使用pthread实现多线程CPU+GPU计算
本次测试目的仅仅为了尝试能否使用pthread实现多线程对CPU和GPU分别进行控制:
文件结构如下:
main.cc:控制线程的主函数
vector.cu:实现对核函数进行调用的任务函数
vector.h:任务函数声明
vector_kernel.cu:核函数
vector_kernel.h:核函数声明
生成文件如下:
vector:最终生成的可执行文件
main.o:生成的函数体obj
vector.o:生成的任务函数obj
vector_kernel.o:生成的核函数obj
功能描述:
线程1:执行GPU代码(向量加法)
线程2:执行CPU代码(循环打印数据)
线程3:执行CPU代码(循环打印数据)
线程4:执行CPU代码(循环打印数据)
文件代码:
main.cc:
#include
<
stdio.h
>
#include < pthread.h >
#include < sys / time.h >
#include < stdlib.h >
#include < string .h >
#include " vector.h "
pthread_t thread[ 4 ];
void * thread1( void * )
{
// do GPU task
float time, start;
start = clock();
printf( " thread1:I'm thread1\n " );
int i, n = 100 ;
float * a, * b, * c;
a = ( float * )malloc(n * sizeof ( float ));
b = ( float * )malloc(n * sizeof ( float ));
c = ( float * )malloc(n * sizeof ( float ));
for (i = 0 ; i < n; i ++ )
{
a[i] = 1.0f ;
b[i] = 1.0f ;
}
for (i = 0 ; i < 100 ; i ++ )
{
vectorAdd(a, b, c, n);
}
printf( " thread1:c[%d] = %f\n " , 0 , c[ 0 ]);
free(a);
free(b);
free(c);
time = clock() - start;
printf( " thread1: task was finished!\ncostTime1 : %f\n " , time / CLOCKS_PER_SEC);
pthread_exit(NULL);
}
void * thread2( void * )
{
// do CPU task
float time, start;
start = clock();
printf( " thread2:I'm thread2\n " );
int i, j, k = 1 ;
for (i = 0 ; i < 1000 ; i ++ )
{
for (j = 0 ; j < 1000 ; j ++ )
{
printf( " thread2:k = %d\n " , k);
k ++ ;
}
}
time = clock() - start;
printf( " thread2: task was finished!\ncostTime2 : %f\n " , time / CLOCKS_PER_SEC);
pthread_exit(NULL);
}
void * thread3( void * )
{
// do CPU task
float time, start;
start = clock();
printf( " thread3:I'm thread3\n " );
int i, j, k = 1 ;
for (i = 0 ; i < 1000 ; i ++ )
{
for (j = 0 ; j < 1000 ; j ++ )
{
printf( " thread3:k = %d\n " , k);
k ++ ;
}
}
time = clock() - start;
printf( " thread3: task was finished!\ncostTime3 : %f\n " , time / CLOCKS_PER_SEC);
pthread_exit(NULL);
}
void * thread4( void * )
{
// do CPU task
float time, start;
start = clock();
printf( " thread4:I'm thread4\n " );
int i, j, k = 1 ;
for (i = 0 ; i < 1000 ; i ++ )
{
for (j = 0 ; j < 1000 ; j ++ )
{
printf( " thread4:k = %d\n " , k);
k ++ ;
}
}
time = clock() - start;
printf( " thread4: task was finished!\ncostTime4 : %f\n " , time / CLOCKS_PER_SEC);
pthread_exit(NULL);
}
void thread_create()
{
int temp;
memset( & thread, 0 , sizeof (thread));
if ((temp = pthread_create( & thread[ 0 ], NULL, thread1, NULL)) != 0 )
printf( " 线程1创建失败!\n " );
else
printf( " 线程1被创建!\n " );
if ((temp = pthread_create( & thread[ 1 ], NULL, thread2, NULL)) != 0 )
printf( " 线程2创建失败!\n " );
else
printf( " 线程2被创建!\n " );
if ((temp = pthread_create( & thread[ 2 ], NULL, thread3, NULL)) != 0 )
printf( " 线程3创建失败!\n " );
else
printf( " 线程3被创建!\n " );
if ((temp = pthread_create( & thread[ 3 ], NULL, thread4, NULL)) != 0 )
printf( " 线程4创建失败!\n " );
else
printf( " 线程4被创建!\n " );
}
void thread_wait()
{
if (thread[ 0 ] != 0 )
{
pthread_join(thread[ 0 ], NULL);
printf( " 线程1已经结束\n " );
}
if (thread[ 1 ] != 0 )
{
pthread_join(thread[ 1 ], NULL);
printf( " 线程2已经结束\n " );
}
if (thread[ 2 ] != 0 )
{
pthread_join(thread[ 2 ], NULL);
printf( " 线程3已经结束\n " );
}
if (thread[ 3 ] != 0 )
{
pthread_join(thread[ 3 ], NULL);
printf( " 线程4已经结束\n " );
