云计算之路-阿里云上:对“黑色30秒”问题的猜想
在云上,底层的东西你无法触及,遇到奇怪问题时只能靠猜想,所以使用云计算会锻炼你的想像力。
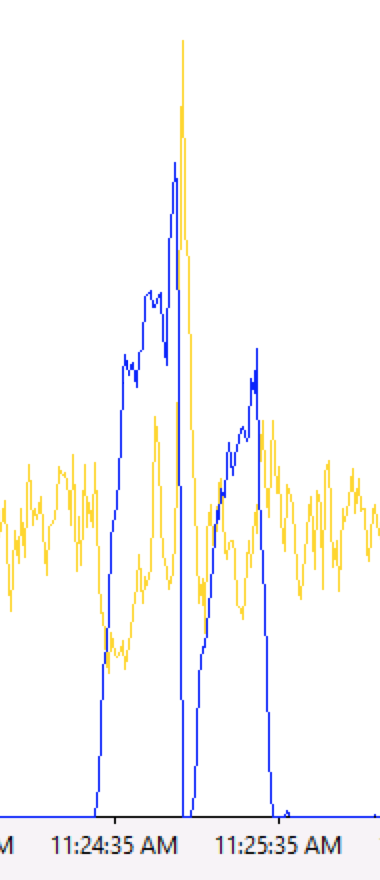
(上图中蓝色是ASP.NET的Requests Queued,另外一个是HTTP.SYS的Arrival Rate)
昨天我们发现了一个重要的线索——“黑色30秒”到来时,最初的表现是请求出现排队(Requests Queued上升),到达IIS的请求数量(Arrival Rate)下降。
而问题奇特之处就在Arrival Rate下降。如果只是Requests Queued上升,而Arrival Rate处于正常水平,我们首先会怀疑应用程序的原因——应用程序在处理请求时卡在哪个地方;而Requests Queued上升伴随着Arrival Rate下降,说明不仅后面出不去(请求完成不了),而且前面进不来(请求到达不了IIS)。应用程序不管出什么样的问题,都不可能造成Arrival Rate下降,所以我们目前找不到任何理由去怀疑应用程序。
于是,我们针对“前面请求进不来,后面请求出不去”展开了风花雪月的想像,终于找到了一个看上去说得通的猜想,下面分享一下。
*先看一下用户的请求是如何到达Web服务器的?
用户浏览器 -> SLB(阿里云负载均衡) -> VM(虚拟机)-> Web服务器
*再看Web服务器如何将响应发送给用户的?
Web服务器 -> VM -> SLB -> 用户浏览器
【猜想 】
假设SLB或VM在某种触发条件下,偷偷地断掉了一些TCP连接,并且不向用户端与服务端发送 FIN 或者 RST 报文,除了肇事者,谁也不知道。于是:
1) 用户端不知道TCP连接被断,还继续用这个TCP连接发包,结果请求当然到不了Web服务器,造成Arrival Rate下降。用户端TCP层发包后,等回包(比如ACK包),迟迟等不到,一直等到超时(假设超时时间是30s),才知道TCP链路挂掉了;然后重建TCP连接重发请求,这时请求成功到达了Web服务器,当前的请求+之前被断连接的请求一起到达Web服务器,这正好解释了“黑色30秒”结束阶段Arrival Rate会突增到一个高点。
2)Web服务器端与SLB端(或者SLB端与用户端)的TCP连接被断,Web服务器不知道,在处理完请求后还继续用这个断掉的TCP连接发送响应包并等回包,迟迟等不到,造成请求处理不能完成而被堆积,从而进一步造成后续的请求没有足够的资源可用而排队,于是Requests Queued上升;一直等到超时(假设超时时间是30s),Web服务器才知道TCP链路挂掉了,然后放弃这些请求处理,于是有了足够的资源处理队列中的请求,这正好解释了“黑色30秒”结束阶段Requests Queued会突降。
这就是我们目前找到的唯一能解释得通“黑色30秒”问题表现的一个猜想。