Knative共用单个共享自动缩放器。默认情况下,这是Knative Pod自动缩放器(KPA),开箱即用即可提供基于请求的快速自动缩放功能。
您还可以配置Knative使用Horizontal Pod Autoscaler(HPA)或使用定义的autoscaler。
KPA配置
KPA的配置文件位于knative-serving 命名空间中的configmap config-autoscaler 。我们执行下面的命令,查看一下默认的内容:
kubectl -n knative-serving describe cm config-autoscaler 可以看到默认的配置内容为:
====
_example:
----
################################
# #
# EXAMPLE CONFIGURATION #
# #
################################
# This block is not actually functional configuration,
# but serves to illustrate the available configuration
# options and document them in a way that is accessible
# to users that `kubectl edit` this config map.
#
# These sample configuration options may be copied out of
# this example block and unindented to be in the data block
# to actually change the configuration.
# The Revision ContainerConcurrency field specifies the maximum number
# of requests the Container can handle at once. Container concurrency
# target percentage is how much of that maximum to use in a stable
# state. E.g. if a Revision specifies ContainerConcurrency of 10, then
# the Autoscaler will try to maintain 7 concurrent connections per pod
# on average.
# Note: this limit will be applied to container concurrency set at every
# level (ConfigMap, Revision Spec or Annotation).
# For legacy and backwards compatibility reasons, this value also accepts
# fractional values in (0, 1] interval (i.e. 0.7 ⇒ 70%).
# Thus minimal percentage value must be greater than 1.0, or it will be
# treated as a fraction.
# NOTE: that this value does not affect actual number of concurrent requests
# the user container may receive, but only the average number of requests
# that the revision pods will receive.
container-concurrency-target-percentage: "70"
# The container concurrency target default is what the Autoscaler will
# try to maintain when concurrency is used as the scaling metric for the
# Revision and the Revision specifies unlimited concurrency.
# When revision explicitly specifies container concurrency, that value
# will be used as a scaling target for autoscaler.
# When specifying unlimited concurrency, the autoscaler will
# horizontally scale the application based on this target concurrency.
# This is what we call "soft limit" in the documentation, i.e. it only
# affects number of pods and does not affect the number of requests
# individual pod processes.
# The value must be a positive number such that the value multiplied
# by container-concurrency-target-percentage is greater than 0.01.
# NOTE: that this value will be adjusted by application of
# container-concurrency-target-percentage, i.e. by default
# the system will target on average 70 concurrent requests
# per revision pod.
# NOTE: Only one metric can be used for autoscaling a Revision.
container-concurrency-target-default: "100"
# The requests per second (RPS) target default is what the Autoscaler will
# try to maintain when RPS is used as the scaling metric for a Revision and
# the Revision specifies unlimited RPS. Even when specifying unlimited RPS,
# the autoscaler will horizontally scale the application based on this
# target RPS.
# Must be greater than 1.0.
# NOTE: Only one metric can be used for autoscaling a Revision.
requests-per-second-target-default: "200"
# The target burst capacity specifies the size of burst in concurrent
# requests that the system operator expects the system will receive.
# Autoscaler will try to protect the system from queueing by introducing
# Activator in the request path if the current spare capacity of the
# service is less than this setting.
# If this setting is 0, then Activator will be in the request path only
# when the revision is scaled to 0.
# If this setting is > 0 and container-concurrency-target-percentage is
# 100% or 1.0, then activator will always be in the request path.
# -1 denotes unlimited target-burst-capacity and activator will always
# be in the request path.
# Other negative values are invalid.
target-burst-capacity: "200"
# When operating in a stable mode, the autoscaler operates on the
# average concurrency over the stable window.
# Stable window must be in whole seconds.
stable-window: "60s"
# When observed average concurrency during the panic window reaches
# panic-threshold-percentage the target concurrency, the autoscaler
# enters panic mode. When operating in panic mode, the autoscaler
# scales on the average concurrency over the panic window which is
# panic-window-percentage of the stable-window.
# When computing the panic window it will be rounded to the closest
# whole second.
panic-window-percentage: "10.0"
# The percentage of the container concurrency target at which to
# enter panic mode when reached within the panic window.
panic-threshold-percentage: "200.0"
