背景
Spark on MaxCompute可以访问位于阿里云VPC内的实例(例如ECS、HBase、RDS),默认MaxCompute底层网络和外网是隔离的,Spark on MaxCompute提供了一种方案通过配置spark.hadoop.odps.cupid.vpc.domain.list来访问阿里云的vpc网络环境的Hbase。Hbase标准版和增强版的配置不同,本文通过访问阿里云的标准版和增强版的Hbase简单的描述需要加的配置。
Hbase标准版
环境准备 Hbase的网络环境是存在vpc下的,所以我们首先要添加安全组开放端口2181、10600、16020.同时Hbase有白名单限制我们需要把对应的MaxCompute的IP加入到Hbase的白名单。 设置对应vpc的安全组
找到对应的vpc id然后添加安全组设置端口

添加Hbase的白名单
在hbase的白名单添加
100.104.0.0/16
创建Hbase表
create 'test','cf'
编写Spark程序 需要的Hbase依赖
org.apache.hbase
hbase-mapreduce
2.0.2
com.aliyun.hbase
alihbase-client
2.0.5
编写代码
object App {
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.appName("HbaseTest")
.config("spark.sql.catalogImplementation", "odps")
.config("spark.hadoop.odps.end.point","http://service.cn.maxcompute.aliyun.com/api")
.config("spark.hadoop.odps.runtime.end.point","http://service.cn.maxcompute.aliyun-inc.com/api")
.getOrCreate()
val sc = spark.sparkContext
val config = HBaseConfiguration.create()
val zkAddress = "hb-2zecxg2ltnpeg8me4-master\*-\*\*\*:2181,hb-2zecxg2ltnpeg8me4-master\*-\*\*\*:2181,hb-2zecxg2ltnpeg8me4-master\*-\*\*\*:2181"
config.set(HConstants.ZOOKEEPER\_QUORUM, zkAddress);
val jobConf = new JobConf(config)
jobConf.setOutputFormat(classOf\[TableOutputFormat\])
jobConf.set(TableOutputFormat.OUTPUT\_TABLE,"test")
try{
import spark.\_
spark.sql("select '7', 88 ").rdd.map(row => {
val name= row(0).asInstanceOf\[String\]
val id = row(1).asInstanceOf\[Integer\]
val put = new Put(Bytes.toBytes(id))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes(id), Bytes.toBytes(name))
(new ImmutableBytesWritable, put)
}).saveAsHadoopDataset(jobConf)
} finally {
sc.stop()
}}
}
提交到DataWorks 由于大于50m通过odps客户端提交
add jar SparkHbase-1.0-SNAPSHOT -f;
进入数据开发新建spark节点
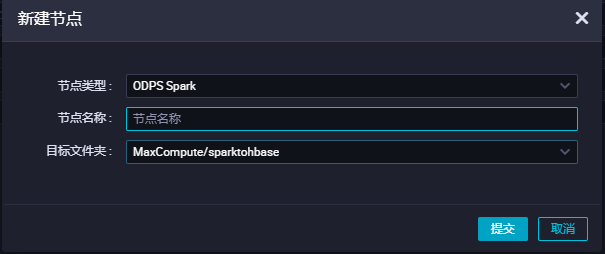
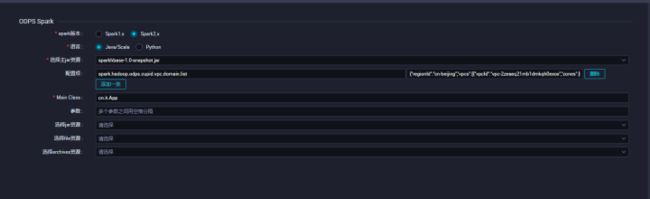
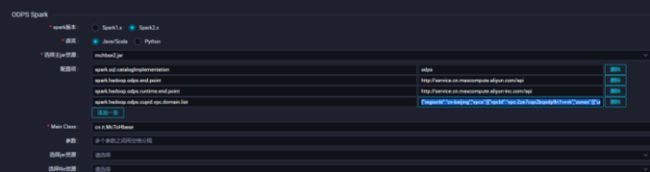
添加配置 需要配置spark.hadoop.odps.cupid.vpc.domain.list 这里的hbase域名需要hbase所有的机器,少一台可能会造成网络不通
{
"regionId":"cn-beijing",
"vpcs":[
{
"vpcId":"vpc-2zeaeq21mb1dmkqh0exox",
"zones":\[
{
"urls":\[
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":2181
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16000
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":2181
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16000
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":2181
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16000
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-cor\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-cor\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-cor\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
}
\]
}
\]
}]
}
Hbase增强版
环境准备 Hbase增强版的端口是30020、10600、16020.同时Hbase有白名单限制我们需要把对应的MaxCompute的IP加入到Hbase的白名单。 设置对应vpc的安全组 找到对应的vpc id然后添加安全组设置端口
![]()
添加Hbase的白名单
100.104.0.0/16
