前言
本文让我们来聊聊匿名共享内存Ashmem。Ashmem为什么会诞生?共享内存本质上还是为了方便跨进程通信,减少拷贝次数,提高性能。
遇到问题可以来本文讨论https://www.jianshu.com/p/6a8513fdb792
但是我们Android不是已经有了Binder这个跨进程通信利器吗?为什么还需要匿名共享内存?让我们先看看Binder初始化时候这行代码。
文件:/frameworks/native/libs/binder/ProcessState.cpp
#define BINDER_VM_SIZE ((1 * 1024 * 1024) - sysconf(_SC_PAGE_SIZE) * 2)
ProcessState::ProcessState(const char *driver)
: mDriverName(String8(driver))
, mDriverFD(open_driver(driver))
, mVMStart(MAP_FAILED)
, mThreadCountLock(PTHREAD_MUTEX_INITIALIZER)
, mThreadCountDecrement(PTHREAD_COND_INITIALIZER)
, mExecutingThreadsCount(0)
, mMaxThreads(DEFAULT_MAX_BINDER_THREADS)
, mStarvationStartTimeMs(0)
, mManagesContexts(false)
, mBinderContextCheckFunc(NULL)
, mBinderContextUserData(NULL)
, mThreadPoolStarted(false)
, mThreadPoolSeq(1)
{
if (mDriverFD >= 0) {
// mmap the binder, providing a chunk of virtual address space to receive transactions.
mVMStart = mmap(0, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0);
...
}
}
能看到应用在初始化Binder的时候,已经限制了大小为1M-2页(1页=4k)的大小也就是1016k大小,如果只是传输命令的话还可以,但是要传输图像数据这个大小根本不够。
加上Binder内部有对每一个Binder内核缓冲区有自己的调度算法,没办法满足以最快的速度传输到SF进程中。也因此,Android选择使用共享内存的方式传递数据,也就是Ashmem匿名内存。
正文
其实Ashmem不仅仅只是内核中能够使用,其实在Java层Android也提供了一个名为MemoryFile的类提供方便使用匿名共享内存,本次就以MemoryFile为切口,来聊聊Ashmem匿名内存的使用。
老规矩,先来看看MemoryFile是如何使用的。
MemoryFile memoryFile = null;
try{
//构建一个共享内存
memoryFile = new MemoryFile("test",1024*5);
OutputStream o = memoryFile.getOutputStream();
byte[] bs = new byte[1024];
bs[0] = 1;
//写入
o.write(bs,0,1);
o.flush();
//读出
InputStream in = memoryFile.getInputStream();
int r = in.read(bs,0,1);
Log.e("r","r:"+bs[0]);
}catch(Exception e){
e.printStackTrace();
}finally {
if(memoryFile != null){
memoryFile.close();
}
}
能看到操作和普通的File操作一模一样,好像根本没有什么区别。File本身也可以作为数据中转站做传递信息。那么MemoryFile比起普通的File优势强在哪里呢?接下来,让我们剖析一下源码,来比较看看匿名内存和File相比有什么区别,和Binder驱动又有什么区别。
MemoryFile源码解析
MemoryFile的创建
文件:/frameworks/base/core/java/android/os/MemoryFile.java
public MemoryFile(String name, int length) throws IOException {
try {
mSharedMemory = SharedMemory.create(name, length);
mMapping = mSharedMemory.mapReadWrite();
} catch (ErrnoException ex) {
ex.rethrowAsIOException();
}
}
能看到实际上MemoryFile内部有一个核心的类SharedMemory作为核心操作类。我们去看看SharedMemory创建了什么东西。
文件:/frameworks/base/core/java/android/os/SharedMemory.java
public static @NonNull SharedMemory create(@Nullable String name, int size)
throws ErrnoException {
...
return new SharedMemory(nCreate(name, size));
}
private SharedMemory(FileDescriptor fd) {
...
mFileDescriptor = fd;
mSize = nGetSize(mFileDescriptor);
..
mMemoryRegistration = new MemoryRegistration(mSize);
mCleaner = Cleaner.create(mFileDescriptor,
new Closer(mFileDescriptor, mMemoryRegistration));
}
SharedMemory首先通过nCreate在native下创建一个文件描述符,并且关联到到SharedMemory,通过nGetSize获取当前共享内存大小,最后通过MemoryRegistration把当前大小注册到Java 虚拟机中的native堆栈大小中,初始化Cleaner等到合适的时候通过gc联动Cleaner销毁native下的对象。
private static final class MemoryRegistration {
private int mSize;
private int mReferenceCount;
private MemoryRegistration(int size) {
mSize = size;
mReferenceCount = 1;
VMRuntime.getRuntime().registerNativeAllocation(mSize);
}
public synchronized MemoryRegistration acquire() {
mReferenceCount++;
return this;
}
public synchronized void release() {
mReferenceCount--;
if (mReferenceCount == 0) {
VMRuntime.getRuntime().registerNativeFree(mSize);
}
}
}
MemoryRegistration 本质上就是注册了Java虚拟机中native堆的大小,每一次一个引用都有一次计数,只有减到0才销毁,毕竟这是共享内存,不应该完全由Java虚拟机的GC机制决定
那么其核心毕竟就是nCreate这个native方法,接着会通过mapReadWrite
nCreate构建native下层的共享内存
文件: /frameworks/base/core/jni/android_os_SharedMemory.cpp
static jobject SharedMemory_create(JNIEnv* env, jobject, jstring jname, jint size) {
const char* name = jname ? env->GetStringUTFChars(jname, nullptr) : nullptr;
int fd = ashmem_create_region(name, size);
int err = fd < 0 ? errno : 0;
if (name) {
env->ReleaseStringUTFChars(jname, name);
}
....
return jniCreateFileDescriptor(env, fd);
}
终于看到了,匿名共享内存相关的字眼,通过ashmem_create_region,创建一个共享内存的区域。还记得Linux中那句话,一切皆为文件,实际上匿名共享内存创建出来也是一个文件,不过因为是在tmpfs临时文件系统才叫做匿名的。最后创建java的文件描述符对象并和fd关联起来。
接下来让我们看看cutils中ashmem_create_region做了什么封装。
文件:/system/core/libcutils/ashmem-dev.cpp
int ashmem_create_region(const char *name, size_t size)
{
int ret, save_errno;
int fd = __ashmem_open();
if (fd < 0) {
return fd;
}
if (name) {
char buf[ASHMEM_NAME_LEN] = {0};
strlcpy(buf, name, sizeof(buf));
ret = TEMP_FAILURE_RETRY(ioctl(fd, ASHMEM_SET_NAME, buf));
...
