
- 「MoreThanJava」 宣扬的是 「学习,不止 CODE」,本系列 Java 基础教程是自己在结合各方面的知识之后,对 Java 基础的一个总回顾,旨在 「帮助新朋友快速高质量的学习」。
- 当然 不论新老朋友 我相信您都可以 从中获益。如果觉得 「不错」 的朋友,欢迎 「关注 + 留言 + 分享」,文末有完整的获取链接,您的支持是我前进的最大的动力!
Part 1. 机器指令

上一次 我们已经了解了 二进制和 CPU 的基本原理,知道了程序运行时,CPU 每秒数以亿次、十亿次、百亿次地震荡着时钟,同步执行着微小的 「电子操作」,例如:从内存读取一个字节的数据到 CPU 又或者判断字节中的某一位是 0 还是 1。
CPU 本身有一组 规定好的 可以执行的 「基本动作」(被称为 机器指令):
- 读取指令;2. 执行指令;3. 写寄存器;
这几乎就是 CPU 工作的全部了。 这些动作虽然每次只能执行一次,但是每秒可以执行数十亿次,这个数量级的「小操作」累加成为一个大的「有用的操作」。
处理器所做的一切都是基于这些微小的操作!幸运的是,我们已经不再需要了解这些操作的详细信息就可以编写和使用各类程序。诸如 Java 这一类的 「高级语言」 的 目的 就是 将这些微小的电子操作组织成由人类可读的「程序语言」表示的大型有用单元。
机器指令演示
一条 机器指令 一般由内存中的几个字节组成,它们告诉 CPU 应该执行一个什么样的 「机器操作」(是取数据还是写寄存器等..)。处理器依次查看 CPU 中的机器指令,并执行每一条。内存中的一组机器指令被称为 「机器语言程序」,或称为 「可执行程序」。
下面我们来使用机器语言来演示一个控制灯泡亮度的机器语言程序。
先和硬件做好规定
假设灯泡由内存中的某一个程序控制,该程序能够完全打开和关闭灯泡,可以使灯泡变亮或变暗,机器指令一个字节长度,并且与机器操作对应如下:
| 机器指令 | 机器操作 |
|---|---|
| 00000000 | 停止程序 |
| 00000001 | 完全打开灯泡 |
| 00000010 | 完全关闭灯泡 |
| 00000100 | 灯泡暗淡 10% |
| 00001000 | 将灯泡照亮 10% |
| 00010000 | 如果灯泡完全点亮,则跳过下一条说明 |
| 00100000 | 如果灯泡完全熄灭,请跳过下一条说明 |
| 01000000 | 转到程序的开始(地址 0) |
Demo 程序 && 演示
根据上方作出的规定,我们写下如下的程序:(为了方便理解,我把对应的机器操作也写在了后面,实际的程序只包含机器指令)
| 地址 | 机器指令 | 机器操作 |
|---|---|---|
| 0 | 00000001 | 完全打开灯泡 |
| 1 | 00000010 | 完全关闭灯泡 |
| 2 | 00000001 | 完全打开灯泡 |
| 3 | 00000100 | 灯泡暗淡10% |
| 4 | 00000100 | 灯泡暗淡10% |
| 5 | 00000000 | 停止程序 |
所以这样的一段程序执行效果就如下图:

您可以尝试自己利用 01000000(跳转到程序开始) 来改写程序来达到让「灯逐渐变亮又逐渐变暗」的目的。
小结
上面演示的程序 核心思想 是:
- 机器语言程序是内存中一系列机器指令的集合;
- 机器指令由一个或多个字节组成(在此示例中,仅一个字节);
- 处理器一次运行一条机器指令的程序;
- 所有的小机器操作加起来都是有用的;
在实际的 CPU 中,拥有更多的机器指令,而且更详细,并且不同的 CPU,指令集是不同的。典型的 CPU 拥有一千或更多的机器指令。
Part 2. 汇编语言

机器语言太 "反人类”
我们已经可以开始写一些程序使用了,但是使用 机器语言编写代码会十分辛苦,比如:
00000001 00000010 00000001
00000100 00000100 00000000即使你刚看过你也会对这一段就在 上方的实例代码 没有什么感知,这是因为机器语言是设计给机器的,人类记忆和使用起来就会显得十分麻烦。
如此你就会感知到 上个世纪 的程序员使用 打孔卡片:

使用 纸带:

甚至是 直接插拔线路 or 按下开关:

是一件多么硬核的事情...

