操作环境
- python 3.6.1
- pycharm 5.0.3
- WampServer 3.0.6
- windows 8(64位)
特点
1.中途退出程序或者断网之后重连再次运行不会抓取到重复的课程表
2.使用MySQL数据库(phpmyadmin)储存数据,方便管理课程表
python安装
- 我的电脑是64位的,所以我下载的是下面的版本
下载地址
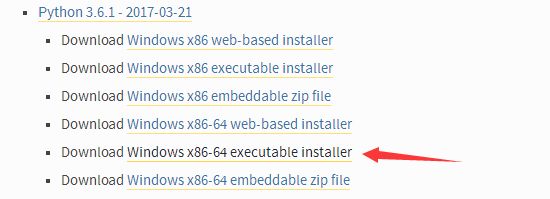 选择版本以及系统位数下载
选择版本以及系统位数下载
-
安装完之后必须将python安装的路径添加至系统变量中去
--> 右击我的电脑-->属性-->高级系统设置-->环境变量-->在path后面添加python的安装路径
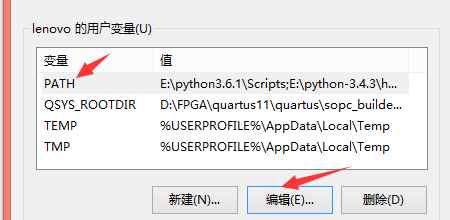 设置环境变量
设置环境变量
pycharm安装
下载地址
 选择版本
选择版本
- 社区版是免费使用的
- 安装及使用教程
Python插件安装
安装Python 完毕后,需要安装下列插件。
- Beautiful Soup
- PyMySQL
以管理员模式打开cmd命令提示符,执行命令
pip install beautifulsoup4
pip install pymysql
WampServer安装
下载地址
根据系统的位数选择相应的进行下载
 根据系统位数进行下载
根据系统位数进行下载
WampServer安装教程
安装启动之后可能会报错:
64位电脑上启动程序出现丢失MSVCR110.dll的解决办法
启动程序报错如下:
无法启动此程序,因为计算机中丢失MSVCR110.dll。尝试重新安装该程序以解决此问题。
应该很容易就搜索到,缺少这样的dll文件,是没有安装Visual C++ Redistributable for Visual Studio 2012的缘故,
但是在安装了
Visual C++ Redistributable for Visual Studio 2012 X64版本后,运行程序依旧报错这个dll文件丢失,问题就在于,64位电脑中,可以运行32位和64位的程序,因而,如果运行的32位的程序,需要32位的
Visual C++ Redistributable for Visual Studio 2012 X86版本的支持,否则会出现上述的错误,因为软件查找的是X86版本的dll文件,而我安装的X64的,当然会发生丢失**
解决方案:如果你是64位的机器,建议安装下列地址上提供的X86和X64版本,两个版本都安装**
安装地址
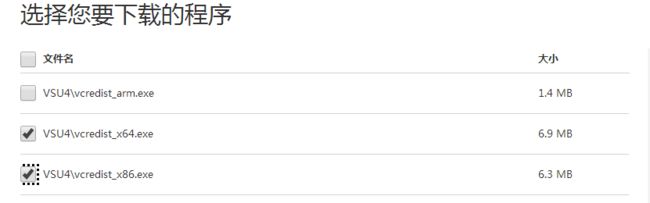 下载两个版本
下载两个版本
至此,应该可以正常启动WampServer程序了。
注意
启动程序请选择google浏览器打开,用其他浏览器可能会报错或者受限制。
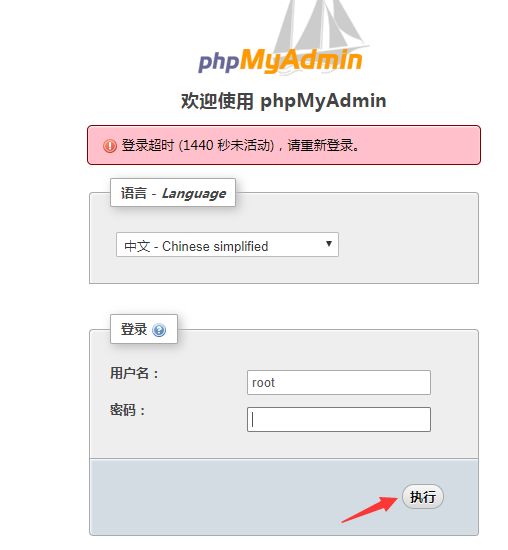
第一次使用密码为空,直接执行即可。
-
进入到web页面,点击左上角的新建创建数据库文件
 新建数据库
新建数据库 -
导入数据库文件
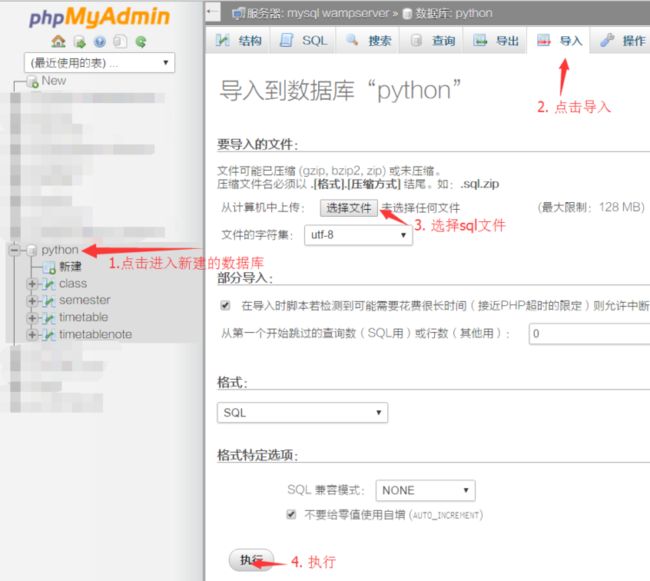 导入数据库文件
导入数据库文件
环境都准备好了,下面开始进入主题
网页分析
- 教务管理信息系统课程表链接分析
例如通信141班课程表的链接:http://172.16.129.117/web_jxrw/cx_kb_bjkb_bj.aspx?xsbh=14040201&xq=17-18-1
从链接的尾部*** .aspx?xsbh=14040201&xq=17-18-1 中的问号?可以看出该网页是用GET的方式请求数据的,第一个参数是xsbh = 14040201,第二个参数是xq = 17-18-1,xq明显是学期拼音首字母缩写,而xsbh应该就是班级编号了。所以我们要先获取所有的班级编号和学期数,然后拼接成班级课表链接,进行遍历抓取课程表:http://172.16.129.117/web_jxrw/cx_kb_bjkb_bj.aspx?xsbh=班级编号&xq=学期
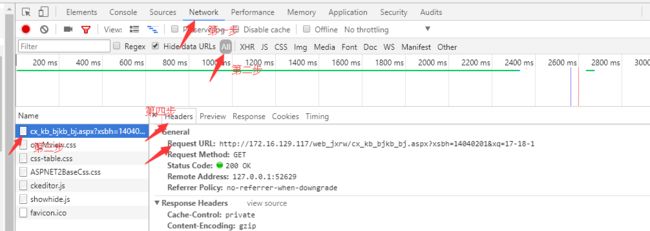 分析网页
分析网页
- 抓取所有学期网页分析
教务信息系统查询课表页面地址:http://172.16.129.117/web_jxrw/cx_kb_bjxzall.aspx
