MDX Cookbook 05 - 条件过滤 FILTER-COUNT 与 SUM-IIF 实现
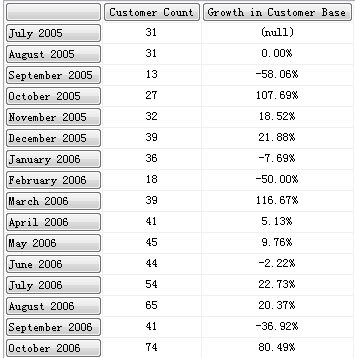
下面的这个查询返回每个财月的 Customer Count 和 基于上个月比较的 Growth in Customer Base 的记录,Slicer 是 Mountain bikes。
SELECT {
[Measures].[Customer Count],
[Measures].[Growth in Customer Base]
} ON 0,
NON EMPTY {[Date].[Fiscal].[Month].MEMBERS} ON 1
FROM [Adventure Works]
WHERE
( [Product].[Product Categories].[Subcategory].&[1] )
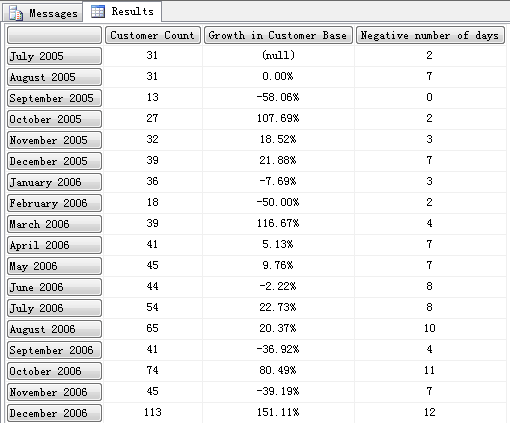
现在来看看如何统计在每个财月中正增长的天数,这是我自己的写法。
WITH
MEMBER [Measures].[Positive number of days]
AS
COUNT(
FILTER(
DESCENDANTS([Date].[Fiscal].CURRENTMEMBER,[Date].[Fiscal].[Date]),
[Measures].[Growth in Customer Base] > 0
)
)
SELECT {
[Measures].[Customer Count],
[Measures].[Growth in Customer Base],
[Measures].[Positive number of days]
} ON 0,
NON EMPTY {[Date].[Fiscal].[Month].MEMBERS} ON 1
FROM [Adventure Works]
WHERE
( [Product].[Product Categories].[Subcategory].&[1] )
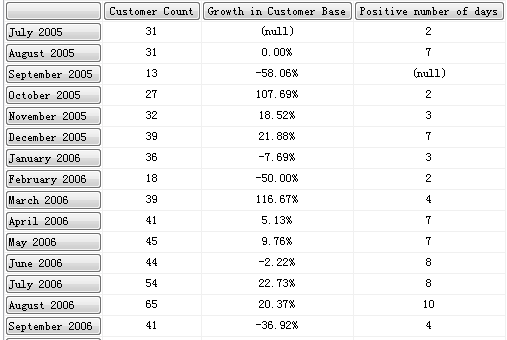
当然书上的写法更加简洁一些直接在 Filter 的基础之上取得了 COUNT,并且由于天位于叶节点,所以使用 DESCENDANTS 的 Leaves 关键字直接取到叶级别上的月中的每一天,使用的非常灵活。
WITH
MEMBER [Measures].[Positive number of days]
AS
FILTER(
DESCENDANTS([Date].[Fiscal].CurrentMember, , leaves),
[Measures].[Growth in Customer Base] > 0
).COUNT
SELECT {
[Measures].[Customer Count],
[Measures].[Growth in Customer Base],
[Measures].[Positive number of days]
} ON 0,
NON EMPTY {[Date].[Fiscal].[Month].MEMBERS} ON 1
FROM [Adventure Works]
WHERE
( [Product].[Product Categories].[Subcategory].&[1] )
Filter 函数实际上是一个迭代函数并且并不是以一个块结构去运行的,因此会降低查询的效率。实际上这个查询可以使用 SUM IF 结构来完成,因此度量值 [Measures].[Growth in Customer Base] 指的就是增长的比率,我们只需要统计增长的天数就可以了。
WITH
MEMBER [Measures].[Positive number of days]
AS
SUM(
Descendants([Date].[Fiscal].CurrentMember, , leaves),
IIF( [Measures].[Growth in Customer Base] > 0, 1, NULL)
)
SELECT {
[Measures].[Customer Count],
[Measures].[Growth in Customer Base],
[Measures].[Positive number of days]
} ON 0,
NON EMPTY {[Date].[Fiscal].[Month].MEMBERS} ON 1
FROM [Adventure Works]
WHERE
( [Product].[Product Categories].[Subcategory].&[1] )
那么这种写法好在什么地方呢? 是因为 SUM 和 IIF 函数都是经过调优的可以在所谓的块模式下运行的,特别是当在 IIF() 函数中有一个分支的值是 NULL 的情况下是非常快的。 在现在我们的例子中可能看不出来这个效果,但是如果当数据量特别大的时候,就会发现 SUM-IIF 这种写法比起 FILTER-COUNT 这种写法在性能上有很大的提升。
其它 BI 博客系列看参看 - BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server)