转:LIRe 源代码分析
1:整体结构
LIRE(Lucene Image REtrieval)提供一种的简单方式来创建基于图像特性的Lucene索引。利用该索引就能够构建一个基于内容的图像检索(content- based image retrieval,CBIR)系统,来搜索相似的图像。在这里就不多进行介绍了,已经写过相关的论文:
因为自己开发的媒资检索系统中用到了LIRe,而且可能还要将实验室自己研究的算法加入其中,因此我研究了一下它源代码的大体结构。
想要看LIRe源代码的话,需要将其源代码包添加进来,相关的教程比较多,在这里就不详细解释了。先来看一看它的目录结构吧。
注:开发环境是MyEclipse 9

乍一看感觉包的数量实在不少,不急,让我们细细来看。所有的包的前缀都是“net.semanticmetadata.lire”,在这里把该目录当成是 “根目录”,根目录中包含的类如上图所示。注:在下面的介绍中就不再提“net.semanticmetadata.lire”了。
根目录主要是一些接口,这些接口可以分为2类:
DocumentBuilder:用于生成索引
ImageSearcher:用于检索
“lire.imageanalysis”里面存储的是lire支持的方法的实现类。每个类以其实现的方法命名。
这些方法的算法有的位于“lire.imageanalysis”的子包中。
比如CEDD算法的实现类位于“lire.imageanalysis.cedd”中;
ColorLayout算法的实现类位于“lire.imageanalysis.mpeg7”中。
“lire.impl”里面存储的是lire支持的方法的DocumentBuilder和ImageSearcher。命名规则是***DocumentBuilder或者***ImageSearcher(***代表方法名称)
2:基本接口(DocumentBuilder)
本文分析LIRe的基本接口。LIRe的基本接口完成的工作不外乎两项:生成索引和检索。生成索引就是根据图片提取特征向量,然后存储特征向量到索引的过程。检索就是根据输入图片的特征向量到索引中查找相似图片的过程。
LIRe的基本接口位于net.semanticmetadata.lire的包中,如下图所示:
将这些接口分为2类:
DocumentBuilder:用于生成索引
ImageSearcher:用于检索
下面来看看与DocumentBuilder相关的类的定义:
(LIRe在代码注释方面做得很好,每个函数的作用都写得很清楚)
DocumentBuilder:接口,定义了基本的方法。
AbstractDocumentBuilder:纯虚类,实现了DocumentBuilder接口。
DocumentBuilderFactory:用于创建DocumentBuilder。
DocumentBuilder相关的类的继承关系如下图所示。可见,各种算法类都继承了AbstractDocumentBuilder,而AbstractDocumentBuilder实现了DocumentBuilder。
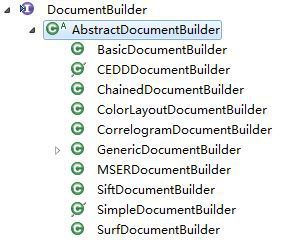
详细的源代码如下所示:
DocumentBuilder
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * ~~~~~~~~~~~~~~~~~~~~ * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire; import org.apache.lucene.document.Document; import java.awt.image.BufferedImage; import java.io.IOException; import java.io.InputStream; /** * <h2>Creating an Index</h2> * <p/> * Use DocumentBuilderFactory to create a DocumentBuilder, which * will create Lucene Documents from images. Add this documents to * an index like this: * <p/> * <pre> * System.out.println(">> Indexing " + images.size() + " files."); * DocumentBuilder builder = DocumentBuilderFactory.getExtensiveDocumentBuilder(); * IndexWriter iw = new IndexWriter(indexPath, new SimpleAnalyzer(LuceneUtils.LUCENE_VERSION), true); * int count = 0; * long time = System.currentTimeMillis(); * for (String identifier : images) { * Document doc = builder.createDocument(new FileInputStream(identifier), identifier); * iw.addDocument(doc); * count ++; * if (count % 25 == 0) System.out.println(count + " files indexed."); * } * long timeTaken = (System.currentTimeMillis() - time); * float sec = ((float) timeTaken) / 1000f; * * System.out.println(sec + " seconds taken, " + (timeTaken / count) + " ms per image."); * iw.optimize(); * iw.close(); * </pre> * <p/> * <p/> * This file is part of the Caliph and Emir project: http://www.SemanticMetadata.net * <br>Date: 31.01.2006 * <br>Time: 23:02:00 * * @author Mathias Lux, [email protected] */ public interface DocumentBuilder { public static final int MAX_IMAGE_SIDE_LENGTH = 800; public static final String FIELD_NAME_SCALABLECOLOR = "descriptorScalableColor"; public static final String FIELD_NAME_COLORLAYOUT = "descriptorColorLayout"; public static final String FIELD_NAME_EDGEHISTOGRAM = "descriptorEdgeHistogram"; public static final String FIELD_NAME_AUTOCOLORCORRELOGRAM = "featureAutoColorCorrelogram"; public static final String FIELD_NAME_COLORHISTOGRAM = "featureColorHistogram"; public static final String FIELD_NAME_CEDD = "featureCEDD"; public static final String FIELD_NAME_FCTH = "featureFCTH"; public static final String FIELD_NAME_JCD = "featureJCD"; public static final String FIELD_NAME_TAMURA = "featureTAMURA"; public static final String FIELD_NAME_GABOR = "featureGabor"; public static final String FIELD_NAME_SIFT = "featureSift"; public static final String FIELD_NAME_SIFT_LOCAL_FEATURE_HISTOGRAM = "featureSiftHistogram"; public static final String FIELD_NAME_SIFT_LOCAL_FEATURE_HISTOGRAM_VISUAL_WORDS = "featureSiftHistogramVWords"; public static final String FIELD_NAME_IDENTIFIER = "descriptorImageIdentifier"; public static final String FIELD_NAME_CEDD_FAST = "featureCEDDfast"; public static final String FIELD_NAME_COLORLAYOUT_FAST = "featureColorLayoutfast"; public static final String FIELD_NAME_SURF = "featureSurf"; public static final String FIELD_NAME_SURF_LOCAL_FEATURE_HISTOGRAM = "featureSURFHistogram"; public static final String FIELD_NAME_SURF_LOCAL_FEATURE_HISTOGRAM_VISUAL_WORDS = "featureSurfHistogramVWords"; public static final String FIELD_NAME_MSER_LOCAL_FEATURE_HISTOGRAM = "featureMSERHistogram"; public static final String FIELD_NAME_MSER_LOCAL_FEATURE_HISTOGRAM_VISUAL_WORDS = "featureMSERHistogramVWords"; public static final String FIELD_NAME_MSER = "featureMSER"; public static final String FIELD_NAME_BASIC_FEATURES = "featureBasic"; public static final String FIELD_NAME_JPEGCOEFFS = "featureJpegCoeffs"; /** * Creates a new Lucene document from a BufferedImage. The identifier can be used like an id * (e.g. the file name or the url of the image) * * @param image the image to index. Cannot be NULL. * @param identifier an id for the image, for instance the filename or an URL. Can be NULL. * @return a Lucene Document containing the indexed image. */ public Document createDocument(BufferedImage image, String identifier); /** * Creates a new Lucene document from an InputStream. The identifier can be used like an id * (e.g. the file name or the url of the image) * * @param image the image to index. Cannot be NULL. * @param identifier an id for the image, for instance the filename or an URL. Can be NULL. * @return a Lucene Document containing the indexed image. * @throws IOException in case the image cannot be retrieved from the InputStream */ public Document createDocument(InputStream image, String identifier) throws IOException; }
从接口的源代码可以看出,提供了两个方法,名字都叫createDocument(),只是参数不一样,一个是从BufferedImage,另一个是从InputStream。
此外,定义了很多的字符串。
AbstractDocumentBuilder
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * -------------------- * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire; import org.apache.lucene.document.Document; import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.IOException; import java.io.InputStream; /** * Abstract DocumentBuilder, which uses javax.imageio.ImageIO to create a BufferedImage * from an InputStream. * <p/> * This file is part of the Caliph and Emir project: http://www.SemanticMetadata.net * <br>Date: 31.01.2006 * <br>Time: 23:07:39 * * @author Mathias Lux, [email protected] */ public abstract class AbstractDocumentBuilder implements DocumentBuilder { /** * Creates a new Lucene document from an InputStream. The identifier can be used like an id * (e.g. the file name or the url of the image). This is a simple implementation using * javax.imageio.ImageIO * * @param image the image to index. Please note that * @param identifier an id for the image, for instance the filename or an URL. * @return a Lucene Document containing the indexed image. * @see javax.imageio.ImageIO */ public Document createDocument(InputStream image, String identifier) throws IOException { assert (image != null); BufferedImage bufferedImage = ImageIO.read(image); return createDocument(bufferedImage, identifier); } }
从抽象类的定义可以看出,只有一个createDocument(InputStream image, String identifier),里面调用了createDocument(BufferedImage image, String identifier)。
其实说白了,就是把接口的那两个函数合成了一个函数。
DocumentBuilderFactory
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * ~~~~~~~~~~~~~~~~~~~~ * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire; import net.semanticmetadata.lire.imageanalysis.