# Max scale up rate limits the rate at which the autoscaler will
# increase pod count. It is the maximum ratio of desired pods versus
# observed pods.
# Cannot be less or equal to 1.
# I.e with value of 2.0 the number of pods can at most go N to 2N
# over single Autoscaler period (see tick-interval), but at least N to
# N+1, if Autoscaler needs to scale up.
max-scale-up-rate: "1000.0"
# Max scale down rate limits the rate at which the autoscaler will
# decrease pod count. It is the maximum ratio of observed pods versus
# desired pods.
# Cannot be less or equal to 1.
# I.e. with value of 2.0 the number of pods can at most go N to N/2
# over single Autoscaler evaluation period (see tick-interval), but at
# least N to N-1, if Autoscaler needs to scale down.
max-scale-down-rate: "2.0"
# Scale to zero feature flag
enable-scale-to-zero: "true"
# Tick interval is the time between autoscaling calculations.
tick-interval: "2s"
# Scale to zero grace period is the time an inactive revision is left
# running before it is scaled to zero (min: 6s).
scale-to-zero-grace-period: "30s"
# Enable graceful scaledown feature flag.
# Once enabled, it allows the autoscaler to prioritize pods processing
# fewer (or zero) requests for removal when scaling down.
enable-graceful-scaledown: "false"
# pod-autoscaler-class specifies the default pod autoscaler class
# that should be used if none is specified. If omitted, the Knative
# Horizontal Pod Autoscaler (KPA) is used by default.
pod-autoscaler-class: "kpa.autoscaling.knative.dev"
# The capacity of a single activator task.
# The `unit` is one concurrent request proxied by the activator.
# activator-capacity must be at least 1.
# This value is used for computation of the Activator subset size.
# See the algorithm here: http://bit.ly/38XiCZ3.
# TODO(vagababov): tune after actual benchmarking.
activator-capacity: "100.0"接下来我们详细介绍一下每一个配置项的含义。
-
enable-scale-to-zero: 如果需要缩放到零,请确保将enable-scale-to-zero设置为true。默认是开启。 -
scale-to-zero-grace-period: 指定将非活动修订版本缩放到零(最小:6s)之前保持运行的时间。默认为30s。 -
stable-window:在稳定模式下运行时,autoscaler将在稳定窗口上的平均并发性数下操作(最小:6s)。默认为30s。当然也可以在Revision的模板中通过annotation设置。比如autoscaling.knative.dev/window: "60s"。 -
container-concurrency-target-percentage: -
activator-capacity: 单个activator任务的容量。单位是activator代理的一个并发请求。activator容量必须至少为1。该值用于计算activator子集大小。 -
pod-autoscaler-class: 指定使用的pod autoscaler类。如果省略,默认情况下使用Knative Horizontal Pod Autoscaler(KPA)。 -
enable-graceful-scaledown: 启用优雅的按比例缩小功能标志。启用后,它允许autoscaler优先缩容请求更少或没有请求的Pod。
缩小时减少#个(或零个)删除请求。 -
tick-interval: 自动缩放计算之间的时间,默认是2s。 -