打开链接后,查看网页源代码,所有学期数都是放在ID为DDxq的select标签下的option标签(如图),
 检查
检查
然后出现下图
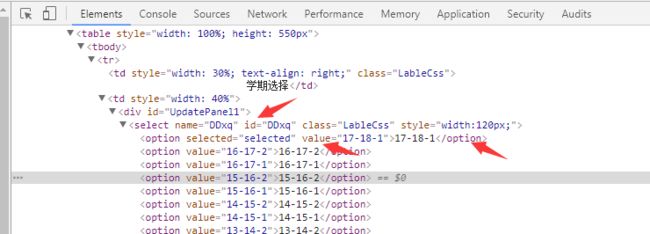 获取学期信息
获取学期信息
因为在前端开发中,id这个属性的值是唯一的,所以使用Beautiful Soup选择此处的代码为soup.find(id=”DDxq”).find_all(“option”)
这就可以用beautifulsoup插件提取所有学期。
- 抓取所有学期的python代码
semester.py
import urllib
import urllib.request
from bs4 import BeautifulSoup
import pymysql.cursors
connection = pymysql.connect(
host='localhost',
user='root',
password=' ',
db='python',
charset="utf8",
cursorclass=pymysql.cursors.DictCursor)
def sqlLink(semester):
try:
with connection.cursor() as cursor:
sql = "INSERT INTO `semester` (`semester`) VALUES (%s)"
#插入数据
cursor.execute(sql, (semester))
connection.commit() #提交
finally:
# connection.close()
pass
return
response = urllib.request.urlopen('http://172.16.129.117/web_jxrw/cx_kb_bjxzall.aspx')
if response.code == 200:
print ("succeed",response.code)
html = response.read()
soup = BeautifulSoup(
html,
'html.parser',
from_encoding = 'gb2312')
arr = soup.find(id="DDxq").find_all("option")
for x in arr:
ch = x.get_text()
print(ch)
sqlLink(str(ch))
else:
print ("failed")
- 抓取所有班级和班级编号
同样查看教务信息系统,分析网页源码按照上面的方法,所有班级都放在id为Cxbj_all1_bjlist1的select标签下(如图),直接用beautifulsoup抓取。
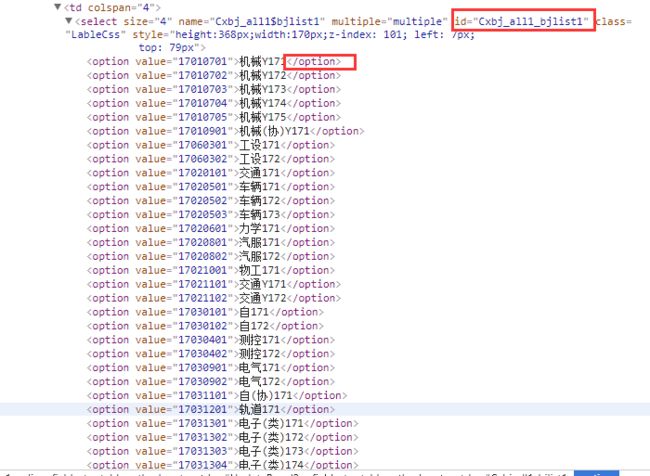 检查
检查
- 抓取所有班级的班级编号的python代码
class.py
import urllib
import urllib.request
from bs4 import BeautifulSoup
import pymysql.cursors
#连接数据库
connection = pymysql.connect(
host='localhost',
user='root',
password=' ',
db='python',
charset="utf8",
cursorclass=pymysql.cursors.DictCursor)
def sqlLink(clssName,classCode,grade):
try:
with connection.cursor() as cursor: #创建游标
sql = "INSERT INTO `class` (`className`,`classCode`,`grade`) VALUES (%s,%s,%s)"
#插入一条数据库
cursor.execute(sql, (clssName,classCode,grade))
#提交
connection.commit()
finally:
# connection.close()
pass
return
response = urllib.request.urlopen('http://172.16.129.117/web_jxrw/cx_kb_bjxzall.aspx')
if response.code == 200:
