Python笔记之re.search()
最近有学习到 正则表达式,有一点收获,分享一下;
re.search()

情景A
某需求中 银行流水的description字段值是我们财务同事来填写的,我想给这条流水来匹配某些关键字,咋搞?
我最初的思路就是 description字段值.find(关键字);
管你三七二十一,find()的结果 非-1,就代表能找到;
加深一点,如果某些关键字 如下图
![]()
onnqor&SYAFTRACO 这个关键字, & 不是内容,是and ; 整个关键字 实际理解为 【onnqor 某些内容 SYAFTRACO】;
故不能用find();
def find_str(self, description, keyword):
"""
非标匹配
:param description:
:param keyword:
:return:
"""
# 会先进行普通规则匹配【匹配时 不改变description】,匹配失败才会进行正则匹配
desc = description.replace(' ', '')
# 实际非标匹配是有 & 和 ...
k_str = keyword.replace('&', '.*').replace('...', '.*')
if (re.search(k_str, desc)) is not None:
Log.info('当前元素 {},正则匹配成功 {}'.format(description, keyword))
情景B
假设 某银行流水的details字段的 ref_no 是我们财务同事来填写的,要来匹配某些规则(前缀为某关键字 + 结尾为12位数字【年月日 8位数字+4位编号】),流水的details字段值 如下图 【为了不泄密,就是这样的啦】
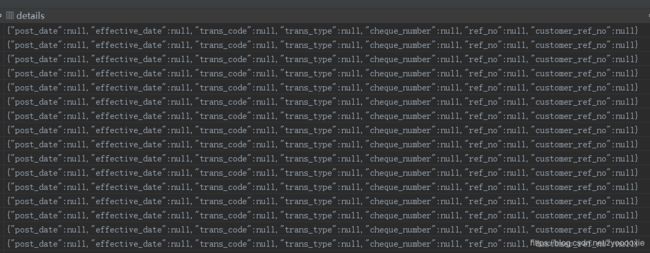
def check_json(self, j):
try:
json.loads(j)
return True
except BaseException:
return False
def find_str_2(self, data_list):
zz_1 = re.compile('^{"')
zz_2 = re.compile('\d{12}$')
for data in data_list:
detail = data[-1]
if detail is not None and zz_1.search(detail) is not None and self.check_json(
detail) is True and ('ref_no' in json.loads(detail).keys()) is True:
reference = json.loads(detail)['ref_no']
# Log.info(reference)
yuanzu = ('探亲', '出差', '薪资(CN)', 'zyooooxie', 'csdn')
if reference is not None and reference.startswith(yuanzu) is True and zz_2.search(reference.strip()) is not None:
Log.info('将进行匹配')
变量yuanzu 代表了 所有的前缀关键字;
而结尾的12位数字,应该要再优化下【思路是 写死 年月日的取值范围,从20200101开始】
def end_search(self, reference):
"""
编号的日期 是 20200101开始,后四位为 全数字
:return:
"""
zz_2 = re.compile(r'\d{12}$')
print(zz_2.search(reference), '优化前')
test_str = '(20[2-9]\d|[3-9]\d{3}|2[1-9]\d{2})(0[1-9]|1[1-2])(0[1-9]|[1-2]\d|3[0-1])\d{4}$' # 年份大于等于2020,小于等于9999
zz_2_new = re.compile(test_str)
print(zz_2_new.search(reference), '优化后')
好像不错呦;
但 我传 20200431(4月没有31号),用上面的正则 是校验不出来的;
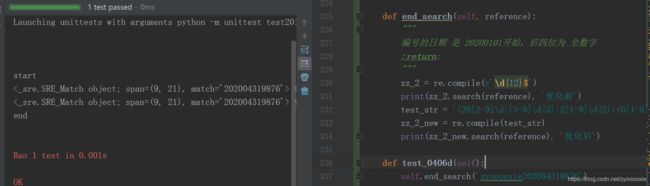
说起来 每月的天数 30or31or29or28,校验是很复杂的 (如2月29 -> 闰年的’四年一闰,百年不闰,四百年再闰’ ),我只能 再写个校验日期的方法 = = (实际原因:正则表达式,我实在是太菜,搞不定)
def check_date(self, reference, zz_2_new):
# test_str = '(20[2-9]\d|[3-9]\d{3}|2[1-9]\d{2})(0[1-9]|1[1-2])(0[1-9]|[1-2]\d|3[0-1])\d{4}$' # 年份大于等于2020,小于等于9999
# zz_2_new = re.compile(test_str)
if zz_2_new.search(reference) is None:
return False
else:
result = zz_2_new.search(reference).group()
check_date = result[0:8]
check_month = result[0:6]
f_l = self.month_first_last('-'.join([check_month[0:4], check_month[4:]]))
check_date = '-'.join([check_date[0:4], check_date[4:6], check_date[6:]])
try:
assert check_date in self.date_list(f_l[0], f_l[1])
return True
except AssertionError:
return False
定义yuanzu变量后 代码改为:
# 前面的zz_2
test_str = '(20[2-9]\d|[3-9]\d{3}|2[1-9]\d{2})(0[1-9]|1[1-2])(0[1-9]|[1-2]\d|3[0-1])\d{4}$' # 年份大于等于2020,小于等于9999
zz_2 = re.compile(test_str)
yuanzu = ('探亲', '出差', '薪资(CN)', 'zyooooxie', 'csdn')
if reference is not None and reference.startswith(yuanzu) is True and self.check_date(reference.strip(), zz_2) is True:
pass # 以下省略
实际的困境
以上 是我写的匹配过程,但我们后台的思路更粗暴:直接把reference的字段值 扔到某个库表去匹配all结果,匹配上,就ok;匹配不上,匹配结束;
实际很不符合需求!
产品小姐姐 定的需求是 匹配前先检查reference是否符合这一类规则,符合就走这一类匹配,不然就走 情景A说的关键字匹配;只是 季度末赶时间交付,产品大佬 又改需求,so 我也得改成这样粗暴匹配;
来到这儿,就得考虑实际库表的记录数量,之前分享过:Python的dict来处理大数据量对账 ,故 把 库表all值 某个字段做成dict
def oa_table_llbh_dict(self):
new_data = self.OA_VALUE()
# Log.info(new_data)
new = [i[0] for i in new_data]
new_dict = dict.fromkeys(new, True)
# Log.info(new_dict)
return new_dict
这样的情景下,代码变成:
yuanzu = ('探亲', '出差', '薪资(CN)', 'zyooooxie', 'csdn')
if (reference.strip() if reference is not None else reference) in self.oa_table_llbh_dict().keys():
pass # 以下省略
情景C
情景:某文件夹内,有很多Excel、CSV文件,其中CSV都是相关Excel转换来的【假设名称完全一样,除了格式不同】;我想知道某个Excel有没有转换成CSV文件,咋整?
思路好像就是: 列出整个文件夹的内容,进行查找,若找到就return,找不到就拉倒;
def find_excel_csv(self, file):
import os
import re
os.chdir(os.path.dirname(file))
# Log.info(file)
# Log.info(os.getcwd())
all_file = os.listdir('.')
Log.info(all_file)
file_csv = '^{}.*.csv$'.format(os.path.basename(file)[:-5])
Log.info(file_csv)
for a in all_file:
if re.search(file_csv, a) is not None:
Log.info('找到了')
Log.info(a)
return a
上面的 for某循环 if某条件,可以直接写成 列表生成式 【或是 列表推导式,列表解析式】 之前有说到 :Python 笔记【一】列表生成式
def find_csv(self, file):
import os
os.chdir(os.path.dirname(file))
all_file = os.listdir('.')
file_csv = '^{}.*.csv$'.format(os.path.basename(file)[:-5])
Log.info(file_csv)
ele = [a for a in all_file if re.search(file_csv, a) is not None]
if len(ele) != 0:
Log.info('找到了')
new_file = ele[0]
Log.info(new_file)
else:
Log.info('整个文件夹没有相关的CSV文件')
交流技术 欢迎+QQ 153132336 zy
个人博客 https://blog.csdn.net/zyooooxie