Apache kylin 入门学习 (1)kylin简单认识
一kylin框架
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
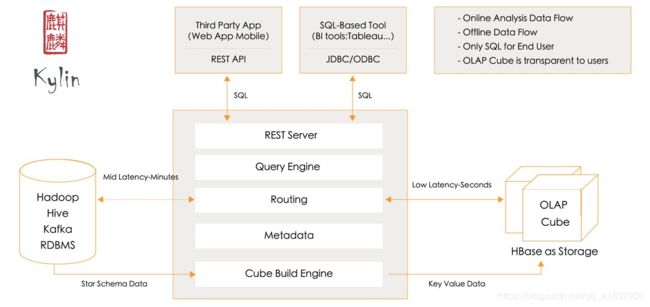
以Hive或者Kafka作为数据源,里面保存着真实表,而Kylin做的就是将数据进行抽象,通过引擎实现Cube的构建。
将Hbase作为数据的仓库,存放Cube。因为Hbase的直接读取比较复杂,所以Kylin提供了近似SQL和HQL的形式,满足了数据读取的基本需求。对外提供了RestApi和JDBC/ODBC方便操作。

kylin解决什么问题
Kylin的使命是超高速的大数据OLAP(Online Analytical Processing)也就是要让大数据分析像使用数据库一样简单迅速,用户的查询请求可以在秒内返回,交互式数据分析将以前所未有的速度释放大数据里潜藏的知识和信息,让我们在面对未来的挑战时占得先机。
kylin如何解决
简单来说,Kylin的核心思想是预计算,即对多维分析可能用到的度量进行预计算,将计算好的结果保存成Cube,供查询时直接访问。把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询,这决定了Kylin能够拥有很好的快速查询和高并发能力。
预加载:
应尽量多地预先计算聚合结果,在查询时刻应尽量使用预算的结果得出查询结
果,从而避免直接扫描可能无限增长的原始记录。
cube:
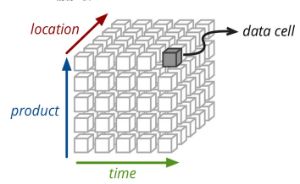
这张图是Cube的一种便于观察的展现方式.
三个维度,依次是时间、产品、地点。维度线上面,就是维度值。度量是上面的小块块。
可以清楚的看到,图形内确定了三个维度,一定可以获取到一个小方块。这个小方块就是最后我们想要的值。这就是Cube的核心。
根据公开数据显示,Kylin的查询性能不只是针对个别SQL,而是对上万种SQL 的平均表现,生产环境下90%ile查询能够在在3s内返回。在上个月举办的Apache Kylin Meetup中,来自美团、京东、百度等互联网公司分享了他们的使用情况。例如,在京东云海的案例中,单个Cube最大有8个维度,最大数据条数4亿,最大存储空间800G,30个Cube共占存储空间4T左右。查询性能上,当QPS在50左右,所有查询平均在200ms以内,当QPS在200左右,平均响应时间在1s以内。
维度与度量
维度和度量是数据分析中的两个基本概念。
维度代表着我们审视数据的角度
通常是数据记录的一个属性,时间是一种维度,地点是一种维度,状态是一种维度。
维度就是观察数据的角度。比如电商的销售数据,可以从
时间的维度来观察(如图1-2的左侧所示),也可以进一步细化,从时间和
地区的维度来观察(如图1-2的右侧所示)。维度一般是一组离散的值,比
如时间维度上的每一个独立的日期,或者商品维度上的每一件独立的商
品。因此统计时可以把维度值相同的记录聚合在一起,然后应用聚合函
数做累加、平均、去重复计数等聚合计算。
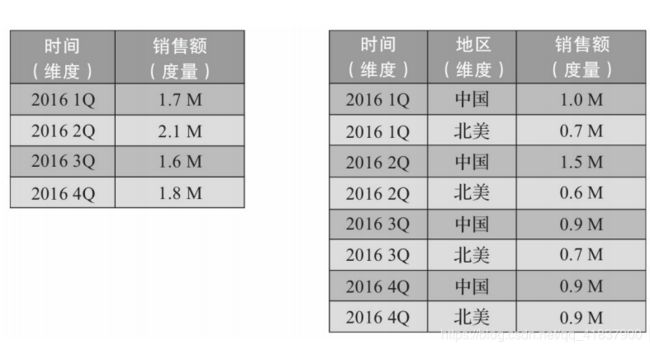
度量代表着基于数据所计算出来的考量值
通常是一个数值,比如这个月份的销售额,购买某产品的客户量。
所谓的数据分析,就是要结合若干维度去审查度量值,找到其中变化的规律。
度量就是被聚合的统计值,也是聚合运算的结果,它一般是连续的
值,如图1-2中的销售额,抑或是销售商品的总件数。通过比较和测算度