}
ret = TEMP_FAILURE_RETRY(ioctl(fd, ASHMEM_SET_SIZE, size));
...
return fd;
...
}
创建匿名共享内存分为三个步骤:
1.__ashmem_open 创建匿名共享内存
2.通过ioctl 给匿名共享内存命名,只有命名了才能通过命名找到对应的匿名共享内存。
3.ioctl通过ASHMEM_SET_SIZE命令设置匿名共享内存的大小
__ashmem_open
这个方法最终会调用到如下的方法:
#define ASHMEM_DEVICE "/dev/ashmem"
static int __ashmem_open_locked()
{
int ret;
struct stat st;
int fd = TEMP_FAILURE_RETRY(open(ASHMEM_DEVICE, O_RDWR | O_CLOEXEC));
if (fd < 0) {
return fd;
}
ret = TEMP_FAILURE_RETRY(fstat(fd, &st));
if (ret < 0) {
int save_errno = errno;
close(fd);
errno = save_errno;
return ret;
}
if (!S_ISCHR(st.st_mode) || !st.st_rdev) {
close(fd);
errno = ENOTTY;
return -1;
}
__ashmem_rdev = st.st_rdev;
return fd;
}
终于看到了,类似于Binder驱动的打开方式一样,通过/dev/ashmem的方式访问ashmem驱动的file_operation的open方法,最后获得对应的文件描述符fd。
在这这里先停下来,只要记住Ashmem创建三个步骤:
- 1.open /dev/ashmem驱动连通ashmem驱动
- 2.ioctl 发送ASHMEM_SET_NAME命令为该ashmem创建名字
- 3.ioctl通过ASHMEM_SET_SIZE命令设置匿名共享内存的大小
ShareMemory.mapReadWrite创建内存映射缓存区
ShareMemory当创建好ashmem匿名共享内存之后,将会调用mapReadWrite
public @NonNull ByteBuffer mapReadWrite() throws ErrnoException {
return map(OsConstants.PROT_READ | OsConstants.PROT_WRITE, 0, mSize);
}
public @NonNull ByteBuffer map(int prot, int offset, int length) throws ErrnoException {
checkOpen();
validateProt(prot);
...
long address = Os.mmap(0, length, prot, OsConstants.MAP_SHARED, mFileDescriptor, offset);
boolean readOnly = (prot & OsConstants.PROT_WRITE) == 0;
Runnable unmapper = new Unmapper(address, length, mMemoryRegistration.acquire());
return new DirectByteBuffer(length, address, mFileDescriptor, unmapper, readOnly);
}
能看到map方法最终会调用 Os.mmap。其实这个方法的本质就是调用系统调用mmap。这里面的意思就是调用Ashmem对应的文件描述符mmap方法,也就是会调用Ashmem驱动中file_ops中的mmap方法,最后会直接映射一段逻辑上的虚拟内存和文件file关联起来。当系统正式访问这一段虚拟内存,如果找不到就会触发缺页中断(或者尝试的从磁盘执行物理页的换入换出),此时就会把这一段逻辑绑定的虚拟内存和file正式映射到物理内存。
通过这种常规的mmap,让用户态的虚拟内存直接和物理内存映射起来,就能通过0次拷贝的方式映射起来。是否是这样,我们稍后来看看。
同时在DirectByteBuffer设置解开映射的回调Unmapper
private static final class Unmapper implements Runnable {
private long mAddress;
private int mSize;
private MemoryRegistration mMemoryReference;
private Unmapper(long address, int size, MemoryRegistration memoryReference) {
mAddress = address;
mSize = size;
mMemoryReference = memoryReference;
}
@Override
public void run() {
try {
Os.munmap(mAddress, mSize);
} catch (ErrnoException e) { /* swallow exception */ }
mMemoryReference.release();
mMemoryReference = null;
}
}
能看到如果通过mMemoryRegistration察觉到引用计数为0,就会调用munmap解映射。因此我们可以推敲出,MemoryFile将会以mapReadWrite产生出来的mMapping为基准,不断的从这一段虚拟内存读写。让我们来看看MemoryFile的读写方法。
MemoryFile写入数据
写入操作能看到就是获取MemoryFile的OutputStream对象进行操作。
private class MemoryOutputStream extends OutputStream {
private int mOffset = 0;
private byte[] mSingleByte;
@Override
public void write(byte buffer[], int offset, int count) throws IOException {
writeBytes(buffer, offset, mOffset, count);
mOffset += count;
}
@Override
public void write(int oneByte) throws IOException {
if (mSingleByte == null) {
mSingleByte = new byte[1];
}
mSingleByte[0] = (byte)oneByte;
write(mSingleByte, 0, 1);
}
}
能看到在write方法中,本质上还是调用writeBytes作为核心写入方法。
private void beginAccess() throws IOException {
checkActive();
if (mAllowPurging) {
if (native_pin(mSharedMemory.getFileDescriptor(), true)) {
throw new IOException("MemoryFile has been purged");
}
}
}
private void endAccess() throws IOException {
if (mAllowPurging) {
native_pin(mSharedMemory.getFileDescriptor(), false);
}
}
public void writeBytes(byte[] buffer, int srcOffset, int destOffset, int count)
throws IOException {
beginAccess();
try {
mMapping.position(destOffset);
mMapping.put(buffer, srcOffset, count);
} finally {
endAccess();
}
}
能看到在这个过程中会先调用native_pin进行锁定这一块大小的虚拟内存,避免被系统回收,最后才调用mMapping的position记录写完后的位置,并且把buffer数据写入到mMapping中.
等一下怎么回事,为什么不调用write系统调用?如果阅读过我之前文章就知道mmap的核心原理就是把物理页和虚拟内存页映射起来。
public ByteBuffer put(byte[] src, int srcOffset, int length) {
...
checkBounds(srcOffset, length, src.length);
int pos = position();
int lim = limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
...
