MYSQL复制
今天我们聊聊复制,复制对于mysql的重要性不言而喻,mysql集群的负载均衡,读写分离和高可用都是基于复制实现。下文主要从4个方面展开,mysql的异步复制,半同步复制和并行复制,最后会简单聊下第三方复制工具。由于生产环境中,innodb存储引擎支持事务,并且行级复制使用广泛,所以下文的讨论都是基于这种假设。
异步复制
异步复制是mysql自带的最原始的复制方式,主库和备库成功建立起复制关系后,在备库上会有一个IO线程去主库拉取binlog,并将binlog写到本地,就是图1中的Relay log,然后备库会开启另外一个SQL线程去读取回放Relay log,通过这种方式达到Master-Slave数据同步的目的。通常情况下,Slave是只读的,可以承担一部分读流量,而且可以根据实际需要,添加一个或多个Slave,这样在一定程度上可以缓解主库的读压力;另一方面,若Master出现异常(crash,硬件故障等),无法对外提供服务,此时Slave可以承担起Master的重任,避免了单点的产生,所以复制就是为容灾和提高性能而生。
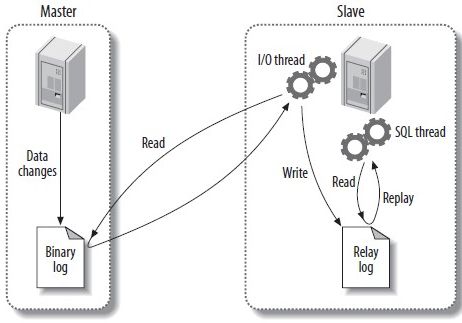
图1
半同步复制
一般情况下,异步复制就已经足够应付了,但由于是异步复制,备库极有可能是落后于主库,特别是极端情况下,我们无法保证主备数据是严格一致的(即使我们观察到Seconds Behind Master 这个值为0)。比如,当用户发起commit命令时,Master并不关心Slave的执行状态,执行成功后,立即返回给用户。试想下,若一个事务提交后,Master成功返回给用户后crash,这个事务的binlog还没来得及传递到Slave,那么Slave相对于Master而言就少了一个事务,此时主备就不一致了。对于要求强一致的业务是不可以接受的,半同步复制就是为了解决数据一致性而产生的。
为什么叫半同步复制?先说说同步复制,所谓同步复制就是一个事务在Master和Slave都执行后,才返回给用户执行成功。而半同步复制不要求Slave执行,而仅仅是接收到日志后,就通知Master可以返回了。这里关键点是Slave接受日志后是否执行,若执行后才通知Master则是同步复制,若仅仅是接受日志成功,则是半同步复制。对于Mysql而言,我们谈到的日志都是binlog,对于其他的关系型数据库可能是redo log或其他日志。
半同步复制如何实现?半同步复制实现的关键点是Master对于事务提交过程特殊处理。目前实现半同步复制主要有两种模式,AFTER_SYNC模式和AFTER_COMMIT模式。两种方式的主要区别在于是否在存储引擎提交后等待Slave的ACK。先来看看AFTER_COMMIT模式,如图2,Start和End分别表示用户发起Commit命令和Master返回给用户的时间点,中间部分就是整个Commit过程Master和Slave做的事情。
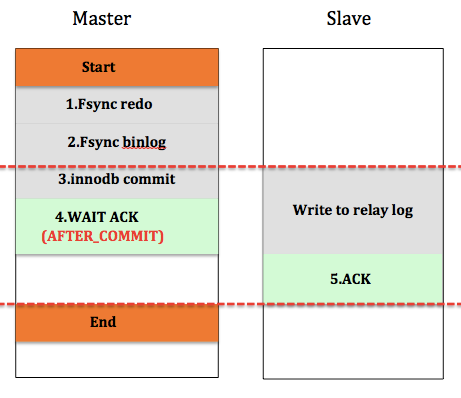
图2