}
}
int main()
{
float time, start;
printf( " 我是主函数,正在创建线程\n " );
start = clock();
thread_create();
printf( " 我是主函数,正在等待线程完成任务\n " );
thread_wait();
time = clock() - start;
printf( " costTime0 : %f\n " , time / CLOCKS_PER_SEC);
return 0 ;
}
#include < pthread.h >
#include < sys / time.h >
#include < stdlib.h >
#include < string .h >
#include " vector.h "
pthread_t thread[ 4 ];
void * thread1( void * )
{
// do GPU task
float time, start;
start = clock();
printf( " thread1:I'm thread1\n " );
int i, n = 100 ;
float * a, * b, * c;
a = ( float * )malloc(n * sizeof ( float ));
b = ( float * )malloc(n * sizeof ( float ));
c = ( float * )malloc(n * sizeof ( float ));
for (i = 0 ; i < n; i ++ )
{
a[i] = 1.0f ;
b[i] = 1.0f ;
}
for (i = 0 ; i < 100 ; i ++ )
{
vectorAdd(a, b, c, n);
}
printf( " thread1:c[%d] = %f\n " , 0 , c[ 0 ]);
free(a);
free(b);
free(c);
time = clock() - start;
printf( " thread1: task was finished!\ncostTime1 : %f\n " , time / CLOCKS_PER_SEC);
pthread_exit(NULL);
}
void * thread2( void * )
{
// do CPU task
float time, start;
start = clock();
printf( " thread2:I'm thread2\n " );
int i, j, k = 1 ;
for (i = 0 ; i < 1000 ; i ++ )
{
for (j = 0 ; j < 1000 ; j ++ )
{
printf( " thread2:k = %d\n " , k);
k ++ ;
}
}
time = clock() - start;
printf( " thread2: task was finished!\ncostTime2 : %f\n " , time / CLOCKS_PER_SEC);
pthread_exit(NULL);
}
void * thread3( void * )
{
// do CPU task
float time, start;
start = clock();
printf( " thread3:I'm thread3\n " );
int i, j, k = 1 ;
for (i = 0 ; i < 1000 ; i ++ )
{
for (j = 0 ; j < 1000 ; j ++ )
{
printf( " thread3:k = %d\n " , k);
k ++ ;
}
}
time = clock() - start;
printf( " thread3: task was finished!\ncostTime3 : %f\n " , time / CLOCKS_PER_SEC);
pthread_exit(NULL);
}
void * thread4( void * )
{
// do CPU task
float time, start;
start = clock();
printf( " thread4:I'm thread4\n " );
int i, j, k = 1 ;
for (i = 0 ; i < 1000 ; i ++ )
{
for (j = 0 ; j < 1000 ; j ++ )
{
printf( " thread4:k = %d\n " , k);
k ++ ;
}
}
time = clock() - start;
printf( " thread4: task was finished!\ncostTime4 : %f\n " , time / CLOCKS_PER_SEC);
pthread_exit(NULL);
}
void thread_create()
{
int temp;
memset( & thread, 0 , sizeof (thread));
if ((temp = pthread_create( & thread[ 0 ], NULL, thread1, NULL)) != 0 )
printf( " 线程1创建失败!\n " );
else
printf( " 线程1被创建!\n " );
if ((temp = pthread_create( & thread[ 1 ], NULL, thread2, NULL)) != 0 )
printf( " 线程2创建失败!\n " );
else
printf( " 线程2被创建!\n " );
if ((temp = pthread_create( & thread[ 2 ], NULL, thread3, NULL)) != 0 )
printf( " 线程3创建失败!\n " );
else
printf( " 线程3被创建!\n " );
if ((temp = pthread_create( & thread[ 3 ], NULL, thread4, NULL)) != 0 )
printf( " 线程4创建失败!\n " );
else
printf( " 线程4被创建!\n " );
}
void thread_wait()
{
if (thread[ 0 ] != 0 )
{
pthread_join(thread[ 0 ], NULL);
printf( " 线程1已经结束\n " );
}
if (thread[ 1 ] != 0 )
{
pthread_join(thread[ 1 ], NULL);
printf( " 线程2已经结束\n " );
}
if (thread[ 2 ] != 0 )
{
pthread_join(thread[ 2 ], NULL);
printf( " 线程3已经结束\n " );
}
if (thread[ 3 ] != 0 )
{
pthread_join(thread[ 3 ], NULL);
printf( " 线程4已经结束\n " );
}
}
int main()
{
float time, start;
printf( " 我是主函数,正在创建线程\n " );
start = clock();
thread_create();
printf( " 我是主函数,正在等待线程完成任务\n " );
