SQL Server Window Function 窗体函数读书笔记二 - A Detailed Look at Window Functions
这一章主要是介绍 窗体中的 Aggregate 函数, Rank 函数, Distribution 函数以及 Offset 函数.
Window Aggregate 函数
Window Aggregate 函数和在Group分组中使用的聚合函数是一样的, 只是不再定义Group并且是通过 OVER子句来定义和使用的. 在标准的SQL中, 窗体聚合函数是支持这三种元素的 - Partitioning, Ordering 和 Framing
function_name(<arguments>) OVER( [ <window partition clause> ] [ <window order clause> [ <window frame clause> ] ] )
这三种元素的作用可以限制窗体集中的行, 如果没有指定任何元素, 那么窗体中包含的就是查询结果集中所有的行.
Partitioning 分区
通过PARTITION BY 得到的窗体集是基于当前查询结果的当前行的一个集, 比如说 PARTITION BY CustomerID, 当前行的 CustomerID = 1, 那么对于当前行的这个 Window 集就是在当前查询结果之上再加上 CustomerID = 1 的一个查询结果. 如果当前行的 CustomerID = 2, 那么它的窗体就是在查询结果上所有 CustomerID = 2 的集.
与GROUP不同, PARTITION 可以在一个 SELECT 中对应不同的分区列, 并且每一行对应的窗体集也可能而不相同.
与子查询也不同,子查询可以任意查询不同的对象集,而 PARTITION 分区对应的窗口集首先它是基于当前 SELECT 的结果集.
回顾上一篇文章中提到的这个例子 -
USE TSQL2012; GO SELECT orderid, custid, val, SUM(val) OVER() AS sumall, SUM(val) OVER(PARTITION BY custid) AS sumcust FROM Sales.OrderValues AS O1;
-- 查询结果
10643 1 814.50 1265793.22 4273.00
10692 1 878.00 1265793.22 4273.00
10702 1 330.00 1265793.22 4273.00
10835 1 845.80 1265793.22 4273.00
10952 1 471.20 1265793.22 4273.00
11011 1 933.50 1265793.22 4273.00
10926 2 514.40 1265793.22 1402.95
10759 2 320.00 1265793.22 1402.95
10625 2 479.75 1265793.22 1402.95
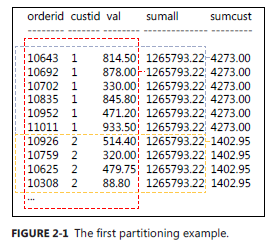
第一个窗体函数每一行对应的都是相同的,它们的窗体都一样,计算的都是Val的总和.
第二个窗体函数每一行对应的可能是不同的,因为它基于 custid 进行了分区, 即在所有的窗体集基础上加入了 custid = 当前行的 custid 这个过滤限制.
SELECT orderid, custid, val, CAST(100. * val / SUM(val) OVER() AS NUMERIC(5, 2)) AS pctall, CAST(100. * val / SUM(val) OVER(PARTITION BY custid) AS NUMERIC(5, 2)) AS pctcust FROM Sales.OrderValues AS O1;
-- 查询结果
10643 1 814.50 0.06 19.06
10692 1 878.00 0.07 20.55
10702 1 330.00 0.03 7.72
10835 1 845.80 0.07 19.79
10952 1 471.20 0.04 11.03
11011 1 933.50 0.07 21.85
10926 2 514.40 0.04 36.67
10759 2 320.00 0.03 22.81
10625 2 479.75 0.04 34.20
这几个窗体同时并存
Ordering and Framing
Framing 框架也是用来过滤和限制窗体集中的行,但同时一般会首先排好序, 然后再通过 Framing 来定位窗体集中的起始行和结束行来获取特定的行集.
function_name(<arguments>) OVER( [ <window partition clause> ] [ <window order clause> [ <window frame clause> ] ] )
在 <window frame clause> 中, 有这三个部分 - <window frame units> <window frame extent> [ <window frame exclusion> ].