*; import net.semanticmetadata.lire.impl.ChainedDocumentBuilder; import net.semanticmetadata.lire.impl.CorrelogramDocumentBuilder; import net.semanticmetadata.lire.impl.GenericDocumentBuilder; import net.semanticmetadata.lire.impl.GenericFastDocumentBuilder; /** * Use DocumentBuilderFactory to create a DocumentBuilder, which * will create Lucene Documents from images. <br/> * This file is part of the Caliph and Emir project: http://www.SemanticMetadata.net * <br>Date: 31.01.2006 * <br>Time: 23:00:32 * * @author Mathias Lux, [email protected] */ public class DocumentBuilderFactory { /** * Creates a simple version of a DocumentBuilder. In this case the * {@link net.semanticmetadata.lire.imageanalysis.CEDD} is used as a feature * * @return a simple and efficient DocumentBuilder. * @see net.semanticmetadata.lire.imageanalysis.CEDD */ public static DocumentBuilder getDefaultDocumentBuilder() { return new GenericFastDocumentBuilder(CEDD.class, DocumentBuilder.FIELD_NAME_CEDD); } /** * Creates a simple version of a DocumentBuilder using the MPEG/-7 visual features features * all available descriptors are used. * * @return a fully featured DocumentBuilder. * @see net.semanticmetadata.lire.imageanalysis.ColorLayout * @see net.semanticmetadata.lire.imageanalysis.EdgeHistogram * @see net.semanticmetadata.lire.imageanalysis.ScalableColor * @deprecated Use ChainedDocumentBuilder instead */ public static DocumentBuilder getExtensiveDocumentBuilder() { ChainedDocumentBuilder cb = new ChainedDocumentBuilder(); cb.addBuilder(DocumentBuilderFactory.getColorLayoutBuilder()); cb.addBuilder(DocumentBuilderFactory.getEdgeHistogramBuilder()); cb.addBuilder(DocumentBuilderFactory.getScalableColorBuilder()); return cb; } /** * Creates a fast (byte[] based) version of the MPEG-7 ColorLayout document builder. * * @return the document builder. */ public static DocumentBuilder getColorLayoutBuilder() { return new GenericFastDocumentBuilder(ColorLayout.class, DocumentBuilder.FIELD_NAME_COLORLAYOUT); } /** * Creates a fast (byte[] based) version of the MPEG-7 EdgeHistogram document builder. * * @return the document builder. */ public static DocumentBuilder getEdgeHistogramBuilder() { return new GenericFastDocumentBuilder(EdgeHistogram.class, DocumentBuilder.FIELD_NAME_EDGEHISTOGRAM); } /** * Creates a fast (byte[] based) version of the MPEG-7 ColorLayout document builder. * * @return the document builder. */ public static DocumentBuilder getScalableColorBuilder() { return new GenericFastDocumentBuilder(ScalableColor.class, DocumentBuilder.FIELD_NAME_SCALABLECOLOR); } /** * Creates a simple version of a DocumentBuilder using ScalableColor. * * @return a fully featured DocumentBuilder. * @see net.semanticmetadata.lire.imageanalysis.ScalableColor * @deprecated Use ColorHistogram and the respective factory methods to get it instead */ public static DocumentBuilder getColorOnlyDocumentBuilder() { return DocumentBuilderFactory.getScalableColorBuilder(); } /** * Creates a simple version of a DocumentBuilder using the ColorLayout feature. Don't use this method any more but * use the respective feature bound method instead. * * @return a simple and fast DocumentBuilder. * @see net.semanticmetadata.lire.imageanalysis.ColorLayout * @deprecated use MPEG-7 feature ColorLayout or CEDD, which are both really fast. */ public static DocumentBuilder getFastDocumentBuilder() { return DocumentBuilderFactory.getColorLayoutBuilder(); } /** * Creates a DocumentBuilder for the AutoColorCorrelation feature. Note that the extraction of this feature * is especially slow! So use it only on small images! Images that do not fit in a 200x200 pixel box are * resized by the document builder to ensure shorter processing time. See * {@link net.semanticmetadata.lire.imageanalysis.AutoColorCorrelogram} for more information on the image feature. * Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @return the created AutoCorrelation feature DocumentBuilder. */ public static DocumentBuilder getAutoColorCorrelogramDocumentBuilder() { return new GenericDocumentBuilder(AutoColorCorrelogram.class, DocumentBuilder.FIELD_NAME_AUTOCOLORCORRELOGRAM, GenericDocumentBuilder.Mode.Fast); } /** * Creates a DocumentBuilder for the AutoColorCorrelation feature. Note that the extraction of this feature * is especially slow, but this is a more fast, but less accurate settings version! * Images that do not fit in a defined bounding box they are * resized by the document builder to ensure shorter processing time. See * {@link net.semanticmetadata.lire.imageanalysis.AutoColorCorrelogram} for more information on the image feature. * Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @return the created AutoCorrelation feature DocumentBuilder. * @deprecated Use #getAutoColorCorrelogramDocumentBuilder instead. */ public static DocumentBuilder getFastAutoColorCorrelationDocumentBuilder() { return new CorrelogramDocumentBuilder(AutoColorCorrelogram.Mode.SuperFast); } /** * Creates a DocumentBuilder for the CEDD feature. See * {@link net.semanticmetadata.lire.imageanalysis.CEDD} for more information on the image feature. * Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @return the created CEDD feature DocumentBuilder. */ public static DocumentBuilder getCEDDDocumentBuilder() { // return new CEDDDocumentBuilder(); return new GenericFastDocumentBuilder(CEDD.class, DocumentBuilder.FIELD_NAME_CEDD); } /** * Creates a DocumentBuilder for the FCTH feature. See * {@link net.semanticmetadata.lire.imageanalysis.FCTH} for more information on the image feature. * Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @return the created FCTH feature DocumentBuilder. */ public static DocumentBuilder getFCTHDocumentBuilder() { return new GenericDocumentBuilder(FCTH.class, DocumentBuilder.FIELD_NAME_FCTH, GenericDocumentBuilder.Mode.Fast); } /** * Creates a DocumentBuilder for the JCD feature. See * {@link net.semanticmetadata.lire.imageanalysis.JCD} for more information on the image feature. * Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @return the created DocumentBuilder */ public static DocumentBuilder getJCDDocumentBuilder() { return new GenericFastDocumentBuilder(JCD.class, DocumentBuilder.FIELD_NAME_JCD); } /** * Creates a DocumentBuilder for the JpegCoefficientHistogram feature. See * {@link net.semanticmetadata.lire.imageanalysis.JpegCoefficientHistogram} for more * information on the image feature. * Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @return the created DocumentBuilder */ public static DocumentBuilder getJpegCoefficientHistogramDocumentBuilder() { return new GenericDocumentBuilder(JpegCoefficientHistogram.class, DocumentBuilder.FIELD_NAME_JPEGCOEFFS, GenericDocumentBuilder.Mode.Fast); } /** * Creates a DocumentBuilder for simple RGB color histograms. See * {@link net.semanticmetadata.lire.imageanalysis.SimpleColorHistogram} for more * information on the image feature. * Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @return the created feature DocumentBuilder. */ public static DocumentBuilder getColorHistogramDocumentBuilder() { return new GenericDocumentBuilder(SimpleColorHistogram.class, DocumentBuilder.FIELD_NAME_COLORHISTOGRAM, GenericDocumentBuilder.Mode.Fast); } /** * Creates a DocumentBuilder for three Tamura features. See * {@link net.semanticmetadata.lire.imageanalysis.Tamura} for more * information on the image feature. * Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @return the created Tamura feature DocumentBuilder. */ public static DocumentBuilder getTamuraDocumentBuilder() { return new GenericFastDocumentBuilder(Tamura.class, DocumentBuilder.FIELD_NAME_TAMURA); } /** * Creates a DocumentBuilder for the Gabor feature. See * {@link net.semanticmetadata.lire.imageanalysis.Gabor} for more * information on the image feature. * Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @return the created Tamura feature DocumentBuilder. */ public static DocumentBuilder getGaborDocumentBuilder() { return new GenericFastDocumentBuilder(Gabor.class, DocumentBuilder.FIELD_NAME_GABOR); } /** * Creates and returns a DocumentBuilder, which contains all available features. For * AutoColorCorrelogram the getAutoColorCorrelogramDocumentBuilder() is used. Therefore * it is compatible with the respective Searcher. * * @return a combination of all available features. */ public static DocumentBuilder getFullDocumentBuilder() { ChainedDocumentBuilder cdb = new ChainedDocumentBuilder(); cdb.addBuilder(DocumentBuilderFactory.getExtensiveDocumentBuilder()); cdb.addBuilder(DocumentBuilderFactory.getAutoColorCorrelogramDocumentBuilder()); cdb.addBuilder(DocumentBuilderFactory.getCEDDDocumentBuilder()); cdb.addBuilder(DocumentBuilderFactory.getFCTHDocumentBuilder()); cdb.addBuilder(DocumentBuilderFactory.getColorHistogramDocumentBuilder()); cdb.addBuilder(DocumentBuilderFactory.getTamuraDocumentBuilder()); cdb.addBuilder(DocumentBuilderFactory.getGaborDocumentBuilder()); return cdb; } }
DocumentBuilderFactory是用于创建DocumentBuilder的。里面有各种get****DocumentBuilder()。其中以下2种是几个DocumentBuilder的合集:
getExtensiveDocumentBuilder():使用MPEG-7中的ColorLayout,EdgeHistogram,ScalableColor
getFullDocumentBuilder():使用所有的DocumentBuilder
3:基本接口(ImageSearcher)
上篇文章介绍了LIRe源代码里的DocumentBuilder的几个基本接口。本文继续研究一下源代码里的ImageSearcher的几个基本接口。
下面来看看与ImageSearcher相关的类的定义:
ImageSearcher:接口,定义了基本的方法。
AbstractImageSearcher:纯虚类,实现了ImageSearcher接口。
ImageSearcherFactory:用于创建ImageSearcher。
ImageSearcher相关的类的继承关系如下图所示。可见,各种算法类都继承了AbstractImageSearcher,而AbstractImageSearcher实现了ImageSearcher接口。
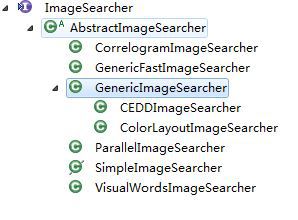
此外还有一个结构体:
ImageSearchHits:用于存储搜索的结果。
详细的源代码如下所示:
ImageSearcher