Memory.pokeByteArray(ix(pos),
src, srcOffset, length);
position = pos + length;
return this;
}
put首先会根据设置进来的position设定已经写入了多少数据,从哪里开始写入。接着会通过传进来的数据长度以及要写入的偏移量来确定要写入哪一块内存。
此时put会调用Memory.pokeByteArray方法,把内容写到虚拟地址偏移量的起点到数据长度结束中,也就是写入到对应位置的物理页中。
文件:/libcore/luni/src/main/native/libcore_io_Memory.cpp
static void Memory_pokeByteArray(JNIEnv* env, jclass, jlong dstAddress, jbyteArray src, jint offset, jint length) {
env->GetByteArrayRegion(src, offset, length, cast(dstAddress));
}
如下就是示意图:

MemoryFile读取数据
同理,MemoryFile读取数据的核心方法也是类似的.
文件:/frameworks/base/core/java/android/os/MemoryFile.java
private class MemoryInputStream extends InputStream {
private int mMark = 0;
private int mOffset = 0;
private byte[] mSingleByte;
....
@Override
public int read() throws IOException {
if (mSingleByte == null) {
mSingleByte = new byte[1];
}
int result = read(mSingleByte, 0, 1);
if (result != 1) {
return -1;
}
return mSingleByte[0];
}
@Override
public int read(byte buffer[], int offset, int count) throws IOException {
if (offset < 0 || count < 0 || offset + count > buffer.length) {
// readBytes() also does this check, but we need to do it before
// changing count.
throw new IndexOutOfBoundsException();
}
count = Math.min(count, available());
if (count < 1) {
return -1;
}
int result = readBytes(buffer, mOffset, offset, count);
if (result > 0) {
mOffset += result;
}
return result;
}
...
}
能看到MemoryInputStream的read核心方法还是使用readBytes方法。
public int readBytes(byte[] buffer, int srcOffset, int destOffset, int count)
throws IOException {
beginAccess();
try {
mMapping.position(srcOffset);
mMapping.get(buffer, destOffset, count);
} finally {
endAccess();
}
return count;
}
能看到核心还是获取mMapping这一块DirectByteBuffer中的数据,其调用核心调用,
文件:/libcore/ojluni/src/main/java/java/nio/DirectByteBuffer.java
public ByteBuffer get(byte[] dst, int dstOffset, int length) {
...
int pos = position();
int lim = limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
...
Memory.peekByteArray(ix(pos),
dst, dstOffset, length);
position = pos + length;
return this;
}
一样也是获取当前已经写入的位置,从该位置+偏移量作为读取数据的起点,读取数据的长度即为所得。
static void Memory_peekByteArray(JNIEnv* env, jclass, jlong srcAddress, jbyteArray dst, jint dstOffset, jint byteCount) {
env->SetByteArrayRegion(dst, dstOffset, byteCount, cast(srcAddress));
}
能看到此时就是获取目标区域内存的数据,设置到srcAddress中。
小结
经过对MemoryFile的解析,能够弄清楚,Ashmem匿名共享内存使用的步骤可以分为4步:
- 1.open /dev/ashmem驱动连通ashmem驱动。
- 2.ioctl 发送ASHMEM_SET_NAME命令为该ashmem创建名字。
- 3.ioctl 发送ASHMEM_SET_SIZE命令为ashmem设置大小
- 4.mmap 做内存映射。
- 5.对该文件描述符进行读写即可。
只要进行了前三步骤,算作是进程初始化了为在ashmem驱动内创建一个文件描述符用于共享内存,但是此时还没有关联起来相当于有了一个该名字的匿名内存标识;同时设置了共享内存的大小区域
第三步,调用mmap才正式把file和虚拟内存在逻辑上关联起来;
第四步,读写才会触发缺页中断,申请物理页并且绑定起来。
从这里我想起一些网上可笑的言论,在做性能优化的内存优化的时候,为了减少Java堆中的大小而把部分数据通过共享内存传递,这样就规避了Java的内存检测。这是优化?这仅仅只是使用了Android老版本检测内存的漏洞而已。如果熟知Linux内核的朋友就知道,这只是障眼法,Linux用户态和内核态使用的都是虚拟内存(内存管理系统分配物理页流程除外),且有大小限制。
而Java虚拟机对Java堆栈和Java的Native堆栈做了大小的限制,就是因为每一个进程本身能申请的虚拟内存就是有限的。压根就没有真正的做到内存优化。
Ashmem驱动
我们了解如何使用Ashmem驱动之后,我们就根据着使用流程,从初始化到使用阅读一下Ashmem究竟在内核中做了什么。
Ashmem 初始化
文件:/drivers/staging/android/ashmem.c
先来看看Ashmem的初始化
static int __init ashmem_init(void)
{
int ret;
ashmem_area_cachep = kmem_cache_create("ashmem_area_cache",
sizeof(struct ashmem_area),
0, 0, NULL);
...
ashmem_range_cachep = kmem_cache_create("ashmem_range_cache",
sizeof(struct ashmem_range),
0, 0, NULL);
....
ret = misc_register(&ashmem_misc);
...
register_shrinker(&ashmem_shrinker);
pr_info("initialized\n");
return 0;
}
能看到在这个过程中,在slab高速缓存开辟了ashmem_area,以及ashmem_range两个结构体的cache,方便之后的申请。ashmem_area结构体的作用为切割出来给用户态的内存,ashmem_range为非锁定的内存块的链表结构,里面的内存块会在内核需要的时候被回收。
最后通过register_shrinker向内存管理系统注册Ashmem回收函数。
Ashmem 的file_operation
了解驱动最快的方式就要看这个驱动复写的file_operation 结构体中有多少操作,每个操作指向哪一个方法:
static const struct file_operations ashmem_fops = {
.owner = THIS_MODULE,
.open = ashmem_open,
.release = ashmem_release,
.read = ashmem_read,
.llseek = ashmem_llseek,
.mmap = ashmem_mmap,
.unlocked_ioctl = ashmem_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_ashmem_ioctl,
#endif
};
能看到里面有open,read,mmap,unlocked_ioctl这四个核心的方法,我们只要分析这四个在Ashmem下的方法就能清除Ashmem做了什么。
Ashmem open
#define ASHMEM_NAME_PREFIX "dev/ashmem/"
#define ASHMEM_NAME_PREFIX_LEN (sizeof(ASHMEM_NAME_PREFIX) - 1)
#define ASHMEM_FULL_NAME_LEN (ASHMEM_NAME_LEN + ASHMEM_NAME_PREFIX_LEN)
static int ashmem_open(struct inode *inode, struct file *file)
{
struct ashmem_area *asma;
int ret;
ret = generic_file_open(inode, file);
...
asma = kmem_cache_zalloc(ashmem_area_cachep, GFP_KERNEL);
...