thread_wait();
time = clock() - start;
printf( " costTime0 : %f\n " , time / CLOCKS_PER_SEC);
return 0 ;
}
vector.cu:
#include
<
stdio.h
>
#include < stdlib.h >
#include < cuda.h >
#include " vector.h "
#include " vector_kernel.h "
void vectorAdd( float * a, float * b, float * c, int n)
{
float * d_a, * d_b, * d_c;
cudaMalloc(( void ** ) & d_a, n * sizeof ( float ));
cudaMemcpy(d_a, a, n * sizeof ( float ), cudaMemcpyHostToDevice);
cudaMalloc(( void ** ) & d_b, n * sizeof ( float ));
cudaMemcpy(d_b, b, n * sizeof ( float ), cudaMemcpyHostToDevice);
cudaMalloc(( void ** ) & d_c, n * sizeof ( float ));
cudaMemcpy(d_b, b, n * sizeof ( float ), cudaMemcpyHostToDevice);
vectorAddKernel <<< 1 , n >>> (d_a, d_b, d_c, n);
cudaMemcpy(c, d_c, n * sizeof ( float ), cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
#include < stdlib.h >
#include < cuda.h >
#include " vector.h "
#include " vector_kernel.h "
void vectorAdd( float * a, float * b, float * c, int n)
{
float * d_a, * d_b, * d_c;
cudaMalloc(( void ** ) & d_a, n * sizeof ( float ));
cudaMemcpy(d_a, a, n * sizeof ( float ), cudaMemcpyHostToDevice);
cudaMalloc(( void ** ) & d_b, n * sizeof ( float ));
cudaMemcpy(d_b, b, n * sizeof ( float ), cudaMemcpyHostToDevice);
cudaMalloc(( void ** ) & d_c, n * sizeof ( float ));
cudaMemcpy(d_b, b, n * sizeof ( float ), cudaMemcpyHostToDevice);
vectorAddKernel <<< 1 , n >>> (d_a, d_b, d_c, n);
cudaMemcpy(c, d_c, n * sizeof ( float ), cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
vector.h:
#include
<
stdio.h
>
#include < stdlib.h >
void vectorAdd( float * a, float * b, float * c, int n);
#include < stdlib.h >
void vectorAdd( float * a, float * b, float * c, int n);
vector_kernel.cu:
#include
<
stdio.h
>
#include < stdlib.h >
#include < cuda.h >
#include " vector_kernel.h "
__global__ void vectorAddKernel( float * a, float * b, float * c, int n)
{
int tid;
tid = threadIdx.x;
if (tid < n)
c[tid] = a[tid] + b[tid];
}
#include < stdlib.h >
#include < cuda.h >
#include " vector_kernel.h "
__global__ void vectorAddKernel( float * a, float * b, float * c, int n)
{
int tid;
tid = threadIdx.x;
if (tid < n)
c[tid] = a[tid] + b[tid];
}
vector_kernel.h:
#include
<
stdio.h
>
#include < cuda.h >
#include < stdlib.h >
__global__ void vectorAddKernel( float * a, float * b, float * c, int n);
#include < cuda.h >
#include < stdlib.h >
__global__ void vectorAddKernel( float * a, float * b, float * c, int n);
而最主要的是makefile的内容,由于nvcc会将.cu生成obj默认为c++方式,所以,需要将主函数改为.cc文件,不然将会编译出错!
makefile:
vector : main.o vector.o vector_kernel.o
nvcc - o vector main.o vector.o vector_kernel.o
vector_kernel.o : vector_kernel.cu vector_kernel.h
nvcc - c vector_kernel.cu
vector.o : vector.cu vector.h vector_kernel.h
nvcc - c vector.cu
main.o : main.cc vector.h
cc - lpthread - c main.cc
nvcc - o vector main.o vector.o vector_kernel.o
vector_kernel.o : vector_kernel.cu vector_kernel.h
nvcc - c vector_kernel.cu
vector.o : vector.cu vector.h vector_kernel.h
nvcc - c vector.cu
main.o : main.cc vector.h
cc - lpthread - c main.cc
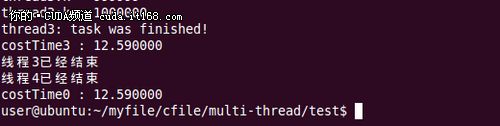
通过测试时间可以知道几个线程之间的执行关系,大家自己测试啦~
以下是一个运行结果:
更多内容请点击:
CUDA专区:http://cuda.it168.com/
CUDA论坛:http://cudabbs.it168.com/
原文链接:地址