Hbase学习笔记(安装和基础知识及操作)
1.Hbase简介
1.面向列的分布式数据库
2. 以HDFS作为文件系统
3. 利用MapReduce处理Hbase中海量数据
4. ZookKeeper作为协调工具
5. sqoop提供Hbase到关系型数据库中数据导入功能
6. Hive和pig提供高层语言支持如HSQL
2. 伪分布式安装
准备: 安装Hadoop 详细见上一篇日志: hadoop分布式安装
hbase版本: hbase-0.94.7-security.tar.gz
安装目录 /usr/local
步骤:
1. 安装 tar -zxvf hbase-0.94.7-security.tar.gz
2. 重命名: mv hbase-0.94.7-security hbase
3. 配置环境变量hbase_home (vi /etc/profile)
4. 修改配置文件
1. hbase_home/conf/hbase_env.sh 修改java_home export JAVA_HOME=/usr/local/jdk/ 修改zookeeper(最后一行) export HBASE_MANAGES_ZK=true(使用Hbase托管的ZooKeeper) 2. hbase_home/conf/hbase-site.xml文件 configuration 中加入: <property> <name>hbase.rootdir</name> <value>hdfs://hadoop0:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop0</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property>
5. 启动hbase
先启动hadoop(start-all.sh)
启用hbase (start-hbase.sh)
jps查看进程 (HMaster,HRegionServer, HQuorumPeer)
http://hadoop0:60010可以查看管理界面,如下:
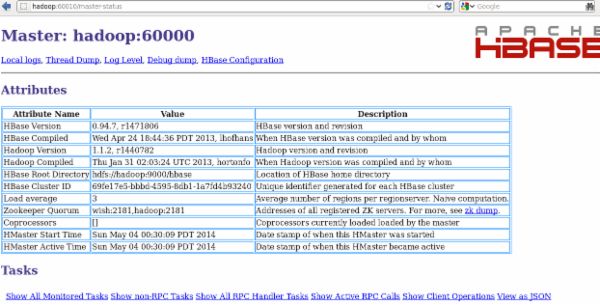
6. 进程说明:
HMaster: 管理Hbase table的DDL操作
给region分配工作
HResionServer: 原则上每个slave对应一个HRegionServer
HQuorumPeer: ZooKeeper的守护进程,此处我们使用的是Hbase内置的ZooKeeper(在hbase-env.sh中有配置)
3. 分布式安装
准备条件: hadoop分布式环境已安装,查看 hadoop分布式安装
hadoop0主机上hbase伪分布已安装完成
安装:
1. scp -rp /usr/local/hbase hadoop1:/usr/local
2. 在hadoop0上更改hbase_home/conf/regionservers 将localhost更改为hadoop1
3. 在hadoop0上启动hbase
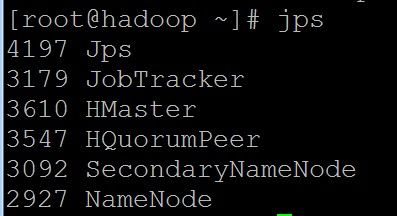
4. jps查看,如下:
hadoop0上进程:

hadoop1上进程:
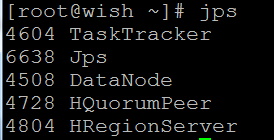
同理可通过 hostname:60010访问hbase管理界面,同分布式安装部分
4. 数据模型
1. Hbase数据库采用了和Bigtable非常类似的数据类型,表格是稀疏的;
1. row key 行键,table的主键
2. timestamp 时间戳,数据操作时对应的时间戳,可以看成数据的version number
3. Column Family 列簇,每个family可以由任意多个column组成,列名是<族名>:<标签>形式;一个表格的族名时固定的,除非使用管理员权限来改变表格的族名; 不过可以在任何时候添加新的标签;
eg:course对于表来说是一个有两个列的列族(该列族由两个列组成math和art);
| rowkey |
name |
TimeStamp |
course |
|
| math |
art |
|||
| wish |
wish |
t1 t2 t3 |
97 93 97 |
98 76 99 |
| rain |
rain |
t4 |
100 |
90 |
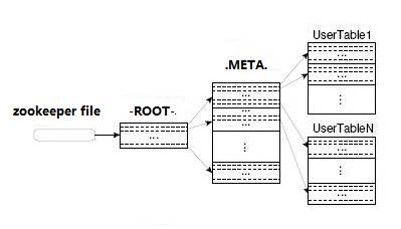
4.两张特殊的表 -ROOT- 和 .META.
作用如下:(即-ROOT-记录.META.的region信息,.META.记录用户表的region信息)

关系如下:
基本操作
(注意操作后不要加分号,习惯了sql,总是在后面加分号,然后发现执行语句后都一直没有反应,去掉分号后成功)
(表名和列名都需要加引号,不区分单双引号)
Hbase shell,是Hbase的命令行工具,命令行中执行hbase shell即可进入hbase shell命令行
1) list 查看hbase中所有表
2) 创建表:
create '表名','列簇1','列簇2'....
create 'student', 'name','grade','course'
在管理界面中查看student

3)describe 查看表结构
describe '表名'
eg: describe 'student'
hbase(main):003:0> describe "student" DESCRIPTION ENABLED 'student', {NAME => 'course', DATA_BLOCK_ENCODING = true > 'NONE', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSION => 'NONE', MIN _VERSIONS => '0', TTL => '2147483647', KEEP_DELETED _CELLS => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', ENCODE_ON_DISK => 'true', BLOCKCACHE => 'true'}, {NAME => 'grade', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSION => 'NONE', MIN_V ERSIONS => '0', TTL => '2147483647', KEEP_DELETED_C ELLS => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'false', ENCODE_ON_DISK => 'true', BLOCKCACHE => ' true'}, {NAME => 'name', DATA_BLOCK_ENCODING => 'NO NE', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '0 ', VERSIONS => '3', COMPRESSION => 'NONE', MIN_VERS IONS => '0', TTL => '2147483647', KEEP_DELETED_CELL S => 'false', BLOCKSIZE => '65536', IN_MEMORY => 'f alse', ENCODE_ON_DISK => 'true', BLOCKCACHE => 'tru e'}
4)插入数据和查看数据
put '表名','行键名','列名','value','列名2','value2','family:列名1','value3'.......
put 'student','wish','name:','wish'
查询数据:
get '表名','行名'
get 'student','wish'

插入更多数据
hbase(main):004:0> put 'student','wish','course:English','100' hbase(main):005:0> put 'student','wish','course:Chinese','60' hbase(main):006:0> put 'student','rain','course:Chinese','100' hbase(main):007:0> put 'student','rain','course:English','200'
查看表中数据: scan 'student'
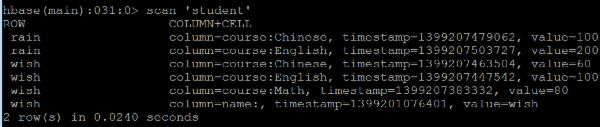
其他get例子:
get 'student','wish','course' get 'student','wish',['course'] get 'student','wish',['course','name']
5)删除数据
delete 'student','wish','course:Math'
6)删除表
需停止表的可用性,再删除表
disable 'student'drop 'student'
7) 统计行数
count 'student'