本文是在Optaplanner创始人 Geoffrey De Smet先生的一篇文章《Formula for measuring unfairness》的基础上进行翻译而成。因为其博文发表在Optaplanner的官网上,因此,其行文过程中存在一定的上下文默认情况,如果直译原文,将会大大降低其可读性。因此,本文是在原文的基础上添加一些本人修饰的表达而成。
负载均衡在Optapalnner的应用案例中是一种极为常见的约束,特别是做一些人员排班等场景,各人的工作量需要尽可能公平分配。但是,说起来容易做起来难。本篇让我们来研究一下这个具挑战性的问题。
本文中,我们使用以下案例:有15个烦人的任务,需要分配给5个员工,每个任务需时1天来完成,且每个任务都有不同的人员技能要求。
何谓公平?
我们先来看看两个关于公平,但又对立的定义:
- 如果大多数员工都认为对自己公平的,那这个方案就是公平的。
- 对于分得最多任务的员工而言,其所分的任务越少,则这个安排就越公平。(即越平均越公平)
很显然,因为我们想将方案调整到对所有人都是平等,第2个定义更正确。此外,如果为了让几乎所有人都高兴,我们把所有任务都分配给一个人(例如都分给阿Ann),那么她很可能马上就走人了。因此,这种想法不可行。如下表:

按公平性对各个方案进行排序
我们来看看同一问题下的若干任务分配方案,都是15个烦人的任务:
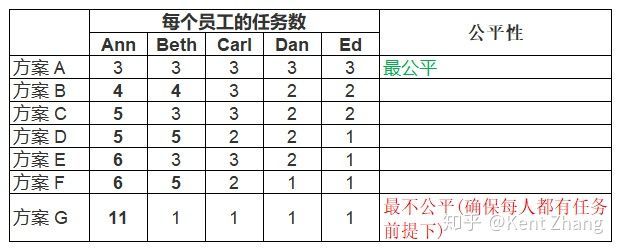
以上是将7个方案的公平程度,从高到低排列。也许这些方案有些是不可行的,因为有些任务是有特定的技术要求。从上表可以看出,所有方案中,阿Ann都满足"分到最多任务"的条件。那么,我们如何对比阿Ann具有相同任务数的两个不同方案呢?
我们截取阿Ann的任务数相同的两个方案(C和D)如下表:

在这种情况下,我们看看除最不公平的Ann以外,正处于第二不公平的员工Beth的任务分配情况, 在此基础上,我们最小化她的任务,按照公平定义的第2条,因阿Ann的任务任务数在两个方案中不变,这两个方案中,对于分得第二多任务的Beth,若分得的任务越少,则越公平。
综上,我们找到了公平性的定义 - 尽可能平均,那么我们应该如何实现它呢?
衡量公平的方式
理想情况下,我们想通过计算出一个惩罚性分值,用于衡量一个方案的公平性。分值越低越公平。我们应该如何计算这个分值呢?我们先来看看一些公式。
离均差
因为在完美公平的分配方案中,所有的员工分得的任务数是平均的,如果我们简单地加总每个员工的任务数,再与均值对比,会怎么样?
我们先看看绝对离均差与平均离均差两个公式,并对上表的各个方案进行,使用这两个公式进行计算:
绝对离均差:

平均离均差:

两个衡量公式计算出来的结果如下:
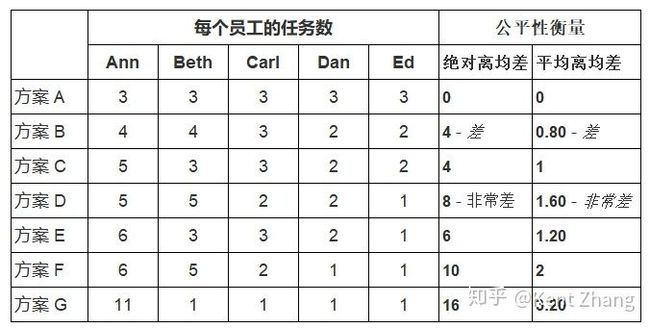
上表的测量结果相当糟糕。在表中:
- 对比方案B与方案C(两个方案的公式计算结果值一样),它们公平性一样吗?不是的,因为两个方案中,各人的任务数不同。
- 再对比方案D与方案E,前者两公式的计算结果都比后者高,那么方案D真的比方案E差吗?也不是的,问一下阿Ann就知道了,方案E中她竟然分得6个任务。
方差与标准差
在统计学上,方差与标准差用于计算数据的离散程度。听起来好像正满足我们需求,我们来看看相关公式:
方差:

标准差:

离均差的平方:
 方差乘以n
方差乘以n
离均差的平方根:

四种公式的计算结果:

上表可见,这四个公式对于公平性衡量结果已经不错,但仍未够理想。例如按4个公式计算结果一致的方案D和E,理论上应该是具有相同的公平程度的,但事实上这两个方案公平性并不一致。
最大值
如果我们对每个方案中,取最大任务数,作为公平性的衡量标准会怎么样呢?
其公式应该是:

那么应用于7个方案,其结果是:

这种衡量方式比方差还糟,它只关注一个员工(任务数最大那个)。因此,这种方式完全抛弃了员工之间的公平性。如果只是针对一个员工衡量其公平性还可行,但当对数据众多的员工一起衡量时就不行了。
任务数列
如果我们不使用任何公式作为公平性衡量标准,我们把所每个方案中,每个员工的任务数都列出来,形成一个任务数的数列,并从小到大把这数列排序,会怎么样?

从上表可以看,可以完美地对比各方案的公平性!那么在Optaplanner里要实现这种衡量方式,我们需要针对每个员工定一个分数级别,Optaplanner会按分数级别进行排序,来找最佳方案。但是,如果我们需要排的员工数量非常大呢?要实现这种衡量方式,除了在运行过程要消耗大量的内存外,如此大数量的评价级别,会与其它约束产生冲突,也难以实现。
不存在单独的约束
在规划问题中,公平性是一种典型的软约束。但在同一个规划问题中,同时存在其它软约束,这些约束也是需要进行优化考虑的。因此,我们需要为这些约束添加相应的权重,令它们互相制衡。
举例
例如同样是上述的任务分配规划问题,存在一个称为优先级约束,它的重要性是10倍于公平性约束。我们再往这个问题中添加1500个任务,我们看看其分配方案开来是怎样的:
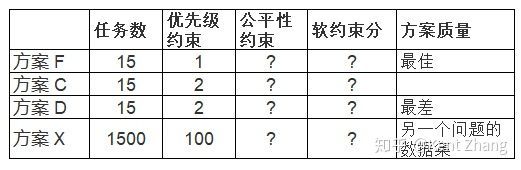
计算软约束分数时,我们把公平性约束分数乘以5倍并加总,再取负。
接下来我们开始处理:
用单一数值表示
每个方案的任务数列并不代表一个单独的数值,因为这个数列中的每个数,对应于不同的评分级别。因此,任务数列无法跟优先级约束进行综合评价。如下表:

惩罚分数随着违反次数的增长而增长
如何我们将问题扩展到1500个员工,我们会发现,若取最大任务数作为约束,则该约束会被优先级约束矮化。

类似地,平均离均差、方差及标准差等衡量方式,其公平性,也会随着数量(即问题规模,通过任务与员工的数量体现)增大,而被矮化。如下表:

因此,随着公平性约束违反量的增多,衡量公平性的比重也应该随之增大。
公平性违反比重,不能随着违反量的增大而逞指数式增长
另一方面,当数据量增大时,公平性的违反比重不能对其它的约束起到矮化作用。如果使用方差作为衡量方式则会出现此情况,见下表。

结论
对于上述讨论到的公平性衡量方式:
- 绝对离均差作为公平性衡量方式时效果最差。
- 离均差的平方根作为公平性衡量方式,未尽完美但够用。
因此,推荐的方法是离均差的平方根::
其效果见下表:

补充说明
处理的问题中,若存在非均等员工时。例如,有些员工的工作时候只有其它员工的一半,在将其代入公式计前,需要将他们可分配的任务数乘上他们FTP(full time equivalent,全职时间等价值)的倒数。其它需要考虑非均待员工的因素(例如残疾或人才保留对象),也可以使用类似的方法,或使用一些单独的约束进行区分,具体办法需视现实的业务需求而定。
原文地址:
Formula for measuring unfairness
或到讨论组发表你的意见:https://groups.google.com/forum/#!forum/optaplanner-cn
若有需要可添加本人微信(13631823503)或QQ(12977379)实时沟通,但因本人日常工作繁忙,通过微信,QQ等工具可能无法深入沟通,较复杂的问题,建议以邮件或讨论组方式提出。(讨论组属于google邮件列表,国内网络可能较难访问,需自行解决)