在 <window frame units> 应该指定 ROWS 或者 RANGE
ROWS 的使用
ROWS BETWEEN UNBOUNDED PRECEDING | <n> PRECEDING | <n> FOLLOWING | CURRENT ROW AND UNBOUNDED FOLLOWING | <n> PRECEDING | <n> FOLLOWING | CURRENT ROW
UNBOUNDED PRECEDING 指的是相对于当前行来说之前的所有的行
UNBOUNDED FOLLOWING 指的是相对于当前行来说之后的所有的行
CURRENT ROW 就是当前行
SELECT empid, ordermonth, qty, SUM(qty) OVER( PARTITION BY empid ORDER BY ordermonth ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS runqty FROM Sales.EmpOrders;
-- 查询结果
1 2006-07-01 00:00:00.000 121 121
1 2006-08-01 00:00:00.000 247 368
1 2006-09-01 00:00:00.000 255 623
1 2006-10-01 00:00:00.000 143 766
1 2006-11-01 00:00:00.000 318 1084
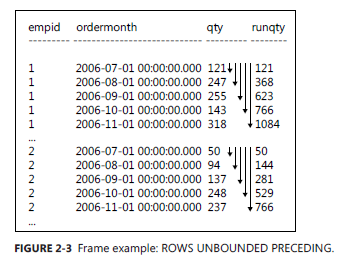
可以写的更简洁一些
SELECT empid, ordermonth, qty, SUM(qty) OVER( PARTITION BY empid ORDER BY ordermonth ROWS UNBOUNDED PRECEDING ) AS runqty FROM Sales.EmpOrders;
下面的这个例子定义了3个窗体
第一个窗体中 ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING 所表明的行的范围就是当前行的上一行
第二个窗体中 ROWS BETWEEN 1 FOLLOWING AND 1 FOLLOWING 所表明的行的范围是当前行的下一行
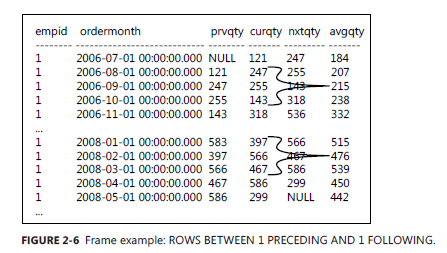
第三个窗体中 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING 所表明的行的范围是上一行到一下行
SELECT empid, ordermonth, MAX(qty) OVER( PARTITION BY empid ORDER BY ordermonth ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING ) AS prvqty, qty AS curqty, MAX(qty) OVER( PARTITION BY empid ORDER BY ordermonth ROWS BETWEEN 1 FOLLOWING AND 1 FOLLOWING ) AS nxtqty, AVG(qty) OVER( PARTITION BY empid ORDER BY ordermonth ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING ) AS avgqty FROM Sales.EmpOrders;
-- 查询结果
1 2006-07-01 00:00:00.000 NULL 121 247 184
1 2006-08-01 00:00:00.000 121 247 255 207
1 2006-09-01 00:00:00.000 247 255 143 215
1 2006-10-01 00:00:00.000 255 143 318 238
1 2006-11-01 00:00:00.000 143 318 536 332
1 2006-12-01 00:00:00.000 318 536 304 386
1 2007-01-01 00:00:00.000 536 304 168 336
1 2007-02-01 00:00:00.000 304 168 275 249
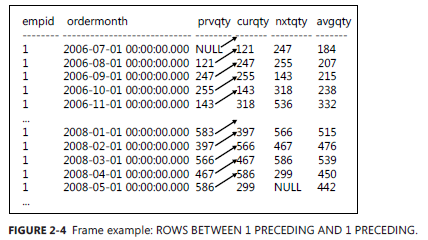
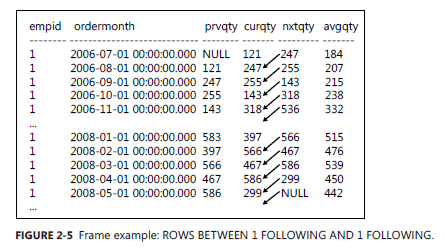
需要值得注意的是, 第三个窗体中求平均值的时候,第一行没有上一行元素的引用,最后一行也不会存在对下一行的引用,所以对于第一行和最后一行的窗体行数可能比其它的窗体行数相对要少,但是最多不会超过3行,AVG 函数在这里会自动判断行数来求平均值。
