Gary Marcus:因果熵理论的荒诞和认知科学带给AI的11个启示 | 文末赠书


本文内容节选自由湛庐文化出版的《如何创造可信的AI》一书,作者Gary Marcus(盖瑞·马库斯)。
马库斯是人工智能领域的专家,同时还是心理学和神经科学教授,在计算机科学、认知科学、语言学、人工智能等领域都练就了相当深厚的学术功底,并敢于挑战学术界的主流观点。
当整个人工智能学术界都在过分乐观地高歌猛进时,他不断撰文和发表演讲来指出以深度学习为代表的当下AI的弊端和局限性。本章内容为《从认知科学中获得的 11 个启示》,作者试图从认知科学出发,希望为AI未来具备人类智慧的宽度和鲁棒性带来启发。文章较长,但值得你一读。
想要了解这本书的更多干货知识,关注AI科技大本营并在评论区分享你对本文的学习心得,我们将从中选出2条优质评论,各送出《如何创造可信的AI》一本。活动截止时间为6月3日晚8点。
2013 年,在我们二人开始展开合作后不久,便遇到了一场让人血液沸腾的“盛况”。亚历山大 · 维斯纳 – 格罗斯(Alexander Wissner-Gross)和卡梅伦·弗里尔(Cameron Freer)这两位学者共同撰写了一篇论文,认为每一种类型的智慧都是一种被称为“因果熵力”(causal entropic forces)的通用的实体过程的表现。在一段视频中,维斯纳 – 格罗斯称,以这一思想为基础打造出来的系统,能“直立行走、使用工具、合作、玩游戏、进行有用的社交介绍、在全球部署舰队,甚至可以通过股票交易挣钱,而无须人类予以指导”。
论文发表之时,维斯纳 – 格罗斯成立了一家名为 Entropica 的创业公司。这家公司的野心极大,承诺在医疗、能源、智能、自动化国防、物流、交通、保险和金融领域推广“大范围应用”。媒体蜂拥而至。平日思想深刻的科学作家菲利普·鲍尔(Philip Ball)也一反常态,称维斯纳 – 格罗斯和他的联合作者已经“找到了让无生命物体采取行动,对自身未来进行预见的‘定律’。如果这些物体遵守这一定律,TED 为维斯纳 – 格罗斯提供了展示其“全新智慧方程式”的舞台。
但我们一个字也不信,而且直言不讳地表达了这一观点,在《纽约客》 的一篇在线文章中毫不留情地揭穿了维斯纳 – 格罗斯的物理和 AI 理论。“维 斯纳 – 格罗斯和弗里尔声称因果熵能解决大量问题,实际上就是在说,你 家电视机能遛狗。”6 事后想来,我们其实可以用更加含蓄的说法来表达同 样的意思。但五六年过去了,关于因果熵这个问题,我们再也没能找到一 篇新的论文,也没有见到维斯纳 – 格罗斯关于因果熵的数学取得任何进展。Entropica 这家创业公司也已经销声匿迹,而维斯纳 – 格罗斯本人则跑去忙 其他项目了。
像因果熵这样的思想,一直以来都对业余人士和科学家具有极大的吸引 力,因为这类思想会让我们联想到物理学中的优雅、数学性和可预测性。媒 体也爱极了因果熵这样的思想,因为听起来就像是经典的“大概念”,是可 能改变整个世界的强大宣言,并且以简单便捷的形象示人,是针对真正复杂 问题的潜在解决方案。谁不想成为下一个相对论的首发记者呢?
在不到一个世纪之前,同样的事情也在心理学领域发生过。当时,行为主义一时间流行起来。约翰斯·霍普金斯大学心理学家约翰·华生(John Watson)曾夸下海口,称仅通过精心控制孩子所处的环境,掌握好给予奖 励和惩罚的时间地点,就能将任何孩子养育成任何样子。这背后的假定是, 有机体可能去做的事情是关于其历史的简单明了的数学函数。因为某个行为 得到的奖励越多,你继续采取这个行为的可能性就越大;因为某个行为受到 的惩罚越多,你继续采取这个行为的可能性就越小。
到了 20 世纪 50 年代后期,绝大多数美国大学的心理学系都充斥着用小鼠和鸽子进行精密量化行 为实验的心理学家,他们想要通过这样的方法,用曲线图描述一切,并总结出精准的数学因果定律。
20 年之后,在诺姆 · 乔姆斯基(Noam Chomsky)的打击下,行为主义几乎完全销声匿迹。个中原因我们随后讨论。在充满局限性的实验中在小鼠身上起效的方法,在研究人类的过程中根本毫无用处。奖励和惩罚的确有 用,但还有太多其他能发挥影响力的事物。
用耶鲁大学认知科学家查兹·费尔斯通(Chaz Firestone)和布莱恩·肖 勒(Brian Scholl)的话说,问题就在于“心智发挥作用没有统一的方法,因为心智本身就不是单一的。心智拥有不同的部分,而不同的部分也以不同 的方法运转:看到某个色彩,其背后的工作原理和策划一场旅行是完全不同 的,而策划一场旅行背后的工作原理又和理解语句、移动肢体、记住事实、 体会情感是完全不同的”。没有哪个等式能涵盖住人类心智的多样性。
计算机不必用人类的方式去工作。计算机无须犯下影响人类思想的许多认知错误,比如证实偏见— 忽略掉与你先前所知理论相悖的数据,也无须反映出人类心智的许多局限性,比如人类在记忆超过 7 项内容的列表时会遇到困难。机器没有理由用人类容易出错的方式来进行数学运算。人类在许多方面都并不完美,机器无须继承同样的缺憾。而人类心智在阅读和灵活 思考方面远超机器,我们仍需深入了解人类心智在这方面的工作原理。
在此,我们提出从认知科学— 心理学、语言学和哲学中提炼出来的11 个启示。如果 AI 有朝一日能具备人类智慧的宽度和鲁棒性,那么我们认为这 11 个启示在 AI 的发展过程中有着至关重要的意义。

