论文作者:Chenxing Li*, Peilun Li*, Dong Zhou* † , Wei Xu, Fan Long † , and Andrew Chi-Chih Yao,清华大学交叉信息研究院
本论文从中本聪共识机制的工作原理出发,指出简单的在共识机制中增大区块容量以及提高出块率的方式并不可取,这两种方式均会使区块在网络上传播的延时相对变长,从而在账本中产生很多分叉,不仅浪费计算和网络的资源,也危害了安全性。而论文提出的Conflux利用区块链中交易少冲突的特点,乐观的处理并发块,且将区块通过父边和引用边组织成有向无环图(DAG),同时创新的将Ghost规则和Epoch的概念相结合,从而使参与协议的机器节点能够在一致的账本结构中决定一致的交易全序。Ghost规则保证的了主链的选择无法被逆转,DAG和Epoch帮助确定一致的交易全序。通过这样的技术,Conflux能够在防治双花攻击的同时将分叉上的区块变为有效从而提升有效区块的比例,进而能够将公链系统的吞吐率提升到每秒上千次交易,且能够在分钟级别的延时内确认交易。在Conflux中,系统的吞吐率瓶颈已不再是共识机制本身,而在于网络带宽以及每个节点局部的计算处理能力。
介绍
现如今,区块链和数字货币在业界已经产生了相当大的影响力。以比特币为代表的区块链技术已经发展成为一可以个在互联网级别上支持安全的,一致的,分布式的交易账本的平台。这个平台进而带动了金融科技,供应链,和医疗健康等应用领域的技术创新。全球的数字货币市场也支撑着千亿美元的市值。
然后讲述了像比特币这样采用POW协议的区块链的底层原理,这种系统性能和效率方面存在很大的问题。由于只能有一个矿工可以赢得竞争,写入区块,导致并发区块作为分叉被遗弃,而且缓慢的性能是防止攻击的必要条件,所以性能问题是中本聪区块链中一个比较重要的瓶颈。我们都知道,比特币每秒可以处理大概7个交易,以太坊是每秒30个交易。为了获得比较高的安全性,一个交易往往需要等待将近10个区块后才能确认交易。这些吞吐量不足,以及高延迟的特征限制了区块链技术的应用,这就导致了糟糕的用户体验
过去的一些研究主要集中在减少共识算法的参与者以提高性能而不损害区块链的安全性。但是这些做法可能会在协议参与者之间产生不期望的层次结构并且损害区块链的去中心化的特点。
Conflux
本论文所介绍的Conflux方法是一个快速,可拓展的,分散的区块链系统,它可以每秒处理上千个交易,并且可以在数分钟内确认每一笔交易。Conflux关键特点是它可以让多个参与者同时贡献区块的时候还保证了安全性,不会造成分叉丢失的现象出现。
我们注意到,在比特币中的这种基于链的共识机制里,它本质上对交易的执行顺序有一个严格的限制,也就是交易的执行顺序要和他们所在的区块的产生顺序是一致的。鉴于交易很少在区块链中发生冲突(特别是在加密货币中),Conflux首先乐观地假设并发块中的事务默认情况下不会相互冲突,因此只考虑区块生成器指定的happens-before关系。实际上区块链的系统里面,很多的交易是没有冲突的,所以它们可以按任意的顺序执行,只要所有的参与节点都同意一个顺序就可以了。
为了安全的合并并发的区块,Conflux维护了两种类型的块间关系。在Conflux中,当一个矿工节点生成一个区块的时候,这个节点要在新区块中定义它的父块(前置块),并且在两个块之间建立一个parent边。这些parent边使Conflux能够在其总链上实现一致的不可逆转的共识。 该节点还标识所有没有进入边的块,并从新块到这些块创建一条reference边。这个reference边表示的是这些块在新块生成之前就已经存在了,它们使Conflux能够系统地扩展已达成的共识以合并并发块。这就导致Conflux区块看起来像一个复杂的DAG图,而不是一个有可能分叉的链。
下面我截取了Conflux项目的CTO 伍鸣在 2018 POD New BlockTrend新区势区块链峰会上的演讲来理解这个共识机制,有图比较好理解点。