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * -------------------- * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire; import org.apache.lucene.document.Document; import org.apache.lucene.index.IndexReader; import java.awt.image.BufferedImage; import java.io.IOException; import java.io.InputStream; import java.util.Set; /** * <h2>Searching in an Index</h2> * Use the ImageSearcherFactory for creating an ImageSearcher, which will retrieve the images * for you from the index. * <p/> * <pre> * IndexReader reader = IndexReader.open(indexPath); * ImageSearcher searcher = ImageSearcherFactory.createDefaultSearcher(); * FileInputStream imageStream = new FileInputStream("image.jpg"); * BufferedImage bimg = ImageIO.read(imageStream); * // searching for an image: * ImageSearchHits hits = null; * hits = searcher.search(bimg, reader); * for (int i = 0; i < 5; i++) { * System.out.println(hits.score(i) + ": " + hits.doc(i).getField(DocumentBuilder.FIELD_NAME_IDENTIFIER).stringValue()); * } * * // searching for a document: * Document document = hits.doc(0); * hits = searcher.search(document, reader); * for (int i = 0; i < 5; i++) { * System.out.println(hits.score(i) + ": " + hits.doc(i).getField(DocumentBuilder.FIELD_NAME_IDENTIFIER).stringValue()); * } * </pre> * <p/> * This file is part of the Caliph and Emir project: http://www.SemanticMetadata.net * <br>Date: 01.02.2006 * <br>Time: 00:09:42 * * @author Mathias Lux, [email protected] */ public interface ImageSearcher { /** * Searches for images similar to the given image. * * @param image the example image to search for. * @param reader the IndexReader which is used to dsearch through the images. * @return a sorted list of hits. * @throws java.io.IOException in case exceptions in the reader occurs */ public ImageSearchHits search(BufferedImage image, IndexReader reader) throws IOException; /** * Searches for images similar to the given image, defined by the Document from the index. * * @param doc the example image to search for. * @param reader the IndexReader which is used to dsearch through the images. * @return a sorted list of hits. * @throws java.io.IOException in case exceptions in the reader occurs */ public ImageSearchHits search(Document doc, IndexReader reader) throws IOException; /** * Searches for images similar to the given image. * * @param image the example image to search for. * @param reader the IndexReader which is used to dsearch through the images. * @return a sorted list of hits. * @throws IOException in case the image could not be read from stream. */ public ImageSearchHits search(InputStream image, IndexReader reader) throws IOException; /** * Identifies duplicates in the database. * * @param reader the IndexReader which is used to dsearch through the images. * @return a sorted list of hits. * @throws IOException in case the image could not be read from stream. */ public ImageDuplicates findDuplicates(IndexReader reader) throws IOException; /** * Modifies the given search by the provided positive and negative examples. This process follows the idea * of relevance feedback. * * @param originalSearch * @param positives * @param negatives * @return */ public ImageSearchHits relevanceFeedback(ImageSearchHits originalSearch, Set<Document> positives, Set<Document> negatives); }
从接口的源代码可以看出,提供了5个方法,其中有3个名字都叫search(),只是参数不一样。一个是BufferedImage,一个是Document,而另一个是InputStream。
AbstractImageSearcher
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * -------------------- * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire; import org.apache.lucene.document.Document; import org.apache.lucene.index.IndexReader; import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.IOException; import java.io.InputStream; import java.util.Set; /** * Abstract ImageSearcher, which uses javax.imageio.ImageIO to create a BufferedImage * from an InputStream. * <p/> * This file is part of the Caliph and Emir project: http://www.SemanticMetadata.net * <br>Date: 01.02.2006 * <br>Time: 00:13:16 * * @author Mathias Lux, [email protected] */ public abstract class AbstractImageSearcher implements ImageSearcher { /** * Searches for images similar to the given image. This simple implementation uses * {@link ImageSearcher#search(java.awt.image.BufferedImage, org.apache.lucene.index.IndexReader)}, * the image is read using javax.imageio.ImageIO. * * @param image the example image to search for. * @param reader the IndexReader which is used to dsearch through the images. * @return a sorted list of hits. * @throws IOException in case the image could not be read from stream. */ public ImageSearchHits search(InputStream image, IndexReader reader) throws IOException { BufferedImage bufferedImage = ImageIO.read(image); return search(bufferedImage, reader); } public ImageSearchHits relevanceFeedback(ImageSearchHits originalSearch, Set<Document> positives, Set<Document> negatives) { throw new UnsupportedOperationException("Not implemented yet for this kind of searcher!"); } }
从代码中可以看出AbstractImageSearcher实现了ImageSearcher接口。其中的search(InputStream image, IndexReader reader)方法调用了search(BufferedImage image, IndexReader reader)方法。说白了,就是把2个函数的功能合并为一个函数。
ImageSearcherFactory
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * ~~~~~~~~~~~~~~~~~~~~ * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire; import net.semanticmetadata.lire.imageanalysis.*; import net.semanticmetadata.lire.impl.CorrelogramImageSearcher; import net.semanticmetadata.lire.impl.GenericFastImageSearcher; import net.semanticmetadata.lire.impl.SimpleImageSearcher; /** * <h2>Searching in an Index</h2> * Use the ImageSearcherFactory for creating an ImageSearcher, which will retrieve the images * for you from the index. * <p/> * <pre> * IndexReader reader = IndexReader.open(indexPath); * ImageSearcher searcher = ImageSearcherFactory.createDefaultSearcher(); * FileInputStream imageStream = new FileInputStream("image.jpg"); * BufferedImage bimg = ImageIO.read(imageStream); * // searching for an image: * ImageSearchHits hits = null; * hits = searcher.search(bimg, reader); * for (int i = 0; i < 5; i++) { * System.out.println(hits.score(i) + ": " + hits.doc(i).getField(DocumentBuilder.FIELD_NAME_IDENTIFIER).stringValue()); * } * * // searching for a document: * Document document = hits.doc(0); * hits = searcher.search(document, reader); * for (int i = 0; i < 5; i++) { * System.out.println(hits.score(i) + ": " + hits.doc(i).getField(DocumentBuilder.FIELD_NAME_IDENTIFIER).stringValue()); * } * </pre> * <p/> * This file is part of the Caliph and Emir project: http://www.SemanticMetadata.net * <br>Date: 03.02.2006 * <br>Time: 00:30:07 * * @author Mathias Lux, [email protected] */ public class ImageSearcherFactory { /** * Default number of maximum hits. */ public static int NUM_MAX_HITS = 100; /** * Creates a new simple image searcher with the desired number of maximum hits. * * @param maximumHits * @return the searcher instance * @deprecated Use ColorLayout, EdgeHistogram and ScalableColor features instead. */ public static ImageSearcher createSimpleSearcher(int maximumHits) { return ImageSearcherFactory.createColorLayoutImageSearcher(maximumHits); } /** * Returns a new default ImageSearcher with a predefined number of maximum * hits defined in the {@link ImageSearcherFactory#NUM_MAX_HITS} based on the {@link net.semanticmetadata.lire.imageanalysis.CEDD} feature * * @return the searcher instance */ public static ImageSearcher createDefaultSearcher() { return new GenericFastImageSearcher(NUM_MAX_HITS, CEDD.class, DocumentBuilder.FIELD_NAME_CEDD); } /** * Returns a new ImageSearcher with the given number of maximum hits * which only takes the overall color into account. texture and color * distribution are ignored. * * @param maximumHits defining how many hits are returned in max (e.g. 100 would be ok) * @return the ImageSearcher * @see ImageSearcher * @deprecated Use ColorHistogram or ScalableColor instead */ public static ImageSearcher createColorOnlySearcher(int maximumHits) { return ImageSearcherFactory.createScalableColorImageSearcher(maximumHits); } /** * Returns a new ImageSearcher with the given number of maximum hits and * the specified weights on the different matching aspects. All weights * should be in [0,1] whereas a weight of 0 implies that the feature is * not taken into account for searching. Note that the effect is relative and * can only be fully applied if the {@link DocumentBuilderFactory#getExtensiveDocumentBuilder() extensive DocumentBuilder} * is used. * * @param maximumHits defining how many hits are returned in max * @param colorHistogramWeight a weight in [0,1] defining the importance of overall color in the images * @param colorDistributionWeight a weight in [0,1] defining the importance of color distribution (which color where) in the images * @param textureWeight defining the importance of texture (which edges where) in the images * @return the searcher instance or NULL if the weights are not appropriate, eg. all 0 or not in [0,1] * @see DocumentBuilderFactory * @deprecated Use ColorLayout, EdgeHistogram and ScalableColor features instead. */ public static ImageSearcher createWeightedSearcher(int maximumHits, float colorHistogramWeight, float colorDistributionWeight, float textureWeight) { if (isAppropriateWeight(colorHistogramWeight) && isAppropriateWeight(colorDistributionWeight) && isAppropriateWeight(textureWeight) && (colorHistogramWeight + colorDistributionWeight + textureWeight > 0f)) return new SimpleImageSearcher(maximumHits, colorHistogramWeight, colorDistributionWeight, textureWeight); else return null; } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.AutoColorCorrelogram} * image feature. Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @param maximumHits number of hits returned. * @return */ public static ImageSearcher createAutoColorCorrelogramImageSearcher(int maximumHits) { return new GenericFastImageSearcher(maximumHits, AutoColorCorrelogram.class, DocumentBuilder.FIELD_NAME_AUTOCOLORCORRELOGRAM); // return new CorrelogramImageSearcher(maximumHits, AutoColorCorrelogram.Mode.SuperFast); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.AutoColorCorrelogram} * image feature. Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @param maximumHits number of hits returned. * @return * @deprecated Use #createAutoColorCorrelogramImageSearcher instead */ public static ImageSearcher createFastCorrelogramImageSearcher(int maximumHits) { return new CorrelogramImageSearcher(maximumHits, AutoColorCorrelogram.Mode.SuperFast); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.CEDD} * image feature. Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createCEDDImageSearcher(int maximumHits) { // return new CEDDImageSearcher(maximumHits); return new GenericFastImageSearcher(maximumHits, CEDD.class, DocumentBuilder.FIELD_NAME_CEDD); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.FCTH} * image feature. Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createFCTHImageSearcher(int maximumHits) { // return new GenericImageSearcher(maximumHits, FCTH.class, DocumentBuilder.FIELD_NAME_FCTH); return new GenericFastImageSearcher(maximumHits, FCTH.class, DocumentBuilder.FIELD_NAME_FCTH); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.JCD} * image feature. Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createJCDImageSearcher(int maximumHits) { return new GenericFastImageSearcher(maximumHits, JCD.class, DocumentBuilder.FIELD_NAME_JCD); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.JpegCoefficientHistogram} * image feature. Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createJpegCoefficientHistogramImageSearcher(int maximumHits) { return new GenericFastImageSearcher(maximumHits, JpegCoefficientHistogram.class, DocumentBuilder.FIELD_NAME_JPEGCOEFFS); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.SimpleColorHistogram} * image feature. Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createColorHistogramImageSearcher(int maximumHits) { // return new GenericImageSearcher(maximumHits, SimpleColorHistogram.class, DocumentBuilder.FIELD_NAME_COLORHISTOGRAM); return new GenericFastImageSearcher(maximumHits, SimpleColorHistogram.class, DocumentBuilder.FIELD_NAME_COLORHISTOGRAM); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.Tamura} * image feature. Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createTamuraImageSearcher(int maximumHits) { return new GenericFastImageSearcher(maximumHits, Tamura.class, DocumentBuilder.FIELD_NAME_TAMURA); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.Gabor} * image feature. Be sure to use the same options for the ImageSearcher as you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createGaborImageSearcher(int maximumHits) { return new GenericFastImageSearcher(maximumHits, Gabor.class, DocumentBuilder.FIELD_NAME_GABOR); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.ColorLayout} * image feature using the byte[] serialization. Be sure to use the same options for the ImageSearcher as * you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createColorLayoutImageSearcher(int maximumHits) { return new GenericFastImageSearcher(maximumHits, ColorLayout.class, DocumentBuilder.FIELD_NAME_COLORLAYOUT); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.ScalableColor} * image feature using the byte[] serialization. Be sure to use the same options for the ImageSearcher as * you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createScalableColorImageSearcher(int maximumHits) { return new GenericFastImageSearcher(maximumHits, ScalableColor.class, DocumentBuilder.FIELD_NAME_SCALABLECOLOR); } /** * Create and return an ImageSearcher for the {@link net.semanticmetadata.lire.imageanalysis.EdgeHistogram} * image feature using the byte[] serialization. Be sure to use the same options for the ImageSearcher as * you used for the DocumentBuilder. * * @param maximumHits * @return */ public static ImageSearcher createEdgeHistogramImageSearcher(int maximumHits) { return new GenericFastImageSearcher(maximumHits, EdgeHistogram.class, DocumentBuilder.FIELD_NAME_EDGEHISTOGRAM); } /** * Checks if the weight is in [0,1] * * @param f the weight to check * @return true if the weight is in [0,1], false otherwise */ private static boolean isAppropriateWeight(float f) { boolean result = false; if (f <= 1f && f >= 0) result = true; return result; } }
ImageSearcherFactory是用于创建ImageSearcher的。里面有各种create****ImageSearcher()。每个函数的作用在注释中都有详细的说明。
ImageSearchHits
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * -------------------- * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire; import org.apache.lucene.document.Document; /** * This class simulates the original Lucene Hits object. * Please note the only a certain number of results are returned.<br> * <p/> * This file is part of the Caliph and Emir project: http://www.SemanticMetadata.net * <br>Date: 02.02.2006 * <br>Time: 23:45:20 * * @author Mathias Lux, [email protected] */ public interface ImageSearchHits { /** * Returns the size of the result list. * * @return the size of the result list. */ public int length(); /** * Returns the score of the document at given position. * Please note that the score in this case is a distance, * which means a score of 0 denotes the best possible hit. * The result list starts with position 0 as everything * in computer science does. * * @param position defines the position * @return the score of the document at given position. The lower the better (its a distance measure). */ public float score(int position); /** * Returns the document at given position * * @param position defines the position. * @return the document at given position. */ public Document doc(int position); }
该类主要用于存储ImageSearcher类中search()方法返回的结果。
SimpleImageSearchHits是ImageSearcher的实现。该类的源代码如下所示:
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * -------------------- * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire.impl; import net.semanticmetadata.lire.ImageSearchHits; import org.apache.lucene.document.Document; import java.util.ArrayList; import java.util.Collection; import java.util.Iterator; /** * This file is part of the Caliph and Emir project: http://www.SemanticMetadata.net * <br>Date: 02.02.2006 * <br>Time: 23:56:15 * * @author Mathias Lux, [email protected] */ public class SimpleImageSearchHits implements ImageSearchHits { ArrayList<SimpleResult> results; public SimpleImageSearchHits(Collection<SimpleResult> results, float maxDistance) { this.results = new ArrayList<SimpleResult>(results.size()); this.results.addAll(results); // this step normalizes and inverts the distance ... // although its now a score or similarity like measure its further called distance for (Iterator<SimpleResult> iterator = this.results.iterator(); iterator.hasNext(); ) { SimpleResult result = iterator.next(); result.setDistance(1f - result.getDistance() / maxDistance); } } /** * Returns the size of the result list. * * @return the size of the result list. */ public int length() { return results.size(); } /** * Returns the score of the document at given position. * Please note that the score in this case is a distance, * which means a score of 0 denotes the best possible hit. * The result list starts with position 0 as everything * in computer science does. * * @param position defines the position * @return the score of the document at given position. The lower the better (its a distance measure). */ public float score(int position) { return results.get(position).getDistance(); } /** * Returns the document at given position * * @param position defines the position. * @return the document at given position. */ public Document doc(int position) { return results.get(position).getDocument(); } private float sigmoid(float f) { double result = 0f; result = -1d + 2d / (1d + Math.exp(-2d * f / 0.6)); return (float) (1d - result); } }