没有银弹
维斯纳 – 格罗斯和弗里尔的那篇论文,我们一看便知其内容言过其实(编者注:《没有银弹》(No Silver Bullet)是软件工程领域的一篇经典论文,强调由于软件的复杂性本 质,没有任何单一技术突破可以让软件工程效率获得数量级的提升)。
行为主义也是一样,总想着大包大揽。为了达到自身的目的,有点灵活 过度。仅凭动物的奖励行为历史,就可以对任何真实或想象中的行为进行解 释,如果动物做了意想不到的事情,那就转而去强调历史中的另一个方面。不存在真实而有效的预测方法,只有许多在事情发生之后对其进行“解释” 的工具。
最后,行为主义实际上只给出了一个靠谱的说法,但这个说法又没 什么实际应用价值。这个说法就是,包括人类在内的动物喜欢去做那些能得 到奖励的事情。这一点儿都没错,在其他因素相同的情况下,人们会选择能 得到更大奖励的那个选项。但这个说法无法帮我们解释人们怎么理解电影中 的对话,怎么搞明白安装宜家书架时凸轮锁的使用方法。奖励的确是整个体 系之中的一部分,但并非体系本身。维斯纳 – 格罗斯只是把奖励这个概念重 新包装了一遍,用他的话说,有机体如果抵抗宇宙的混乱(熵),就会获得 奖励。我们谁也不想化为尘埃,我们都会抵抗混乱,但这并不能解释人类是 如何做出个体选择的。
在我们看来,深度学习也落入了“寻找银弹”的陷阱,用充满“残差 项”和“损失函数”等术语的全新数学方法来分析世界,依然局限于“奖励 最大化”的角度,而不去思考,若想获得对世界的“深度理解”,整个体系 中还需要引入哪些东西。
神经科学研究让我们懂得,大脑是极为复杂的,常常被人们称作宇宙中 已知的最复杂的系统。这样的说法很有道理。人类大脑平均拥有成百上千种不同类别的约 860 亿个神经元,数万亿个突触,每个突触中有数百种不同的蛋白质。
每一个层级都包含巨大的复杂性。同时,还有 150 多个可识别的不同脑区,以及脑区之间大量错综复杂的连接网。正如神经科学先驱圣地亚哥·拉蒙 – 卡哈尔(Santiago Ramón y Cajal)在 1906 年诺贝尔 奖获奖感言中所说:“可惜的是,大自然似乎并没有意识到我们在智力需求 上对便利和统一的向往,经常在复杂和多样性中寻找
真正拥有智慧和复杂性的系统,很可能就像大脑一样充满复杂性。任何 一个提出将智慧凝练成为单一原则的理论,或是简化成为单一“终极算法” 的理论,都将误入歧途。

认知大量利用内部表征
对行为主义一击致命的,是 1959 年乔姆斯基写的一篇书评。斯基的攻击目标是“语言行为”。当年在全世界占据领导地位的心理学家B.F. 斯金纳(B.F. Skinner)曾试图用语言行为理论来解释人类的语言。
乔姆斯基的批判核心是围绕着这样一个问题展开的:人类语言是否可以 严格地仅从个体的外部环境中所发生历史的角度去理解。所谓外部环境,指 的是人们说了什么,他们得到了什么样的回应。换句话说,理解个体内部的 心理结构是否重要。乔姆斯基在他的结语中,着重强调了这样一个观点“:我 们将一个新事物识别为一个句子,并不是因为它以简单的形式与我们所熟悉 的某个事物相匹配,而是因为它是由语法生成的,而每个人都以某种方式、 某种形式将语法内在化了。”
乔姆斯基认为,只有理解了这种内在的语法,我们才有希望了解孩子 是如何学习语言的,仅仅靠刺激和响应的历史,永远不会让我们达到这个目标。
在行为主义应声陨落时,取而代之的是一个全新的领域— 认知心理 学。行为主义曾试图完全根据外部奖励历史来对行为进行解释(刺激和响 应,可能会让读者想起深度学习在当下应用中非常流行的“监督学习”),而 认知心理学则主要关注内部表征,如信念、欲望和目标。
本书中,我们一次又一次地看到,机器学习,尤其是神经网络,试图以 过少的表征来搞定一切,这会导致什么样的结果。从严格的技术意义上讲, 神经网络也具有表征,比如表示输入、输出和隐藏单元的向量,但几乎完全 不具备更加丰富的内容。例如,没有任何直接的方法来表征认知心理学家 所谓的命题(proposition),这些命题用以描述实体之间的关系。例如,若 要在经典人工智能系统中表示美国总统约翰 · 肯尼迪 1963 年著名的柏林之 行— 当时他说了一句“我是柏林人”,可以加上一组命题,例如“是...... 的一部分”(柏林,德国)和“拜访”(肯尼迪,柏林,1963 年 6 月)。在经 典人工智能中,知识完全是由这类表征的积累所组成的,而推理则是建立在 此基础之上的。以此为基础,推断出肯尼迪访问德国,就是轻而易举的了。
深度学习试图用一堆向量来模糊处理这个问题,这些向量会粗略捕捉一 些信息,但永远不会直接表示出类似“拜访”(肯尼迪,柏林,1963 年 6 月) 这样的命题。赶上好时候,深度学习中常见的那种变通方法或许可以正确推 断出肯尼迪访问过德国,但却不具备可靠性。遇上运气不好的时候,纯粹的 深度学习就会犯糊涂,甚至推断肯尼迪访问过东德(这在 1963 年是完全不 可能的),或者他的兄弟罗伯特访问过波恩,因为所有这些可能性都在所谓 的向量空间附近。你不能指望通过深度学习来进行推理和抽象思考,因为它 一开始就不是为了表征精确的事实知识而存在的。
如果事实本身模糊不清,得到正确的推理就会难于上青天。外显表征的 缺失,也在 DeepMind 的雅达利游戏系统中造成了类似的问题。DeepMind的雅达利游戏系统之所以在《打砖块》这类游戏的场景发生稍许变化时便会 崩溃,原因就在于它实际上根本不表征挡板、球和墙壁等抽象概念。
没有这样的表征,就不可能有认知模型。没有丰富的认知模型,就不可 能有鲁棒性。你所能拥有的只是大量的数据,然后指望着新事物不会与之前 的事物有太大的出入。当这个希望破灭时,整个体系便崩溃了。
在为复杂问题构建有效系统时,丰富的表征通常是必不可少的。DeepMind在开发以人类(或超人)水平下围棋的 AlphaGo 系统时,就放弃了先前雅达利游戏系统所采用的“仅从像素学习”的方法,以围棋棋盘和围棋规则的详细表征为起步,一直用手工的机制来寻找走棋策略的树形图和各种对抗手段。正如布朗大学机器学习专家斯图尔特·杰曼(Stuart Geman)所言:“神经建模的根本挑战在于表征,而不是学习本身。”