在这个例子中,PARTITION的列和 ORDER 列它们组合在一起唯一标识了一行记录,因此它们在窗体集里不会重复,所以它们查询出来
的结果是唯一的。
当使用在 PARTITION 和 ORDER 上的列组合起来不能唯一确定一行记录的话,查询的结果有可能不是唯一的,下面的例子就能说明这个问题。
SET NOCOUNT ON;
USE TSQL2012;
IF OBJECT_ID('dbo.T1', 'U') IS NOT NULL DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
keycol INT NOT NULL CONSTRAINT PK_T1 PRIMARY KEY,
col1 VARCHAR(10) NOT NULL
);
INSERT INTO dbo.T1 VALUES
(2, 'A'),(3, 'A'),
(5, 'B'),(7, 'B'),(11, 'B'),
(13, 'C'),(17, 'C'),(19, 'C'),(23, 'C');
SELECT * FROM dbo.T1
查询结果
2 A
3 A
5 B
7 B
11 B
13 C
17 C
19 C
23 C
SELECT keycol,
col1,
COUNT(*) OVER(ORDER BY col1
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt
FROM dbo.T1
查询结果
2 A 1
3 A 2
5 B 3
7 B 4
11 B 5
13 C 6
17 C 7
19 C 8
23 C 9
由于没有使用 PARTITION,因此默认的情况就是每一行都使用的相同的 PARTITION 即 SELECT 查询结果集。但是在这里由于ORDER BY 的列 col1 并不是唯一的,因此相同的 col1 的行共享同一个窗体,那么这时它们计算 COUNT 的方式可能就无法确定。
比如这个例子中的 A, B, C, A 对应的窗体里有2条A 的记录,B 有3条,C 有4条,无法判断它们如何定位计算。这时 SQL Server就强制性的给相同的元素定了位以便计算各个元素之前的条数。
给它们设置一个唯一索引,这样SQL Server就知道如何在内部对它们进行排序。
CREATE UNIQUE INDEX idx_col1D_keycol ON dbo.T1(col1 DESC, keycol);
SELECT keycol,
col1,
COUNT(*) OVER(ORDER BY col1
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt
FROM dbo.T1
查询结果
3 A 1
2 A 2
11 B 3
7 B 4
5 B 5
23 C 6
19 C 7
17 C 8
13 C 9
理解了这个原因之后,可以这样写来确保在窗体集里的排序的元素是唯一的,这样查询的结果也一定是唯一的。
SELECT keycol,
col1,
COUNT(*) OVER(ORDER BY keycol,col1
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cnt
FROM dbo.T1
2 A 1
3 A 2
5 B 3
7 B 4
11 B 5
13 C 6
17 C 7
19 C 8
23 C 9
RANGE 框架的扩展选项和使用
定义
RANGE BETWEEN UNBOUNDED PRECEDING |
<val> PRECEDING |
<val> FOLLOWING |
CURRENT ROW
AND
UNBOUNDED FOLLOWING |
<val> PRECEDING |
<val> FOLLOWING |
CURRENT ROW
要事先说的是 RANGE 框架在 SQL Server 2012 中并没有实现的很完善, 目前只支持 UNBOUNDED 和 CURRENT ROW 这两个选项。
比如说,这样的代码
SELECT empid,
ordermonth,
qty,
SUM(qty) OVER(PARTITION BY empid
ORDER BY ordermonth
RANGE BETWEEN 2 PRECEDING AND CURRENT ROW)
FROM Sales.EmpOrders AS O1
ORDER BY empid,
ordermonth
会出现错误
Msg 4194, Level 16, State 1, Line 1
RANGE is only supported with UNBOUNDED and CURRENT ROW window frame delimiters.