可以看出检索的结果是存在名为results的ArrayList<SimpleResult> 类型的变量中的。
4:建立索引(DocumentBuilder)[以颜色布局为例]
前几篇文章介绍了LIRe 的基本接口。现在来看一看它的实现部分,本文先来看一看建立索引((DocumentBuilder))部分。不同的特征向量提取方法的建立索引的类各不相同,它们都位于“net.semanticmetadata.lire.impl”中,如下图所示:
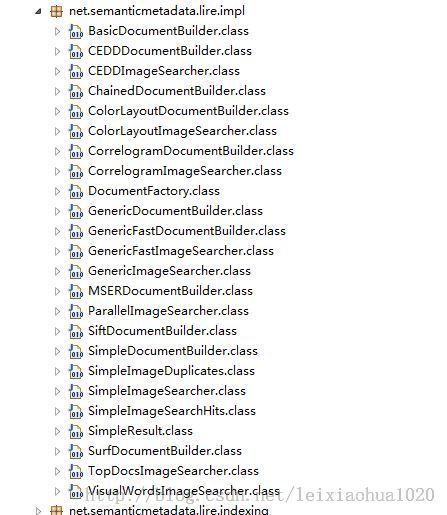
由图可见,每一种方法对应一个DocumentBuilder和一个ImageSearcher,类的数量非常的多,无法一一分析。在这里仅分析一个比较有代表性的:颜色布局。
颜色直方图建立索引的类的名称是ColorLayoutDocumentBuilder,该类继承了AbstractDocumentBuilder,它的源代码如下所示:
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * -------------------- * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire.impl; import net.semanticmetadata.lire.AbstractDocumentBuilder; import net.semanticmetadata.lire.DocumentBuilder; import net.semanticmetadata.lire.imageanalysis.ColorLayout; import net.semanticmetadata.lire.utils.ImageUtils; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import java.awt.image.BufferedImage; import java.util.logging.Logger; /** * Provides a faster way of searching based on byte arrays instead of Strings. The method * {@link net.semanticmetadata.lire.imageanalysis.ColorLayout#getByteArrayRepresentation()} is used * to generate the signature of the descriptor much faster. * User: Mathias Lux, [email protected] * Date: 30.06.2011 */ public class ColorLayoutDocumentBuilder extends AbstractDocumentBuilder { private Logger logger = Logger.getLogger(getClass().getName()); public static final int MAX_IMAGE_DIMENSION = 1024; public Document createDocument(BufferedImage image, String identifier) { assert (image != null); BufferedImage bimg = image; // Scaling image is especially with the correlogram features very important! // All images are scaled to guarantee a certain upper limit for indexing. if (Math.max(image.getHeight(), image.getWidth()) > MAX_IMAGE_DIMENSION) { bimg = ImageUtils.scaleImage(image, MAX_IMAGE_DIMENSION); } Document doc = null; logger.finer("Starting extraction from image [ColorLayout - fast]."); ColorLayout vd = new ColorLayout(); vd.extract(bimg); logger.fine("Extraction finished [ColorLayout - fast]."); doc = new Document(); doc.add(new Field(DocumentBuilder.FIELD_NAME_COLORLAYOUT_FAST, vd.getByteArrayRepresentation())); if (identifier != null) doc.add(new Field(DocumentBuilder.FIELD_NAME_IDENTIFIER, identifier, Field.Store.YES, Field.Index.NOT_ANALYZED)); return doc; } }
从源代码来看,其实主要就一个函数:createDocument(BufferedImage image, String identifier),该函数的流程如下所示:
1.如果输入的图像分辨率过大(在这里是大于1024),则将图像缩小。
2.新建一个ColorLayout类型的对象vd。
3.调用vd.extract()提取特征向量。
4.调用vd.getByteArrayRepresentation()获得特征向量。
5.将获得的特征向量加入Document,返回Document。
其实其他方法的DocumentBuilder的实现和颜色直方图的DocumentBuilder差不多。例如CEDDDocumentBuilder的源代码如下所示:
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * ~~~~~~~~~~~~~~~~~~~~ * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire.impl; import net.semanticmetadata.lire.AbstractDocumentBuilder; import net.semanticmetadata.lire.DocumentBuilder; import net.semanticmetadata.lire.imageanalysis.CEDD; import net.semanticmetadata.lire.utils.ImageUtils; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import java.awt.image.BufferedImage; import java.util.logging.Logger; /** * Provides a faster way of searching based on byte arrays instead of Strings. The method * {@link net.semanticmetadata.lire.imageanalysis.CEDD#getByteArrayRepresentation()} is used * to generate the signature of the descriptor much faster. * User: Mathias Lux, [email protected] * Date: 12.03.2010 * Time: 13:21:35 * * @see GenericFastDocumentBuilder * @deprecated use GenericFastDocumentBuilder instead. */ public class CEDDDocumentBuilder extends AbstractDocumentBuilder { private Logger logger = Logger.getLogger(getClass().getName()); public static final int MAX_IMAGE_DIMENSION = 1024; public Document createDocument(BufferedImage image, String identifier) { assert (image != null); BufferedImage bimg = image; // Scaling image is especially with the correlogram features very important! // All images are scaled to guarantee a certain upper limit for indexing. if (Math.max(image.getHeight(), image.getWidth()) > MAX_IMAGE_DIMENSION) { bimg = ImageUtils.scaleImage(image, MAX_IMAGE_DIMENSION); } Document doc = null; logger.finer("Starting extraction from image [CEDD - fast]."); CEDD vd = new CEDD(); vd.extract(bimg); logger.fine("Extraction finished [CEDD - fast]."); doc = new Document(); doc.add(new Field(DocumentBuilder.FIELD_NAME_CEDD, vd.getByteArrayRepresentation())); if (identifier != null) doc.add(new Field(DocumentBuilder.FIELD_NAME_IDENTIFIER, identifier, Field.Store.YES, Field.Index.NOT_ANALYZED)); return doc; } }
5:提取特征向量[以颜色布局为例]
在上一篇文章中,讲述了建立索引的过程。这里继续上一篇文章的分析。在ColorLayoutDocumentBuilder中,使用了一个类型为ColorLayout的对象vd,并且调用了vd的extract()方法:
ColorLayout vd = new ColorLayout(); vd.extract(bimg);
此外调用了vd的getByteArrayRepresentation()方法:
new Field(DocumentBuilder.FIELD_NAME_COLORLAYOUT_FAST, vd.getByteArrayRepresentation())
在这里我们看一看ColorLayout是个什么类。ColorLayout位于“net.semanticmetadata.lire.imageanalysis”包中,如下图所示:

由图可见,这个包中有很多的类。这些类都是以检索方法的名字命名的。我们要找的ColorLayout类也在其中。看看它的代码吧:
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * -------------------- * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire.imageanalysis; import net.semanticmetadata.lire.imageanalysis.mpeg7.ColorLayoutImpl; import net.semanticmetadata.lire.utils.SerializationUtils; /** * Just a wrapper for the use of LireFeature. * Date: 27.08.2008 * Time: 12:07:38 * * @author Mathias Lux, [email protected] */ public class ColorLayout extends ColorLayoutImpl implements LireFeature { /* public String getStringRepresentation() { StringBuilder sb = new StringBuilder(256); StringBuilder sbtmp = new StringBuilder(256); for (int i = 0; i < numYCoeff; i++) { sb.append(YCoeff[i]); if (i + 1 < numYCoeff) sb.append(' '); } sb.append("z"); for (int i = 0; i < numCCoeff; i++) { sb.append(CbCoeff[i]); if (i + 1 < numCCoeff) sb.append(' '); sbtmp.append(CrCoeff[i]); if (i + 1 < numCCoeff) sbtmp.append(' '); } sb.append("z"); sb.append(sbtmp); return sb.toString(); } public void setStringRepresentation(String descriptor) { String[] coeffs = descriptor.split("z"); String[] y = coeffs[0].split(" "); String[] cb = coeffs[1].split(" "); String[] cr = coeffs[2].split(" "); numYCoeff = y.length; numCCoeff = Math.min(cb.length, cr.length); YCoeff = new int[numYCoeff]; CbCoeff = new int[numCCoeff]; CrCoeff = new int[numCCoeff]; for (int i = 0; i < numYCoeff; i++) { YCoeff[i] = Integer.parseInt(y[i]); } for (int i = 0; i < numCCoeff; i++) { CbCoeff[i] = Integer.parseInt(cb[i]); CrCoeff[i] = Integer.parseInt(cr[i]); } } */ /** * Provides a much faster way of serialization. * * @return a byte array that can be read with the corresponding method. * @see net.semanticmetadata.lire.imageanalysis.CEDD#setByteArrayRepresentation(byte[]) */ public byte[] getByteArrayRepresentation() { byte[] result = new byte[2 * 4 + numYCoeff * 4 + 2 * numCCoeff * 4]; System.arraycopy(SerializationUtils.toBytes(numYCoeff), 0, result, 0, 4); System.arraycopy(SerializationUtils.toBytes(numCCoeff), 0, result, 4, 4); System.arraycopy(SerializationUtils.toByteArray(YCoeff), 0, result, 8, numYCoeff * 4); System.arraycopy(SerializationUtils.toByteArray(CbCoeff), 0, result, numYCoeff * 4 + 8, numCCoeff * 4); System.arraycopy(SerializationUtils.toByteArray(CrCoeff), 0, result, numYCoeff * 4 + numCCoeff * 4 + 8, numCCoeff * 4); return result; } /** * Reads descriptor from a byte array. Much faster than the String based method. * * @param in byte array from corresponding method * @see net.semanticmetadata.lire.imageanalysis.CEDD#getByteArrayRepresentation */ public void setByteArrayRepresentation(byte[] in) { int[] data = SerializationUtils.toIntArray(in); numYCoeff = data[0]; numCCoeff = data[1]; YCoeff = new int[numYCoeff]; CbCoeff = new int[numCCoeff]; CrCoeff = new int[numCCoeff]; System.arraycopy(data, 2, YCoeff, 0, numYCoeff); System.arraycopy(data, 2 + numYCoeff, CbCoeff, 0, numCCoeff); System.arraycopy(data, 2 + numYCoeff + numCCoeff, CrCoeff, 0, numCCoeff); } public double[] getDoubleHistogram() { double[] result = new double[numYCoeff + numCCoeff * 2]; for (int i = 0; i < numYCoeff; i++) { result[i] = YCoeff[i]; } for (int i = 0; i < numCCoeff; i++) { result[i + numYCoeff] = CbCoeff[i]; result[i + numCCoeff + numYCoeff] = CrCoeff[i]; } return result; } /** * Compares one descriptor to another. * * @param descriptor * @return the distance from [0,infinite) or -1 if descriptor type does not match */ public float getDistance(LireFeature descriptor) { if (!(descriptor instanceof ColorLayoutImpl)) return -1f; ColorLayoutImpl cl = (ColorLayoutImpl) descriptor; return (float) ColorLayoutImpl.getSimilarity(YCoeff, CbCoeff, CrCoeff, cl.YCoeff, cl.CbCoeff, cl.CrCoeff); } }
