【JavaWeb】从单体架构到微服务架构
文章目录
- 一、前言
- 二、单体架构
- 三、服务器集群架构
- 四、数据库集群架构
- 4.1 数据库读写分离、索引库搜索
- 4.2 redis数据存储、oss文件存储
- 4.3 大数据量分库分表
- 五、SOA架构
- 六、微服务架构
- 七、小结
一、前言
随着互联网的不断发展,后端架构不断更新,一文带你看遍整个过程。
二、单体架构
早期的web程序使用的就是单体架构,如图: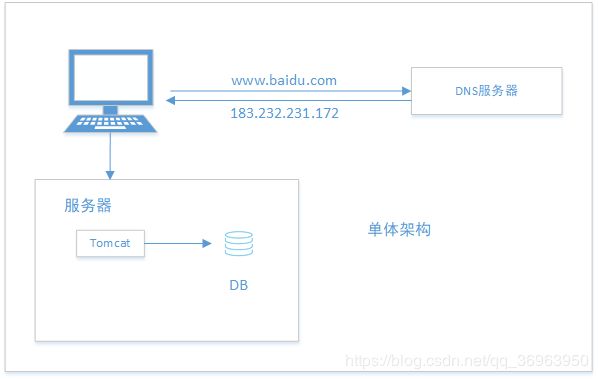
客户端使用域名www.baidu.com访问百度首页,但是服务端只能使用ip解析,不能对字符串解析,所以需要配合DNS服务器,将域名解析为ip地址,传递给服务器,这样服务器才可识别,服务器从数据库中取出数据,交给浏览器,用户可以查看。
上图中,tomcat和db放在同一个物理服务器上,共同使用一个物理服务器的硬件资源和通信资源。
tomcat需要使用的硬件资源包括:使用CPU资源进行计算、使用内存资源运行;
db需要使用的硬件资源包括:使用CPU资源进行计算、使用内存资源运行、使用硬盘资源持久化存储;
tomcat需要使用的通信资源包括:使用网络资源通信;
db需要使用的通信资源包括:使用网络资源通信。
由于一台物理服务器的硬件资源和网络资源有限,很容易达到瓶颈,所有可以把应用服务器tomcat和数据库db放到不同的物理服务器上,如下:
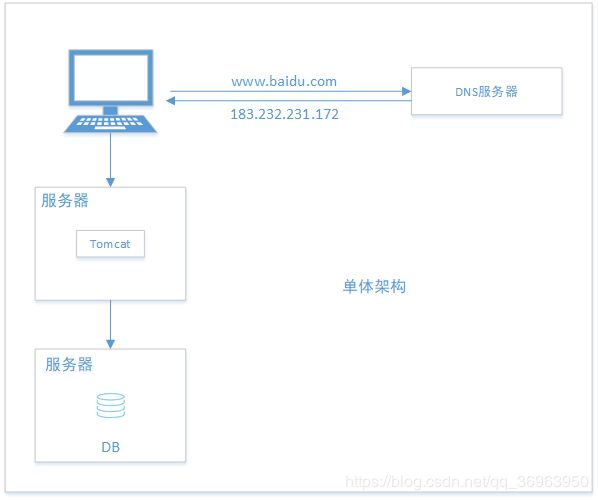
虽然把应用服务器tomcat和数据库db放到不同的物理服务器上,但是这种方式还是单体架构。
三、服务器集群架构
当客户端的网络请求并发数越来越多,服务端的无法承受如此大的网络并发,即服务器的响应成为了整个后端的性能瓶颈,是亟待处理的一个问题。
这里使用tomcat作为应用服务器,响应浏览器请求,tomcat默认并发数 200,即同一时刻最大响应用户请求数为200,超过200会容易出现网络延迟、数据异常等问题,所以对应用服务器tomcat采用集群架构。

服务器集群架构的两个问题:负载均衡、session同步。
负载均衡
由于一个tomcat无法满足并发量,使用多个物理服务器(服务器A 服务器B)搭载多个tomcat,客户端的请求先由负载均衡服务器(这里使用Nginx)处理,负载均衡服务器收到客户端请求后,使用负载均衡算法(有很多,总的原则是均衡各个服务器的压力),将请求转发给相对的tomcat处理。