INIT_LIST_HEAD(&asma->unpinned_list);
memcpy(asma->name, ASHMEM_NAME_PREFIX, ASHMEM_NAME_PREFIX_LEN);
asma->prot_mask = PROT_MASK;
file->private_data = asma;
return 0;
}
首先从ashmem_area_cachep申请slab缓冲区中一块ashmem_area区域,并且初始化ashmem_area中unpinned_list解锁内存块列表的队列头,并且把asma这一块匿名区域设置名字为/dev/ashmem。
最后把当前的ashmem_area设置为file的私有数据。
Ashmem ioctl设置名字与大小
接下来会通过ioctl设置名字,调用的命令是ASHMEM_SET_NAME。
static long ashmem_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{
struct ashmem_area *asma = file->private_data;
long ret = -ENOTTY;
switch (cmd) {
case ASHMEM_SET_NAME:
ret = set_name(asma, (void __user *) arg);
break;
case ASHMEM_GET_NAME:
ret = get_name(asma, (void __user *) arg);
break;
case ASHMEM_SET_SIZE:
ret = -EINVAL;
if (!asma->file) {
ret = 0;
asma->size = (size_t) arg;
}
break;
case ASHMEM_GET_SIZE:
ret = asma->size;
break;
...
return ret;
}
首先来看看几个简单的命令,ASHMEM_SET_NAME通过set_name设置名字;ASHMEM_GET_NAME通过get_name获取名字;ASHMEM_SET_SIZE设置区域大小。设置大小本质上就是设置asma中的size属性。我们来看看设置名字的set_name的逻辑。
static int set_name(struct ashmem_area *asma, void __user *name)
{
int len;
int ret = 0;
char local_name[ASHMEM_NAME_LEN];
len = strncpy_from_user(local_name, name, ASHMEM_NAME_LEN);
...
if (len == ASHMEM_NAME_LEN)
local_name[ASHMEM_NAME_LEN - 1] = '\0';
mutex_lock(&ashmem_mutex);
/* cannot change an existing mapping's name */
if (unlikely(asma->file))
ret = -EINVAL;
else
strcpy(asma->name + ASHMEM_NAME_PREFIX_LEN, local_name);
mutex_unlock(&ashmem_mutex);
return ret;
}
这里面的逻辑很简单,实际上就是获取asma中那么属性,之前是/dev/ashmem,现在在末尾追加文件名字,如/dev/ashmem/
Ashmem的mmap映射内存
static int ashmem_mmap(struct file *file, struct vm_area_struct *vma)
{
struct ashmem_area *asma = file->private_data;
int ret = 0;
mutex_lock(&ashmem_mutex);
/* user needs to SET_SIZE before mapping */
if (unlikely(!asma->size)) {
ret = -EINVAL;
goto out;
}
/* requested protection bits must match our allowed protection mask */
if (unlikely((vma->vm_flags & ~calc_vm_prot_bits(asma->prot_mask)) &
calc_vm_prot_bits(PROT_MASK))) {
ret = -EPERM;
goto out;
}
vma->vm_flags &= ~calc_vm_may_flags(~asma->prot_mask);
if (!asma->file) {
char *name = ASHMEM_NAME_DEF;
struct file *vmfile;
if (asma->name[ASHMEM_NAME_PREFIX_LEN] != '\0')
name = asma->name;
/* ... and allocate the backing shmem file */
vmfile = shmem_file_setup(name, asma->size, vma->vm_flags);
if (unlikely(IS_ERR(vmfile))) {
ret = PTR_ERR(vmfile);
goto out;
}
asma->file = vmfile;
}
get_file(asma->file);
if (vma->vm_flags & VM_SHARED)
shmem_set_file(vma, asma->file);
else {
if (vma->vm_file)
fput(vma->vm_file);
vma->vm_file = asma->file;
}
out:
mutex_unlock(&ashmem_mutex);
return ret;
}
能看到这个过程校验了,必须要设置asma的size,不然会抛异常。检测需要映射的vma虚拟内存是否符合权限,否则抛异常。
接着检查asma中的file文件结构体是否创建,没有则获取asma名字和大小通过shmem_file_setup创建一个文件描述符。
检查如果当前的vma虚拟内存允许共享则调用shmem_set_file映射文件。
我们就来看看shmem_file_setup和shmem_set_file。
shmem_file_setup
文件:/mm/shmem.c
最后会调用如下核心代码
static struct file *__shmem_file_setup(const char *name, loff_t size,
unsigned long flags, unsigned int i_flags)
{
struct file *res;
struct inode *inode;
struct path path;
struct super_block *sb;
struct qstr this;
...
res = ERR_PTR(-ENOMEM);
this.name = name;
this.len = strlen(name);
this.hash = 0; /* will go */
sb = shm_mnt->mnt_sb;
path.mnt = mntget(shm_mnt);
path.dentry = d_alloc_pseudo(sb, &this);
...
d_set_d_op(path.dentry, &anon_ops);
res = ERR_PTR(-ENOSPC);
inode = shmem_get_inode(sb, NULL, S_IFREG | S_IRWXUGO, 0, flags);
...
inode->i_flags |= i_flags;
d_instantiate(path.dentry, inode);
inode->i_size = size;
clear_nlink(inode); /* It is unlinked */
res = ERR_PTR(ramfs_nommu_expand_for_mapping(inode, size));
if (IS_ERR(res))
goto put_path;
res = alloc_file(&path, FMODE_WRITE | FMODE_READ,
&shmem_file_operations);
...
return res;
put_memory:
shmem_unacct_size(flags, size);
put_path:
path_put(&path);
return res;
}
在__shmem_file_setup中做了如下几个十分重要的事情:
- 1.d_instantiate设置目录结构体
- 2.通过shmem_get_inode设置共享的inode,inode是Linux访问硬盘文件系统的基本单位,里面包含如superblock等元数据。
- 3.alloc_file申请一个file结构体,同时复写file的结构中的file_operation文件操作.