ColorLayout类继承了ColorLayoutImpl类,同时实现了LireFeature接口。其中的方法大部分都是实现了LireFeature接口的方法。先来看看LireFeature接口是什么样子的:
注:这里没有注释了,仅能靠自己的理解了。
/** * This is the basic interface for all content based features. It is needed for GenericDocumentBuilder etc. * Date: 28.05.2008 * Time: 14:44:16 * * @author Mathias Lux, [email protected] */ public interface LireFeature { public void extract(BufferedImage bimg); public byte[] getByteArrayRepresentation(); public void setByteArrayRepresentation(byte[] in); public double[] getDoubleHistogram(); float getDistance(LireFeature feature); java.lang.String getStringRepresentation(); void setStringRepresentation(java.lang.String s); }
我简要概括一下自己对这些接口函数的理解:
1.extract(BufferedImage bimg):提取特征向量
2.getByteArrayRepresentation():获取特征向量(返回byte[]类型)
3.setByteArrayRepresentation(byte[] in):设置特征向量(byte[]类型)
4.getDoubleHistogram():
5.getDistance(LireFeature feature):
6.getStringRepresentation():获取特征向量(返回String类型)
7.setStringRepresentation(java.lang.String s):设置特征向量(String类型)
其中咖啡色的是建立索引的过程中会用到的。
看代码的过程中发现,所有的算法都实现了LireFeature接口,如下图所示:
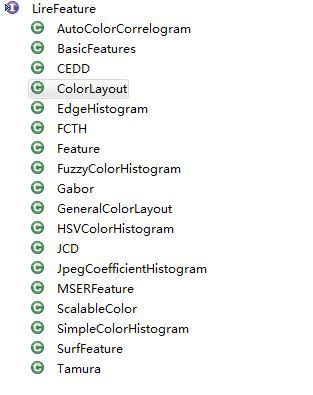
不再研究LireFeature接口,回过头来本来想看看ColorLayoutImpl类,但是没想到代码其长无比,都是些算法,暂时没有这个耐心了,以后有机会再看吧。以下贴出个简略版的。注意:该类中实现了extract(BufferedImage bimg)方法。其他方法例如getByteArrayRepresentation()则在ColorLayout中实现。
package net.semanticmetadata.lire.imageanalysis.mpeg7; import java.awt.image.BufferedImage; import java.awt.image.WritableRaster; /** * Class for extrcating & comparing MPEG-7 based CBIR descriptor ColorLayout * * @author Mathias Lux, [email protected] */ public class ColorLayoutImpl { // static final boolean debug = true; protected int[][] shape; protected int imgYSize, imgXSize; protected BufferedImage img; protected static int[] availableCoeffNumbers = {1, 3, 6, 10, 15, 21, 28, 64}; public int[] YCoeff; public int[] CbCoeff; public int[] CrCoeff; protected int numCCoeff = 28, numYCoeff = 64; protected static int[] arrayZigZag = { 0, 1, 8, 16, 9, 2, 3, 10, 17, 24, 32, 25, 18, 11, 4, 5, 12, 19, 26, 33, 40, 48, 41, 34, 27, 20, 13, 6, 7, 14, 21, 28, 35, 42, 49, 56, 57, 50, 43, 36, 29, 22, 15, 23, 30, 37, 44, 51, 58, 59, 52, 45, 38, 31, 39, 46, 53, 60, 61, 54, 47, 55, 62, 63 }; ... public void extract(BufferedImage bimg) { this.img = bimg; imgYSize = img.getHeight(); imgXSize = img.getWidth(); init(); } ... }
6:检索(ImageSearcher)[以颜色布局为例]
前几篇文章介绍了LIRe 的基本接口,以及建立索引的过程。现在来看一看它的检索部分(ImageSearcher)。不同的方法的检索功能的类各不相同,它们都位于“net.semanticmetadata.lire.impl”中,如下图所示:

在这里仅分析一个比较有代表性的:颜色布局。前文已经分析过ColorLayoutDocumentBuilder,在这里我们分析一下ColorLayoutImageSearcher。源代码如下:
/* * This file is part of the LIRe project: http://www.semanticmetadata.net/lire * LIRe is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License as published by * the Free Software Foundation; either version 2 of the License, or * (at your option) any later version. * * LIRe is distributed in the hope that it will be useful, * but WITHOUT ANY WARRANTY; without even the implied warranty of * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the * GNU General Public License for more details. * * You should have received a copy of the GNU General Public License * along with LIRe; if not, write to the Free Software * Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA * * We kindly ask you to refer the following paper in any publication mentioning Lire: * * Lux Mathias, Savvas A. Chatzichristofis. Lire: Lucene Image Retrieval 鈥� * An Extensible Java CBIR Library. In proceedings of the 16th ACM International * Conference on Multimedia, pp. 1085-1088, Vancouver, Canada, 2008 * * http://doi.acm.org/10.1145/1459359.1459577 * * Copyright statement: * -------------------- * (c) 2002-2011 by Mathias Lux ([email protected]) * http://www.semanticmetadata.net/lire */ package net.semanticmetadata.lire.impl; import net.semanticmetadata.lire.DocumentBuilder; import net.semanticmetadata.lire.ImageDuplicates; import net.semanticmetadata.lire.ImageSearchHits; import net.semanticmetadata.lire.imageanalysis.ColorLayout; import net.semanticmetadata.lire.imageanalysis.LireFeature; import org.apache.lucene.document.Document; import org.apache.lucene.index.IndexReader; import java.io.FileNotFoundException; import java.io.IOException; import java.util.HashMap; import java.util.LinkedList; import java.util.List; import java.util.logging.Level; /** * Provides a faster way of searching based on byte arrays instead of Strings. The method * {@link net.semanticmetadata.lire.imageanalysis.ColorLayout#getByteArrayRepresentation()} is used * to generate the signature of the descriptor much faster. First tests have shown that this * implementation is up to 4 times faster than the implementation based on strings * (for 120,000 images) * <p/> * User: Mathias Lux, [email protected] * Date: 30.06 2011 */ public class ColorLayoutImageSearcher extends GenericImageSearcher { public ColorLayoutImageSearcher(int maxHits) { super(maxHits, ColorLayout.class, DocumentBuilder.FIELD_NAME_COLORLAYOUT_FAST); } protected float getDistance(Document d, LireFeature lireFeature) { float distance = 0f; ColorLayout lf; try { lf = (ColorLayout) descriptorClass.newInstance(); byte[] cls = d.getBinaryValue(fieldName); if (cls != null && cls.length > 0) { lf.setByteArrayRepresentation(cls); distance = lireFeature.getDistance(lf); } else { logger.warning("No feature stored in this document ..."); } } catch (InstantiationException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } catch (IllegalAccessException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } return distance; } public ImageSearchHits search(Document doc, IndexReader reader) throws IOException { SimpleImageSearchHits searchHits = null; try { ColorLayout lireFeature = (ColorLayout) descriptorClass.newInstance(); byte[] cls = doc.getBinaryValue(fieldName); if (cls != null && cls.length > 0) lireFeature.setByteArrayRepresentation(cls); float maxDistance = findSimilar(reader, lireFeature); searchHits = new SimpleImageSearchHits(this.docs, maxDistance); } catch (InstantiationException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } catch (IllegalAccessException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } return searchHits; } public ImageDuplicates findDuplicates(IndexReader reader) throws IOException { // get the first document: SimpleImageDuplicates simpleImageDuplicates = null; try { if (!IndexReader.indexExists(reader.directory())) throw new FileNotFoundException("No index found at this specific location."); Document doc = reader.document(0); ColorLayout lireFeature = (ColorLayout) descriptorClass.newInstance(); byte[] cls = doc.getBinaryValue(fieldName); if (cls != null && cls.length > 0) lireFeature.setByteArrayRepresentation(cls); HashMap<Float, List<String>> duplicates = new HashMap<Float, List<String>>(); // find duplicates ... boolean hasDeletions = reader.hasDeletions(); int docs = reader.numDocs(); int numDuplicates = 0; for (int i = 0; i < docs; i++) { if (hasDeletions && reader.isDeleted(i)) { continue; } Document d = reader.document(i); float distance = getDistance(d, lireFeature); if (!duplicates.containsKey(distance)) { duplicates.put(distance, new LinkedList<String>()); } else { numDuplicates++; } duplicates.get(distance).add(d.getFieldable(DocumentBuilder.FIELD_NAME_IDENTIFIER).stringValue()); } if (numDuplicates == 0) return null; LinkedList<List<String>> results = new LinkedList<List<String>>(); for (float f : duplicates.keySet()) { if (duplicates.get(f).size() > 1) { results.add(duplicates.get(f)); } } simpleImageDuplicates = new SimpleImageDuplicates(results); } catch (InstantiationException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } catch (IllegalAccessException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } return simpleImageDuplicates; } }
源代码里面重要的函数有3个:
float getDistance(Document d, LireFeature lireFeature):
ImageSearchHits search(Document doc, IndexReader reader):检索。最核心函数。
ImageDuplicates findDuplicates(IndexReader reader):目前还没研究。
在这里忽然发现了一个问题:这里竟然只有一个Search()?!应该是有参数不同的3个Search()才对啊......
经过研究后发现,ColorLayoutImageSearcher继承了一个类——GenericImageSearcher,而不是继承 AbstractImageSearcher。Search()方法的实现是在GenericImageSearcher中实现的。看来这个 ColorLayoutImageSearcher还挺特殊的啊......
