BP算法 手写数字识别 py3 失败的记录
手写数字识别的python实现
周二的时候讲模式识别的杨老师在板书了很久的理论以后即兴布置了一项实践作业,手写数字图像的识别,恰好之前在看机器学习和深度学习的书里也接触了一些相关东西,初步的想法是利用神经网络和BP算法进行图像的处理和相似度校正(也可以采用SVM或者K近邻算法,或者cnn神经网络等),误差损失函数为均方误差损失函数,数据则打算选用minist手写数据集。
当然,在正式进行python实现之前我们需要补充一些资料,并对相关原理进行简单的介绍。
参考材料:
CSDN博客 BP神经网络识别手写数字项目解析及代码
mnsit 手写数据集 python3.x的读入 以及利用softmax回归进行数字识别
KTWO博客 python神经网络识别手写数字实例(minist图片数据集)
机器学习 周志华 第五章 神经网络 5.1 神经元模型 5.2 感知机与多层网络 5.3 误差逆传播算法
深度学习 第六章 深度前馈网络 6.5反向传播和其他的微分算法
机器学习实战 第2章k-近邻算法 2.3 示例:手写识别系统
神经网络出现于20世纪40年代,最早的神经元模型为M_P神经元模型,随着感知机的提出,50年代也成为神经网络发展的第一个高潮期,但明斯基出版的感知机一书指出单层神经网络无法解决非线性问题(异或问题),使这一领域的研究转入低潮,哈佛大学的Paul Werbos在1974年发明的BP算法也因而没有受到重视,直到1984年UCSD的Rumelhart等人又重新发明了BP算法,掀起了神经网络的第二次高潮。
BP神经网络属于传统神经网络,与现在流行的cnn(卷积神经网络)、rnn(循环神经网络)等相比要简单一些。神经网络是一种模仿生物神经网络特征分布并进行信息处理的数学模型,传统的人工神经网络一般分为三层,输入层,隐含层和输出层,而根据隐含层的个数又可分为浅层学习(一般小于3层)和现在大热的深度学习(等于甚至远远超过3层)。
我们可以看一下比较典型的神经元模型和神经网络模型(图源来自网络)。
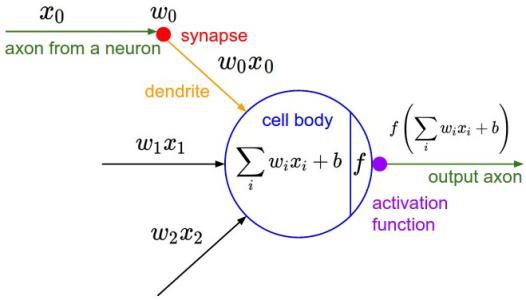
这是一个M-P神经元模型,在这个模型中神经元接收到来自多个(图中为3个)神经元传递过来的输入信号Xi,这些信号通过带权重Wi的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过激活函数处理以产生神经元的输出。
总输入值 ![]()
激活函数![]()
常用激活函数为 ![]()
S为总输入值,为对应第i个输入的权值,为第i个输入值。

这是一个简单的“双层神经网络”(尽管它有着三层),也叫做单层前馈网络(或称单隐层网络),每层神经元与下一层神经元全连接,神经元之间不存在同层连接和跨层连接。其中,输入层神经元接收外界输入,隐层与输出层对信号进行加工,最终结果由输出层神经元输出,即输入层仅接收输入,不进行函数处理,隐层与输入层包含功能单元。
反向传播(back propagation),即在神经网络中允许来自代价函数的信息通过网络向后流动(从子节点向父节点),以便计算梯度。下面是BP算法的数学推导。
关于BP算法的推导写的比较粗泛,推荐周志华老师的机器学习中关于BP算法的内容,思路比较清晰,深度学习中关于算法的推导只有算法的流程没有数学符号的表示看起来比较晦涩,更详细具体的理解则可以看参考资料中的博客。
假定总输出为O(O1,O2,...,On),输入X(X1,X2,...,Xn),隐含层输入Y(Y1,Y2,...,Yn)权重为(Wj1,Wj2,...,Wjk)(隐含层到输出层)和(Wi1,Wi2,...,Win)(输入层到隐含层),实际值与估计值之间的均方误差为E,则W是一个关于权重W(隐含层到输出层),V(输入层到隐含层)和输入X 的函数。要求W的修正量∆w,可得公式