量,分析师可以对数据进行评估,比如今年的销售额相比去年有多大的
增长,增长的速度是否达到预期,不同商品类别的增长比例是否合理等。
事实表与维度表
事实表是储存有事实记录的表,例如日志就是一种事实表,它一般在不断的动态增长,所以它的体积通常很大。
维度表是对应事实表的一种体现,保存了维度值,可以关联上事实表,相当于把事实表精细处理,然后生成的一张表。
如果事实表过于庞大笨重,可以考虑使用维度表。
举例:我可以把一张事实表,拆开,生成两种表,一张日期表,日期表里面存储着日期对应的周、月、季度、年等时间属性。一张地点表,地点表里包含着国家、省、城市等属性。优点就是将事实表进行瘦身,便于维度的管理和维护,不至于破坏事实表。减少了工作量,大多数是重复的查询工作。
Cube和Cuboid
有了维度和度量,一个数据表或数据模型上的所有字段就可以分类
了,它们要么是维度,要么是度量(可以被聚合)。于是就有了根据维度和
度量做预计算的Cube理论。
给定一个数据模型,我们可以对其上的所有维度进行组合。对于N个
维度来说,组合的所有可能性共有2N 种。对于每一种维度的组合,将度
量做聚合运算,然后将运算的结果保存为一个物化视图,称为Cuboid。所
有维度组合的Cuboid作为一个整体,被称为Cube。所以简单来说,一个
Cube就是许多按维度聚合的物化视图的集合。
一个cube就是一个Hive表的数据按照指定维度与指标计算出的所有组合结果。
其中每一种维度组合称为cuboid,一个cuboid包含一种具体维度组合下所有指标的值。
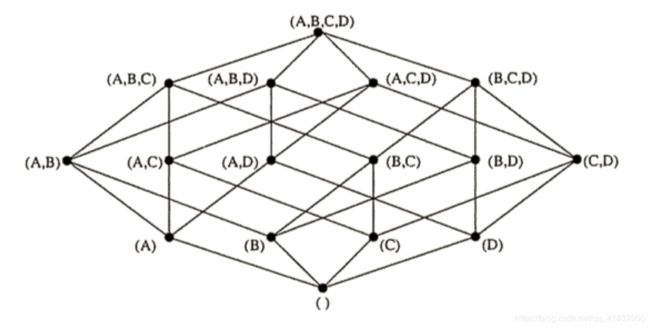
如下图,整个立方体称为1个cube,立方体中每个网格点称为1个cuboid,图中(A,B,C,D)和(A,D)都是cuboid,特别的,(A,B,C,D)称为Base cuboid。cube的计算过程是逐层计算的,首先计算Base cuboid,然后计算维度数依次减少,逐层向下计算每层的cuboid。
简单的说Cuboid的维度会映射为HBase的Rowkey,Cuboid的指标会映射为HBase的Value。如下图所示:
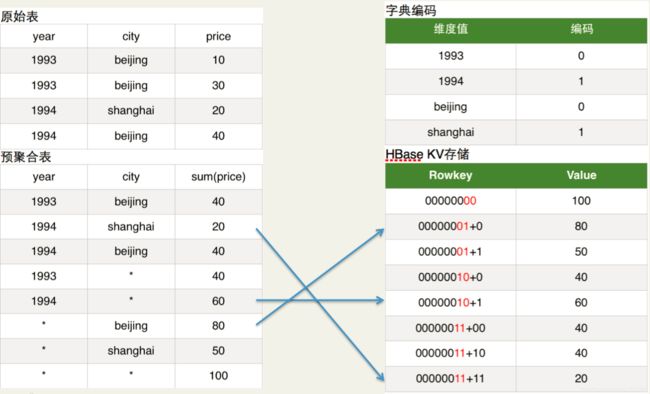
如上图原始表所示:Hive表有两个维度列year和city,有一个指标列price。
如上图预聚合表所示:我们具体要计算的是year和city这两个维度所有维度组合(即4个cuboid)下的sum(priece)指标,这个指标的具体计算过程就是由MapReduce完成的。
如上图字典编码所示:为了节省存储资源,Kylin对维度值进行了字典编码。图中将beijing和shanghai依次编码为0和1。
如上图HBase KV存储所示:在计算cuboid过程中,会将Hive表的数据转化为HBase的KV形式。Rowkey的具体格式是cuboid id + 具体的维度值(最新的Rowkey中为了并发查询还加入了ShardKey),以预聚合表内容的第2行为例,其维度组合是(year,city),所以cuboid id就是00000011,cuboid是8位,具体维度值是1994和shanghai,所以编码后的维度值对应上图的字典编码也是11,所以HBase的Rowkey就是0000001111,对应的HBase Value就是sum(priece)的具体值。
所有的cuboid计算完成后,会将cuboid转化为HBase的KeyValue格式生成HBase的HFile,最后将HFile load进cube对应的HBase表中。