配置/etc/hosts文件
vi /etc/hosts
# 添加
192.168.200.110 master
192.168.200.111 slave1
192.168.200.112 slave2安装Zookeeper集群
下载Zookeeper安装包
下载地址:https://www.apache.org/dyn/cl...
创建对应的ZK数据和日志目录
# 创建ZK的数据目录,同时需要创建myid指定这个节点的ID
mkdir -p /software/zookeeper/zkdata/
vi /software/zookeeper/zkdata/myid
# 创建ZK的日志目录
mkdir /software/zookeeper/zklogs/修改zoo.cfg文件
先复制一份:
cp zoo_sample.cfg zoo.cfg开始修改:
cat zoo.cfg# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
# ZK的数据目录,myid也在里面
dataDir=/software/zookeeper/zkdata
# ZK的日志目录
dataLogDir=/software/zookeeper/zklogs
# 集群模式的各个节点,如果是自身的话,需要配置为0.0.0.0,而不是master/IP地址,不然可能会出现zk之间无法连接通信的情况。(如果您提供了公共IP,则侦听器将无法连接到端口,您必须为当前节点指定0.0.0.0)
server.1=0.0.0.0:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888启动/停止ZK/查看状态/重启
zkServer.sh start
zkServer.sh stop
zkServer.sh status
zkServer.sh restartZK的相关命令操作
# 连接ZK
[root@master conf]# zkCli.sh -server 127.0.0.1:2181
# 显示根目录下文件
[zk: 127.0.0.1:2181(CONNECTED) 0] ls /
[admin, brokers, cluster, config, consumers, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
# 显示根目录下文件,并能看到更新次数等数据
[zk: 127.0.0.1:2181(CONNECTED) 1] ls2 /
'ls2' has been deprecated. Please use 'ls [-s] path' instead.
[cluster, controller_epoch, brokers, zookeeper, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x400000003
cversion = 10
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 10
# 创建文件,并设置初始化内容
[zk: 127.0.0.1:2181(CONNECTED) 3] create /lzhpo-test1 "hello,lzhpo-test1~"
Created /lzhpo-test1
# 查看文件内容
[zk: 127.0.0.1:2181(CONNECTED) 6] get /lzhpo-test1
hello,lzhpo-test1~
# 修改文件内容
[zk: 127.0.0.1:2181(CONNECTED) 7] set /lzhpo-test1 "test1"
[zk: 127.0.0.1:2181(CONNECTED) 8] get /lzhpo-test1
test1
# 删除文件
[zk: 127.0.0.1:2181(CONNECTED) 9] delete /lzhpo-test1
[zk: 127.0.0.1:2181(CONNECTED) 10] ls /
[admin, brokers, cluster, config, consumers, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]剩下的,请看官方文档:https://zookeeper.apache.org/...
安装Kafka集群
下载Kafka安装包
下载地址:https://www.apache.org/dyn/cl...
开启JMX监控(可选)
方法1