有了这些边的定义,这个账本结构就定下来了,这个结构会在全网节点进行广播,所以,所有的节点最终都会得到一个一致的账本。那么有了一致的账本以后,所有的节点如何去决定一个一致的区块全序呢?论文核心想法是,首先,这些节点先在DAG中决定一个一致的主链,然后,再根据这个主链来决定一个一致的区块的全序。
为了决定主链,Conflux使用了Ghost规则。具体来说就是,从创世块开始,迭代的去从孩子区块中选择下一个在主链上的区块。选择的规则是挑选拥有最大子树的孩子区块。比如,区块A和区块B是创世区块的两个孩子区块。A的子树有6个区块,B的子树有5个区块。所以我们选择区块A作为紧接着创世区块的主链区块。
为了产生一个新的区块,一个机器节点首先选择主链上的最后一个区块作为新区块的父亲,然后这个新区块再把所有已经收到但还没有被其他区块所引用的区块引用起来。这里之所以使用Ghost规则而不是最长链规则来选主链,是因为Ghost规则中所有的区块,包括那些在分叉上的区块,都会对主链的选择做出贡献。这样的话,就保证了只要攻击者的算力没有超过50%, 就无法改变由诚实节点确定的主链。
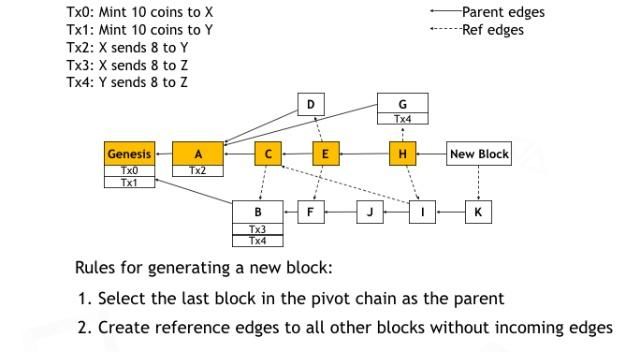
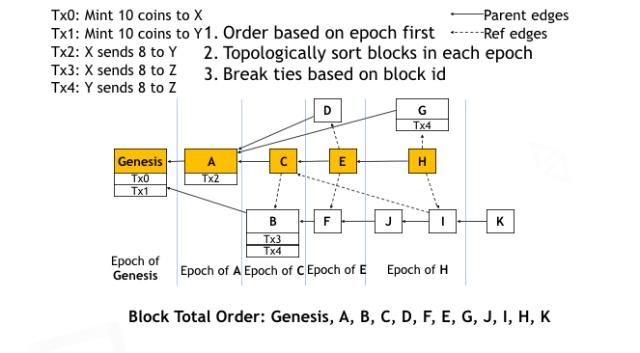
现在有了让所有机器节点对主链产生共识的机制。那接下来,这些节点如何对区块的全序达成共识呢?为了做到这一点,引入一个Epoch的概念。在主链上的每一个区块就确定了一个Epoch。在分叉上的区块属于哪个Epoch,是由第一个产生在它之后的主链区块所在的Epoch决定的。比如,区块D属于Epoch E,因为D最先被E引用,所以产生在E之前,但是D并不产生在C之前。
所以,在Conflux中,首先按照Epoch的顺序来给区块排个序。然后在每一个Epoch内部,按照拓扑排序来确定区块的顺序。如果出现平局的情况,再根据区块的哈希值来打破平局。接下来我们要为交易排序,Conflux首先按照区块的顺序去给交易排序。然后在每个区块内部,就按照交易在区块里所在的位置来排就可以了。
后面演讲还涉及到如何防止交易冲突,如何防止双花攻击以及51%算力攻击的防范方法。然后一个交易的确认包含以下几步。用户首先对攻击者的算力比例以及他所能承受的风险有一个假设。给定这个假设,Conflux首先找到这个交易所属的Epoch,然后找到和这个Epoch相应的主链区块。最后再检查这个主链区块被逆转的概率是否小于用户所能承受的风险。如果小于,则该交易可以确认。
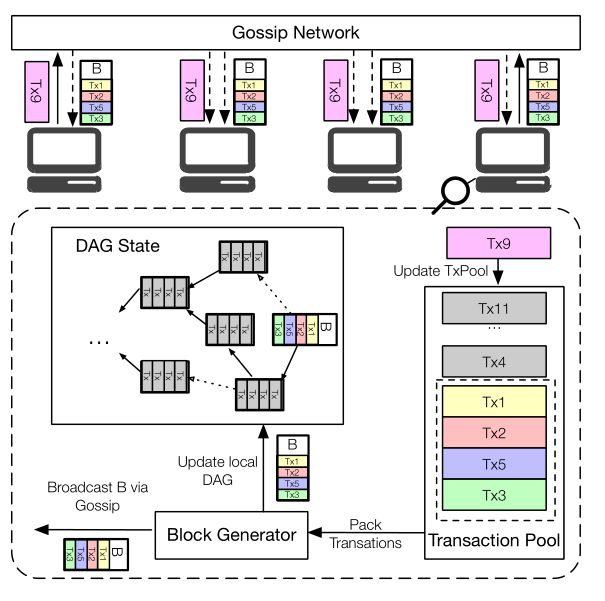
这个图概括的展示了Conflux系统架构。 所有参加Conflux协议的机器节点由一个p2p的网络连接起来,他们通过Gossip的方式在网络中传播交易和区块。每个机器节点,维护一个交易池,交易池里面缓存着将要打包的交易。另外每个机器节点同时也在不停的运行Conflux的共识协议。
值得注意的是,这篇论文只关注于设计和实现共识协议,而奖励机制没有在论文的范围内。然后在论文中提到的“诚实节点”是那些在Conflux上忠实执行没有错误的程序的节点。对于奖励机制可作为Conflux未来的工作。
Contribution
这篇论文的主要贡献:
1.共识协议:论文主要介绍了一个快速可拓展,基于DAG图的中本聪共识协议以及它的原型实现Conflux来乐观地处理并发区块,然后再决定一个一致的区块顺序,并在这个区块顺序下进一步决定所有交易的执行顺序,最后再依照这个交易的顺序去解决交易的冲突问题。Conflux创新的维护两个块间关系来安全的合并并发区块。
2.Conflux实现:论文基于比特币的代码库来实现Conflux。Conflux是第一个基于DAG图的中本聪区块链系统,并且可以在每秒执行上千的交易。
3.实验结果:论文系统的大规模评估了Conflux。根据实验可以发现,当执行20k个完整节点的时候,Conflux可以达到2.88GB/h ~5.76GB/h的交易吞吐量,并且可以让交易在4.5~13.8分钟内确认高度信任的交易,即不可逆转的交易。