max-scale-down-rate: 最大缩放比例限制了自动缩放器的缩容Pod速率。其值不能小于或等于1。当其值为2.0时,原来的Pod数目为N,在单个Autoscaler周期内(请参阅刻度间隔),Pod的数量最多可以缩容到N / 2,但如果Autoscaler需要缩小,则至少缩容到N-1。 -
max-scale-up-rate: 最大扩展速率限制了autoscaler的扩容Pod速率。其值不能小于或等于1。当其值为2.0时,原来的Pod数目为N,在单个Autoscaler周期内(请参阅刻度间隔),Pod的数量最多可以扩容到2N,但至少为N + 1,如果Autoscaler需要放大。 -
panic-threshold-percentage: 容器并发目标要达到的百分比,此时在紧急情况窗口内进入紧急状态。 -
panic-window-percentage: 当观察到紧急窗口期间的平均并发达到目标并发的紧急阈值百分比,自动缩放进入紧急模式。在紧急模式下运行时,autoscaler在紧急情况窗口上按平均并发缩放稳定窗口的紧急窗口百分比。计算恐慌窗口时,它将四舍五入到最接近的值
整秒。 -
target-burst-capacity: 指定并发中突发的请求大小。如果当前服务的备用容量小于设定值,Autoscaler将通过引入请求器路径中的Activator来尝试保护系统免于排队。如果此设置为 0,则只当修订版缩放为0时,Activator位于请求路径中。如果此设置 > 0,并且container-concurrency-target-percentage为100%或1.0,则Activator将始终位于请求路径中。-1 表示无限的目标爆发容量,Activator将始终在请求路径中。其他负值无效。 -
requests-per-second-target-default: 当将每秒请求数(RPS)用作修订的缩放指标,以及 修订版指定了无限制的RPS,autoscaler 将尝试去维护。即使指定了无限制的RPS,autoscaler将基于此目标RPS水平缩放应用程序。该值必须大于1.0。注意:仅一个度量标准可用于自动缩放修订。
Termination period
Termination period(终止时间)是 POD 在最后一个请求完成后关闭的时间。POD 的终止周期等于稳定窗口值和缩放至零宽限期参数的总和。在本例中,Termination period 为 90 秒。
配置并发
可以使用以下方法配置 Autoscaler 的并发数:
target
target 定义在给定时间(软限制)需要多少并发请求,是 Knative 中 Autoscaler 的推荐配置。
在 ConfigMap 中默认配置的并发 target 为 100。
`container-concurrency-target-default: 100这个值可以通过 Revision 中的 autoscaling.knative.dev/target 注释进行修改:
autoscaling.knative.dev/target: "50"containerConcurrency
注意:只有在明确需要限制在给定时间有多少请求到达应用程序时,才应该使用 containerConcurrency (容器并发)。只有当应用程序需要强制的并发约束时,才建议使用 containerConcurrency。
containerConcurrency 限制在给定时间允许并发请求的数量(硬限制),并在 Revision 模板中配置。
containerConcurrency: 0 | 1 | 2-N- 1: 将确保一次只有一个请求由 Revision 给定的容器实例处理;
- 2-N: 请求的并发值限制为 2 或更多;
- 0: 表示不作限制,有系统自身决定。
配置扩缩容边界(minScale 和 maxScale)
通过 minScale 和 maxScale 可以配置应用程序提供服务的最小和最大 Pod 数量。通过这两个参数配置可以控制服务冷启动或者控制计算成本。
minScale 和 maxScale 可以在 Revision 模板中按照以下方式进行配置:
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "2"
autoscaling.knative.dev/maxScale: "10"默认行为
如果未设置minScaleannotation,则容器将缩放为零(如果根据上述ConfigMap,如果enable-scale-to-zero为false,则缩放为1)。
如果未设置maxScale annotation,则创建的Pod数将没有上限。
KPA原理
其实关于伸缩,无非就是两个问题,第一个是参照的指标是什么?CPU?内存?RPS?另外一个问题是伸缩的策略,也就是伸缩的数目。

用到的组件
自动缩放系统由一些在此简要定义的“物理”和逻辑组件组成。了解它们是什么,它们在哪里部署以及它们在做什么,将极大地有助于理解控制和数据流。提到的组件可能做的事情比这里概述的要多。本文档将仅遵循影响自动缩放系统的细节。
Queue Proxy
队列代理是一个sidecar容器,与每个用户容器中的用户容器一起部署。发送到应用程序实例的每个请求都首先通过队列代理,因此其名称为“代理”。
队列代理的主要目的是测量并限制用户应用程序的并发性。如果修订将并发限制定义为5,则队列代理可确保一次到达应用程序实例的请求不超过5个。如果发送给它的请求更多,它将在本地将它们排队,因此是其名称中的“队列”。队列代理还测量传入的请求负载,并在单独的端口上报告平均并发和每秒请求数。
Autoscaler
自动缩放器是一个独立的Pod,包含三个主要组件:
- PodAutoscaler reconciler
- Collector
- Decider
PodAutoscaler协调程序可确保正确获取对PodAutoscalers的任何更改(请参阅API部分),并将其反映在Decider,Collector或两者中。