抽象和概括在认知中发挥着至关重要的作用
我们的认知大部分是相当抽象的。例如,“X 是 Y 的姐妹”可用来形容 许多不同的人之间的关系:玛利亚·奥巴马是萨沙·奥巴马的姐妹,安妮公 主是查尔斯王子的姐妹,等等。我们不仅知道哪些具体的人是姐妹,还知道 姐妹的一般意义,并能把这种知识用在个体身上。比如,我们知道,如果 两个人有相同的父母,他们就是兄弟姐妹的关系。如果我们知道劳拉 · 英格 斯 · 怀德是查尔斯 · 英格斯和卡罗琳 · 英格斯的女儿,还发现玛丽 · 英格斯也 是他们的女儿,那么我们就可以推断,玛丽和劳拉是姐妹,我们也可以推 断:玛丽和劳拉很可能非常熟识,因为绝大多数人都和他们的兄弟姐妹一起 生活过;两人之间还可能有些相像,还有一些共同的基因特征;等等。
认知模型和常识的基础表征都建立在这些抽象关系的丰富集合之上, 以复杂的结构组合在一起。人类可以对任何东西进行抽象,时间(“晚上10 : 35”)、空间(“北极”)、特殊事件(“亚伯拉罕 · 林肯被暗杀”)、社会政治 组织(“美国国务院”“暗网”)、特征(“美”“疲劳”)、关系(“姐妹”“棋局 上击败”)、理论(“马克思主义”)、理论构造(“重力”“语法”)等,并将这 些东西用在句子、解释、比较或故事叙述之中,对极其复杂的情况剥丝抽茧, 得到最基础的要素,从而令人类心智获得对世界进行一般性推理的能力。
在撰写这本书的时候,我们在马库斯家里进行了下面这一段对话。当时,马库斯的儿子亚历山大 5 岁半:
亚历山大:“及胸的水深”是啥意思?
妈妈:及胸就是说水到了你胸口的位置。
爸爸:每个人都不一样。相对我而言,及胸的水深就比相对你而言的要高一些。亚历山大:你的及胸水深,就是我的及头水深。
基于少量输入对新概念进行创造和扩展,同时进行概括,这种灵活性才 是人工智能应该努力获取的。

认知系统是高度结构化的
在《思考,快与慢》(Thinking,Fast and slow)中,丹尼尔·卡尼曼将 人类的认知过程分为两类:系统 1 和系统 2。系统 1,也就是快系统的过程, 执行得很快,通常是自动进行的。人类的大脑会直接去做,你根本感觉不出 来自己是怎么做到的。当你看外面的世界时,你立刻就能理解面前的景象; 当你听到母语的讲话时,马上就能理解对方在说什么。你无法控制这个过程, 你也不知道自己的大脑是如何运作的。事实上,你根本意识不到大脑在工作。系统 2,也就是慢系统的过程,需要有意识的、按部就班的思考。当系统 2被调用时,你会有一种思考的意识:例如试图找到谜语的答案,算出数学题的解,或者慢慢阅读一门你并不十分熟悉的外语,必须频繁查阅生词。
关于这两类系统,我们觉得用“本能反射”和“深思熟虑”这两个说法更加恰当,因为这样说更便于记忆,但无论冠以怎样的称呼,人类在面对不同问题时都会调用不同的认知能力,这一点毋庸置疑。甚至认为,我们应该将人类认知视为一个“心智社会”,其中有数十到数百种不同的“智能体”(agent),每种智能体都专门执行不同类型的任务。例如,喝茶需要依靠抓握智能体、平衡智能体、口渴智能体和一系列运动智能体之间的互动。霍华德·加德纳(Howard Gardner)的多元智能理论,罗伯特·斯滕伯格(Robert Sternberg)的智力三段论以及进化和发展心理学中的许多研究,都指向了同一个广阔的方向:心智并非一件事物,而是由许多东西所组成的。
神经科学则描绘出一幅更为复杂的图景。为进行任何一种计算,大脑中成百上千个不同区域以不同的模式联合在一起,每个区域都有自己独特的功能:“平时人们只调用大脑的 10 %”这样的说法是不正确的。事实情况是,大脑活动需要消耗巨大的新陈代谢成本,因此我们几乎不可能同时调用整个大脑。我们所做的每件事都需要调用大脑资源中的不同子集,在任一给定时刻,总有一些大脑区域是空闲的,而另一些是活跃的。枕叶皮层在视觉方 面很活跃,小脑在运动协调方面很活跃,以此类推。大脑是一个高度结构化 的装置,而我们的大部分智力能力源自在正确的时间调用了正确的神经工 具。我们可以预期,真正的人工智能很可能也是高度结构化的,在应对给定 的认知挑战时,其大部分能力也将源自在正确的时间以正确的方式对这种结构进行利用。
具有讽刺意味的是,当前的趋势与这样的愿景几乎完全相反。现在的机器学习界偏向于利用尽可能少的内部结构形成单一同质机制的端到端模型。英伟达 2016 年推出的驾驶模型就是一个例子,该模式摒弃了感知、预测和决策等经典的模块划分,而是使用了单一的、相对统一的神经网络,避开了通常情况下的内部工作分工,偏重于学习在输入(像素)和一组输出(转向和加速的指令)之间的更为直接的关联。这类系统的支持者,指出了“联合”训练整个系统相较于分别训练一堆模块(感知、预测等)的优势。
在某种程度上,这样的系统从概念上来看更简单,用不着为感知、预测 等分别设计单独的算法。而且,初看起来,该模型大体上效果还算理想,有 一部令人印象深刻的视频似乎也证明了这一点。那么,既然用一个庞大的网 络和正确的训练集就能简单易行地达到目标,为什么还要将感知、决策和预 测视为其中的独立模块,然后费心费力地建立混合系统呢?
问题就在于,这样的系统几乎不具备所需的灵活性。英伟达的系统一次 可以正常工作好几个小时,无须人类司机太多的干预,但无法像 Waymo 的 模块化系统那样正常工作数千个小时。Waymo 的系统可以从 A 点导航到 B 点, 途中对诸如更换行车道之类的事情进行处理,但英伟达的系统只能始终走在 一条车道上,虽说走直道的能力很重要,但这只是驾驶过程中的一小部分而 已。(此类端到端系统也更难调试,我们稍后将对此进行讨论。)
在关键的应用场景中,最优秀的 AI 研究人员致力于解决复杂问题时, 常常会使用混合系统,我们预期,这样的情况在未来会越来越多。举例来 说,DeepMind 能够在某种程度上避开混合系统来解决雅达利游戏的问题, 从像素到游戏分数再到操纵杆都进行端到端训练,却不能用类似的方法来下围棋,因为围棋在许多方面都比 20 世纪七八十年代的低分辨率雅达利游戏更为复杂。比如,围棋中有更多可能存在的棋局,每一步行动都可能带来更复杂的结果。纯端到端系统,再见啦;混合系统,你好啊。
在围棋中获得胜利需要将深度学习和蒙特卡罗树搜索(Monte Carlo Tree Search)两种理念融合为一体。蒙特卡罗树搜索是从包含棋局各种可能的树形 分支中抽取可能性的技术。蒙特卡罗树搜索本身也是两种思想的混合体,而 这两种思想都可以追溯到 20 世纪 50 年代:游戏树搜索是一种教科书式的人 工智能技术,用以预测玩家未来可能采取的行动;蒙特卡罗搜索则是运行多 个随机模拟并统计结果的常见方法。无论是深度学习还是蒙特卡罗树搜索, 哪个技术单独拿出来用都不可能造就世界围棋冠军。从中我们发现,AI 和大脑 一样,必须要有结构,利用不同的工具来解决复杂问题的不同方面。

