置, 会把前面那几个线程中的一个解除阻塞, poll出的数据就是那个线程要放进队列的数据, 这样一个生产者线程和一个消费者线程都离开了.
同样, 如果有多个线程都要poll数据, 那么这几个线程也要排队请求, 可能公平, 可能不公平, 这个策略是在创建SynchronousQueue时传如的唯一boolean参数决定的.
好了 , 那么在这里SynchronousQueue的用处是什么呢?
具体是为了实现一个newCachedThreadPool, 具体原理跟线程池新建线程的策略有关, 可以阅读: http://dongxuan.iteye.com/blog/901689
简单来说使用SynchronousQueue的原因就是为了使生产者无法往队列中添加数据, 从而促使线程池产生新的消费线程, 并且保证了添加到队列中的任务(runnable)的开始执行的顺序.
但是这里new出来的线程池跟 Executors.newCachedThreadPool()方式创建出来的线程池, 在我看来没有任何区别.
另外为什么要创建一个线程池来执行后台cleanup工作? 真的有此必要吗?
这个线程池对象只处理这么一个任务:cleanupRunnable 并且还只处理一次. why? 为什么要用线程池??
猜测可能的好处: 方便的创建后台执行的线程, 设置线程名字;
ConnectionPool.put()是实例方法, 也就是说如果有多个地方创建了不同的ConnectionPool对象, 那么会有对应的多个cleanupRunnable任务对象, 都会添加到静态实例executor线程池中.
这是一个多对1的关系.
终于明白用线程池的原因了, 对于每个连接池对象ConnectionPool 在某些时刻, cleanupRunnable是可以停止运行的, 比如长时间没有连接了, 我还cleanup个毛了, 也就自己停止运行了:
具体代码逻辑:
 ...
 这个cleanup方法返回-1 标志这可以停止运行cleanupRunnable任务了; 上这个博文分析的挺好:
http://www.jianshu.com/p/aad5aacd79bf
http://blog.csdn.net/qq_31694651/article/details/52463078
对比glide和picasso的使用:
http://www.jianshu.com/p/fc72001dc18d
下面是我自己关注的一些点而已:
ConnectionPool : 连接池
相同地址的连接, 有可能会复用.
首先注意到的是SynchronousQueue的使用, 这是一个同步队列, 没有容量, 如果同时有多个或者一个线程往队列中添加数据, 那么都会阻塞, 不管是一个还是多个线程, 知道有一个消费者线程会从队列中取(poll)数据, 这是根据是否公平的设置, 会把前面那几个线程中的一个解除阻塞, poll出的数据就是那个线程要放进队列的数据, 这样一个生产者线程和一个消费者线程都离开了.
同样, 如果有多个线程都要poll数据, 那么这几个线程也要排队请求, 可能公平, 可能不公平, 这个策略是在创建SynchronousQueue时传如的唯一boolean参数决定的.
好了 , 那么在这里SynchronousQueue的用处是什么呢?
具体是为了实现一个newCachedThreadPool, 具体原理跟线程池新建线程的策略有关, 可以阅读: http://dongxuan.iteye.com/blog/901689
简单来说使用SynchronousQueue的原因就是为了使生产者无法往队列中添加数据, 从而促使线程池产生新的消费线程, 并且保证了添加到队列中的任务(runnable)的开始执行的顺序.
但是这里new出来的线程池跟 Executors.newCachedThreadPool()方式创建出来的线程池, 在我看来没有任何区别.
另外为什么要创建一个线程池来执行后台cleanup工作? 真的有此必要吗?
这个线程池对象只处理这么一个任务:cleanupRunnable 并且还只处理一次. why? 为什么要用线程池??
猜测可能的好处: 方便的创建后台执行的线程, 设置线程名字;
ConnectionPool.put()是实例方法, 也就是说如果有多个地方创建了不同的ConnectionPool对象, 那么会有对应的多个cleanupRunnable任务对象, 都会添加到静态实例executor线程池中.
这是一个多对1的关系.
终于明白用线程池的原因了, 对于每个连接池对象ConnectionPool 在某些时刻, cleanupRunnable是可以停止运行的, 比如长时间没有连接了, 我还cleanup个毛了, 也就自己停止运行了:
具体代码逻辑:
[图片上传中。。。(1)] ...
[图片上传中。。。(2)] 这个cleanup方法返回-1 标志这可以停止运行cleanupRunnable任务了; [图片上传中。。。(3)]
如上图的return, 也就停止了运行. 但以后如果还有新的连接connection对象生成了, 那么这个任务又得重新新建, 并放到线程池中运行.