值得注意的是,这个负载均衡服务器虽然不处理客户端发来的请求,但是它还是要接收和转发客户端发来的请求,所以它本身必须是高可用的,这是使用Nginx,可以承受的并发量为50000,大多数情况下是可以的,如果不够,负载均衡服务器要在做集群。
session同步
由于http协议是无状态的,即http协议不保存客户端状态,即下一次http请求与上一次http请求无关,如用户的登录状态,如果无法被保存的话,那么每一次网络请求之前都要重新登录一次,这是糟糕的,单体架构中使用服务端的session保存用户的登录状态,如图:
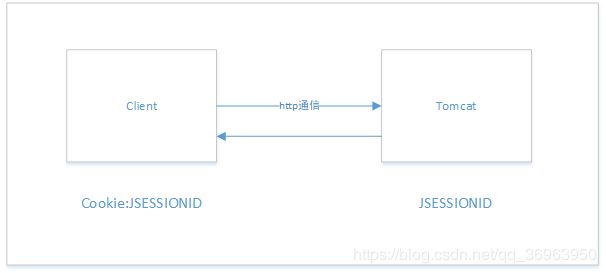
但是使用tomcat集群后,有n个服务器,如果让用户的登录状态在各个服务器之间共享成为一个问题。
解决方式四种:
方式1:由客户端来保存桩体JWT;
方式2:各个服务器之间实现session复制;
方式3:一致性hash(对于同一个客户端的请求都发送到同一个服务器);
方式4:session统一存储(spring-redis-session)。
四、数据库集群架构
当服务端使用tomcat集群架构后,现在负载压力要转移到数据库来了,即数据库读写成为了整个后端的性能瓶颈,而不是在是应用服务器的响应。
4.1 数据库读写分离、索引库搜索
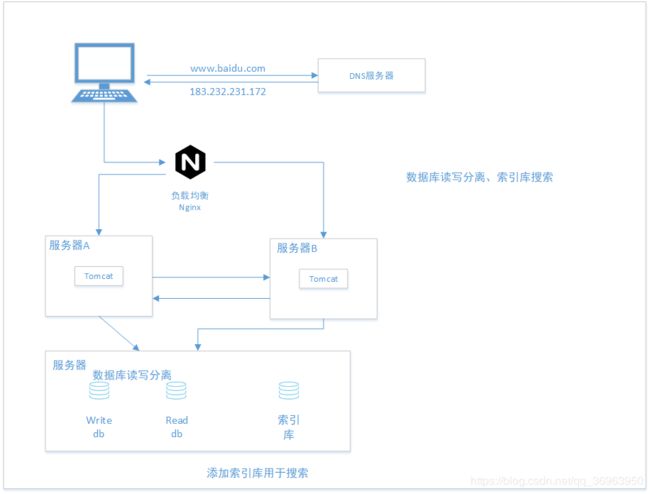
数据库SQL语句优化
借助数据库索引或其他方法,对数据库中CRUD的SQL语句优化,可以大大提高数据库读写效率。
数据库读写分离
数据库查询操作为读操作,添加修改删除为写操作,在后端请求中,读操作的请求远远多于写操作的请求,传统的架构将读操作和写操作冗杂在同一个数据库中,越来越无法满足数据库并发请求,现在将数据库分为读库和写库,所有的读数据操作由读库来完成,所有的写操作由写库来完成,每一个只关注自己的请求,满足更高要求的并发。
数据库主从同步
原来一个数据库不存在数据同步的问题,但是分为读库和写库之后,就要保证读库写库的数据一致,数据库主从同步将数据库分为主库master和从库slave,并定义好主库从库的关系,当然,这里主要是保证写库对数据的插入、更新、删除可以被读库可见。
索引库搜索
即使是分为读库和写库,由于数据库读操作的太过于频繁,但是很多的数据必须存放在数据库,无法存放在内存和磁盘上,查询数据库的代价是非常大的。
比如搜索功能,淘宝、京东、百度的全局搜索功能,面对这种需求,提取出数据库中用于搜索的字段,建立一个专门应对用户搜索的索引库,支持模糊查询、快速响应,常见的有elasticsearch和solr。
索引库更新:全量、增量、实时、非实时
索引库的数据来源是数据库,那么数据库的变化(添加、修改、删除)如何更新给索引库呢?