![]()
其中E为输出量与估计量之间的均方误差,
![]()
传统BP神经网络通过均方误差衡量误差损失,现在则多采用交叉熵损失进行代替,使用交叉熵损失可以有效提升模型的性能。 假设输出层理想输出为D(d1,d2,...,dn)上式求增量公式中可得=![]()
由yj的定义输入 =![]()
又![]()
故而∆![]()
通常,我们写做![]() ,为步长,η也称为学习率,然后就可以迭代求出最接近的权重值。同理可求出V的权重,比较懒就不写出来了。还有衡量迭代停止的方法,即当均方误差趋于0时,迭代终止。
,为步长,η也称为学习率,然后就可以迭代求出最接近的权重值。同理可求出V的权重,比较懒就不写出来了。还有衡量迭代停止的方法,即当均方误差趋于0时,迭代终止。
这里还要多嘴一句神经元网络图像识别的原理(与卷积网络进行图像识别的方法有一些不同),就是如果有一张28*28(像素)的图片,需要将图片转化为一个二维的灰度值矩阵,再将每一行的值连接在一行组成一个1*256的行向量,作为输入,通过输入层的256个神经元输入,再通过隐藏层,隐藏层神经元数目在这里可以选择为64个,为什么是64个呢?现在神经网络中隐层节点数目与输入层节点之间的关系有很多种非权威的解释,一般是需要自己根据模型数据进行调参以后才能得到较准确地数据。也有一些常用的神经元数目经验选择的方法:
1)一般取(输入层个数+输出层个数)/2;
2)(输入层个数*输出层个数)^(1/2);
3)隐含层<输入层即可;
4)[(输入+1)/2 (输入-1)];
5)log(输入)
6)2*输入+1
最后的输出神经元选择10个,这是因为数字0-10共10个,期望的输出是,比如输入一张写着数字1的图像,在输出端得到的输出是{1 0 0 0 0 0 0 0 0 0},输入的图像为2时,输出{ 0 1 0 0 0 0 0 0 0 0},以此类推,实际上输出的未必就是刚好1和刚好0,经过调参和训练,基本是输出0.9多和正负的0.0多,不过也足够了,仅仅用判断最大值所在位置的方式就可以识别到图像上的数字(这里和卷积神经网络图像识别的方法不同,卷积神经网络是通过一个特征提取区域filter对二维灰度图像进行处理,然后透过卷积层进行层层过滤并最终得到相应的特征区域,里面还有一些小细节如为了防止图像边缘部分信息缺失的padding方法等,以后如果有机会可以再讨论一下)。
下面是代码部分,环境为pycharm python3,图片数据已经下载在桌面,路径为
测试集C:\Users\DELL\Desktop\testimage
训练集C:\Users\DELL\Desktop\trainimage
这里用的trainimage进行训练,图片大小均为28*28,数据是从参考资料中ktwo博主分享的百度云链接中得到,在此表示感谢。
首先,是对图像进行处理得到特征统计表,得到命名为getImageData.py的文件。
import numpy as np
from PIL import Image
from sklearn.externals import joblib
import os
"""定义一个类用来获取图片特征"""
class ImageData:
"""初始化获得图像"""
def __init__(self,image):
self.image=image
"""将图像化为二维数据"""
def point(self,z=80):
return self.image.point(lambda x 1. else if x>z 0.)