如果你对它们如何工作以及多么硬核感兴趣,可以参考一下下方的链接:
- 开发语言小传之一:最早的编程语言——机器语言 - https://blog.csdn.net/killer0...
- 50年前的登月程序和程序员有多硬核 - https://coolshell.cn/articles...、
再附带一个宝藏网站(哥伦比亚大学出版的计算机历史,非常详细),有条件的同学 非常推荐 进去浏览一下:
汇编语言诞生
CPU 的指令都是 二进制 的,这显然对于人类来说是 不可读 的。为了解决二进制指令的可读性问题,工程师将那些指令写成了 八进制。二进制转八进制是轻而易举的,但是八进制的可读性也不行。
很自然地,最后还是用文字表达,加法指令写成 ADD。内存地址也不再直接引用,而是 用标签 表示。
这样的话,就多出一个步骤,要把这些文字指令翻译成二进制,这个步骤就称为 assembling,完成这个步骤的程序就叫做 assembler。它处理的文本,自然就叫做 aseembly code。标准化以后,称为 assembly language,缩写为 asm,中文译为 汇编语言。

理解汇编语言
每一种 CPU 的机器指令都是不一样的,因此对应的汇编语言也不一样。本文介绍的是目前最常见的 x86 汇编语言,即 Intel 公司的 CPU 使用的那一种。
寄存器
要学习汇编语言,首先必须了解两个知识点:寄存器 和 内存模型。
先来看寄存器。CPU 本身只负责运算,不负责储存数据。数据一般都储存在内存之中,CPU 要用的时候就去内存读写数据。但是,CPU 的运算速度远高于内存的读写速度,为了避免被拖慢,CPU 都自带一级缓存和二级缓存。基本上,CPU 缓存可以看作是读写速度较快的内存。
但是,CPU 缓存还是不够快,另外数据在缓存里面的地址是不固定的,CPU 每次读写都要寻址也会拖慢速度。因此,除了缓存之外,CPU 还自带了寄存器(register),用来储存最常用的数据。也就是说,那些最频繁读写的数据(比如循环变量),都会放在寄存器里面,CPU 优先读写寄存器,再由寄存器跟内存交换数据。

寄存器不依靠地址区分数据,而依靠名称。每一个寄存器都有自己的名称,我们告诉 CPU 去具体的哪一个寄存器拿数据,这样的速度是最快的。有人比喻寄存器是 CPU 的零级缓存。
寄存器的种类
早期的 x86 CPU 只有 8 个寄存器,而且每个都有不同的用途。现在的寄存器已经有 100 多个了,都变成通用寄存器,不特别指定用途了,但是早期寄存器的名字都被保存了下来。
- EAX
- EBX
- ECX
- EDX
- EDI
- ESI
- EBP
- ESP
上面这 8 个寄存器之中,前面七个都是通用的。ESP 寄存器有特定用途,保存当前 Stack 的地址(详见下一节)。

我们常常看到 32 位 CPU、64 位 CPU 这样的名称,其实指的就是寄存器的大小。32 位 CPU 的寄存器大小就是 4 个字节。
内存模型:Heap(堆)
寄存器只能存放很少量的数据,大多数时候,CPU 要指挥寄存器,直接跟内存交换数据。所以,除了寄存器,还必须了解内存怎么储存数据。
程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从 0x1000 到 0x8000,起始地址是较小的那个地址,结束地址是较大的那个地址。