即便是看似简单的认知,有时也需要多种工具
人们发现,即使在极为精细的颗粒尺度上,认知机制往往也并非单一机 制,而是由许多机制组成的。
以动词及其过去时形式为例,这是一个看似普通的系统,史蒂芬 · 平 克曾将其称为语言学中的果蝇,因为这是一个简单的“模型有机体”,可以让我们从中学到很多东西。在英语和许多其他语言中,一些动词利用 简 单 的 规 则 来 构 成 过 去 时, 如 walk–walked、talk–talked、perambulate–perambulated,等等;还有一些动词的过去时不遵守规则,如 sing–sang、ring–rang、bring–brought、go–went,等等。马库斯在跟随平克读博士时,研究重点就是儿童的过度规则化错误,在这种错误中,不规则动词被孩子们当作规则动词来处理,例如将 broke 说成 breaked,将 went 说成 goed。数据分析的基础上,马库斯和平克提出了混合模型理论。该理论指出了微观 层面上的一点点小结构:规则动词利用规则泛化来改变时态,就像计算机程 序和经典 AI 中一样,而不规则动词通过联想网络来改变时态,这基本相当于 深度学习的前身。这两种不同的系统共存互补:非规则性需要利用记忆(内 存)能力,而规则性即使在几乎没有直接相关数据可用的情况下也能进行泛化。
同样,大脑也利用几种不同的模式来处理概念,利用定义,利用典型特 征,或利用关键示例。我们经常会同时关注某个类别的特征是什么,以及为 了令其满足某种形式的标准,必须符合什么条件。蒂娜 · 特纳奶奶穿着超短 裙翩翩起舞。她可能看起来不像一位典型的老奶奶,但她能很好地满足关系 上的定义:她有孩子,而且她的孩子也有孩子。
AI 面临的一个关键挑战,就是在捕捉抽象事实的机制(绝大多数哺乳动 物是胎生)和处理这个世界不可避免的异常情况的机制(鸭嘴兽这种哺乳动 物会产卵)之间,寻求相对的平衡。通用人工智能既需要能识别图像的深度 学习机制,也需要能进行推理和概括的机制,这种机制更接近于经典人工智 能的机制以及规则和抽象的世界。
杰米斯 · 哈萨比斯最近讲道:“真正的智能远远不只是深度学习所擅长 的感知分类,我们必须对其进行重新组合,形成更高级的思考和符号推理, 也就是 20 世纪 80 年代经典人工智能试图解决的那些问题。”33 要获得适用 范围更广的 AI,我们必须将许多不同的工具组织在一起,有些是老旧的,有些是崭新的,还有一些是我们尚未发现的。

人类思想和语言是由成分组成的
在乔姆斯基看来,语言的本质,用更早期的一位语言学家威廉 · 冯 · 洪堡(Wilhelm von Humboldt)的话来说,就是“有限方法的无限使用”。借有限的大脑和有限的语言数据,我们创造出了一种语法,能让我们说出并 理解无限的句子,在许多情况下,我们可以用更小的成分构造出更大的句 子,比如用单词和短语组成上面这句话。如果我们说,“水手爱上了那个女 孩”,那么我们就可以将这句话作为组成要素,用在更大的句子之中,“玛丽 亚想象水手爱上了那个女孩”,而这个更大的句子还可以作为组成要素,用 在还要大的句子之中“克里斯写了一篇关于玛丽亚想象水手爱上了那个女孩 的文章”,以这样的方式接着类推,每一句话我们都可以轻松理解。
与之相对的,是神经网络先驱学者杰弗里·欣顿。欣顿在其研究领域中 的地位,和乔姆斯基在语言学领域的地位一样,他们都是高高在上的领导者。最近,欣顿一直在为他提出的“思维向量”而发声。向量就是一串数 字,比如 [ 40 . 7128° N, 74 . 0060° W],这是纽约市的经纬度,或者 [ 52419,663268,......24230,97914 ],这是按字母顺序排列的美国各州的平方英 里a 面积。在深度学习中,每个输入和输出都可以被描述为一个向量,网络 中的每个“神经元”都为相关向量贡献一个数字。由此,许多年以来,机器 学习领域的研究人员一直试图将单词以向量的形式进行编码,认为任何两 个在意义上相似的单词都应该使用相似的向量编码。如果“猫”被编码为[0,1,–0.3,0.3],那么“狗”可能就会被编码为 [0,1,–0.35,0.25]。伊利亚·苏茨科弗和托马斯·米科洛弗(Tomas Mikolov)当年在谷歌时,开 发了一门叫作 Word 2 Vec 的技术,允许计算机高效、迅速地以词汇附近经常出现的文本为基础,给出这类词汇的向量,其中每一个词汇的向量都由数百个真实的数字构成 。
在某些情况下,这种方法还不错。以“萨克斯”这个词为例。从大量英语文本资料之中,我们发现,萨克斯这个单词常常出现在“演奏”和“音乐”等动词,以及约翰·科尔特兰(John Coltrane)和凯丽·金(Kenny G)等人名附近。大规模数据库中,萨克斯的统计数据与小号和单簧管的统计数据接近,而与电梯和保险的统计数据相去甚远。搜索引擎可以使用这种技术或是此技术的改编版来识别同义词。得益于这些技术,亚马逊的产品搜索也变得更加精准。
然而,Word 2 Vec 真正出名的地方,在于人们发现这门技术似乎可以用在语言类比上,比如“男人对女人就像国王对____一样”。如果你把代表国王和女人的数字加起来,减去代表男人的数字,再去寻找最近的向量,很快就得到了答案— 王后,根本不需要任何关于国王是什么或女人是什么 的明确表征。b 传统人工智能研究人员花费数年时间试图定义这些概念,而Word 2 Vec 则貌似解决了这个棘手的难题。
在这些结论的基础之上,欣顿尝试着将这一观点进行泛化。与其用复杂 的树形图来表征句子和思想,不如用向量来表征思想,因为复杂的树形图与 神经网络之间的互动并不理想。欣顿在接受《卫报》采访时表示 :“如果用巴 黎的向量减去法国的向量,再加上意大利,就能得到罗马。非常了不起。”
欣顿指出,类似的技术被谷歌所采用,并体现在了谷歌最近在机器翻译方面 取得的进展之中。那么,为什么不以这种方式来表征所有的思想呢?
因为句子和单词不同。我们不能通过单词在各类情况下的用法来推测其 意思。例如猫的意思,至少与我们听说过的所有“猫”的用法的平均情况有 些许相似,或(从技术角度讲)像是深度学习系统用于表征的矢量空间中的 一堆点。但每一个句子都是不同的:John is easy to please ( 约翰很好哄 ) 和John is eager to please(约翰迫不及待的想要取悦别人)并不是完全相似的, 虽然两句话中的字母乍看去并没有多大区别。John is easy to please 和 John is not easy to please 的意思则完全不同。在句子中多加一个单词,就能将句 子的整个意思全部改变。
这些观点和观点之间微妙的关系太复杂了,无法通过简单地将表面上相 似的句子组合在一起来捕捉。我们可以把“桌子(table)上的书”和“书上 的表格(table)”区分开来,也可以将这两句话和“不在桌子上的书”区分 开来,还能将上面每一句话和下面这段话区分开来:“杰弗里知道弗雷德根 本不在乎桌子上的书,但是他非常关注那个非常特别的大鱼雕塑,现在,雕 塑上摇摇欲坠地摆着一个桌面,而且这个桌面还有些向右倾斜,随时都可能 翻倒。”这些句子可以表现为无数种形式,每句话都有不同的含义,而这些 句子所体现的整体思想又与句中各部分的统计平均值截然不同。
恰恰是因为这个原因,语言学家通常用树形分支图来表征语言(通常将 根部绘于顶端):
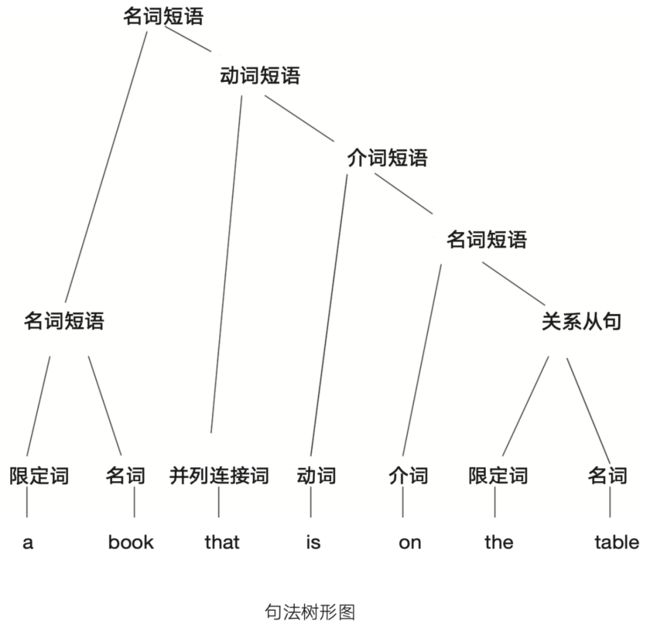
在这个框架中,句子中的每个成分都有自己的位置。我们很容易将不 同的句子区分开来,并确定句中元素之间的关系,就算两个句子共享大部分 或全部单词也没问题。深度学习在没有这种高度结构化句子表征的情况下工 作,往往会在处理细微差别时遇到问题。
例如,情绪分析器是利用深度学习实现的系统,将句子语气分类为积 极或消极。每个句子都被转换成一个向量。研究人员的想法是将积极的句子 (“好喜欢 !”)由一组聚为一处的向量表示,消极的句子(“好讨厌 !”)由另 一组聚于另一处的向量表示。每当出现一个新句子时,简单来说,系统只需测试这个句子是更接近于正向量集还是负向量集。
许多输入的句子语气是很明显的,也被正确地分了类,但句子中的细 微差别往往会随之消失。这样的系统不能区分“我在心生厌恶之前还是很 感兴趣的”(关于电影情节急转直下的负面评论),和“我在感兴趣之前还 是很厌恶的”(关于电影的一个更为积极的评价,说的是影片开头没什么意 思,随着情节的发展逐渐开始扣人心弦),因为这样的系统不会分析句子的 结构,不会考虑句子成分之间的关系,也不明白句子的意思来源于句子的成分。
这个例子告诉我们:统计数字经常能近似地表示意义,但永远不可能抓 住真正的意思。如果不能精准地捕捉单个单词的意义,就更不能准确地捕捉复杂的思想或描述它们的句子。正如得克萨斯大学奥斯汀分校计算语言学家雷·穆尼(Ray Mooney)用通俗语言说出的大道理:“不可能把整句的意思全部塞进一个向量里 !” 这样的要求有点太过了。