Collector负责从应用程序实例上的队列代理收集度量。为此,它会刮擦其内部指标端点并对其求和,以得到代表整个系统的指标。为了实现可伸缩性,仅会抓取所有应用程序实例的一个样本,并将接收到的指标外推到整个集群。
Decider获得所有可用指标,并决定应将应用程序部署扩展到多少个Pod。基本上,要做的事情就是want = concurrencyInSystem/targetConcurrencyPerInstance。
除此之外,它还会针对修订版的最大缩放比例和最小实例数和最大实例数设置值进行调整。它还计算当前部署中还剩下多少突发容量,从而确定是否可以从数据路径中删除Activator。
Activator
Activator是全局共享的部署,具有很高的可伸缩性。其主要目的是缓冲请求并向autoscaler报告指标。
Activator主要涉及从零到零的规模扩展以及容量感知负载平衡。当修订版本缩放到零实例时,Activator将被放置到数据路径中,而不是修订版本的实例中。如果请求将达到此修订版,则Activator将缓冲这些请求,并使用指标戳autoscaler并保留请求,直到出现应用程序实例。在这种情况下,Activator会立即将其缓冲的请求转发到新实例,同时小心避免使应用程序的现有实例过载。Activator在这里有效地充当负载平衡器。当它们可用时,它将负载分配到所有Pod上,并且不会在并发设置方面使它们过载。在系统认为合适的情况下,将Activator放置在数据路径上或从数据路径上取下,以使其充当如上所述的负载平衡器。如果当前部署具有足够的空间以使其不太容易过载,则将Activator从数据路径中删除,以将网络开销降至最低。
与队列代理不同,激活器通过Websocket连接主动将指标发送到autoscaler,以最大程度地减小从零开始的延迟。
算法
autoscaler是基于每个Pod(并发)的运行中请求的平均数量。系统的默认目标并发性为100,但是我们为服务使用了10。我们为服务加载了50个并发请求,因此自动缩放器创建了5个容器(50个并发请求/目标10 = 5个容器)。
算法中有两种模式,分别是panic和stable模式,一个是短时间,一个是长时间,为了解决短时间内请求突增的场景,需要快速扩容。
Stable Mode(稳定模式)
在稳定模式下,Autoscaler 根据每个pod期望的并发来调整Deployment的副本个数。根据每个pod在60秒窗口内的平均并发来计算,而不是根据现有副本个数计算,因为pod的数量增加和pod变为可服务和提供指标数据有一定时间间隔。
Panic Mode (恐慌模式)
KPA会在60秒的窗口内计算平均并发性,因此系统需要一分钟时间才能稳定在所需的并发性级别。但是,自动缩放器还会计算一个6秒的紧急窗口,如果该窗口达到目标并发性的2倍,它将进入紧急模式。在紧急模式下,自动缩放器在较短,更敏感的紧急窗口上运行。一旦在60秒内不再满足紧急情况,autoscaler将返回到最初的60秒稳定窗口。
|
Panic Target---> +--| 20
| |
| <------Panic Window
| |
Stable Target---> +-------------------------|--| 10 CONCURRENCY
| | |
| <-----------Stable Window
| | |
--------------------------+-------------------------+--+ 0
120 60 0
TIME数据流向
稳定模式下的扩缩

在稳定状态下,autoascaler会不断抓取当前活动的修订包,以不断调整修订的规模。当请求流入系统时,被刮擦的值将发生变化,并且自动缩放器将指示修订版的部署遵循给定的缩放比例。
SKS通过私有服务跟踪部署规模的变化。它将相应地更新公共服务。
scale 到 0

一旦系统中不再有任何请求,修订版本就会缩放为零。从autoscaler到修订版容器的所有刮擦都返回0并发性,并且activator报告的并发性相同(1)。
在实际删除修订的最后一个pod之前,系统应确保activator在路径中并且可路由。首先决定将比例缩放为零的autoscaler会指示SKS使用代理模式,因此所有流量都将定向到activator(4.1)。现在将检查SKS的公共服务,直到确保它返回activator的响应为止。在这种情况下,如果已经过去了宽限期(可通过_scale-to-zero-grace-period_进行配置),则修订的最后一个pod将被删除,并且修订已成功缩放为零(5)。
从 0 扩容

如果修订版本缩放为零,并且系统中有一个试图达到该修订版本的请求,则系统需要将其扩展。当SKS处于代理模式时,请求将到达activator(1),activator将对其进行计数并将其报告给autoscaler(2.1)。然后,activator将缓冲请求,并监视SKS的专用服务以查看端点的出现(2.2)。
Aujtoscaler从activator获取度量,并立即运行自动缩放循环(3)。该过程将确定至少需要一个pod(4),autoscaler将指示修订的部署扩展到N> 0个副本(5.1)。它还将SKS置于“服务”模式,一旦流量上升(5.2),流量就会直接流到修订版的Pod。
activator最终会看到端点出现并开始对其进行探测。一旦探测成功通过,相应的地址将被认为是健康的,并用于路由我们缓冲的请求以及在此期间到达的所有其他请求(8.2)。
该修订版已成功从零开始缩放。
KPA示例
我们使用官方autoscale-go来进行演示。service.yaml如下:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: autoscale-go
namespace: default
spec:
template:
metadata:
annotations:
# Target 10 in-flight-requests per pod.
autoscaling.knative.dev/target: "10"
autoscaling.knative.dev/minScale: "1"
autoscaling.knative.dev/maxScale: "3"
spec:
containers:
- image: gcr.io/knative-samples/autoscale-go:0.1部署完成以后,我们可以看到由于我们设置最小scale为1,所以即使在没有流量访问的情况下,也会保持一个实例。
kubectl get pods
NAME READY STATUS RESTARTS AGE
autoscale-go-h9x5z-deployment-84d57876-5mjzt 2/2 Running 0 12s根据并发数来作为扩缩的参照指标,30s内发起50个并发请求,minScale 最小保留实例数为 1,maxScale 最大扩容实例数为 3。
我们通过hey测试,执行以下命令:
hey -z 30s -c 50 "http://autoscale-go.default.serverless.ushareit.me?sleep=100&prime=10000&bloat=5"执行完毕,hey输出一些统计内容:
Summary:
Total: 30.1853 secs
Slowest: 0.4866 secs
Fastest: 0.1753 secs
Average: 0.1838 secs
Requests/sec: 271.6219
Total data: 819814 bytes
Size/request: 99 bytes
Response time histogram:
0.175 [1] |
0.206 [8044] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.238 [63] |
0.269 [39] |
0.300 [0] |
0.331 [1] |
0.362 [1] |
0.393 [7] |
0.424 [17] |
0.455 [11] |
0.487 [15] |
Latency distribution:
10% in 0.1782 secs
25% in 0.1794 secs
50% in 0.1808 secs
75% in 0.1828 secs
90% in 0.1863 secs
95% in 0.1910 secs
99% in 0.2502 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0012 secs, 0.1753 secs, 0.4866 secs
DNS-lookup: 0.0007 secs, 0.0000 secs, 0.1098 secs
req write: 0.0000 secs, 0.0000 secs, 0.0024 secs
resp wait: 0.1824 secs, 0.1752 secs, 0.3321 secs
resp read: 0.0001 secs, 0.0000 secs, 0.0071 secs
Status code distribution:
[200] 8199 responses查看具体POD扩缩情况如下:
kubectl get pods
NAME READY STATUS RESTARTS AGE
autoscale-go-h9x5z-deployment-84d57876-5mjzt 2/2 Running 0 5m15s
autoscale-go-h9x5z-deployment-84d57876-64b2f 2/2 Running 0 21s
autoscale-go-h9x5z-deployment-84d57876-pf2c9 2/2 Running 0 21s本来应该扩容到5个实例,但是由于设置了maxscale为3,所以最大实例为3。
您可以将Knative自动缩放配置为与默认KPA或基于CPU的指标(即“水平Pod自动缩放器”(HPA))一起使用。 通过在修订模板中添加或修改autoscaling.knative.dev/class和autoscaling.knative.dev/metric值作为注释,可以将Knative配置为使用基于CPU的自动缩放,而不使用基于默认请求的度量。
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/metric: cpu
autoscaling.knative.dev/target: "70"
autoscaling.knative.dev/class: hpa.autoscaling.knative.dev如果你已经在knative-monitoring 命名空间部署了对应的监控,那么观察grafana可以看到更直观的变化:

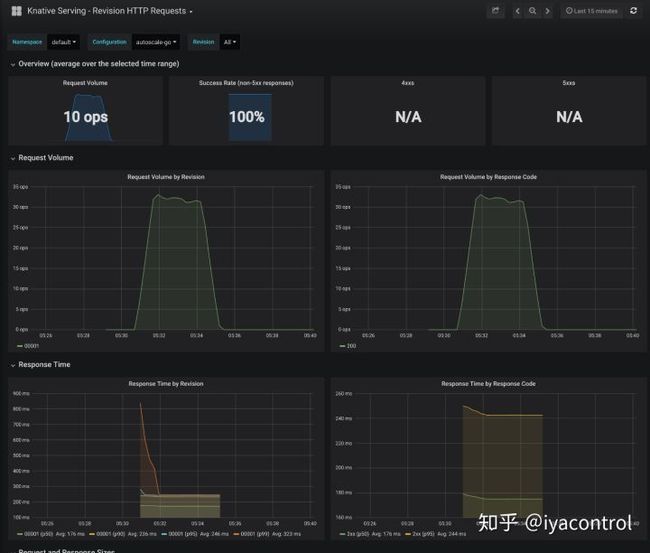
结论
相对于传统K8s的HPA,KPA支持了scale 到 0和从0扩容的特点。试想,在传统的HPA中,如果POD数目为0,那么根本没法统计到RPS,那么即使流量开始从无到有,那么HPA也不会扩容。