如果不想做kafka的监控的话,可以选择不开启JMX监控。
就像下图这样子的监控,如果是自己写了一个Kafka的监控平台的话,不开启JMX监控就无法获取Kafka的一些信息。
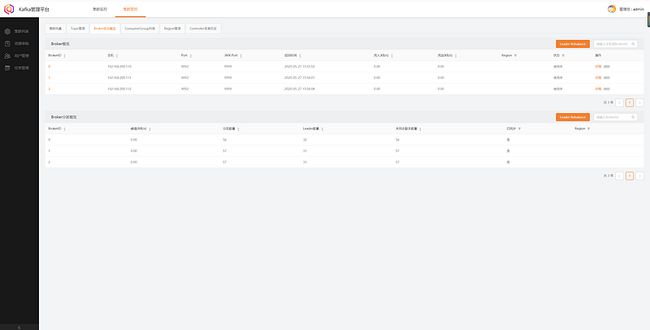
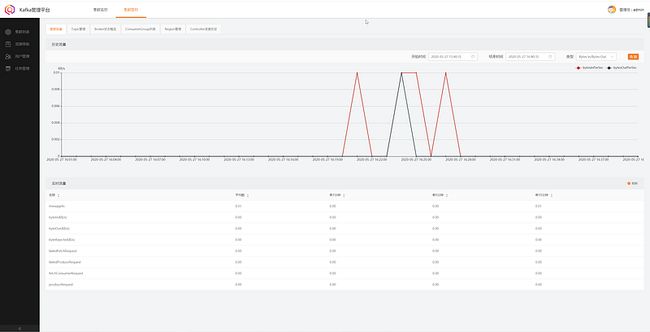

修改KAFKA_HEAP_OPTS为主机运行内存的一半;
vi /software/kafka/kafka_2.12-2.2.0/bin/kafka-server-start.sh添加export JMX_PORT="9999",也就是添加JMX监控,用来监控Kafka集群。
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx2G -Xms2G"
export JMX_PORT="9999"
fi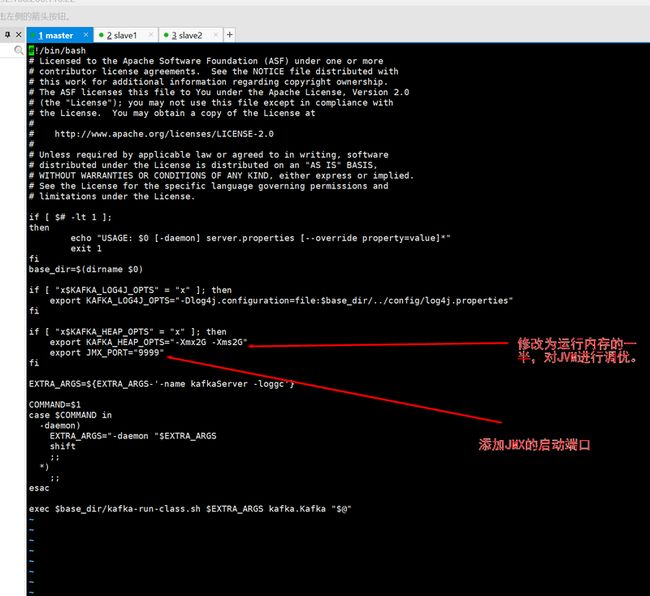
方法2(废弃)
这种方法在创建topic的时候,会报错:
Error: Exception thrown by the agent : java.rmi.server.ExportException: Port already in use: 9988; nested exception is:
java.net.BindException: Address in use (Bind failed)
sun.management.AgentConfigurationError: java.rmi.server.ExportException: Port already in use: 9988; nested exception is: # 修改kafka-run-class.sh
vi /software/kafka/kafka_2.12-2.2.0/bin/kafka-run-class.sh
# 第一行增加(也就是开启JMX监控,制定JMX监控端口)
JMX_PORT=9988
# 某些服务器可能无法正确绑定ip,这时候我们需要显示指定绑定的host
# 在参数KAFKA_JMX_OPTS,增加一个,也就是制定服务IP
# 不同的主机的需要修改为对应的IP地址
-Djava.rmi.server.hostname=192.168.10.110修改bin/kafka-server-start.sh
这是我优化的地方,优化JVM。
vi /software/kafka/kafka_2.12-2.2.0/bin/kafka-server-start.sh
# 调整KAFKA_HEAP_OPTS="-Xmx16G -Xms16G”的值
# 推荐配置:一般HEAP SIZE的大小不超过主机内存的50%。修改config/server.properties
vi /software/kafka/kafka_2.12-2.2.0/bin/server.properties
# 修改处1:broker.id,集群中唯一的ID,不同主机的不能相同。
broker.id=0
# 修改处2:对外网开放地址。不同主机需要修改为对应的地址
listeners=PLAINTEXT://192.168.200.110:9092
# 修改处3:监听地址。不同主机需要修改为对应的地址
advertised.listeners=PLAINTEXT://192.168.200.110:9092
# 修改处4:socket最大请求,int类型的,不能超过int类型的最大值
socket.request.max.bytes=2147483600
# 修改处5:partition的个数
num.partitions=6
# 修改处6:是否启用log压缩,一般不用启用,启用的话可以提高性能
log.cleaner.enable=false
# 修改处7:zookeeper集群地址
zookeeper.connect=192.168.200.110:2181,192.168.200.111:2181,192.168.200.112:2181
# 修改处8:是否允许删除
# 是否允许删除topic
delete.topic.enable=true
# 修改处9:消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
log.dirs=/software/kafka/kafka-logs# 创建消息存放的目录
mkdir -p /software/kafka/kafka-logs/Kafka调优请看我的文章:https://www.lzhpo.com/article...