程序运行过程中,对于动态的内存占用请求(比如新建对象,或者使用 malloc 命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分(实际上,起始地址会有一段静态数据,这里忽略)。举例来说,用户要求得到 10 个字节内存,那么从起始地址 0x1000 开始给他分配,一直分配到地址 0x100A,如果再要求得到 22 个字节,那么就分配到 0x1020。

这种因为用户主动请求而划分出来的内存区域,叫做 Heap(堆)。它由起始地址开始,从低位(地址)向高位(地址)增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
内存模型:Stack(栈)
除了 Heap 以外,其他的内存占用叫做 Stack(栈)。简单说,Stack 是由于 函数运行 而 临时占用 的内存区域。

例如我们在执行一个叫 main 的函数时,会为它在内存里面创建一个 帧,用来保存所有 main 中使用的内部变量。main 函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。

如果在 main 函数 内部调用了其他函数,例如 add_a_and_b 函数,那么执行到这一行的时候,系统也会为 add_a_and_b 新建一个帧,用来储存它的内部变量。也就是说,此时同时存在两个帧:main 和 add_a_and_b。一般来说,调用栈有多少层,就有多少帧。

等到 add_a_and_b 运行结束,它的帧就会被回收,系统会回到函数 main 刚才中断执行的地方,继续往下执行。通过这种机制,就实现了函数的 层层调用,并且 每一层都能使用自己的本地变量。
我们可以把栈理解为一个下方密封,而上方打开的「桶」。
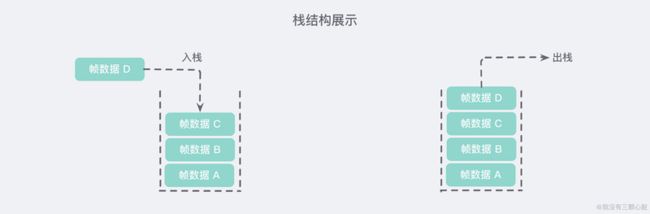
生成的新帧放入我们称之为 「入栈」,而释放帧我们称之为 「出栈」。栈的特点 就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做 "后进先出" 的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个栈就都释放了。
汇编语言演示
举个简单的例子,我们需要计算:
(1 + 4) * 2 + 3我们按照 「后缀表示法」 进行一下转换:
1,4,+,2,*,3,+我们平常使用的方法是 「中缀表示法」,也就是把计算符号放中间,例如 1 + 3,后缀则是把符号放最后,例如 1, 3, +。
这样做的好处是没有先乘除后加减的影响,也没有括号,直接运算就行了。(例如 1, 3, +,先把 1 和 3 保存起来碰到 + 知道是加法则直接相加)
OK,我们从头开始使用汇编语言来编写一下程序,首先第一步:把 1 保存起来(放入寄存器):
MOV 1之后是 4, +,那就直接加一下:
ADD 4然后是 2, *,那就直接乘一下(SHL 是向左移动一位的意思,二进制中左移一个单位就相当于乘以 2,例如 01 表示 1,而 10 则表示 2):
SHL 0最后是 3, +,再加一下:
ADD 3完整程序如下:
MOV 1
ADD 4
SHL 0
ADD 3这似乎看起来比 00001111 这样的二进制要好上太多了!程序员们感动到落泪:

Part 3. 高级编程语言

摆脱了 二进制,我们有了更可读的 汇编语言,但仍然十分繁琐和复杂,每一条汇编指令代表一个基本操作,例如:「从内存 x 位置获取一个数字并放入寄存器 A」、「将寄存器 A 中的数字添加到寄存器 B 的数字上」。这样的编程风格既费时又容易出错,并且一旦出错还很难发现。
例如,我们来看一看 「1969 年阿波罗 11号登月计划」 用来 防止登月舱计算机耗尽自身资源 的 BAILOUT 代码:
POODOO INHINT
CA Q
TS ALMCADR
TC BANKCALL
CADR VAC5STOR # STORE ERASABLES FOR DEBUGGING PURPOSES.
INDEX ALMCADR
CAF 0
ABORT2 TC BORTENT
OCT77770 OCT 77770 # DONT MOVE
CA V37FLBIT # IS AVERAGE G ON
MASK FLAGWRD7
CCS A
TC WHIMPER -1 # YES. DONT DO POODOO. DO BAILOUT.
TC DOWNFLAG
ADRES STATEFLG
TC DOWNFLAG
ADRES REINTFLG
TC DOWNFLAG
ADRES NODOFLAG
TC BANKCALL
CADR MR.KLEAN
TC WHIMPER- 出处:改变世界的代码行 - https://www.infoq.cn/article/...
似乎不太容易读的样子...
阿波罗登月计划的源代码在 Github 上已经公开,有兴趣的可以去下方链接膜拜一下(可以去感受一下当时程序员的工程能力):
另外附一下当时代码的设计负责人 Margaret Heafield Hamilton(女程序员)和完成的堆起来跟人一样高的代码量:

第一个高级语言:FORTRAN
当 John Backus 在 1950 年以一名科学程序员的身份加入 IBM 时,已经可以使用诸如 ADD 之类的助记词代替数字代码来编写程序,也就是我们的汇编语言。这使编程变得容易一些,但是即使是一个简单的程序也需要数十次操作,并且仍然很难找到错误。
巴克斯认为,应该有可能创建一种编程语言,使一系列计算可以用类似于数学符号的形式来表达。然后,使用特定的翻译程序(以今天的术语来说是编译器)可以将其转换为计算机可以理解的数字代码。
Backus 在 1953 年向他的经理提出了这个想法。他得到了预算,并被鼓励雇用一个小团队来测试该想法的可行性。三年后,该团队发布了一本手册,其中描述了 IBM Mathematical Formula Translating System(简称 FORTRAN)。不久之后, IBM 向 IBM 704 的用户提供了第一个 FORTRAN 编译器。