全量更新:每次更新将数据库中用于搜索的字段的所有记录更新到索引库中;
全量更新优点:保证每次更新后索引库中数据库中数据同步;
全量更新缺点:所有记录更新,耗时太大,代价太大。
增量更新:每次更新将数据库中用于搜索的字段的新增记录更新到索引库中;
增量更新优点:仅更新新增记录,即仅添加数据库新增记录;
增量更新缺点:不保证索引库和数据库完全同步,仅更新上一次同步之后数据库中新增的记录,对于数据库中修改或删除的记录得不到更新,但是这样已经够了,因为索引库仅保证模糊搜索就好了,仅完成搜索功能,搜索后对具体业务的操作还是按数据库中的数据完成。
实时更新:数据库一旦修改用于搜索的字段的记录,索引库要更新;
实时更新优点:索引库与数据库中用于搜索字段的完全同步;
实时更新缺点:代价太大,每一次写数据操作还要额外多一次索引库更新操作。
非实时更新:每个一段固定时间(程序员设置),索引库更新数据库中用于搜索字段的记录;
非实时更新优点:代价小;
非实时更新缺点:无法实时保证索引库和数据库中记录同步。
4.2 redis数据存储、oss文件存储
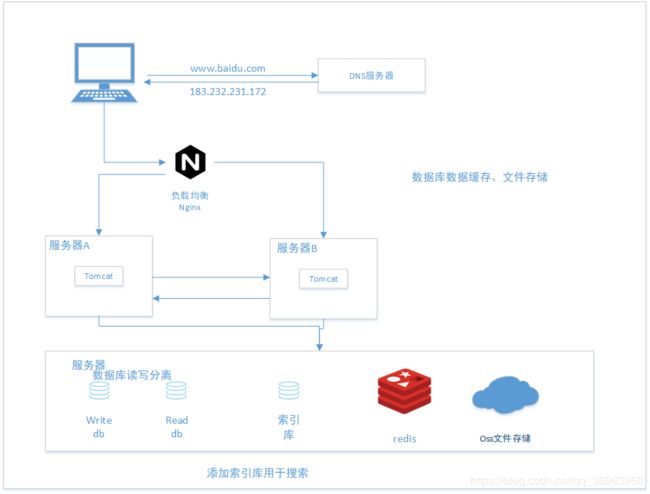
数据库数据缓存
直接从数据库读库、写库中读写数据代价比较大,索引库虽然快,但是目标对象是大数据量的搜索,且是模糊搜索,现在想要从数据库中快速读取数据,需要使用到数据库缓存。
这里是使用redis,它是一种基于内存的非关系型数据库,基于内存则读写速度可以很快,缓存作为服务端程序和数据库之间的一层,解决服务端与数据库速度不匹配问题,大大加快数据读写速度。
redis数据预热
就是初始加载的时候,将需要用到的数据库放到redis,这样程序第一次加载就可以直接从redis中拿到数据,这样可以加快第一次加载的速度。
数据库文件存储
数据库的字段只能保存数据不能保存静态文件(即使可以保存静态文件也不建议这样去做),所以从古到今我的都是将文件保存到服务器磁盘上,数据库中存储文件路径。现在,我们可以使用阿里oss文件云存储工具,将文件存储在阿里云,为我们带来方便。
4.3 大数据量分库分表
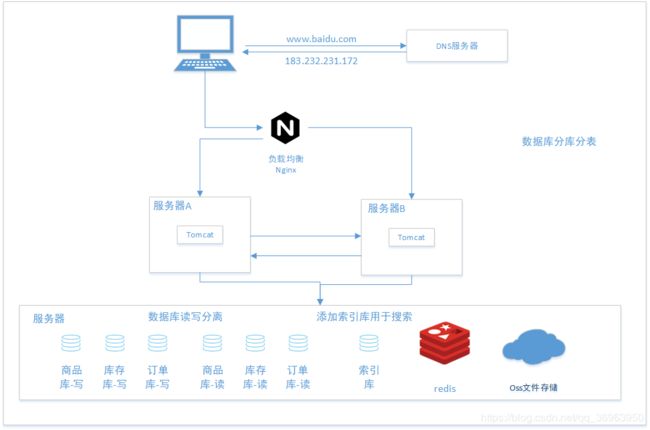
当数据量变大时间,我们要对数据库分库分表操作,分库有两种业务数据库分离、冷热数据库分离,分表有两种水平分表、垂直分表。
库操作:业务数据库分离