让我们看看shmem_file_operations有具体操作:
static const struct file_operations shmem_file_operations = {
.mmap = shmem_mmap,
#ifdef CONFIG_TMPFS
.llseek = shmem_file_llseek,
.read = new_sync_read,
.write = new_sync_write,
.read_iter = shmem_file_read_iter,
.write_iter = generic_file_write_iter,
.fsync = noop_fsync,
.splice_read = shmem_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = shmem_fallocate,//预分配物理内存
#endif
};
通过shmem_file_setup,ashmem驱动程序就把vma中的file文件结构体转化为共享内存了。
不过看到shmem这个名字就应该知道其实这就是Linux中的共享内存。
shmem_set_file
文件:/mm/shmem.c
void shmem_set_file(struct vm_area_struct *vma, struct file *file)
{
if (vma->vm_file)
fput(vma->vm_file);
vma->vm_file = file;
vma->vm_ops = &shmem_vm_ops;
}
能看到本质上这个方法就是把vm_file和file结构体关联起来,同时设置了虚拟内存的操作函数:
static const struct vm_operations_struct shmem_vm_ops = {
.fault = shmem_fault,
.map_pages = filemap_map_pages,
#ifdef CONFIG_NUMA
.set_policy = shmem_set_policy,
.get_policy = shmem_get_policy,
#endif
.remap_pages = generic_file_remap_pages,
};
这个结构体尤为的重要其中fault操作函数shmem_fault,是指当接收到缺页中断时候,共享内存该如何绑定物理页。
因为此时只是从逻辑上把vma和匿名共享内存对应的file文件在逻辑上关联起来,当我们尝试读写这一段虚拟内存的时候,发现并没有映射,也没有在硬盘上保存相应的数据进行换入,就会绑定一段物理内存。
先不关心是怎么调用到shmem_fault之后有机会会聊到的,先看看下面这个方法做了什么。
static int shmem_fault(struct vm_area_struct *vma, struct vm_fault *vmf)
{
struct inode *inode = file_inode(vma->vm_file);
int error;
int ret = VM_FAULT_LOCKED;
if (unlikely(inode->i_private)) {
struct shmem_falloc *shmem_falloc;
spin_lock(&inode->i_lock);
shmem_falloc = inode->i_private;
if (shmem_falloc &&
shmem_falloc->waitq &&
vmf->pgoff >= shmem_falloc->start &&
vmf->pgoff < shmem_falloc->next) {
...
}
spin_unlock(&inode->i_lock);
}
error = shmem_getpage(inode, vmf->pgoff, &vmf->page, SGP_CACHE, &ret);
...
return ret;
}
当触发了缺页中断之后,就会查找预分配的物理内存,此时没有,会直接调用shmem_getpage,绑定vmf中的物理页和虚拟内存页。
static int shmem_getpage_gfp(struct inode *inode, pgoff_t index,
struct page **pagep, enum sgp_type sgp, gfp_t gfp, int *fault_type)
{
struct address_space *mapping = inode->i_mapping;
struct shmem_inode_info *info;
struct shmem_sb_info *sbinfo;
struct mem_cgroup *memcg;
struct page *page;
swp_entry_t swap;
int error;
int once = 0;
int alloced = 0;
if (index > (MAX_LFS_FILESIZE >> PAGE_CACHE_SHIFT))
return -EFBIG;
repeat:
swap.val = 0;
page = find_lock_entry(mapping, index);
....
/*
* Fast cache lookup did not find it:
* bring it back from swap or allocate.
*/
info = SHMEM_I(inode);
sbinfo = SHMEM_SB(inode->i_sb);
if (swap.val) {
....
} else {
if (shmem_acct_block(info->flags)) {
error = -ENOSPC;
goto failed;
}
if (sbinfo->max_blocks) {
if (percpu_counter_compare(&sbinfo->used_blocks,
sbinfo->max_blocks) >= 0) {
error = -ENOSPC;
goto unacct;
}
percpu_counter_inc(&sbinfo->used_blocks);
}
page = shmem_alloc_page(gfp, info, index);
if (!page) {
error = -ENOMEM;
goto decused;
}
__SetPageSwapBacked(page);
__set_page_locked(page);
if (sgp == SGP_WRITE)
__SetPageReferenced(page);
error = mem_cgroup_try_charge(page, current->mm, gfp, &memcg);
if (error)
goto decused;
error = radix_tree_maybe_preload(gfp & GFP_RECLAIM_MASK);
if (!error) {
error = shmem_add_to_page_cache(page, mapping, index,
NULL);
radix_tree_preload_end();
}
if (error) {
mem_cgroup_cancel_charge(page, memcg);
goto decused;
}
mem_cgroup_commit_charge(page, memcg, false);
lru_cache_add_anon(page);
spin_lock(&info->lock);
info->alloced++;
inode->i_blocks += BLOCKS_PER_PAGE;
shmem_recalc_inode(inode);
spin_unlock(&info->lock);
alloced = true;
/*
* Let SGP_FALLOC use the SGP_WRITE optimization on a new page.
*/
if (sgp == SGP_FALLOC)
sgp = SGP_WRITE;
clear:
/*
* Let SGP_WRITE caller clear ends if write does not fill page;
* but SGP_FALLOC on a page fallocated earlier must initialize
* it now, lest undo on failure cancel our earlier guarantee.
*/
if (sgp != SGP_WRITE) {
clear_highpage(page);
flush_dcache_page(page);
SetPageUptodate(page);
}
if (sgp == SGP_DIRTY)
set_page_dirty(page);
}
/* Perhaps the file has been truncated since we checked */
...
*pagep = page;
return 0;
...