配置文件调优详细说明(说明示例)
# 当前机器在集群中的唯一标识,和zookeeper的myid性质一样 建议用自己主机的后三位 每台(主机)broker不一致
broker.id
# 当前kafka对外提供服务的端口默认是9092 生产者(producer)要以这个端口为准[kafka-0.1.x之前]
#port
# 这个参数默认是关闭的,在0.8.1有个bug,DNS解析问题,失败率的问题。 (填写本机地址即可)[kafka-0.1.x之前]
#host.name
# Kafka启动的端口[kafka-0.1.x之前]
#advertised.port=9092
# kafka的本机IP地址[kafka-0.1.x之前]
#advertised.host.name=192.168.10.130
# 监听
listeners=PLAINTEXT://192.168.10.130:9092
# 对外开放。kafka-0.1.x之后的就是这样子修改的了,启用了上面的开放端口和地址方式
advertised.listeners=PLAINTEXT://192.168.10.130:9092
# 这个是borker进行网络处理的线程数
# 【优化:num.network.threads主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为cpu核数加1。】
num.network.threads=3
# 这个是borker进行I/O处理的线程数
# 【优化:num.io.threads主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。配置线程数量为cpu核数2倍,最大不超过3倍。】
num.io.threads=8
# 消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个
log.dirs=/software/kafka/kafka-logs
# 是否允许删除topic
delete.topic.enable=true
# 发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.send.buffer.bytes=102400
# kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.receive.buffer.bytes=102400
# 这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
# 【优化:这个是int类型的取值,int类型范围是-2147483648~2147483647。不能超出,超出之后报错:org.apache.kafka.common.config.ConfigException: Invalid value 8589934592 for configuration socket.request.max.bytes: Not a number of type INT。如果很纠结的话,那就按我推荐设置为2147483600】
socket.request.max.bytes=104857600
# 默认的分区数,一个topic默认1个分区数
# 【优化:默认partition数量1,如果topic在创建时没有指定partition数量,默认使用此值。Partition的数量选取也会直接影响到Kafka集群的吞吐性能,配置过小会影响消费性能,建议改为6。】
num.partitions=1
# 默认消息的最大持久化时间,168小时,7天
log.retention.hours=168
# 消息保存的最大值5M
message.max.byte=5242880
# kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务
default.replication.factor=2
# 取消息的最大直接数
replica.fetch.max.bytes=5242880
# 这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
log.segment.bytes=1073741824
# 每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除
log.retention.check.interval.ms=300000
# 是否启用log压缩,一般不用启用,启用的话可以提高性能
log.cleaner.enable=false
# 设置zookeeper的连接端口 消费的时候要以这个端口消费
zookeeper.connect=192.168.10.130:2181,192.168.10.128:2181,192.168.10.129:2181
# zookeeper连接超时时间
zookeeper.connection.timeout.ms=6000
# 【优化:为了大幅度提高producer写入吞吐量,需要定期批量写文件。一般无需改动,如果topic的数据量较小可以考虑减少log.flush.interval.ms和log.flush.interval.messages来强制刷写数据,减少可能由于缓存数据未写盘带来的不一致。推荐配置分别message 10000,间隔1s。】
# 每当producer写入10000条消息时,刷数据到磁盘
log.flush.interval.messages=10000
# 每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000默认的config/server.properties配置文件:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0修改完,分发到其它机器
scp -r /software/kafka/ slave1:/software/kafka/
scp -r /software/kafka/ slave2:/software/kafka/修改其它机器的参数
config/server.properties
需要修改的参数,修改为自己主机的实际地址:
broker.id、listeners、advertised.listeners
bin/kafka-run-class.sh
需要修改的:
-Djava.rmi.server.hostname
kafka相关操作命令
# 启动kafka
[root@master /]# kafka-server-start.sh -daemon /software/kafka/kafka_2.12-2.2.0/config/server.properties
# 停止kafka
[root@master /]# kafka-server-stop.sh
# 创建topic,设置分区数为3,副本数为6
[root@master kafka-logs]# kafka-topics.sh --create --zookeeper 192.168.200.110:2181,192.168.200.111:2181,192.168.200.112:2181 --replication-factor 3 --partitions 6 --topic lzhpo-topic-test06
Created topic lzhpo-topic-test06.
