大数据迁移实践之路
随着业务的迅速发展,农业银行某系统承担的运行压力越来越大。现阶段, 该系统每天的交易量在2300 万笔以上,峰值达2950 万笔。交易量的攀升导致了后台数据库数据量的激增,从而影响了联机程序响应时间,也增加了系统各类资源开销和后续数据分析的处理时间。为保障系统稳定运行,项目组从增加系统资源、优化资源配置、优化重点程序和升级系统数据库等多个维度对系统进行了综合优化。下面笔者从大表、热表的数据分析和优化角度,阐述对大数据量表进行的存储优化。
一、大表数据分析
目前农业银行某系统工作流数据量最大且访问最频繁的两张核心表:
(1)流程实例表,用于存储系统发起的所有流程实例,包括基本流程、会签流程、补充资料流程和抄送流程;
(2)任务实例表,用于存储每个流程实例的流转记录。
截至2013 年4 月1 日, 工作流两张大表的数据量如表1 所示。其中任务实例表为系统中数据量最大的一张表,达到了1.2 亿。根据ProDBA 抓取的执行次数最多且执行时间最长的前30 条SQL 信息中,显示流程实例表和任务实例表压力比较大。大表中的数据按照结束时间和状态两个维度可以区分为三类:
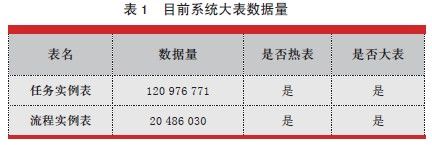
(1)正在运行的流程数据,即业务正在办理过程中,尚未结束;
(2)已结束流程一年内的数据,即业务总体流程已经结束,期限在一年内(包含一年);
(3)已经结束流程一年以上的数据,即业务总体流程已经结束,期限在一年以上(如表2 所示)。事实上,由于存在业务制度等方面的规定,已经结束一年以上的数据基本处于静态无变化的情况,不会发生修改、删除等数据操作,但是占据了一定的表空间,同时也影响了对其他运行中数据的访问效率。为降低大数据量对系统访问的影响,需制定迁移规则,进行数据拆分。
二、拆分规则
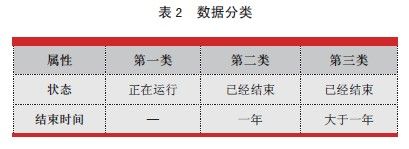
根据上述大数据表的数据分布特点,建立三套表结构:运行表、历史表和备份表。运行表仅存储正在运行的流程数据,流程结束后(正常完成或者终止)将基本流程以及其所属子流程相关的所有数据(流程实例、任务实例、流程变量、异常、分支等)实时迁移至历史表。如业务需要将已结束的流程恢复,系统支持流程从历史表实时迁回到运行表继续流转,整个过程对用户是完全透明的。
由于已完成和终止一年以上的流程,需恢复的业务需求很少(系统上线以来未发生过类似业务),因此由备份表存放第三类数据,形成三级存储模式如图1 所示。历史表中的数据,每年执行一次批量拆分操作,拆分至备份表。
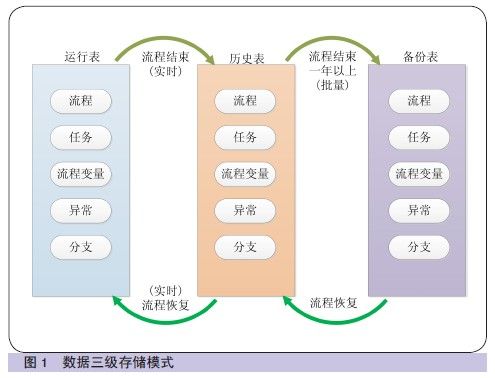
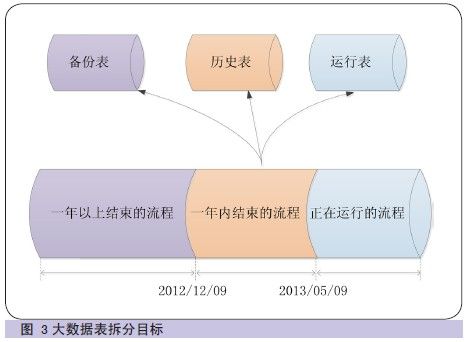
为保障数据平稳的迁移,应采取分布实施的策略。2012 年12 月8日,流程结束数据实时迁移到历史表功能先期投产,因此目前工作流运行表中存放的数据包含三种情况:正在运行的数据;2012 年5 月至2012 年12 月结束的流程;2012 年5 月前结束一年以上的流程(如图2所示)。