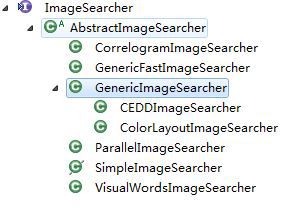
看一下GenericImageSearcher的源代码:
package net.semanticmetadata.lire.impl; import net.semanticmetadata.lire.AbstractImageSearcher; import net.semanticmetadata.lire.DocumentBuilder; import net.semanticmetadata.lire.ImageDuplicates; import net.semanticmetadata.lire.ImageSearchHits; import net.semanticmetadata.lire.imageanalysis.LireFeature; import net.semanticmetadata.lire.utils.ImageUtils; import org.apache.lucene.document.Document; import org.apache.lucene.index.IndexReader; import java.awt.image.BufferedImage; import java.io.FileNotFoundException; import java.io.IOException; import java.util.HashMap; import java.util.LinkedList; import java.util.List; import java.util.TreeSet; import java.util.logging.Level; import java.util.logging.Logger; /** * This file is part of the Caliph and Emir project: http://www.SemanticMetadata.net * <br>Date: 01.02.2006 * <br>Time: 00:17:02 * * @author Mathias Lux, [email protected] */ public class GenericImageSearcher extends AbstractImageSearcher { protected Logger logger = Logger.getLogger(getClass().getName()); Class<?> descriptorClass; String fieldName; private int maxHits = 10; protected TreeSet<SimpleResult> docs; public GenericImageSearcher(int maxHits, Class<?> descriptorClass, String fieldName) { this.maxHits = maxHits; docs = new TreeSet<SimpleResult>(); this.descriptorClass = descriptorClass; this.fieldName = fieldName; } public ImageSearchHits search(BufferedImage image, IndexReader reader) throws IOException { logger.finer("Starting extraction."); LireFeature lireFeature = null; SimpleImageSearchHits searchHits = null; try { lireFeature = (LireFeature) descriptorClass.newInstance(); // Scaling image is especially with the correlogram features very important! BufferedImage bimg = image; if (Math.max(image.getHeight(), image.getWidth()) > GenericDocumentBuilder.MAX_IMAGE_DIMENSION) { bimg = ImageUtils.scaleImage(image, GenericDocumentBuilder.MAX_IMAGE_DIMENSION); } lireFeature.extract(bimg); logger.fine("Extraction from image finished"); float maxDistance = findSimilar(reader, lireFeature); searchHits = new SimpleImageSearchHits(this.docs, maxDistance); } catch (InstantiationException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } catch (IllegalAccessException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } return searchHits; } /** * @param reader * @param lireFeature * @return the maximum distance found for normalizing. * @throws java.io.IOException */ protected float findSimilar(IndexReader reader, LireFeature lireFeature) throws IOException { float maxDistance = -1f, overallMaxDistance = -1f; boolean hasDeletions = reader.hasDeletions(); // clear result set ... docs.clear(); int docs = reader.numDocs(); for (int i = 0; i < docs; i++) { // bugfix by Roman Kern if (hasDeletions && reader.isDeleted(i)) { continue; } Document d = reader.document(i); float distance = getDistance(d, lireFeature); assert (distance >= 0); // calculate the overall max distance to normalize score afterwards if (overallMaxDistance < distance) { overallMaxDistance = distance; } // if it is the first document: if (maxDistance < 0) { maxDistance = distance; } // if the array is not full yet: if (this.docs.size() < maxHits) { this.docs.add(new SimpleResult(distance, d)); if (distance > maxDistance) maxDistance = distance; } else if (distance < maxDistance) { // if it is nearer to the sample than at least on of the current set: // remove the last one ... this.docs.remove(this.docs.last()); // add the new one ... this.docs.add(new SimpleResult(distance, d)); // and set our new distance border ... maxDistance = this.docs.last().getDistance(); } } return maxDistance; } protected float getDistance(Document d, LireFeature lireFeature) { float distance = 0f; LireFeature lf; try { lf = (LireFeature) descriptorClass.newInstance(); String[] cls = d.getValues(fieldName); if (cls != null && cls.length > 0) { lf.setStringRepresentation(cls[0]); distance = lireFeature.getDistance(lf); } else { logger.warning("No feature stored in this document!"); } } catch (InstantiationException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } catch (IllegalAccessException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } return distance; } public ImageSearchHits search(Document doc, IndexReader reader) throws IOException { SimpleImageSearchHits searchHits = null; try { LireFeature lireFeature = (LireFeature) descriptorClass.newInstance(); String[] cls = doc.getValues(fieldName); if (cls != null && cls.length > 0) lireFeature.setStringRepresentation(cls[0]); float maxDistance = findSimilar(reader, lireFeature); searchHits = new SimpleImageSearchHits(this.docs, maxDistance); } catch (InstantiationException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } catch (IllegalAccessException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } return searchHits; } public ImageDuplicates findDuplicates(IndexReader reader) throws IOException { // get the first document: SimpleImageDuplicates simpleImageDuplicates = null; try { if (!IndexReader.indexExists(reader.directory())) throw new FileNotFoundException("No index found at this specific location."); Document doc = reader.document(0); LireFeature lireFeature = (LireFeature) descriptorClass.newInstance(); String[] cls = doc.getValues(fieldName); if (cls != null && cls.length > 0) lireFeature.setStringRepresentation(cls[0]); HashMap<Float, List<String>> duplicates = new HashMap<Float, List<String>>(); // find duplicates ... boolean hasDeletions = reader.hasDeletions(); int docs = reader.numDocs(); int numDuplicates = 0; for (int i = 0; i < docs; i++) { if (hasDeletions && reader.isDeleted(i)) { continue; } Document d = reader.document(i); float distance = getDistance(d, lireFeature); if (!duplicates.containsKey(distance)) { duplicates.put(distance, new LinkedList<String>()); } else { numDuplicates++; } duplicates.get(distance).add(d.getFieldable(DocumentBuilder.FIELD_NAME_IDENTIFIER).stringValue()); } if (numDuplicates == 0) return null; LinkedList<List<String>> results = new LinkedList<List<String>>(); for (float f : duplicates.keySet()) { if (duplicates.get(f).size() > 1) { results.add(duplicates.get(f)); } } simpleImageDuplicates = new SimpleImageDuplicates(results); } catch (InstantiationException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } catch (IllegalAccessException e) { logger.log(Level.SEVERE, "Error instantiating class for generic image searcher: " + e.getMessage()); } return simpleImageDuplicates; } public String toString() { return "GenericSearcher using " + descriptorClass.getName(); } }
下面来看看GenericImageSearcher中的search(BufferedImage image, IndexReader reader)函数的步骤(注:这个函数应该是用的最多的,输入一张图片,返回相似图片的结果集):
1.输入图片如果尺寸过大(大于1024),则调整尺寸。
2.使用extract()提取输入图片的特征值。
3.根据提取的特征值,使用findSimilar()查找相似的图片。
4.新建一个ImageSearchHits用于存储查找的结果。
5.返回ImageSearchHits
在这里要注意一点:
GenericImageSearcher中创建特定方法的类的时候,使用了如下形式:
LireFeature lireFeature = (LireFeature) descriptorClass.newInstance();
即接口的方式,而不是直接新建一个对象的方式,形如:
AutoColorCorrelogram acc = new AutoColorCorrelogram(CorrelogramDocumentBuilder.MAXIMUM_DISTANCE)
相比而言,更具有通用型。
在search()函数中,调用了一个函数findSimilar()。这个函数的作用是查找相似图片的,分析了一下它的步骤:
1.使用IndexReader获取所有的记录
2.遍历所有的记录,和当前输入的图片进行比较,使用getDistance()函数
3.获取maxDistance并返回
在findSimilar()中,又调用了一个getDistance(),该函数调用了具体检索方法的getDistance()函数。
下面我们来看一下ColorLayout类中的getDistance()函数:
public float getDistance(LireFeature descriptor) { if (!(descriptor instanceof ColorLayoutImpl)) return -1f; ColorLayoutImpl cl = (ColorLayoutImpl) descriptor; return (float) ColorLayoutImpl.getSimilarity(YCoeff, CbCoeff, CrCoeff, cl.YCoeff, cl.CbCoeff, cl.CrCoeff); }
发现其调用了ColorLayoutImpl类中的getSimilarity()函数:
public static double getSimilarity(int[] YCoeff1, int[] CbCoeff1, int[] CrCoeff1, int[] YCoeff2, int[] CbCoeff2, int[] CrCoeff2) { int numYCoeff1, numYCoeff2, CCoeff1, CCoeff2, YCoeff, CCoeff; //Numbers of the Coefficients of two descriptor values. numYCoeff1 = YCoeff1.length; numYCoeff2 = YCoeff2.length; CCoeff1 = CbCoeff1.length; CCoeff2 = CbCoeff2.length; //take the minimal Coeff-number YCoeff = Math.min(numYCoeff1, numYCoeff2); CCoeff = Math.min(CCoeff1, CCoeff2); setWeightingValues(); int j; int[] sum = new int[3]; int diff; sum[0] = 0; for (j = 0; j < YCoeff; j++) { diff = (YCoeff1[j] - YCoeff2[j]); sum[0] += (weightMatrix[0][j] * diff * diff); } sum[1] = 0; for (j = 0; j < CCoeff; j++) { diff = (CbCoeff1[j] - CbCoeff2[j]); sum[1] += (weightMatrix[1][j] * diff * diff); } sum[2] = 0; for (j = 0; j < CCoeff; j++) { diff = (CrCoeff1[j] - CrCoeff2[j]); sum[2] += (weightMatrix[2][j] * diff * diff); } //returns the distance between the two desciptor values return Math.sqrt(sum[0] * 1.0) + Math.sqrt(sum[1] * 1.0) + Math.sqrt(sum[2] * 1.0); }
由代码可见,getSimilarity()通过具体的算法,计算两张图片特征向量之间的相似度。
7:算法类[以颜色布局为例]
前面关于LIRe的文章,介绍的都是架构方面的东西,没有细研究具体算法。本文以颜色布局为例,介绍一下算法类的实现。
颜色布局描述符以一种非常紧密的形式有效地表示了图像的颜色空间分布信息。它以非常小的计算代价, 带来高的检索效率。因此, 颜色布局特征在视频镜头关键帧提取中有很重要的意义。颜色布局提取方法如下:
1 将图像从RGB 空间映射到YCbCr空间, 映射公式为
Y= 0.299* R + 0.587* G + 0.114* B
Cb= - 0.169* R – 0.331* G + 0.500* B
Cr = 0.500* R –0.419* G – 0.081* B
2 将整幅图像分成64块, 每块尺寸为(W /8) *(H/8), 其中W 为整幅图像的宽度, H 为整幅图像的高度, 计算每一块中所有像素的各个颜色分量( Y, Cb, Cr )的平均值, 并以此作为该块的代表颜色( Y, Cb, Cr );
3 对帧图像中各块的颜色分量平均值进行DCT 变换, 得到各分量的一系列DCT 系数;
4 对各分量的DCT 系数, 通过之字形扫描和量化, 取出各自DCT 变换的低频分量, 这三组低频分量共同构成该帧图像的颜色布局描述符。
颜色布局算法的实现位于ColorLayoutImpl类中,该类处于“net.semanticmetadata.lire.imageanalysis.mpeg7”包中,如图所示:
ColorLayoutImpl类的代码量很大,很多地方都还没有研究,在这里仅展示部分已经看过的代码:
/* 雷霄骅 * 中国传媒大学/数字电视技术 * [email protected] * */ /** * Class for extrcating & comparing MPEG-7 based CBIR descriptor ColorLayout * * @author Mathias Lux, [email protected] */ public class ColorLayoutImpl { // static final boolean debug = true; protected int[][] shape; protected int imgYSize, imgXSize; protected BufferedImage img; protected static int[] availableCoeffNumbers = {1, 3, 6, 10, 15, 21, 28, 64}; //特征向量(Y,Cb,Cr) public int[] YCoeff; public int[] CbCoeff; public int[] CrCoeff; //特征向量的大小 protected int numCCoeff = 28, numYCoeff = 64; protected static int[] arrayZigZag = { 0, 1, 8, 16, 9, 2, 3, 10, 17, 24, 32, 25, 18, 11, 4, 5, 12, 19, 26, 33, 40, 48, 41, 34, 27, 20, 13, 6, 7, 14, 21, 28, 35, 42, 49, 56, 57, 50, 43, 36, 29, 22, 15, 23, 30, 37, 44, 51, 58, 59, 52, 45, 38, 31, 39, 46, 53, 60, 61, 54, 47, 55, 62, 63 }; protected static double[][] arrayCosin = { ... }; protected static int[][] weightMatrix = new int[3][64]; protected BufferedImage colorLayoutImage; /** * init used by all constructors */ private void init() { shape = new int[3][64]; YCoeff = new int[64]; CbCoeff = new int[64]; CrCoeff = new int[64]; colorLayoutImage = null; extract(); } public void extract(BufferedImage bimg) { this.img = bimg; imgYSize = img.getHeight(); imgXSize = img.getWidth(); init(); } private void createShape() { int y_axis, x_axis; int i, k, x, y, j; long[][] sum = new long[3][64]; int[] cnt = new int[64]; double yy = 0.0; int R, G, B; //init of the blocks for (i = 0; i < 64; i++) { cnt[i] = 0; sum[0][i] = 0; sum[1][i] = 0; sum[2][i] = 0; shape[0][i] = 0; shape[1][i] = 0; shape[2][i] = 0; } WritableRaster raster = img.getRaster(); int[] pixel = {0, 0, 0}; for (y = 0; y < imgYSize; y++) { for (x = 0; x < imgXSize; x++) { raster.getPixel(x, y, pixel); R = pixel[0]; G = pixel[1]; B = pixel[2]; y_axis = (int) (y / (imgYSize / 8.0)); x_axis = (int) (x / (imgXSize / 8.0)); k = (y_axis << 3) + x_axis; //RGB to YCbCr, partition and average-calculation yy = (0.299 * R + 0.587 * G + 0.114 * B) / 256.0; sum[0][k] += (int) (219.0 * yy + 16.5); // Y sum[1][k] += (int) (224.0 * 0.564 * (B / 256.0 * 1.0 - yy) + 128.5); // Cb sum[2][k] += (int) (224.0 * 0.713 * (R / 256.0 * 1.0 - yy) + 128.5); // Cr cnt[k]++; } } for (i = 0; i < 8; i++) { for (j = 0; j < 8; j++) { for (k = 0; k < 3; k++) { if (cnt[(i << 3) + j] != 0) shape[k][(i << 3) + j] = (int) (sum[k][(i << 3) + j] / cnt[(i << 3) + j]); else shape[k][(i << 3) + j] = 0; } } } } ......(其他代码都已经省略) private int extract() { createShape(); Fdct(shape[0]); Fdct(shape[1]); Fdct(shape[2]); YCoeff[0] = quant_ydc(shape[0][0] >> 3) >> 1; CbCoeff[0] = quant_cdc(shape[1][0] >> 3); CrCoeff[0] = quant_cdc(shape[2][0] >> 3); //quantization and zig-zagging for (int i = 1; i < 64; i++) { YCoeff[i] = quant_ac((shape[0][(arrayZigZag[i])]) >> 1) >> 3; CbCoeff[i] = quant_ac(shape[1][(arrayZigZag[i])]) >> 3; CrCoeff[i] = quant_ac(shape[2][(arrayZigZag[i])]) >> 3; } setYCoeff(YCoeff); setCbCoeff(CbCoeff); setCrCoeff(CrCoeff); return 0; } /** * Takes two ColorLayout Coeff sets and calculates similarity. * * @return -1.0 if data is not valid. */ public static double getSimilarity(int[] YCoeff1, int[] CbCoeff1, int[] CrCoeff1, int[] YCoeff2, int[] CbCoeff2, int[] CrCoeff2) { int numYCoeff1, numYCoeff2, CCoeff1, CCoeff2, YCoeff, CCoeff; //Numbers of the Coefficients of two descriptor values. numYCoeff1 = YCoeff1.length; numYCoeff2 = YCoeff2.length; CCoeff1 = CbCoeff1.length; CCoeff2 = CbCoeff2.length; //take the minimal Coeff-number YCoeff = Math.min(numYCoeff1, numYCoeff2); CCoeff = Math.min(CCoeff1, CCoeff2); setWeightingValues(); int j; int[] sum = new int[3]; int diff; sum[0] = 0; for (j = 0; j < YCoeff; j++) { diff = (YCoeff1[j] - YCoeff2[j]); sum[0] += (weightMatrix[0][j] * diff * diff); } sum[1] = 0; for (j = 0; j < CCoeff; j++) { diff = (CbCoeff1[j] - CbCoeff2[j]); sum[1] += (weightMatrix[1][j] * diff * diff); } sum[2] = 0; for (j = 0; j < CCoeff; j++) { diff = (CrCoeff1[j] - CrCoeff2[j]); sum[2] += (weightMatrix[2][j] * diff * diff); } //returns the distance between the two desciptor values return Math.sqrt(sum[0] * 1.0) + Math.sqrt(sum[1] * 1.0) + Math.sqrt(sum[2] * 1.0); } public int getNumberOfCCoeff() { return numCCoeff; } public void setNumberOfCCoeff(int numberOfCCoeff) { this.numCCoeff = numberOfCCoeff; } public int getNumberOfYCoeff() { return numYCoeff; } public void setNumberOfYCoeff(int numberOfYCoeff) { this.numYCoeff = numberOfYCoeff; } public String getStringRepresentation() { StringBuilder sb = new StringBuilder(256); StringBuilder sbtmp = new StringBuilder(256); for (int i = 0; i < numYCoeff; i++) { sb.append(YCoeff[i]); if (i + 1 < numYCoeff) sb.append(' '); } sb.append("z"); for (int i = 0; i < numCCoeff; i++) { sb.append(CbCoeff[i]); if (i + 1 < numCCoeff) sb.append(' '); sbtmp.append(CrCoeff[i]); if (i + 1 < numCCoeff) sbtmp.append(' '); } sb.append("z"); sb.append(sbtmp); return sb.toString(); } public void setStringRepresentation(String descriptor) { String[] coeffs = descriptor.split("z"); String[] y = coeffs[0].split(" "); String[] cb = coeffs[1].split(" "); String[] cr = coeffs[2].split(" "); numYCoeff = y.length; numCCoeff = Math.min(cb.length, cr.length); YCoeff = new int[numYCoeff]; CbCoeff = new int[numCCoeff]; CrCoeff = new int[numCCoeff]; for (int i = 0; i < numYCoeff; i++) { YCoeff[i] = Integer.parseInt(y[i]); } for (int i = 0; i < numCCoeff; i++) { CbCoeff[i] = Integer.parseInt(cb[i]); CrCoeff[i] = Integer.parseInt(cr[i]); } } public int[] getYCoeff() { return YCoeff; } public int[] getCbCoeff() { return CbCoeff; } public int[] getCrCoeff() { return CrCoeff; } }
下面介绍几个主要的函数:
提取:
1.extract(BufferedImage bimg):提取特征向量的函数,里面调用了init()。
2.init():初始化了 YCoeff,CbCoeff, CrCoeff。调用extract()(注意这个extract()是没有参数的)
3.extract():完成了提取特征向量的过程,其中调用了createShape()。
4.createShape():未研究。
获取/设置特征向量(注意:有参数为String和byte[]两种类型的特征向量,按照原代码里的说法,byte[]的效率要高一些):
1.getStringRepresentation():获取特征向量
2.setStringRepresentation():设置特征向量
计算相似度:
getSimilarity(int[] YCoeff1, int[] CbCoeff1, int[] CrCoeff1, int[] YCoeff2, int[] CbCoeff2, int[] CrCoeff2)
主要的变量:
3个存储特征向量(Y,Cb,Cr)的数组:
public int[] YCoeff; public int[] CbCoeff; public int[] CrCoeff;
特征向量的大小:
protected int numCCoeff = 28, numYCoeff = 64;