# 查看集群所有topic
[root@master kafka-logs]# kafka-topics.sh --list --zookeeper 192.168.200.110:2181,192.168.200.111:2181,192.168.200.112:2181
__consumer_offsets
lzhpo-topic-test01
lzhpo-topic-test02
lzhpo-topic-test03
lzhpo-topic-test04
lzhpo-topic-test05
lzhpo-topic-test06
lzhpo-topic-test3
lzhpo-topic-test4
topic-test-01# 在slave2节点启动消费者consumer,监听lzhpo-topic-test3的topic
[root@slave2 ~]# kafka-console-consumer.sh --bootstrap-server 192.168.200.112:9092 --topic lzhpo-topic-test05 --from-beginning
# 在slave1启动一个生产者发送消息
[root@slave1 ~]# kafka-console-producer.sh --broker-list 192.168.200.111:9092 --topic lzhpo-topic-test05slave2节点启动一个消费者:

slave1节点启动一个生产者发送消息:
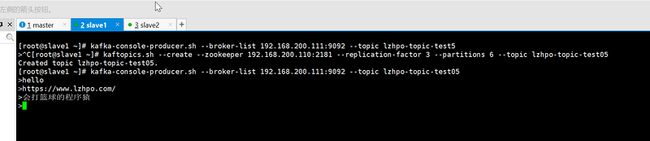
# 查看topic的信息
[root@master kafka-logs]# kafka-topics.sh --describe --zookeeper master:2181,slave1:2181,slave2:2181 --topic lzhpo-topic-test05
Topic:lzhpo-topic-test05 PartitionCount:6 ReplicationFactor:3 Configs:
Topic: lzhpo-topic-test05 Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: lzhpo-topic-test05 Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: lzhpo-topic-test05 Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: lzhpo-topic-test05 Partition: 3 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: lzhpo-topic-test05 Partition: 4 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: lzhpo-topic-test05 Partition: 5 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2kafka调优
调优参数:
-
replication.factor:这是给topic设置的参数,也就是分区数,这个参数值必须大于1,默认是1,要求每个partition必须至少有2个副本。kafka集群虽然是高可用的,但是该topic在有broker宕机时,可能发生无法使用的情况。
-
方法1:建立topic的时候就设置。
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 6 --topic lzhpo01查看修改情况:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic lzhpo01 -
方法2:动态的给已经创建的topic添加
replication-factora. 首先我们配置topic的副本,保存为json文件()
例如, 我们想把lzhpo01的部分设置为3,(我的kafka集群有3个broker,id分别为0,1,2), json文件名称为increase-replication-factor.json:{"version":1, "partitions":[ {"topic":"lzhpo01","partition":0,"replicas":[0,1,2]}, {"topic":"lzhpo01","partition":1,"replicas":[0,1,2]}, {"topic":"lzhpo01","partition":2,"replicas":[0,1,2]} ]}b. 执行脚本:
bin/kafka-reassign-partitions.sh -zookeeper 127.0.0.1:2181 --reassignment-json-file increase-replication-factor.json --executec.查看修改之后的topic副本因子:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic lzhpo01
-
-
min.insync.replicas:这是给Kafka服务端设置的参数,这个参数值也必须大于1,意思是要求一个Leader至少有一个Follower跟自己保持联系,也就是数据和Leader一直是保持同步的,这样子就确保了Leader挂掉了,至少还有一个Follower,不至于丢失数据。
设置
min.insync.replicas:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 6 --min.insync.replicas 2 --topic lzhpo01 - acks=all:这是在生产者端设置的,这是要求每条数据必须是写入所有的replica之后,才能认为是写入成功了。
就举个例子,SpringBoot集成Kafka的话,可以直接在
application.yml中配置:

-
retries=MAX:这个是要求一旦写入失败,就无限充值,卡在这里。这个我没有研究过,略......
欢迎关注我
一个热爱技术、热爱篮球的程序猿。
我的微信公众号:会打篮球的程序猿