}
这里面做的事情有如下几件:
- 1.首先拿到页内偏移,尝试的查找是否虚拟地址中保存着物理内存页
- 2.检查inode中的superblock的标志位或者容量是否已经超出原来预设的
- 3.shmem_alloc_page通过alloc_page通过伙伴系统申请绑定物理页
- 4.mem_cgroup_try_charge 记录当前page的缓存,mem_cgroup_commit_charge提交到linux中。cgroup的机制就是为了检测申请的内存,以及寻找时机回收。
- 5.最后把page挂在到address_space这个结构体的maping的基数树中。
这里提一句,address_space这个结构体是用于记录文件和内存的关联的。基数树实际上就是以bit为key,生成多个分支的树。有点像哈夫曼树一样,把一个key的bit位全部读出来,取出key中一位一位或者多位的生成多个阶段的树,只要把这个key的bit位全部读取完毕就能找到内容。
是一个十分快速的映射数据结构,借用网上的一个图:
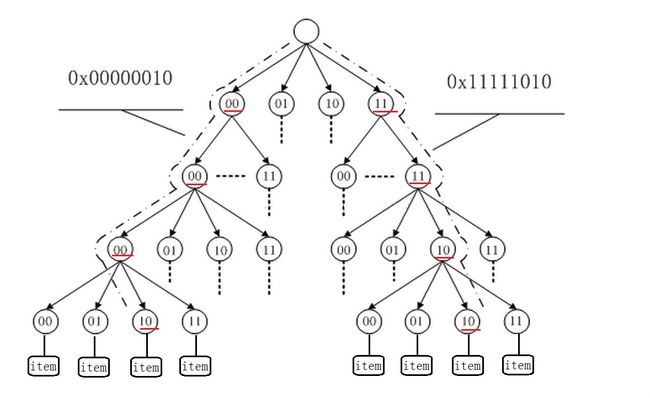
这样就完成了映射,而这种机制其实是比起Binder的mmap很接近ext4文件系统的方式。
Ashmem驱动读写
还记得读写操作此时不会对ashmem生成的文件进行读写,而是对映射的区域进行读写,换句话说就是对共享内存这段地址区域直接进行读写,没有经过write,read的系统调用,也就不会走到他们对应的file_operation.
Ashmem锁定与解锁
还记得,在这Ashmem初始化一节就说过的另一个数据结构ashmem_range吗?这里就涉及到了。那么Ashmem申请的共享匿名共享本质上还是借助shmem共享内存函数实现的,那么Ashmem和shmem有什么区别,其实区别就在这个映射区域的锁定与解锁中。
让我们把目光回顾到MemoryFile中,能够发现每一次调用读写都会调用一次native_pin方法:
native_pin(mSharedMemory.getFileDescriptor(), true)//锁定
native_pin(mSharedMemory.getFileDescriptor(), false)//解锁
在native层调用方式如下:
static jboolean android_os_MemoryFile_pin(JNIEnv* env, jobject clazz, jobject fileDescriptor,
jboolean pin) {
int fd = jniGetFDFromFileDescriptor(env, fileDescriptor);
int result = (pin ? ashmem_pin_region(fd, 0, 0) : ashmem_unpin_region(fd, 0, 0));
if (result < 0) {
jniThrowException(env, "java/io/IOException", NULL);
}
return result == ASHMEM_WAS_PURGED;
}
文件:/system/core/libcutils/ashmem-dev.cpp
int ashmem_pin_region(int fd, size_t offset, size_t len)
{
// TODO: should LP64 reject too-large offset/len?
ashmem_pin pin = { static_cast(offset), static_cast(len) };
int ret = __ashmem_is_ashmem(fd, 1);
if (ret < 0) {
return ret;
}
return TEMP_FAILURE_RETRY(ioctl(fd, ASHMEM_PIN, &pin));
}
int ashmem_unpin_region(int fd, size_t offset, size_t len)
{
// TODO: should LP64 reject too-large offset/len?
ashmem_pin pin = { static_cast(offset), static_cast(len) };
int ret = __ashmem_is_ashmem(fd, 1);
if (ret < 0) {
return ret;
}
return TEMP_FAILURE_RETRY(ioctl(fd, ASHMEM_UNPIN, &pin));
}
能看到本质上就是把offset偏移量和len要写入的长度封装为一个ashmem_pin结构体中。此时全是0.
而这个方式本质上是调用ioctl如下命令ASHMEM_PIN和ASHMEM_UNPIN:
static long ashmem_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{
struct ashmem_area *asma = file->private_data;
long ret = -ENOTTY;
switch (cmd) {
...
case ASHMEM_PIN:
case ASHMEM_UNPIN:
case ASHMEM_GET_PIN_STATUS:
ret = ashmem_pin_unpin(asma, cmd, (void __user *) arg);
break;
...
return ret;
}
static int ashmem_pin_unpin(struct ashmem_area *asma, unsigned long cmd,
void __user *p)
{
struct ashmem_pin pin;
size_t pgstart, pgend;
int ret = -EINVAL;
...
if (unlikely(copy_from_user(&pin, p, sizeof(pin))))
return -EFAULT;
...
pgstart = pin.offset / PAGE_SIZE;
pgend = pgstart + (pin.len / PAGE_SIZE) - 1;
mutex_lock(&ashmem_mutex);
switch (cmd) {
case ASHMEM_PIN:
ret = ashmem_pin(asma, pgstart, pgend);
break;
case ASHMEM_UNPIN:
ret = ashmem_unpin(asma, pgstart, pgend);
break;
case ASHMEM_GET_PIN_STATUS:
ret = ashmem_get_pin_status(asma, pgstart, pgend);
break;
}
mutex_unlock(&ashmem_mutex);
return ret;
}
此时会计算要锁定或者解锁的区域开始和结束地址。pgstart计算方式就是除去一页大小4kb,这样就能拿到偏移量是第几页,由于是除没有余数就能拿到当前页的起点。pgend就是pgstart加上长度占用的页数减1.
其实从计算就能知道,ashmem的锁定区域必定是按照页为最基本单位锁定和解锁的。
在阅读源码之前首先要明白,默认mmap出来的地址都是锁定好的。
Ashmem的解锁ashmem_unpin
static int ashmem_unpin(struct ashmem_area *asma, size_t pgstart, size_t pgend)
{
struct ashmem_range *range, *next;
unsigned int purged = ASHMEM_NOT_PURGED;
restart:
list_for_each_entry_safe(range, next, &asma->unpinned_list, unpinned) {
/* short circuit: this is our insertion point */
if (range_before_page(range, pgstart))
break;
/*
* The user can ask us to unpin pages that are already entirely
* or partially pinned. We handle those two cases here.