如果假设有这样的一个代码结构能在 2012 中实现的话,那么就真正可以做到一个动态的范围控制。比如,查询当前月到它前两个月的订单总额。
SELECT empid, ordermonth, qty,
SUM(qty) OVER(PARTITION BY empid
ORDER BY ordermonth
RANGE BETWEEN INTERVAL '2' MONTH PRECEDING AND CURRENT ROW) AS sum3month
FROM Sales.EmpOrders;
假设,当前月是3月,那么它前两个月就应该包含2月和1月,那么总共的取值范围就是1,2,3 这三个月。假设2月份没有数据时,那么结果就应该是1月和3月,而不会因为2月不存在就往前走一个月包含12,1和3月来凑齐3个月,这就是 RANGE 和 ROWS 的不同 。只不过很遗憾,目前还没有支持到这个程度。
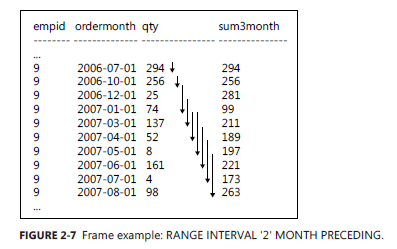
如何理解和 ROWS 不同,ROWS BETWEEN 2 PRECEDING AND CURRENT ROW 表示的是包含当前行以及前两行的数据。借用上面的一个例子,如果当前月是3月,同时2月份的数据不存在,那么它取值的范围是 12月,1月和3月。
现在如果想要实现类似于RANGE BETWEEN INTERVAL '2' MONTH PRECEDING 的效果在 Windows Function 中还是非常复杂, 还有一个选择就是使用下面提到的
这种替代方案。
查询员工在各个订单月的订单额以及从当前月到它前两个月共三个月的总订单额
SELECT empid,
ordermonth,
qty,
( SELECT SUM(qty)
FROM Sales.EmpOrders AS O2
WHERE O2.empid = O1.empid
AND O2.ordermonth BETWEEN DATEADD(MONTH, -2, O1.ordermonth)
AND O1.ordermonth
) AS sum3month
FROM Sales.EmpOrders AS O1
ORDER BY empid,
ordermonth
查询结果
1 2006-07-01 00:00:00.000 121 121
1 2006-08-01 00:00:00.000 247 368
1 2006-09-01 00:00:00.000 255 623
1 2006-10-01 00:00:00.000 143 645
1 2006-11-01 00:00:00.000 318 716
通过上面这种方式来查询就实现了 RANGE BETWEEN INTERVAL '2' MONTH PRECEDING 所描述的效果。
如果只是计算包含当前月以及之前所有月份的总和,在这里使用 RANGE 和 ROWS 效果一样。
SELECT empid,
ordermonth,
qty,
SUM(qty) OVER(PARTITION BY empid
ORDER BY ordermonth
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS runqty
FROM Sales.EmpOrders;
SELECT empid,
ordermonth,
qty,
SUM(qty) OVER(PARTITION BY empid
ORDER BY ordermonth
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS runqty
FROM Sales.EmpOrders;
可以省略掉 CURRENT ROW, 默认就是
SELECT empid,
ordermonth,
qty,
SUM(qty) OVER(PARTITION BY empid
ORDER BY ordermonth
RANGE UNBOUNDED PRECEDING ) AS runqty
FROM Sales.EmpOrders;
甚至在这里可以更加简化成
SELECT empid,
ordermonth,
qty,
SUM(qty) OVER(PARTITION BY empid
ORDER BY ordermonth) AS runqty
FROM Sales.EmpOrders;
因为这里使用了 PARTITION BY 和 ORDER BY 它们俩唯一定位了一条记录,虽然没有显示写出 RANGE UNBOUNDED PRECEDING 但是内部处理也是包含了从之前所有行当当前行的所有记录。
1 2006-07-01 00:00:00.000 121 121
1 2006-08-01 00:00:00.000 247 368
1 2006-09-01 00:00:00.000 255 623
1 2006-10-01 00:00:00.000 143 766
1 2006-11-01 00:00:00.000 318 1084
1 2006-12-01 00:00:00.000 536 1620
如果把 ORDER BY 去掉,那么就只剩下 empid, 可以简单理解为按 empid 分类计算各个 empid 下的总和。
SELECT empid, ordermonth, qty,
SUM(qty) OVER(PARTITION BY empid) AS runqty
FROM Sales.EmpOrders;
查询结果
1 2007-03-01 00:00:00.000 275 7812
1 2008-01-01 00:00:00.000 397 7812
1 2007-12-01 00:00:00.000 583 7812
1 2006-11-01 00:00:00.000 318 7812
1 2008-03-01 00:00:00.000 467 7812
那么再来看看 RANGE 和 ROWS 到底有什么区别?
在之前提到的例子中,我们是假设 RANGE 支持 RANGE BETWEEN INTERVAL '2' MONTH PRECEDING 这样的功能来和 ROWS 做比较的。
而事实上我们知道,这个功能并没有在 SQL Server 2012 中实现。
(未带完续)