对世界的鲁棒理解,既需要自上向下的信息,也需要自下而上的信息
看一看这幅图片。这是个字母,还是个数字?

字母 B 还是数字 13 ?很明显,这幅图片既可以是字母,也可以是数字,具体取决于它所在的上下文。

认知心理学家将知识分为两类:自下而上的信息,是直接来自我们感 官的信息;还有自上而下的知识,是我们对世界的先验知识 , 例如 , 字母 和数字是两个不同的类别,单词和数字是由来自这些类别之中的元素所组 成的,等等。这种模棱两可的 B/ 13 图像,在不同的上下文中会呈现出不 同的面貌,因为我们会尝试着将落在视网膜上的光线与合乎逻辑的世界相 结合。
从心理学教科书中,我们会看到很多例子。比如,在一个经典实验中, 研究人员要求人们看这样的照片,先将图片与特定短语相对应,再将图片记在脑海中,比如最底下那幅图对应的特定短语是太阳或船舵,最上面那幅图对应的特定短语是窗中的帘子或矩形中的钻石。
人们如何对这些图片进行重建,很大程度上取决于他们得到的标签:

我们最喜欢的关于上下文感知重要性的演示,源自麻省理工学院安东尼奥·托拉尔瓦(Antonio Torralba)的实验室。
演示中有一幅图片,图中湖泊涟漪的形状有些像汽车,其相似程度足以在视觉系统中蒙混过关。如果你将 图片放大,仔细观察涟漪的细节,确实会发现斑驳的光点看上去像汽车,但 不会有人真的认为这是一辆汽车,因为我们知道汽车不可能在
再举一个例子,看看我们从茱莉亚·蔡尔德(Julia Child)家的厨房图片 中提取的细节。

你能认出下面这些图中的局部吗?当然没问题。左边的图片是厨房的桌子,桌子旁边放着两把椅子(以及远处第三把椅子的顶部,在图片中是几乎看不出来的边角),桌子上面摆放着一个餐垫,餐垫上摆放着一个餐盘。右边的图片就是桌子左边的椅子。