"""将二维数据转化为特征统计表的形式"""
def get_features(self, imArray, num):
# 拿到数组的高度和宽度
h, w = imArray.shape
data = []
for x in range(0, w / num):
offset_y = x * num
temp = []
for y in range(0, h / num):
offset_x = y * num
# 统计每个区域的1的值
temp.append(sum(sum(imArray[0 + offset_y:num + offset_y, 0 + offset_x:num + offset_x])))
data.append(temp)
return np.asarray(data)
def getData(self, num):
img = self.point()
# 将图片转换为数组形式,元素为其像素的亮度值
img_array = np.asarray(img)
# 得到网格特征统计图
features_array = self.get_features(img_array, num)
# print features_array
return features_array.reshape(features_array.shape[0] * features_array.shape[1])
然后是构建一个BP算法的神经网络。命名为BpNN.py
"""定义两个不同的激活函数tanh和sigmoid"""
import numpy as np
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x)
def logistic(x):
return 1 / (1 + np.exp(-x))
def logistic_derivative(x):
return logistic(x) * (1 - logistic(x))
"""定义一个类来进行BP算法"""
class NeuralNetwork:
#构造函数
def __init__(self, layers, activation='tanh'):
'''
:param layers: list类型,比如[2,2.1]代表输入层有两个神经元,隐藏层有两个,输出层有一个
:param activation: 激活函数
'''
self.layers = layers
#选择后面用到的激活函数
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
#定义网络的层数
self.num_layers = len(layers)
'''
生成除输入层外的每层中神经元的biase值,在(-1,-1)之间,每一层都是一行一维数组数据
randn函数执行一次生成x行y列的数据
'''
self.biases = [np.random.randn(x) for x in layers[1:]]
print ('偏向:',self.biases)
'''
随机生成每条连接线的权重,在(-1,1)之间
weights[i-1]代表第i层和第i-1层之间的权重,元素个数等于i层神经元个数
weights[i-1][0]表示第i层中第一个神经单元和第i-1层每个神经元的权重,元素个数等于i-1层神经元个数
'''
self.weights = [np.random.randn(y, x)
for x, y in zip(layers[:-1], layers[1:])]
print ('权重:',self.weights)
#训练模型,进行建模
def fit(self, X, y, learning_rate=0.2, epochs=1):
'''
:param self: 当前对象指针
:param X: 训练集
:param y: 训练标记
:param learning_rate: 学习率
:param epochs: 训练次数
:return: void
'''
for k in range(epochs):
#每次迭代都循环一次训练集
for i in range(len(X)):
#存储本次的输入和后几层的输出
activations = [X[i]]
#向前一层一层的走
for b, w in zip(self.biases, self.weights):
# print "w:",w
# print "activations[-1]:",activations[-1]
# print "b:", b
#计算激活函数的参数,计算公式:权重.dot(输入)+偏向
z = np.dot(w, activations[-1])+b
#计算输出值
output = self.activation(z)
#将本次输出放进输入列表,后面更新权重的时候备用
activations.append(output)
# print "计算结果",activations
#计算误差值
error = y[i]-activations[-1]
#print "实际y值:",y[i]
#print "预测值:",activations[-1]
# print "误差值",error
#计算输出层误差率
deltas = [error * self.activation_deriv(activations[-1])]
#循环计算隐藏层的误差率,从倒数第2层开始
for l in range(self.num_layers-2, 0, -1):
# print "第l层的权重",self.weights[l]
# print "l+1层的误差率",deltas[-1]
deltas.append(self.activation_deriv(activations[l]) * np.dot( deltas[-1],self.weights[l]))
#将各层误差率顺序颠倒,准备逐层更新权重和偏向
deltas.reverse()
# print "每层的误差率:",deltas
#更新权重和偏向
for j in range(self.num_layers-1):
#本层结点的输出值
layers = np.array(activations[j])
# print "本层输出:",layers
# print "错误率:",deltas[j]
# 权重的增长量,计算公式,增长量 = 学习率 * (错误率.dot(输出值))
delta = learning_rate * ((np.atleast_2d(deltas[j]).T).dot(np.atleast_2d(layers)))
#更新权重
self.weights[j] += delta
#print "本层偏向:",self.biases[j]
#偏向增加量,计算公式:学习率 * 错误率
delta = learning_rate * deltas[j]
#print np.atleast_2d(delta).T
#更新偏向
self.biases[j] += delta
#print self.weights
def predict(self, x):
'''
:param x: 测试集
:return: 各类型的预测值
'''
for b, w in zip(self.biases, self.weights):
# 计算权重相加再加上偏向的结果
z = np.dot(w, x) + b