按照数据三级存储规则,需要对大数据表进行拆分、剥离及整合,最终实现运行表只存储运行的数据,降低系统压力(如图3 所示)。
三、问题分析及拆分策略
1. 数据表重命名
数据迁移前需要对流程实例表和任务表进行BCP 数据备份,以确保出现异常情况时,可及时恢复数据。任务实例表(1.2 亿)和流程实例表(2 千万),备份估计需要2~3个小时。数据迁移最终要达到运行表中仅存放流程正在运行中的数据,因此采取如下策略,节省BCP 备份时间。
首先,创建任务实例和流程实例中间表,表结构和运行表保持完全一致;其次,将运行表中正在运行的数据迁移至中间表;再次,对流程运行表和中间表重命名,实现中间表转换为运行表,运行表转换为备份表。如出现数据迁移异常和验证不通过等情况,由于备份表保存了迁移当日的全量数据,因此,再次执行数据表重命名即可解决问题,无需再对两张大表进行BCP 备份。数据表重命名脚本执行时间,经测试在1 分钟内即可完成,大大减少迁移时间。
2. 数据完整性
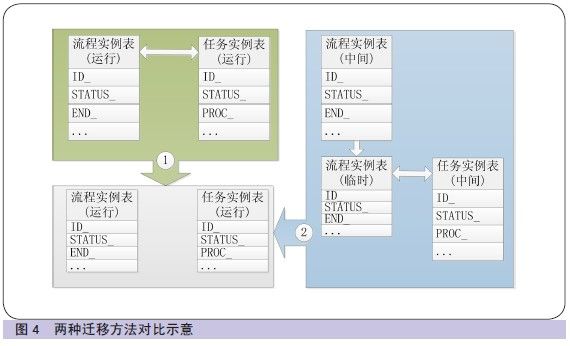
一笔完整的流程,包含一条流程实例和多条任务实例,任务实例根据流程实例编号和状态等属性,确定所属流程。迁移方法一:为保障迁移数据完整,需要根据流程的状态,查询流程和关联任务的记录,一次性迁移两张表的记录,如迁移失败同时回滚,因此,需要进行任务实例表和流程实例表关联。考虑到两张表的数据量,此方案将会导致迁移效率很低。经测试,迁移5万笔流程(5 万条流程和36 万条任务记录) 数据约7分钟,循环执行迁移,迁移完全部流程数据需要约42 个小时。
为提高拆分效率,减少对投产时间窗口的占用,对拆分方法进行了优化。迁移方法二:首先,流程实例表按照I D 号升序排列,取前50 万条记录存放至临时表;其次,将临时表(50 万)和任务表(1.2 亿)进行关联,迁移流程所属的所有任务;再次,再迁移50 万条流程记录;最后,删除临时表。循环执行操作,每次迁移,以前一次迁移的最大I D 号为条件, 再取50 万条记录。此方法同样可以保障事务一致性,每次迁移两张表的数据,但是少了表关联的数据量。经测试,迁移50 万笔流程(包括流程和任务记录)数据约8 分钟,迁移正在运行的数据预计可在1 个小时内完成。两种迁移方法对比示意如图4所示。
3. 自增字段
任务实例表和流程实例表的主键ID,同为Identity 型字段。数据迁移过程中,要保持ID 号一致。首先,建表DBO 用户和数据迁移操作用户需保持一致;其次,数据迁移脚本中,使用SET IDENTITY_INSERT 表名 ON 命令强制关闭对表的自增字段设置;再次, 迁移完成后,再使用SET IDENTITY_INSERT 表名 OFF 命令再打开自增字段设置。
4. 划分数据拆分批次