这么一停 一起 的操作 , 非常适合在线程池中实现.
这个ConnectionPool更像是一个cache, 因为创建新Connection的操作不在get()操作中.
缓存
跟glide这种图片库不同, okhttp的缓存是基于http协议标准的, 主要是通过header字段, 和返回码来决定的, ---------这个地方需要确认, 好像也不是这么回事
所以, 重点是协议的逻辑. 准备买本http的书好好补充下基础知识
----------------责任链模式
不同interceptor会有不同的处理方式, 可以选择让下一个intercepter先执行, 比如retryAndFollowUpInterceptor 只是静观其变, 它要等待其他人处理完之后在决定是否需要重试.
也可以选择先把请求处理一番, 比如bridgeInterceptor, 会把原始请求封装成一个包含http header的具体http请求.
也有的直接决定终止责任链的传递, 比如CacheInterceptor, 当它发现可以直接使用缓存数据时, 就直接返回缓存数据, 没有必要继续往下了, 因为往下可能就真的去联网了.
为什么Dispatcher类中用了一堆Deque, ArrayDeque 为什么? 这比ArrayList有什么优势吗? 目前还想不明白.
--------------问题
OkHttpClient对象是单例吗? 那么ConnectionPool是单例吗?
可以自己封装成单例. ConnectionPool对象与OkHttpClient对象是一对一的.StreamAllocation 与Connection 对象应该是多对一的关系, 一个connection可以被多个StreamAllocation对象引用. 而同时在 connection内部也有一个虚引用列表, 记录了所有引用自己的StreamAllocation对象, 当这个列表为空时 , 说明是空闲的.
在缓存这块对DiskLruCache的使用基本上就是用FileSystem替换了原始的java.io
如上图的return, 也就停止了运行. 但以后如果还有新的连接connection对象生成了, 那么这个任务又得重新新建, 并放到线程池中运行.
这么一停 一起 的操作 , 非常适合在线程池中实现.
这个ConnectionPool更像是一个cache, 因为创建新Connection的操作不在get()操作中.
缓存
跟glide这种图片库不同, okhttp的缓存是基于http协议标准的, 主要是通过header字段, 和返回码来决定的, ---------这个地方需要确认, 好像也不是这么回事
所以, 重点是协议的逻辑. 准备买本http的书好好补充下基础知识
----------------责任链模式
不同interceptor会有不同的处理方式, 可以选择让下一个intercepter先执行, 比如retryAndFollowUpInterceptor 只是静观其变, 它要等待其他人处理完之后在决定是否需要重试.
也可以选择先把请求处理一番, 比如bridgeInterceptor, 会把原始请求封装成一个包含http header的具体http请求.
也有的直接决定终止责任链的传递, 比如CacheInterceptor, 当它发现可以直接使用缓存数据时, 就直接返回缓存数据, 没有必要继续往下了, 因为往下可能就真的去联网了.
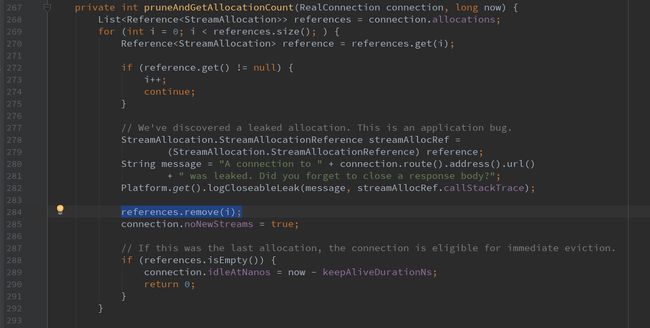
上图284行这个位置, 很是疑问, 这种形式的for循环中就这么删除一个元素, 然后还可能继续循环, 继续删除, 这看起来是个错误啊. 但是这么有名的项目, 不可能犯这种错误, 但我就是想不明白为什么这么用/!!!!!
为什么Dispatcher类中用了一堆Deque, ArrayDeque 为什么? 这比ArrayList有什么优势吗? 目前还想不明白.
--------------问题
OkHttpClient对象是单例吗? 那么ConnectionPool是单例吗?
可以自己封装成单例. ConnectionPool对象与OkHttpClient对象是一对一的.StreamAllocation 与Connection 对象应该是多对一的关系, 一个connection可以被多个StreamAllocation对象引用. 而同时在 connection内部也有一个虚引用列表, 记录了所有引用自己的StreamAllocation对象, 当这个列表为空时 , 说明是空闲的.
在缓存这块对DiskLruCache的使用基本上就是用FileSystem替换了原始的java.io