# 计算输出值
x = self.activation(z)
return x
"""测试矩阵"""
nn = NeuralNetwork([2, 4, 3, 1], 'tanh')
# 训练集
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
# lanbel标记
y = np.array([0, 1, 1, 0])
# 建模
nn.fit(X, y, epochs=1000)
# 预测
for i in [[0, 0], [0, 1], [1, 0], [1, 1]]:
print(i, nn.predict(i))
偏置,权值以及测试矩阵输出如下(每次训练结果不相同,只取一次展示)
D:\Python\python.exe "C:/Users/DELL/PycharmProjects/untitled3/machine learning/BpNN.py"
偏向: [array([ 0.81341952, 0.74587856, 0.86215504, -0.55349183]), array([ 0.22901807, -0.07770371, 1.3076994 ]), array([-0.39075547])]
权重: [array([[ 0.34868473, 1.24480277],
[-0.05181289, -1.32704758],
[ 2.54196556, -1.18239785],
[ 1.06893951, 0.47298943]]), array([[-0.21838303, 1.24066113, 1.36329644, -0.58120532],
[ 0.36332816, -0.93562068, -0.44458885, -0.31798126],
[ 0.71686413, -0.14080825, -0.43187991, -0.48989009]]), array([[ 0.87268238, -0.13692022, -0.96503621]])]
[0, 0] [0.01024474]
[0, 1] [0.99824071]
[1, 0] [0.99771963]
[1, 1] [0.01712992]
Process finished with exit code 0
最后是总的程序,命名为BP神经网络手写数字识别.py,并从上面两个程序中分别调用ImageData类和NeuralNetwork类。
"""导入需要的库"""
from PIL import Image
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.preprocessing import LabelBinarizer
import numpy as np
from getImageData import ImageData
from BpNN import NeuralNetwork
import os
###############提取图片中的特征向量####################
X = []
Y = []
for i in range(0, 10):
# 遍历文件夹,读取数字图片
for f in os.listdir(r'C:\Users\DELL\Desktop\trainimage\pic2\%s'%i):
# 打开一张文件并灰度化
im = np.array(Image.open(r'C:\Users\DELL\Desktop\trainimage\pic2\%s\%s'%(i,f)).convert('L'), 'f')
# 使用ImageData类
z = ImageData(im)
# 获取图片网格特征向量,2代表每上下2格和左右两格为一组
data = z.getData(2)
X.append(data * 0.1)
Y.append(i)
X = np.array(X)
Y = np.array(Y)
# 切分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=1)
# 对标记进行二值化
labels_train = LabelBinarizer().fit_transform(y_train)
###########构造神经网络模型################
# 构建神经网络结构
nn = NeuralNetwork([14 * 14, 100, 10], 'logistic')
# 训练模型
nn.fit(X_train, labels_train, learning_rate=0.2, epochs=60)
# 保存模型
# joblib.dump(nn, 'model/nnModel.m')
# 加载模型
# nn = joblib.load('model/nnModel.m')
###############数字识别####################
# 存储预测结果
predictions = []
# 对测试集进行预测
for i in range(y_test.shape[0]):
out = nn.predict(X_test[i])
predictions.append(np.argmax(out))
###############模型评测#####################
# 打印预测报告
confusion_matrix(y_test, predictions)
# 打印预测结果混淆矩阵
classification_report(y_test, predictions)
D:\Python\python.exe "C:/Users/DELL/PycharmProjects/untitled3/machine learning/BP神经网络手写数字识别.py"
Traceback (most recent call last):
File "C:/Users/DELL/PycharmProjects/untitled3/machine learning/BP神经网络手写数字识别.py", line 23, in
data = z.getData(2)
File "C:\Users\DELL\PycharmProjects\untitled3\machine learning\getImageData.py", line 35, in getData
img = self.point()
File "C:\Users\DELL\PycharmProjects\untitled3\machine learning\getImageData.py", line 16, in point
self.image.point=point
AttributeError: 'numpy.ndarray' object has no attribute 'point'
在运行总文件的过程中出现了bug,苦恼了很久,查了很多网页和博客也没有解决,托师姐找了她的男朋友,师兄现在还没回复,决定先放出来等回头解决,写技术博客对自己是一个很好地锻炼,如博客排版(感觉自己写的有点乱, 希望多写博客以后能有进步),算法的原理,编程过程中产生的问题,继续努力吧,希望以后的程序能少一些bug。
这周的想法是做一些word2vec相关的工作,下周一见(当然也要解决这个令人头大的bug)。