Master提交时,会首先将该事务的redo log刷入磁盘,然后将事务的binlog刷入磁盘(这里其实还涉及到两阶段提交的问题,这里不展开讲),然后进入innodb commit流程,这个步骤主要是释放锁,标记事务为提交状态(其他用户可以看到该事务的更新),这个过程完成后,等待Slave发送的ACK消息,等到Slave的响应后,Master才成功返回给用户。看到图中红色虚线部分,这段是Master和Slave的同步逻辑,是Master-Slave一致性的保证。
半同步复制是否能保证不丢数据?我们通过几种场景来简单分析下。第一种情况:假设Master第1,2步执行成功后,binlog还没来得及传递给Slave,此时Master挂了,Slave作为新Master提供服务,那么备库比主库要少一个事务(因为主库的redo 和binlog已经落盘),但是不影响用户,对于用户而言,这个事务没有成功返回,那么提交与否,用户都可以接受,用户一定会进行异常捕获而重试。第二种情况,假设第3步innodb commit执行成功后,binlog还没来得及传递给Slave,此时Master挂了,此时与第一种情况一样,备库比主库少一个事务,但是其他用户在3执行完后,可以看到该事务的更新,而切换到备库后,却发现再次读这个更新又没了,这个就发生了“幻读”,如果其他事务依赖于这个更新,则会对业务逻辑产生影响。当然这仅仅是极端情况。
对于第二种情况产生的影响,AFTER_SYNC模式可以解决这一问题。与AFTER_COMMIT相比,master在AFTER_SYNC模式下,Fsync binlog后,就开始等待SLAVE同步。那么在进行第5步innodbcommit后,即其它事务能看到该事务的更新时,Slave已经成功接收到binlog,即使发生切换,Slave拥有与Master同样的数据,不会发生“幻读”现象。但是对于上面描述的第一种情况,结果是一样的。
所以,在极端情况下,半同步复制的Master-Slave会有一个事务不一致,但是对于用户而言,由于这个事务并没有成功返回给用户,所以无论事务提交与否都是可以接受的,用户有必要进行查询或重试,判读是否更新成功。或者我们想想,对于单机而言,若事务执行成功后,返回给用户时,网络断了,用户也是面临一样的问题,所以,这不是半同步复制的问题。对于提交返回成功的事务,版同步复制保证Master-Slave一定是一致的,从这个角度来看,半同步复制不会丢数据,可以保证Master-Slave的强一致性。图3是AFTER_SYNC模式,事务提交过程。
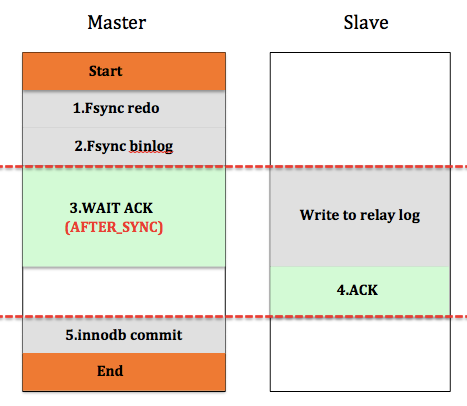
图3
并行复制
半同步复制解决了Master-Slave的强一致问题,那么性能问题呢?从图1中可以看到参与复制的主要有两个线程:IO线程和SQL线程,分别用于拉取和回放binlog。对于Slave而言,所有拉取和解析binlog的动作都是串行的,相对于Master并发处理用户请求,在高负载下, 若Master产生binlog的速度超过Slave消费binlog的速度,导致Slave出现延迟。如图4,可以看到,Users和Master之间的管道远远大于Master和Slave之间的管道。
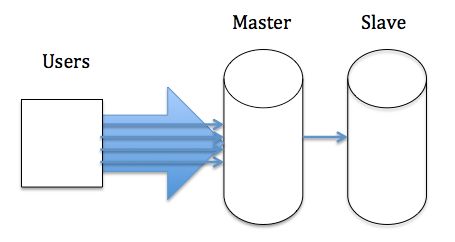
图4