但仅仅凭借桌子和椅子的像素,并不能告诉我们这些内容。如果我们用亚马逊的照片检测软件 Rekognition,软件会将左边的照片标注为“胶合板”,置信度为 65.5 %,将右边的照片标注为“土路”或“砾石”,置信度为 51.1 %。在没有上下文的情况下,像素本身并没有什么意义。
同样的道理也适用于我们对语言的理解。上下文可发挥作用的一个领 域,就是前面提到过的歧义的消除。前几天,我俩中的一人在乡间小路上看 到写着“free horse manure”(免费马粪)的标牌,从逻辑上讲,这个说法 可能代表对于“free”(释放)的呼吁,其语法与“释放纳尔逊 · 曼德拉”(Free Nelson Mandela)相同,也可能是主人将不再需要的马粪免费(free)赠予 他人。我们很容易就能分辨出是哪一种,因为马粪并不渴望自由。
对于非文字语言的理解而言,关于世界的知识也是至关重要的。当一位 餐厅服务员对另一位服务员说“烤牛肉想要咖啡”时,没人会以为有个烤牛 肉三明治突然感觉口渴。我们推断这句话的意思是,点烤牛肉的人想喝杯饮 料。关于这个世界的了解会让我们知道,三明治本身并没有任何信念或欲望。
用语言学的专业术语来说,语言往往是“部分指定的”(underspecified), 也就是说,我们不会将想要表达的意思全部说出来,相反,我们会将大部分意思融入上下文,因为若要将所有内容说得一清二楚,永远也说不完。
自上而下的知识也会影响我们的道德判断。比如,大多数人认为杀戮 是错误的,而许多人会将战争、自卫和复仇之中的残杀视为特例。如果我 凭空说出邓坚强杀死了唐坚毅,你会认为这种杀戮行为是错的。但是,如果你在一部好莱坞电影中看到邓坚强杀死唐坚毅的情节,而在此之前唐坚 毅先残暴地杀害了邓坚强的家人,那么当邓坚强扣动扳机进行报复的那一 刻,你很可能会激动得欢呼雀跃。偷窃是不对的,但罗宾汉是个很酷的角 色。我们理解事物的方式,很少是孤立地使用自下而上的数据,比如谋杀 或盗窃的发生,而是将这些数据与更抽象、更高层次的原则相结合。找到 一种方法将自下而上和自上而下两者整合为一体,是人工智能的当务之急, 却常常被人忽视。

概念嵌于理论之中
从维基百科来看,“quarter”(在此作为美国货币的单位)是“一枚价值25 美分的美国硬币,直径大约 1 英寸 a”,“比萨”是“源自意大利的美食”。绝大多数比萨是圆形,少数是矩形,还有一些不太常见的是椭圆形或其他形状。这些圆形比萨的直径一般在 6 英寸到 18 英寸之间。然而,正如西北大学认知心理学家兰斯·里普斯(Lance Rips)曾指出的一样,我们很容易想象出一个直径正好相当于一枚 25 美分硬币那么大的比萨,说不定还很想品尝这样一道小巧的开胃菜。另一方面,你永远不会接受一个比标准 25 美分硬币面积大 50 % 的硬币复制品作为合法货币,而是会将这个假硬币认作质量低劣的仿冒品而不予理睬。
其中一部分原因,在于你对金钱和食物有着不同的直觉理论。你的货币 理论告诉你,我们愿意用有形的有价值的东西,如食物,来交换表示抽象价 值的标记物,如硬币和纸币,但交换依赖于标记物的合法性。这种合法性部 分取决于标记物由特殊的权威机构,比如铸币厂所发行,而我们评估这种合 法性的方式,部分在于我们期望标记物能满足确切的要求。由此可见,25美分的硬币不可能与比萨的大小一样。

心理学家和哲学家一度试图严格按照“必要和充分”条件来定义概念: 正方形必须有 4 条等边,两边夹角成 90 度;点与点之间的最短距离是直线。任何符合标准的都是合格的,不符合标准的都是不合格的;如果任意两条边不相等,就不是正方形。但学者们在定义不那么数学化的概念时,就遇到了麻烦。很难给一只鸟火一把椅子定出确定的标准。
另一种定义概念的方法,就是参照特定的示例,要么是中心示例,比如知更鸟是典型的鸟类,要么是一组示例,比如你见过的所有鸟类。自20 世纪 80 年代以来,许多人都赞同“概念嵌于理论之中”的观点。我们 也是这一观点的忠实拥趸。我们的大脑能很好地跟进单个的示例和原型, 但我们也能根据它们所嵌入的理论来推断出概念,比如比萨和 25 美分硬币 的例子。再举一个例子,我们可以理解一个生命体拥有独立于其全部感知属性的“隐藏的本质”。
在一个经典实验中,耶鲁大学心理学家弗兰克·凯尔(Frank Keil)问孩 子们,如果给一只浣熊做整容手术,让它看起来和臭鼬一样,并在其身体中植入“超级臭”的东西,那么这只浣熊是否就变成了一只臭鼬。孩子们相 信,虽然这只浣熊有着不一样的感知外表和气味等功能特性,但浣熊仍然是 一只浣熊。这样的结论可能是孩子们的生物学理论使然,孩子们知道,真正 重要的是生物体内在的东西。一项重要的对照研究表明,孩子们并没有将同 样的理论扩展到人类制造的人工制品上,比如通过金属加工改造将咖啡壶变 成喂鸟器。
我们认为,嵌入在理论中的概念对有效学习至关重要。假设一位学龄前 儿童第一次看到鬣蜥的照片。从此之后,孩子们就能认出其他照片上的、视 频中的和现实生活中的鬣蜥,而且准确率相当高,很容易就能将鬣蜥与袋鼠 甚至其他蜥蜴区分开来。同样,孩子能够从关于动物的一般知识中推断出, 鬣蜥会吃东西,会呼吸,它们生下来很小,会长大,繁殖,然后死去,并意 识到可能有一群鬣蜥,它们看起来或多或少都有些相似,行为方式也相似。
没有哪个事实是一座孤岛。通用人工智能若想获得成功,就需要将获取到的事实嵌入到更加丰富的、能帮助将这些事实组织起来的高层级理论之中。

因果关系是理解世界的基础
图灵奖得主朱迪亚·珀尔(Judea Pearl)提出,对因果关系的丰富理解是人类认知中无处不在、不可或缺的一个方面。如果世界是简单的,我们 对其中的一切都有充分的了解,那么唯一需要的因果关系就只有在物理学里 面了。我们可以通过模拟来确定什么对什么产生了影响,比如,如果我施加 这么多微牛顿的力,接下来会发生什么?
但正如我们将要讨论的,这种细致的模拟往往并不现实可行。真实世界 中有太多的粒子,无法一一追踪,而且时间也不够。
为此,我们会使用近似法。虽然我们不知道确切原因,但我们知道事物 之间是因果相关的。我们服用阿司匹林,因为我们知道这种药物会让我们感 觉好一些,而不需要了解背后的生物化学原理。绝大多数成年人,就算并不 了解胚胎发育的确切机制,也知道性行为会导致婴儿的诞生,就算相关知识 并不全面,也能根据这些知识来采取行动。我们不是医生,也知道维生素 C可以预防坏血病,不是机械工程师,也知道踩下油门可以让汽车跑得更快。因果知识无处不在,是我们所做的许多事情的基础。
在劳伦斯· 卡斯丹(Lawrence Kasdan)的经典电影《大寒》(The Big Chill)中,杰夫·高布伦(Jeff Goldblum)饰演的角色开玩笑说,合理化思 考比性生活还重要(“你是否曾坚持过一周的时间,不去进行合理化思考?” 他问道)。而因果推理,甚至比合理化更重要;没有因果关系,我们就无法 对这个世界进行理解,连一个小时都坚持不下去。我们赞同珀尔的观点,即 因果推理在人工智能领域中的重要性几乎超越所有其他主题,然而目前却又 遭到业界的忽视。珀尔本人开发出了一种强大的数学理论,但关于如何从已 知的众多因果关系中汲取知识,尚待我们去探索。
这是个特别棘手的问题,因为摆在我们眼前的那条通往因果知识的道 路上布满了荆棘。我们所知的几乎所有原因都会导致相关性——当你踩下油 门踏板时,只要发动机还在运转,紧急刹车还没有启动,汽车确实会跑得更 快,但很多相关性实际上并不是因果关系。鸡鸣可以报晓,但人人都知道, 让雄鸡安静下来并不会阻止太阳的升起。气压计上的读数与气压密切相关, 但用手移动气压计指针,并不会改变真实的气压。
只要花点时间,就很容易找到各种纯属巧合的相关性,比如泰勒 · 维根 (Tyler Vigen)给出的这个例子:2000 年至 2009 年,人均奶酪消费量与床单缠结导致死亡人数之间的对比。