如上图所示,由于数据量太大、记录数太多,单一数据库无法承担,将商品、库存、订单分表用单独的库来管理,这就是按照业务对数据库分库。
库操作:冷热数据库分离
分库处理业务数据库分离,还有一种冷热数据库分离,对于同一个业务数据库,将其分为热库和冷库,热库就是我们认为用户将会经常用到的数据,冷库就是我们认为用户偶尔用到的数据,数据读写现在热库中操作,未找到数据再在冷库中操作。
如果对数据划分冷热呢?当然,这结合具体业务来谈,一个通用的原则是,用户当前访问的数据可以认为是热乎的,用户不久之后还会用到,所以放在热库中;当一个数据用户隔着很久的一段时间没有用到,这个数据从热库中移到冷库中。这就是同一个数据库的冷热数据分离。
表操作:水平分表和垂直分表
水平分表:将表按记录划分,如一个表的记录数为500万,按记录划分为三个表记录分别为100万、200万、200万;
垂直分表:将表按字段划分,如一个表的字段为20个,但是我们认为其中5个字段很重要或其他的业务需求(通常是概要列表和详细信息的类似关系),将该表中5个字段提取出来,划分为一个表,即一个表15个字段、一个表5个字段。
五、SOA架构
由于数据库已经根据业务进行分库,服务端也要与数据库对应,将一个服务器处理一个服务,所以引入SOA架构。
SOA,英文全称为Service-Oriented Architecture,即面向服务架构,如图:
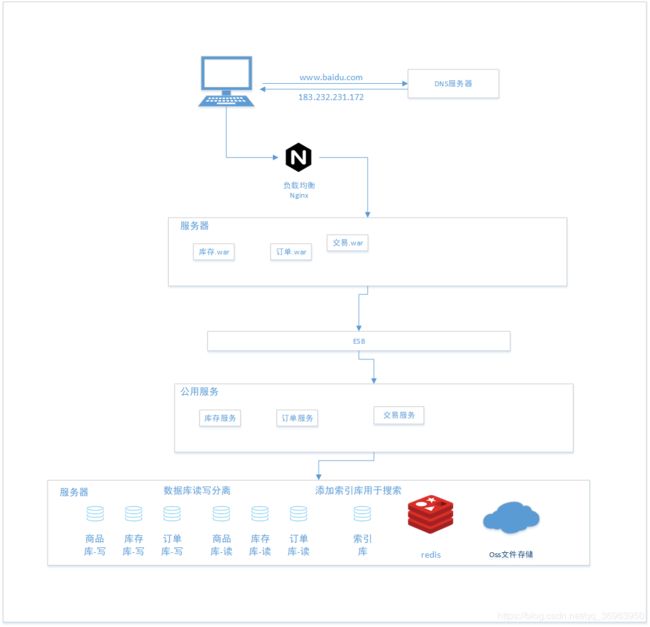
SOA架构需要解决两个问题:信息孤岛和复用。
信息孤岛
信息孤岛即SOA架构将服务端逻辑划分为一个个具体服务,那么各个服务之间如互相调用,如何数据共享?
解决:使用ESB企业服务总线。
复用
复用即SOA架构对于一些通用的信息如何使用?
解决:这里的话是将通用的信息放到“公共服务”中被业务服务调用。
六、微服务架构
SOA是面向服务,是粗粒度的服务,而微服务是对粗粒度服务的进一步解耦,如图:
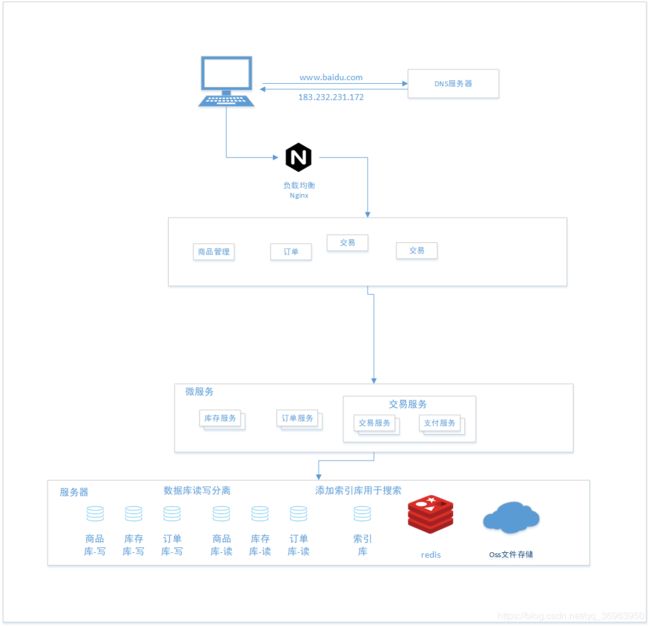
可以看到,微服务去掉了SOA架构的ESB企业服务总线,然后将公用服务进一步细分。
SOA和微服务区别
SOA是面向服务的开始,微服务的面向服务的升华。
七、小结
在后端架构不断更新的过程,从单体架构到应用服务器集群,到数据库各个优化,再到SOA面向服务、微服务架构,虽然在跟随着业务需求不断变化,但是分层的思想一直没有发生变化。分层处理,这正是整个后端架构的精髓。
天天打码,天天进步!