Backus 和他的团队创造了世界上第一种高级编程语言。科学家和工程师将不再需要将其程序编写为数字代码或冗长的助记符。
FORTRAN 代码演示
下面演示计算并输出 8 * 6 的代码实例:
program VF0944
implicit none
integer a, b, c
a= 8
b= 6
c= a*b
print *, 'Hello World, a, b, c= ', a, b, c
end program VF0944对比汇编代码,是不是看上去要清晰(人类可读)多了呢?
FORTRAN 的意义
FORTRAN 的问世在计算机史上具有划时代的意义,它使计算机语言从原始的低级汇编语言走出来,进入了更高的境界,使得 计算机语言不再是计算机专家的专利,使广大的工程技术人员有了进行计算机编程的手段。
由此计算机更快地深入到了社会之中,它在工业部门中初露头角,更是在火箭、导弹、人造地球卫星的设计中大显身手,因此有人称 FORTRAN 语言使计算机的工业应用成了可能,是推动第二次世界大战以后西方工业经济复苏和进入第二次工业革命的无形力量,是 "看不见的蒸汽机"。
FORTRAN 后时代
FORTRAN 高级程序设计语言的出现孕育了计算机软件业,继其之后,计算机高级程序语言的开发进入到了一个蓬勃发展的时代。
1959
Grace Hopper 发明了第一个面向企业业务的编程语言,又称 “面向商业的通用语言”,也常常简称 COBOL。
1964
美国达特茅斯学院约翰·凯梅尼和托马斯·卡茨认为,像 FORTRAN 那样的语言太过专业,编程非常困难。于是他们简化了 FORTRAN,并设计出了更适合初学者的 BASIC 语言。
1970
尼古拉斯·沃斯非常痴迷于编程语言,他率先提出了结构化程序设计思想并发明了 Pascal 语言。
此外他还提出了 Wirth 定律,意为 “软件变慢的速度比硬件变快的速度更快”,这让摩尔定律变得充满讽刺。之后的 Electron.js 也确实证明了这一点。
1972
丹尼斯·里奇在贝尔实验室工作期间发明了 C 语言,开启了现代程序语言的革命。之后,他又添加了段错误和其他一些帮助开发人员的实用功能,大大提升了编程效率。
除了 C 语言之外, 他和贝尔实验室的同事还创造了伟大的 Unix 操作系统。
1980
Alan Kay 发明了面向对象的编程语言 Smalltalk,在 Smalltalk 中,一切皆对象。
1987
拉里·沃尔发明了 Perl 语言。
1983
Jean Ichbiah 发现 Ada Lovelace 的程序从未运行成功过,因此决定用她的名字创建一种语言,于是 Ada 语言诞生了。
1986
Brac Box 和 Tol Move 通过融合 C 语言和 Smalltalk 的特征,发明了 Objective-C。但由于其语法晦涩,不太容易理解。
1983
Bjarne Stroustrup 在 C 语言的基础上引入并扩充了面向对象的概念,发明了—种新的程序语言并将其命名为 C++。
C++ 大大提升了应用程序的编程效率。
1991
Guido van Rossum 讨厌带有大括号的编程语言,于是他参考 Monty Python 和 Flying Circus 语法,并发明了 Python。
1993
Roberto Ierusalimschy 和其朋友创造了一门巴西本地的脚本语言。在本地化过程中,由于一个小的错误使得索引从1开始,而不是0。这门语言就是 Lua。
1994
Rasmus Lerdorf 为他个人主页的 CGI 脚本制作了一个模板引擎,用来统计他自己网站的访问量。
这个文件被上传到网上之后用它的人越来越多。后来又用 C 语言重新编写,还添加了数据库访问功能。这门语言就是 PHP。
1995
松本行弘发明了 Ruby 语言。
1995
Brendan Eich 利用周末时间设计了一种语言,用于为世界各地的网页浏览器提供支持,并最终推出了 Skynet。他最初去了 Netscape,并将这门语言命名为 LiveScript,后来在代码审查期间 Java 逐渐开始风靡,因此他们决定将其改名为 JavaScript。
后来 Java 使其陷入了商标麻烦,于是 JavaScript 被更名为 ECMAScript。但是人们还是习惯称之为 JavaScript。
1996
James Gosling 发明了 Java,这是 第一个真正意义上面向对象得编程语言,其中设计模式在实用主义中占统治地位。
More...
对于这一段计算机历史感兴趣的同学可以拜读一下「IT 通史 12.2 节 - 高级计算机程序设计语言」的内容,在线预览链接如下:
高级语言分类
CPU 终究只认识二进制指令,在我们发明高级语言之后,仍然无可避免的需要进行 「翻译」 工作。按照翻译方式的不同,我们又把高级语言分为了 「编译型」 和 「解释型」。
编译型
编译型专业解释为:
使用 专门的编译器,针对 特定的平台,将高级语言源代码 一次性 的编译成可被该平台硬件执行的机器码,并包装成该平台所能识别的可执行性程序的格式,并且只需要编译一次,以后再也不用编译。其实可以简单理解成谷歌/ 百度翻译,我们把要翻译的文字全部放进去,一次翻译,下次使用直接使用上一次翻译好的结果。

- 优点(较解释型):执行效率高(有解释器省去很多翻译的过程)
- 缺点(较解释型):开发效率低(写完所有的代码才能检查
bug,得多恐怖呀???)
解释型

解释型专业解释为:
使用 专门的解释器 对源程序逐行解释成 特定平台 的机器码并 立即执行,它不需要事先编译,直接将代码解释称机器码直接运行,也就是说只要某一平台提供了相应的解释器即可运行代码。其实可以理解成同声传译,我们需要翻译的时候,找一个翻译员,对方说一句翻译员翻译一句,下次翻译还是需要一个翻译员一句一句的翻译。