维根在读研究生的时候,编撰了一本名为《假性相关》(Spurious Correlations )的著作。同一时期,维根注意到,掉进池塘里淹死的人数与 尼古拉斯·凯奇(Nicholas Cage)出镜的影片数量存在紧密的相关性。这些 胡乱搭上关系的相关性是不存在的,其中并没有真正的因果关系,但是油门 踏板和汽车加速之间的关联则是因果关系的真实实例。有朝一日,若能让机器认识到这一点,将是一项重大成就。

我们针对逐个的人和事件进行跟进
日常生活中,我们会对各种各样的事物进行跟进了解,对其特征和历史进行把握。你的另一半以前当过记者,喜欢喝白兰地,不那么喜欢威士 忌。你的女儿以前特别害怕暴风雨,喜欢吃冰激凌,没那么喜欢吃曲奇饼。你车子的右后门被撞了个小坑,一年前你更换了车子的变速器。街角那家小 商店,以前卖的东西质量特别好,后来转手给新老板之后,东西的质量就一 天不如一天。我们对世界的体验,是由许多持续存在、不断变化的个体组成 的,而我们的许多知识,也是围绕着这些个体事物而建立起来的。不仅包括 汽车、人物和商店,还包括特定的实体,及其特定的历史和特征。
奇怪的是,这并非深度学习与生俱来的观点。深度学习以类别为重点,而不以个体为重点。通常情况下,深度学习善于归纳和概括:孩子都喜欢吃甜食,不那么喜欢吃蔬菜,汽车有四个轮子。这些事实,是深度学习系统善于发现和总结的,而对关于你的女儿和你的车子的特定事实,则没什么感觉。
当然,也存在例外情况。但如果我们深入观察,就会发现,那些例外 情况也证实了这个原则。举例来说,深度学习非常善于学习关于个体人物的 图片识别,比如,你可以训练深度学习以很高的准确率去识别德瑞克 · 基特(Derek Jeter)的图片。但是,这是因为系统认为“德瑞克·基特的图片”属 于同类图片之中的一个类别,而不是因为系统了解德瑞克 · 基特是一位运动 员,是一个人。学习识别德瑞克 · 基特等人物图片与学习识别诸如棒球运动 员等类别的深度学习机制,基本是相同的,都是图像的类别。训练深度学习 识别德瑞克 · 基特的图片,比让系统从多年的新闻报道中推断出此人从 1995年到 2014 年在洋基队担任游击手,要容易得多。
同样,我们可以让深度学习以一定的准确率在视频中对某个人进行跟 踪。但是对于深度学习来说,不过是将一个视频帧中的一块像素与下一个视 频帧中的另一块像素进行关联而已;系统并不了解像素究竟指代的是什么东西。系统不知道,当人物从视频帧中暂时消失,此人依然在别处存在。如果 系统看到一个人走进电话亭,过一会儿从里面走出来两个人,并不会觉得有 什么不妥。