*/
if (page_range_subsumed_by_range(range, pgstart, pgend))
return 0;
if (page_range_in_range(range, pgstart, pgend)) {
pgstart = min_t(size_t, range->pgstart, pgstart),
pgend = max_t(size_t, range->pgend, pgend);
purged |= range->purged;
range_del(range);
goto restart;
}
}
return range_alloc(asma, range, purged, pgstart, pgend);
}
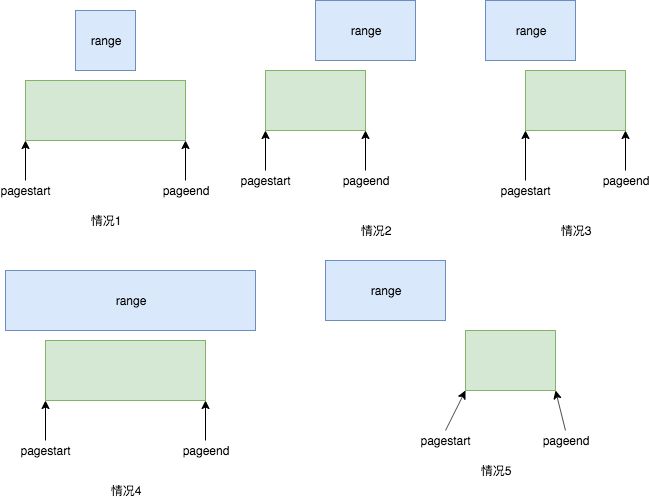
在这个过程中需要比较从unpinned_list链表种每一项已经解锁的range。大致会分为5种情况:
在情况1,2,3种当解锁的range在这一次pagestart和pageend之间有交集,则会合并起来.
在第4种情况,由于range已经包含了pagestart和pageend就没必要处理
第5种情况,由于range和即将解锁的区域不相交,并且range在即将解锁区域的前方则不需要遍历,没必要做合并操作。
range_alloc
static int range_alloc(struct ashmem_area *asma,
struct ashmem_range *prev_range, unsigned int purged,
size_t start, size_t end)
{
struct ashmem_range *range;
range = kmem_cache_zalloc(ashmem_range_cachep, GFP_KERNEL);
...
range->asma = asma;
range->pgstart = start;
range->pgend = end;
range->purged = purged;
list_add_tail(&range->unpinned, &prev_range->unpinned);
if (range_on_lru(range))
lru_add(range);
return 0;
}
此时会从ashmem_range_cachep创建一个asma_range,设置好其起始和结束地址,添加amsa的unpinnedlist末尾中。
static inline void lru_add(struct ashmem_range *range)
{
list_add_tail(&range->lru, &ashmem_lru_list);
lru_count += range_size(range);
}
最后把当前range设置到全局变量ashmem_lru_list链表的末尾,并且记录当前解锁的总大小。
Ashmem的锁定ashmem_pin
static int ashmem_pin(struct ashmem_area *asma, size_t pgstart, size_t pgend)
{
struct ashmem_range *range, *next;
int ret = ASHMEM_NOT_PURGED;
list_for_each_entry_safe(range, next, &asma->unpinned_list, unpinned) {
/* moved past last applicable page; we can short circuit */
if (range_before_page(range, pgstart))
break;
/*
* The user can ask us to pin pages that span multiple ranges,
* or to pin pages that aren't even unpinned, so this is messy.
*
* Four cases:
* 1. The requested range subsumes an existing range, so we
* just remove the entire matching range.
* 2. The requested range overlaps the start of an existing
* range, so we just update that range.
* 3. The requested range overlaps the end of an existing
* range, so we just update that range.
* 4. The requested range punches a hole in an existing range,
* so we have to update one side of the range and then
* create a new range for the other side.
*/
if (page_range_in_range(range, pgstart, pgend)) {
ret |= range->purged;
/* Case #1: Easy. Just nuke the whole thing. */
if (page_range_subsumes_range(range, pgstart, pgend)) {
range_del(range);
continue;
}
/* Case #2: We overlap from the start, so adjust it */
if (range->pgstart >= pgstart) {
range_shrink(range, pgend + 1, range->pgend);
continue;
}
/* Case #3: We overlap from the rear, so adjust it */
if (range->pgend <= pgend) {
range_shrink(range, range->pgstart, pgstart-1);
continue;
}
/*
* Case #4: We eat a chunk out of the middle. A bit
* more complicated, we allocate a new range for the
* second half and adjust the first chunk's endpoint.
*/
range_alloc(asma, range, range->purged,
pgend + 1, range->pgend);
range_shrink(range, range->pgstart, pgstart - 1);
break;
}
}
return ret;
}
同理,在上锁的情况也可以依照上面解锁的图中的4种情况:
- 1.情况1如果内存块start和end包含了range区域,那么直接把range从unpinned_list中移除
- 2.如果是内存块start和end后半部分和让相交,则直接修改要锁定的unpinned_list中range的起始地址是内存块的末尾地址
- 3.如果是内存块start和end前半部分和让相交,则直接修改要锁定的unpinned_list中range的末尾地址是内存块的起始地址
- 4.如果range包含了要锁定的内存块,则要挖一个洞,移除range中间部分,把前后两部分生成两个新的range加入到unpinned_list
第5种情况不相交就不用管了。
Ashmem的内存回收
既然存在了unpinned_list解锁定的内存区域,那么什么时候回收呢?这个操作结构体在初始化的时候就提到过,我们来直接看看这个结构体做了什么。
static struct shrinker ashmem_shrinker = {
.count_objects = ashmem_shrink_count,
.scan_objects = ashmem_shrink_scan,
.seeks = DEFAULT_SEEKS * 4,
};
核心是这个扫描函数ashmem_shrink_scan
static unsigned long
ashmem_shrink_scan(struct shrinker *shrink, struct shrink_control *sc)
{
struct ashmem_range *range, *next;
unsigned long freed = 0;
/* We might recurse into filesystem code, so bail out if necessary */
...