那么如何并行化,并行IO线程,还是并行SQL线程?其实两方面都可以并行,但是并行SQL线程的收益更大,因为SQL线程做的事情更多(解析,执行)。并行IO线程,可以将从Master拉取和写Relay log分为两个线程;并行SQL线程则可以根据需要做到库级并行,表级并行,事务级并行。库级并行在mysql官方版本5.6已经实现。如图5,并行复制框架实际包含了一个协调线程和若干个工作线程,协调线程负责分发和解决冲突,工作线程只负责执行。图中,DB1,DB2和DB3的事务就可以并发执行,提高了复制的性能。有时候库级并发可能不够,需要做表级并发,或更细粒度的事务级并发。
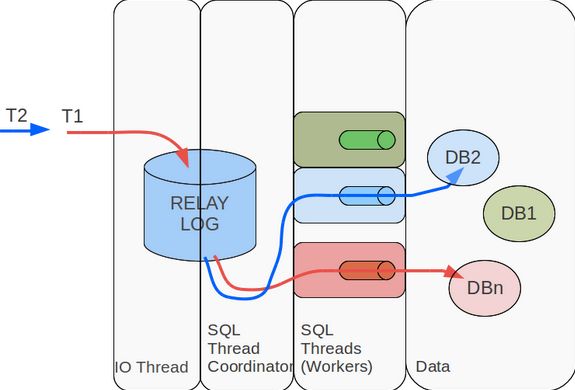
图 5
并行复制如何处理冲突?并发的世界是美好的,但不能乱并发,否则数据就乱了。Master上面通过锁机制来保证并发的事务有序进行,那么并行复制呢?Slave必需保证回放的顺序与Master上事务执行顺序一致,因此只要做到顺序读取binlog,将不冲突的事务并发执行即可。对于库级并发而言,协调线程要保证执行同一个库的事务放在一个工作线程串行执行;对于表级并发而言,协调线程要保证同一个表的事务串行执行;对于事务级而言,则是保证操作同一行的事务串行执行。
是否粒度越细,性能越好?这个并不是一定的。相对于串行复制而言,并行复制多了一个协调线程。协调线程一个重要作用是解决冲突,粒度越细的并发,可能会有更多的冲突,最终可能也是串行执行的,但消耗了大量的冲突检测代价。
第三方复制工具
为什么会出现第三方复制工具?第三方复制工具的出现一定是内嵌的复制功能不能满足用户需求,就像半同步复制和并行复制从无到有一样。既然现在mysql复制已经做地这么好了,为什么还有第三方复制工具,我能想到最重要的一点是异构复制。在异构数据源迁移场景下,内嵌复制是无能为力的,第三方复制工具通过解析源端的数据库日志,然后在目的端回放,就能达到同步的目的,比如大名鼎鼎的GoldenGate就是一个例子。第三方复制工具同样能很好地实现并发,在并行复制出现之前,这也是一个巨大的优势。另一方面,就是可以统一下游,避免所有下游都跑到DB上拉binlog,增大DB负载。
参考文档
https://code.google.com/p/google-mysql-tools/wiki/SemiSyncReplicationDesign
http://yoshinorimatsunobu.blogspot.com/2014/04/semi-synchronous-replication-at-facebook.html
http://mysqllover.com/?s=semi
https://code.google.com/p/mysql-parallel-replication/
http://www.cnblogs.com/cchust/p/3295547.html
http://www.gpfeng.com/?p=515
http://wenku.baidu.com/link?url=wc8ZY0j1oIRIRmcZ-dYFTcWghsR2nrxW9CqdXQczeqUqogi1GU6uF48nNjU_LraUmPxmxKU2kcsfYhPMTdTW-I65N3owFVuAOdOufPklb2a
http://www.docin.com/p-450229355.html