复杂的认知生物体并非白板一块
1865 年,格雷戈尔· 孟德尔(Gregor Mendel)发现了遗传的核心,他 称之为因子,如今我们称之为基因。他当时不知道基因是由什么构成的。后 来,科学家们又花了将近 80 年的时间才找到答案。几十年间,许多科学家都 走上了一条死胡同,错误地认为孟德尔的基因是由蛋白质构成的,几乎没有 人想到,基因是由不起眼的核酸构成的。直到 1944 年,奥斯瓦尔德 · 埃弗里(Oswald Avery)才利用排除法,最终发现了 DNA 的重要作用。即使在那个时 候,人们也鲜有关注,因为当时科学界“对核酸并不感兴趣”。孟德尔本人的重要地位最初也被人忽视,一直到他提出的定律在 1900 年被人重新发现。
关于“先天”这个古老的话题,当代人工智能很可能也同样错失良机。面对自然界的诸多现象,这一话题常被表达成为“先天还是后天”。大脑有多 少结构是与生俱来的,又有多少是后天习得的?同样的问题也出现在人工智 能领域之中:所有东西都应该是预先内置的吗?还是应该通过学习而掌握?
认真思考过这一话题的人都会意识到,这是逻辑谬误中的假两难推理。从发展心理学(研究婴幼儿发展的学科)和发展神经科学(研究基因和大脑 发育之间关系的学科)等领域,我们得到了大量的生物学证据:先天和后 天合作发挥作用,而不是互为对立面。正如马库斯在其著作《心智的诞生》(The Birth of the Mind)中所讲到的一样,个体基因实际上是这一合作关系的杠杆。每个基因,都像是计算机程序中的“IF–THEN”语句。THEN 一 侧指明需要构建的特定蛋白质,但只在 IF 特定化学信号存在的情况下,该蛋白质才会构建出来,每个基因都有其自身独特的 IF 条件。这个结果,就像是富有适应性而经过高度压缩的一套计算机程序,由个体细胞在对其所在 环境进行响应的过程中自动执行。学习本身,也是基因的产品。
奇怪的是,机器学习领域的大多数研究人员似乎并不想要与生物领域的这一方面发生互动。a 关于机器学习的文章很少与发展心理学的大量文献有什么关联,就算有所关联,也只是提到让·皮亚杰(Jean Piaget)这位业界先驱,而他早在近 40 年前就离世了。举例来说,皮亚杰提出的问题“将物体藏起来之后,婴儿是否知道此物依然存在”55 如今看来依然一针见血,但他给出的答案,正如他提出的认识发展阶段理论和他对儿童发现事物年龄的猜测,其方法论的依据并没能经得起时间的考验,如今看来,这些都是过时的参考资料了。
我们很少能见到机器学习的论文引用近 20 年来的发展心理学研究成果, 更是看不到机器学习论文引用遗传学或发展神经科学的内容。通常来看,机 器学习领域的人们会着重强调学习,但从不考虑先天知识。就好像是他们认 为,因为他们在研究学习,所以任何具有价值的事物都不可能是先天的。但 先天和后天并不构成如此的竞争模式,反之,你在起跑线上所拥有的越丰 富,你能学习的就越多。但是,深度学习还是被“白板”视角所主宰,完全 忽略掉任何形式的先天知识。
我们认为,未来的人们在回顾时会将这种对先天的忽视看作一次巨大的 疏忽。当然,我们并不否认从经验中进行学习的重要性,就算我们这些非常 重视先天知识的人也懂得学习的重要性。但是,像机器学习领域的研究人员 所做的那样,从空无一物的白板起步进行学习,会令这项任务的难度更加艰 巨。这就相当于只有后天没有先天,而最有效的解决方案,应该是将两者合二为一。
在生物界,生命体自出生之时就具备各自不同的先天能力,以及关于世 界的一些知识。据我们了解,山羊生下来就能识别出山峦(或陡坡与平面) 的作用,也对自己的身体有一定的了解,知道如何加以运用。
正如哈佛大学发展心理学家伊丽莎白·史培基(Elizabeth Spelke)提出的观点一样,人类很可能自出生之时便了解世界由持续的物体所构成,这些物体沿时空的连接通路行进,拥有对几何和数量的感知能力,以及直觉心理学的基础。或如康德在 200 年前从哲学角度出发的观点,若想正确地对世界加以理解,先天的“时空流形”是不可或缺的。
而且,语言之中的某些方面,很可能也部分地形成了先天的预连线。孩子或许天生就知道,周围的人们所发出的声音和做出的动作是在进行富有意义的沟通;59 而这种知识,与有关人类关系的其他先天基础知识(妈妈会照顾我等)相互联结。而且,人类语言的其他方面或许也是先天的,例如:将语言划分为句子和词汇;对语言发音特征的预期;语言所拥有的句法结构,以及句法结构与语义结构的关系。
相比之下,一位从白板起步的纯粹的学习者则将世界当作纯粹的视听流,就像一个 MPEG 4 文件一样。这位学习者需要对每一样事物进行学习, 就连反复出现的不同人物都要去学习。包括 DeepMind 在内的一部分研究者曾尝试着做过一些白板学习的事情,但结果远远不像利用同样的方法来下棋那样令人惊叹。
在机器学习领域内,许多人都认为,先天连线的做法就和作弊一样令人 不齿,预置的内容越少,解决方案就越牛。DeepMind 的许多早期工作,似 乎都受到这种思想的指引。玩雅达利游戏的系统,除了用于深度强化学习的 通用架构,以及代表操纵杆选项、屏幕像素和总分的特征之外,完全没有内 置内容,甚至连游戏规则本身,也必须通过经验和各种策略来获得。
在《自然》杂志后来发表的一篇论文中,DeepMind 宣称,他们已经“在没有人类知识的情况下”掌握了围棋。虽然 DeepMind 所使用的人类围棋知识的确比前辈要少,但“没有人类知识”这个说法还是夸大了事实:系统仍然在很大程度上依赖于人类在过去几十年间发现的让机器下围棋的方法,尤其是蒙特卡洛树搜索,之前讲到过这种方法。这种方法通过从具备不同 棋局可能性的树形图上随机抽样来实现,本质上与深度学习并没有什么关系。他们之前在雅达利游戏上所做的工作有所不同,雅达利的成果在业内已经得到了广泛讨论。人类知识与此无关的说法,根本不符合事实。
不仅如此,同样重要的是,这种说法本身也揭示了深度学习界的价值倾 向:尽力消除先验知识,而不是尝试利用这些知识。这就好像汽车制造商认 为重新发现圆形车轮是件很酷的事情,所以从一开始就无视过去两千年车辆 制造的丰富经验,对现成的车轮置之不理。
我们相信,人工智能要获得真正的进步,首先要搞清楚应该内置何种知 识和表征,并以此为起点来启动其他的能力。DeepMind 还内置了棋局规则和其他一些关于围棋的详细知识,这与他们之前在雅达利游戏上所做的工作有所不同,雅达利的成果在业内已经得到了广泛讨论。人类知识与此无关的说法,根本不符合事实。
不仅如此,同样重要的是,这种说法本身也揭示了深度学习界的价值倾 向:尽力消除先验知识,而不是尝试利用这些知识。这就好像汽车制造商认 为重新发现圆形车轮是件很酷的事情,所以从一开始就无视过去两千年车辆 制造的丰富经验,对现成的车轮置之不理。
我们相信,人工智能要获得真正的进步,首先要搞清楚应该内置何种知识和表征,并以此为起点来启动其他的能力。
我们整个行业,都需要学习如何利用对实体对象的核心理解来进一步了 解世界,在此基础之上构建起系统,而不是单纯凭借像素和行为之间的相关 性来学习一切,以此为系统的核心。我们所谓的“常识”,大部分是后天习 得的,比如钱包是用来装钱的、奶酪可以打成碎屑,但几乎所有这些常识, 都始于对时间、空间和因果关系的确定感知。所有这一切的基础,可能就是 表征抽象、组合性,以及持续存在一段时间(可以是几分钟,也可以是数十 年)的对象和人等个体实体的属性的内在机制。如果机器想要学习尚无法掌 握的东西,那么从一开始就需要拥有这样的基础。
为机器赋予常识
加州大学洛杉矶分校计算机科学项目主席阿德南· 德尔维希(AdnanDarwische)在最近的一份给人工智能行业的公开信中,呼吁对 AI 研究人员进行更加广泛的培训,提出“我们需要新一代的 AI 研究人员,能深谙行业之道,用更宽的视角去理解经典人工智能、机器学习和计算机科学,同时掌握人工智能的发展历史”。
我们在此观点之上进一步拓展,认为 AI 研究人员不仅需要借鉴计算机 科学领域的诸多成就(在如今大数据热潮之中,计算机科学的成果常常被人 遗忘),而且还要从心理学、语言学、神经科学等其他学科中汲取养料。这 些认知科学领域的发展历史和研究成果,能让我们了解到生物体应对“智 能”这个复杂挑战的整个过程:如果人工智能想要成为与自然智能有些许相似之处的事物,我们就要学习如何构建结构化的混合系统,将先天的知识和 能力融入进去,让它实现对知识的组合性表征,并对持续存在的个体进行跟 进,就像人类所做的一样。
一旦 AI 开始利用认知科学,从围绕大数据形成的范式上升成为围绕大 数据和抽象因果知识形成的范式,我们就将有能力解决“为机器赋予常识” 这个无比困难的挑战。

赠书活动
想要了解关于推荐系统的更多干货知识,关注AI科技大本营并在评论区分享你对本文的学习心得,我们将从中选出2条优质评论,各送出由湛庐文化出版的《如何创造可信的AI》一本。