- 缺点(较编译型):执行效率低(写一次翻译一次)
- 优点(较编译型):开发效率高(写一行翻译一行,错了马上就知道,妈妈再也不用担心我找不到 bug 了)
半解释半编译的 Java
不同厂商、不同时间开发的 CPU 的指令集是不一样的,这就是上方为什么提到要使用 专门的解释器,要用于 特定的平台 的原因。
所以 Java 为了实现 「一次编译,到处运行」 的目的,采用了一种特别的方案:先 编译 为 与任何具体及其环境及操作系统环境无关的中间代码(也就是 .class 字节码文件),然后交由各个平台特定的 Java 解释器(也就是 JVM)来负责 解释 运行。
编程人员和计算机都无法直接读懂字节码文件,它必须由专用的 Java 解释器来解释执行,因此 Java 是一种在 编译基础上进行解释运行 的语言。(Java 程序运行流程如下)

Java 解释器 负责将字节码文件翻译成具体硬件环境和操作系统平台下的机器代码,以便执行。因此 Java 程序不能直接运行在现有的操作系统平台上,它必须运行在被称为 Java 虚拟机的软件平台之上。
Java 虚拟机(JVM) 是运行 Java 程序的软件环境(我们后面会详细说到,这是学习 Java 绕不过的题),Java 解释器是 Java 虚拟机的一部分。在运行 Java 程序时,首先会启动 JVM,然后由它来负责解释执行 Java 的字节码程序,并且 Java 字节码程序只能运行于 JVM 之上。这样利用 JVM 就可以把 Java 字节码程序和具体的硬件平台以及操作系统环境分隔开来,只要在不同的计算机上安装了针对特定平台的 JVM,Java 程序就可以运行,而不用考虑当前具体的硬件平台及操作系统环境,也不用考虑字节码文件是在何种平台上生成的。
JVM 把这种不同软、硬件平台的具体差别隐藏起来,从而 实现了真正的二进制代码级的跨平台移植。JVM 是 Java 平台架构的基础,Java 的跨平台特性正是通过在 JVM 中运行 Java 程序实现的。Java 的这种运行机制可以通过下图来说明:

Java 语言这种「一次编写,到处运行」的方式,有效地解决了目前大多数高级程序设计语言需要针对不同系统来编译产生不同机器代码的问题,即硬件环境和操作平台的异构问题,大大降低了程序开发、维护和管理的开销。
- 提示: Java 程序通过 JVM 可以实现跨平台特性,但 JVM 是不跨平台的。也就是说,不同操作系统之上的 JVM 是不同的,Windows 平台之上的 JVM 不能用在 Linux 平台,反之亦然。
参考资料
- Introduction to Computer Science using Java | CHAPTER 4 - http://programmedlessons.org/...
- 汇编语言入门教程 - http://www.ruanyifeng.com/blo...
- CPU 是怎么认识代码的? | 知乎@Zign - https://www.zhihu.com/questio...
- 改变世界的代码行 - https://www.infoq.cn/article/...
- The History of FORTRAN - https://www.obliquity.com/com...
- 《IT 通史》 | @李彦
- A Brief Totally Accurate History Of Programming Languages - https://medium.com/commitlog/...
- 编程语言分类 - https://www.cnblogs.com/nickc...
往期精彩
- 「MoreThanJava」当大学选择了计算机之后应该知道的
- 「MoreThanJava」计算机发展史—从织布机到IBM
- 「MoreThanJava」计算机系统概述
- 「MoreThanJava」一文了解二进制和CPU工作原理
- 本文已收录至我的 Github 程序员成长系列 【More Than Java】,学习,不止 Code,欢迎 star:https://github.com/wmyskxz/MoreThanJava
- 个人公众号 :wmyskxz,个人独立域名博客:wmyskxz.com,坚持原创输出,下方扫码关注,2020,与您共同成长!

非常感谢各位人才能 看到这里,如果觉得本篇文章写得不错,觉得 「我没有三颗心脏」有点东西 的话,求点赞,求关注,求分享,求留言!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!