print ("succeed",response.code)
html = response.read()
#创建soup对象
soup = BeautifulSoup(
html,
'html.parser',
from_encoding = 'gb2312')
arr = soup.find(id="Cxbj_all1_bjlist1").find_all("option")
for x in arr:
ch = x.get_text() #获取班级名
classCode = x['value']
last = x['value'][0]+x['value'][1]
if last == "98":
grade = "19"+last
pass
else:
grade = "20"+last
print(classCode)
sqlLink(str(ch),classCode,grade)
else:
print ("failed")
- 抓取所有班级的课程表
有了班级列表和学期这些数据,我们就可以遍历班级列表和学期列表来拼接成课程表查询链接,提取每个链接中的课程。
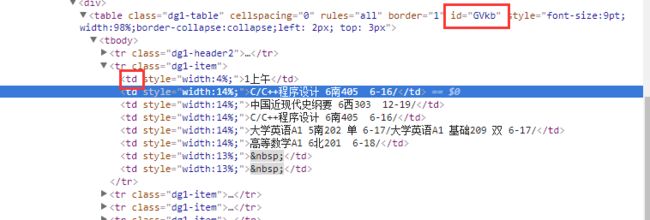 检查
检查
同理,在id为GVkb的table标签下,每天的课程都会放在td标签下。
Python代码为soup.find(id=”GVkb”).find_all(“td”)
- 抓取所有班级课程表的python代码
此处分为两个python文件, 请按照注释命名文件,第一个是schedule.py,第二个是spider.py,要放在同一目录下运行。
1.schedule.py
import urllib
import urllib.request
from bs4 import BeautifulSoup
import pymysql.cursors
def insertTimeTable(classCode,semester):
connection = pymysql.connect(
host='localhost',
user='root',
password=' ',
db='python',
charset="utf8",
cursorclass=pymysql.cursors.DictCursor)
response = urllib.request.urlopen('http://172.16.129.117/web_jxrw/cx_kb_bjkb_bj.aspx?xsbh='+classCode+'&xq='+semester)
if response.code == 200:
print ("succeed to open the url, code=",response.code)
html = response.read()
soup = BeautifulSoup(
html,
'html.parser',
from_encoding = 'gbk')
arr = soup.find(id="GVkb").find_all("td")
note = soup.find(id="TextBox1")
timeTable = []
for x in arr:
ch = x.get_text()
strings = str(ch).replace("\xa0","none") + "\n"
timeTable.append(strings)
if len(timeTable) == 8:
try:
with connection.cursor() as cursor:
sql = "INSERT INTO `timetable` (`classCode`,`semester`,`section`,`one`,`two`,`three`,`four`,`five`,`six`,`seven`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(sql, (classCode,semester,timeTable[0],timeTable[1],timeTable[2],timeTable[3],timeTable[4],timeTable[5],timeTable[6],timeTable[7]))
connection.commit()
finally:
timeTable = []
print("insert succeed!")