创建Hbase表
create 'test','cf'
编写Spark程序 需要的Hbase依赖,引用的包必须是阿里云增强版的依赖
com.aliyun.hbase
alihbase-client
2.0.8
编写代码
object McToHbase {
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.appName("spark\_sql\_ddl")
.config("spark.sql.catalogImplementation", "odps")
.config("spark.hadoop.odps.end.point","http://service.cn.maxcompute.aliyun.com/api")
.config("spark.hadoop.odps.runtime.end.point","http://service.cn.maxcompute.aliyun-inc.com/api")
.getOrCreate()
val sc = spark.sparkContext
try{
spark.sql("select '7', 'long'").rdd.foreachPartition { iter =>
val config = HBaseConfiguration.create()
// 集群的连接地址(VPC内网地址)在控制台页面的数据库连接界面获得
config.set("hbase.zookeeper.quorum", ":30020");
import spark.\_
// xml\_template.comment.hbaseue.username\_password.default
config.set("hbase.client.username", "");
config.set("hbase.client.password", "");
val tableName = TableName.valueOf( "test")
val conn = ConnectionFactory.createConnection(config)
val table = conn.getTable(tableName);
val puts = new util.ArrayList\[Put\]()
iter.foreach(
row => {
val id = row(0).asInstanceOf\[String\]
val name = row(1).asInstanceOf\[String\]
val put = new Put(Bytes.toBytes(id))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes(id), Bytes.toBytes(name))
puts.add(put)
table.put(puts)
}
)
}} finally {
sc.stop()}
}
}
注意 hbase clinet会报org.apache.spark.SparkException: Task not serializable 原因是spark会把序列化对象以将其发送给其他的worker 解决方案
- 使类可序列化
- 仅在map中传递的lambda函数中声明实例。
- 将NotSerializable对象设置为静态对象,并在每台计算机上创建一次。
- 调用rdd.forEachPartition并在其中创建
Serializable对象,如下所示:
rdd.forEachPartition(iter-> {NotSerializable notSerializable = new NotSerializable();
// ...现在处理iter});
提交到DataWorks 由于大于50m通过odps客户端提交
add jar SparkHbase-1.0-SNAPSHOT -f;
进入数据开发新建spark节点
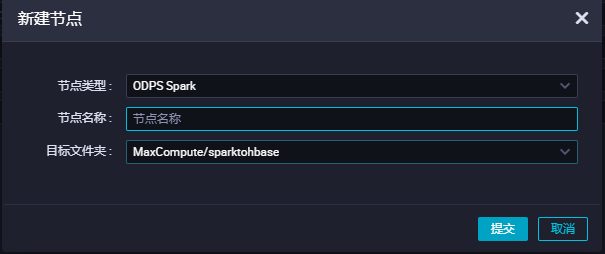
添加配置 需要配置spark.hadoop.odps.cupid.vpc.domain.list 注意: 1.这个里需要添加增强版java api访问地址,这里必须采用ip的形式。ip通过直接ping该地址获取,这里的ip是172.16.0.10添加端口16000

2.这里的hbase域名需要hbase所有的机器,少一台可能会造成网络不通
{
"regionId":"cn-beijing",
"vpcs":[
{
"vpcId":"vpc-2zeaeq21mb1dmkqh0exox",
"zones":\[
{
"urls":\[
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":30020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16000
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":30020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16000
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":30020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16000
},
{
"domain":"hb-2zecxg2ltnpeg8me4-master\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-cor\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-cor\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{
"domain":"hb-2zecxg2ltnpeg8me4-cor\*-\*\*\*.hbase.rds.aliyuncs.com",
"port":16020
},
{"domain":"172.16.0.10","port":16000}
\]
}
\]
}]
}
大家如果对MaxCompute有更多咨询或者建议,欢迎扫码加入 MaxCompute开发者社区钉钉群,或点击链接 申请加入。