list_for_each_entry_safe(range, next, &ashmem_lru_list, lru) {
loff_t start = range->pgstart * PAGE_SIZE;
loff_t end = (range->pgend + 1) * PAGE_SIZE;
range->asma->file->f_op->fallocate(range->asma->file,
FALLOC_FL_PUNCH_HOLE | FALLOC_FL_KEEP_SIZE,
start, end - start);
range->purged = ASHMEM_WAS_PURGED;
lru_del(range);
freed += range_size(range);
if (--sc->nr_to_scan <= 0)
break;
}
mutex_unlock(&ashmem_mutex);
return freed;
}
能看到,在这个过程会循环之前解锁放进来的全局链表,并且不断的调用lru_del删除rang项,重新计算剩余的空间大小。还有一个更加重要的是调用了fallocate文件操作调用。
还记得这个文件操作是在__shmem_file_setup中设置的吗?我们去shmem中一看shmem_fallocate方法中解映射的逻辑
文件:/mm/shmem.c
static long shmem_fallocate(struct file *file, int mode, loff_t offset,
loff_t len)
{
struct inode *inode = file_inode(file);
struct shmem_sb_info *sbinfo = SHMEM_SB(inode->i_sb);
struct shmem_inode_info *info = SHMEM_I(inode);
struct shmem_falloc shmem_falloc;
pgoff_t start, index, end;
int error;
if (mode & ~(FALLOC_FL_KEEP_SIZE | FALLOC_FL_PUNCH_HOLE))
return -EOPNOTSUPP;
mutex_lock(&inode->i_mutex);
if (mode & FALLOC_FL_PUNCH_HOLE) {
struct address_space *mapping = file->f_mapping;
loff_t unmap_start = round_up(offset, PAGE_SIZE);
loff_t unmap_end = round_down(offset + len, PAGE_SIZE) - 1;
DECLARE_WAIT_QUEUE_HEAD_ONSTACK(shmem_falloc_waitq);
/* protected by i_mutex */
if (info->seals & F_SEAL_WRITE) {
error = -EPERM;
goto out;
}
shmem_falloc.waitq = &shmem_falloc_waitq;
shmem_falloc.start = unmap_start >> PAGE_SHIFT;
shmem_falloc.next = (unmap_end + 1) >> PAGE_SHIFT;
spin_lock(&inode->i_lock);
inode->i_private = &shmem_falloc;
spin_unlock(&inode->i_lock);
if ((u64)unmap_end > (u64)unmap_start)
unmap_mapping_range(mapping, unmap_start,
1 + unmap_end - unmap_start, 0);
shmem_truncate_range(inode, offset, offset + len - 1);
/* No need to unmap again: hole-punching leaves COWed pages */
spin_lock(&inode->i_lock);
inode->i_private = NULL;
wake_up_all(&shmem_falloc_waitq);
spin_unlock(&inode->i_lock);
error = 0;
goto out;
}
...
out:
mutex_unlock(&inode->i_mutex);
return error;
}
因为调用时候设置了FALLOC_FL_PUNCH_HOLE标志,因此会走到这里面,能看到最核心的方法,调用了unmap_mapping_range解开了物理内存和虚拟内存的映射关系。同时调用shmem_truncate_range释放保存在address_space的mapping的映射区域。并且设置等大小的文件空洞。这个这个空洞的意思,可以访问超出当前的文件大小,当然要在预留的空洞大小内,当写入的时候就会把该文件撑大。
总结
ashmem的使用流程如下:
-
- ashmem_create_region创建匿名共享内存区域,本质是调用open系统调用
- 2.ioctl设置共享内存的名字和大小,设置的名字为/dev/ashmem/
,名字的存在就为了能够让其他人找到目标 - 3.mmap映射文件中的虚拟内存以及物理内存
- 4.直接对着这一块地址区域读写。
其中ioctl必须设置名字和大小,不然没办法进行映射,因为在映射之前进行了校验。
而mmap步骤才会真正的把匿名共享内存的区域和file结构体关联起来,并且设置上shmem共享内存的文件操作符以及共享内存的vma操作。到这一步开始ashmem把工作交给了shmem中,最后通过alloc_page的方法把虚拟内存和物理页映射起来。
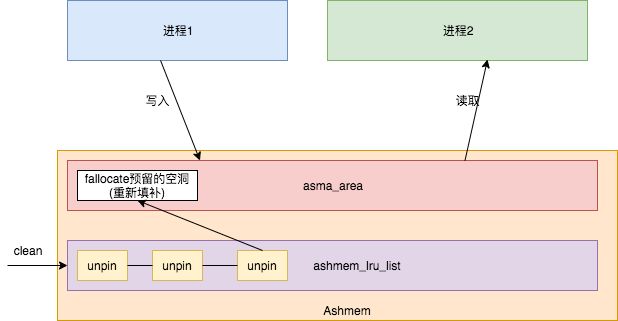
因此ashmem本质上还是依靠这shmem共享内存进行工作。那么ashmem和shmem有什么关系吗。从名字上就能知道a是指auto,也就是能够通过内存系统自动回收需要的内存。
因此在ashmem中有比较重要的机制锁定和解锁的机制。一般所有解锁都会放到当前amsa的unpinned_list中管理,同时会记录在全局变量ashmem_lru_list中。上锁就是把添加到unpinned_list和ashmem_lru_list的内存块记录移除。
因此,mmap诞生出来的整个内存块默认是解锁的。也正因为添加到全局变量ashmem_lru_list中,也就让内存管理系统遍历ashmem_lru_list通过shmem_fallocate文件操作对这些内存进行解开映射,并且留下文件空洞(其实就是想办法通过页缓存,重新申请等手段重新把这一块内存重新填补上来),
原理图如下:
思考
那么ashmem和Binder有什么区别呢?先放上Binder的mmap 的文章:
Android 重学系列 Binder驱动的初始化 映射原理(二)
其实最主要的区别就是Binder的mmap时候已经通过伙伴系统绑定了物理页和虚拟内存之间的联系,而Ashmem则是通过缺页中断,调用相关的函数才进行绑定。换句话说Ashmem是按需加载,而Binder则是一开始就通过mmap就分配好。当然这也是Binder的机制相关,因为Binder一旦在一个Android启动之后就要开始通信,同时Binder需要通过mmap的方式,在Binder驱动程序中设置一个象征进程的内核缓冲区,方便一开始通信,没必要等到中断来了再申请物理页,从设计的角度来看Binder这么做更加合理。
两者之间的设计有什么优劣呢?很明显,Ashmem就是打通一块大的内存通道方便进程之间通信大数据。而Binder更加倾向小规模的指令,并且这种指令有明确的方向和顺序,保证每一个指令的可靠性。从功能上看起来差不多的东西,但是由于设计出发的角度看来,Binder为了保证每一个指令的可靠做了极其复杂的数据结构进行管理。
对了,稍后还有一篇关于Linux内存管理的笔记,如果对内存管理系统比较吃力,不妨先去看那一篇再回来看Binder和Ashmem吧。