对拆分策略和脚本进行测试和优化后,完成全部迁移仍然需5 个小时左右,因此考虑分批次执行。在数据拆分规则中,数据被区分为三类,根据此规则迁移分为两个批次:一是执行迁移正在运行的数据;二是执行迁移已经完成流程一年内的数据。尽可能减小两批次执行的时间间隔。第一批次执行完成后,流程运行中的数据不受影响,一年内已结束的流程如需恢复,将受到影响。考虑到业务的实际办理情况,流程结束后再次被恢复的情况很少,因此分两个批次执行的影响面积较小。
四、数据迁移方案实践
以迁移正在运行的数据为例,阐述数据迁移过程。迁移流程结束一年内的数据到历史表的操作过程同此,不再赘述。
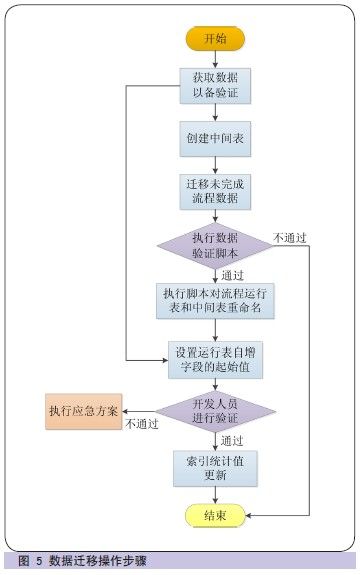
1. 操作步骤
第一,执行脚本查询流程实例表和任务实例表,获取数据以备验证。同时查询最大流程和任务I D号, 以备在步骤六中设置自增起始值。
第二,创建中间表,表结构和运行表保持一致。
第三, 迁移未完成流程数据,每次迁移50 万个流程,检查日志内容,直到执行影响结果不足50 万个,证明数据迁移完成。
第四,执行数据验证脚本,比较此脚本的执行结果和步骤1 中的执行结果是否一致。如不一致,后续步骤不再执行。
第五,执行脚本对流程运行表和中间表重命名,执行完成后验证表结构是否一致。
第六,根据步骤一的查询结果,设置运行表自增字段的起始值。
第七,开启工作流WAS,由开发人员进行验证。如验证通过,关闭工作流WAS ;如验证不通过,执行应急方案。执行完成后再次进行验证。
第八,进行运行表的索引统计值更新(如图5 所示)。
2. 应急方案
(1)异常情况一:执行迁移脚本出现时间超长等异常情况,在计划时间窗口内不能正常执行完成。应急方案:迁移脚本未对运行表进行更新和删除等操作,数据未受影响,因此后续操作步骤不再执行,删除中间表即可。
(2)异常情况二:数据拆分完成,开启工作流WAS 验证,开发人员验证不通过。应急方案:执行脚本将运行表更名为中间表,备份表更名为运行表,执行完成后,再次由开发人员进行验证,验证通过删除中间表。
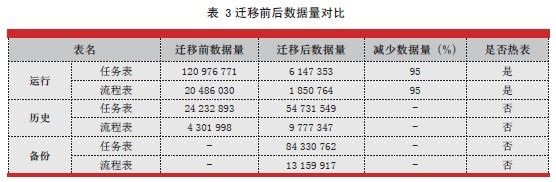
3. 数据量比较
经过两轮迁移,数据量对比如表3 所示,从中可以看出访问最频繁的运行表数据量减少95%。
4. 结论
数据经过拆分、剥离及整合后形成了三级存储模式。流程结束后数据实时转移到历史表,而运行表数据增量变化不大,因此有效解决了由于数据量巨大带来的数据访问响应时间长等问题,提升了系统性能。
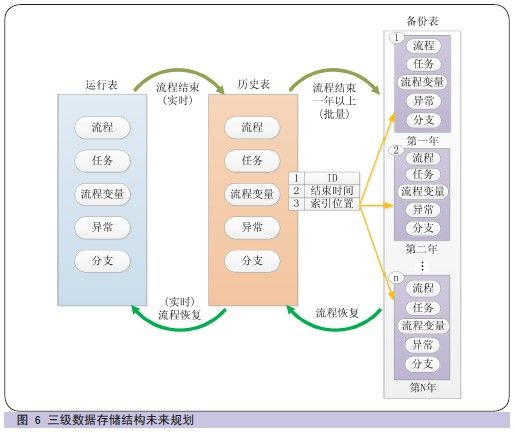
五、未来规划
数据迁移完成后,根据数据增长特点,每年对历史表数据进行一次批量迁移,迁移至备份表存储,而运行表数据不受影响, 即消除表 3 迁移前后数据量对比了对运行中流程的影响。由此带来备份表数据也将不断增大。备份表的存储采用索引存储方式,增加备份数据索引表( 如图6 所示)。为做到对业务操作的完全透明, 如需对备份表的数据恢复,则根据索引定位流程数据, 缩小数据查询范围, 最终降低系统响应时间。备份表中数据也可转移至其他存储设备进行保存。对备份表中数据查询需求, 提供单独的查询、统计及分析服务。