pass
try:
with connection.cursor() as cursor:
sql = "INSERT INTO `timetablenote` (`classCode`,`semester`,`note`) VALUES (%s,%s,%s)"
cursor.execute(sql, (classCode,semester,note.get_text()))
connection.commit()
finally:
print("note insert succeed!")
pass
else:
print("failed to open the url, code=", response.code)
pass
2.spider.py
import pymysql.cursors
import schedule
connection = pymysql.connect(
host='localhost',
user='root',
password=' ',
db='python',
charset="utf8",
cursorclass=pymysql.cursors.DictCursor)
try:
### get all semester
with connection.cursor() as cursor:
sql = "SELECT * FROM `semester`"
cursor.execute(sql)
resultSemester = cursor.fetchall()
# for x in resultSemester:
# print(x["semester"])
# pass
### get all classCode
with connection.cursor() as cursor:
sql = "SELECT `classCode` FROM `class`"
cursor.execute(sql)
resultClassCode = cursor.fetchall()
# for x in resultClassCode:
# print(x["classCode"])
# pass
finally:
i = 0
pass
for x in resultClassCode:
classCode = x["classCode"]
# print("classCode = ",classCode)
for y in resultSemester:
semester = y["semester"]
# print("Semester = ",semester)
gradeClassCode = int(classCode[0]+classCode[1])
gradeSemester = int(semester[0]+semester[1])
try:
with connection.cursor() as cursor:
sql = "SELECT `classCode`,`semester` FROM `timetable` WHERE classCode='"+classCode+"' AND semester='"+semester+"'"
cursor.execute(sql)
resultRepeat = cursor.fetchone()
finally:
# connection.close()
pass
if (gradeSemester >= gradeClassCode) and (gradeSemester <= gradeClassCode+3):
if resultRepeat is None:
arr = [classCode,semester]
print(arr)
schedule.insertTimeTable(classCode,semester)
else:
print("The timetable had already exist")
i += 1
print(i,"Processing...")
python.sql
-- phpMyAdmin SQL Dump
-- version 4.6.4
-- http://www.phpmyadmin.net
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
--
-- Database: `python`
--
-- --------------------------------------------------------
--
-- 表的结构 `class`
--
CREATE TABLE IF NOT EXISTS `class` (
` id` int(11) NOT NULL AUTO_INCREMENT,
`className` text NOT NULL,
`classCode` text NOT NULL,
`grade` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- 表的结构 `semester`
--
CREATE TABLE IF NOT EXISTS `semester` (
`semester` text NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- --------------------------------------------------------
--
-- 表的结构 `timetable`
--
CREATE TABLE IF NOT EXISTS `timetable` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`classCode` text NOT NULL,
`semester` text NOT NULL,
`section` text NOT NULL,
`one` text NOT NULL,
`two` text NOT NULL,
`three` text NOT NULL,
`four` text NOT NULL,
`five` text NOT NULL,
`six` text NOT NULL,
`seven` text NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
-- --------------------------------------------------------
--
-- 表的结构 `timetablenote`
--
CREATE TABLE IF NOT EXISTS `timetablenote` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`classCode` text NOT NULL,
`semester` text NOT NULL,
`note` text NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
- 运行程序进行班级课程表的爬取
爬取的时间可能会有点长,请耐心等待。在爬取过程中可能会由于网络不稳定出现断线情况,出现断线情况后只能进行手动重新运行程序,但是不会出现重复的课程表爬取现象。