针对新冠肺炎疫情的Python疫情数据爬取(基于requests和pandas)
数据源选择
将新闻媒体的播报平台作为数据源,以网易的疫情播报平台为例,如下图所示可以看到它的数据内容非常丰富,不仅包括国内的数据还包括国外的数据,且作为大平台,公信度也比较高。因此我们选择网易的疫情实时动态播报平台作为数据源,其地址如下:https://wp.m.163.com/163/page/news/virus_report/index.html?nw=1&anw=1
我们基于网易的实时播报平台寻找数据,由于它是一个实时的动态平台,因此数据一般在Network标签下可以找到,以Chrome浏览器为例展示寻找数据步骤:
- 访问网易实时疫情播报平台
- 在页面任意位置右键点击检查
- 进入Network标签下的XHR,此时可能会提示刷新,按下“Ctrl+R”即可
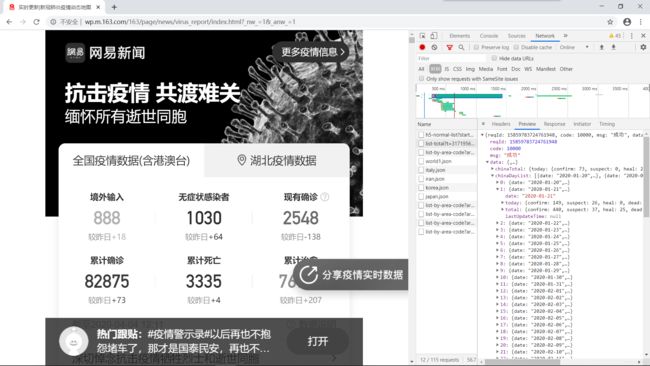
在网页的检查页面内,左下角红框所示的部分是我们找到的数据源,基于这些地址进行爬取,我们获取数据的目标是全国,世界各国以及全国各省的实时以及历史数据。
初步探索
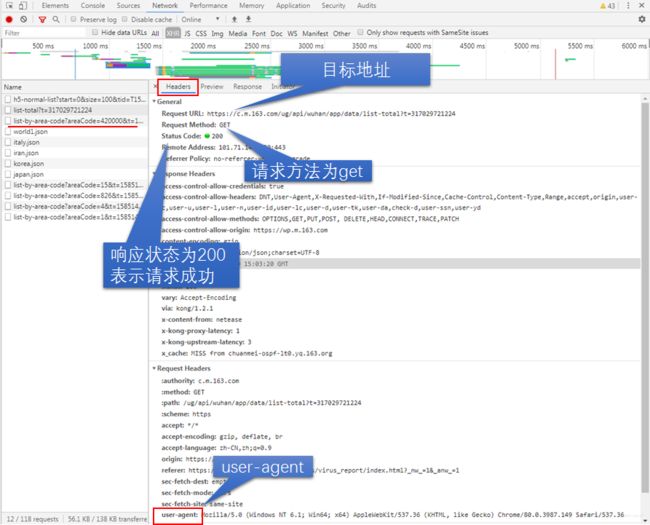
通过比对,我们发现在第二个地址中存放着关于疫情的数据,因此我们先对这个地址进行爬虫。接下来找到其地址,点击headers后进行查看,在url中?后边为参数,可以不用设置,因此我们需要请求的地址为:https://c.m.163.com/ug/api/wuhan/app/data/list-total ,并且可以看到请求方法为get,同时查看自己浏览器的user-agent,使用requests请求时,设置user-agent伪装浏览器。
接下来开始请求,首先导入使用的包,使用request进行网页请求,使用pandas保存数据。
同时设置请求头,伪装为浏览器使用requests发起请求,查看请求状态。
import requests
import pandas as pd
import time
pd.set_option('max_rows',500)
url = "https://c.m.163.com/ug/api/wuhan/app/data/list-total" # 定义要访问的地址
r = requests.get(url,headers={'user-agent': '填写自己的user-agent'}) # 使用requests发起请求
print(r.status_code) # 查看请求状态
print(type(r.text))
print(len(r.text))
可以看到返回后的内容是一个几十万长度的字符串,由于字符串格式不方便进行分析,并且在网页预览中发现数据为类似字典的json格式,所以我们将其转为json格式。
import json
data_json = json.loads(r.text)
type(data_json)
data_json.keys()
可以看出在data中存放着我们需要的数据,因此我们取出数据。
data = data_json['data'] # 取出json中的数据
data.keys()
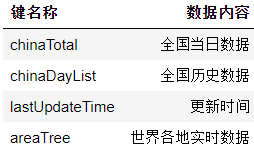
数据中总共有四个键,每个键存储着不同的内容:
接下来分别获取实时数据和历史数据。
直接上代码了,具体不懂可以评论讨论。
import requests
import pandas as pd
import time
import json
# 将提取数据的方法封装为函数
def get_data(data, info_list):
info = pd.DataFrame(data)[info_list] # 主要信息
today_data = pd.DataFrame([i['today'] for i in data]) # 提取today的数据
today_data.______ = ['today_' + i for i in today_data.columns] # 修改列名 columns
total_data = pd.DataFrame([i['total'] for i in data]) # 提取total的数据
total_data.______ = ['total_' + i for i in total_data.columns] # 修改列名 columns
return pd.concat([info, total_data, today_data], axis=1) # info、today和total横向合并最终得到汇总的数据
def save_data(data,name): # 定义保存数据方法
file_name = name+'_'+time.strftime('%Y_%m_%d',time.localtime(time.time()))+'.csv'
data.to_csv(file_name,index=None,encoding='utf_8_sig')
print(file_name+' 保存成功!')
def main():
pd.set_option('max_rows',500)
url = "https://c.m.163.com/ug/api/wuhan/app/data/list-total"
headers = {'user-agent': '这里随便写入一个user-agent'}
r = requests.get(url,headers=headers)
# print(r.status_code)
# print(type(r.text))
# print(len(r.text))
data_json = json.loads(r.text)
type(data_json)
data_json.keys()
data = data_json['data'] # 取出json中的数据
# 中国各省的实时数据爬取
data_province = data['areaTree'][2]['children']
today_province = get_data(data_province,['id','lastUpdateTime','name'])
save_data(today_province, 'today_province')
# 世界各国实时数据爬取
areaTree = data['areaTree'] # 取出areaTree
today_world = get_data(areaTree, ['id', 'lastUpdateTime', 'name'])
today_world.head()
# 中国历史数据爬取
chinaDayList = data['chinaDayList']
alltime_China = get_data(chinaDayList, ['date', 'lastUpdateTime'])
save_data(alltime_China, 'alltime_China')
# 中国各省历史数据爬取
start = time.time()
for province_id in province_dict: # 遍历各省编号
try:
# 按照省编号访问每个省的数据地址,并获取json数据
url_1 = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + province_id
r = requests.get(url_1, headers=headers)
data_json = json.loads(r.text)
# 提取各省数据,然后写入各省名称
province_data = get_data(data_json['data']['list'], ['date'])
province_data['name'] = province_dict[province_id]
# 合并数据
if province_id == '420000':
alltime_province = province_data
else:
alltime_province = pd.DataFrame([alltime_province, province_data])
print('-' * 20, province_dict[province_id], '成功',
province_data.shape, alltime_province.shape,
',累计耗时:', round(time.time() - start), '-' * 20)
# 设置延迟等待
time.sleep(10)
except:
print('-' * 20, province_dict[province_id], 'wrong', '-' * 20)
alltime_province.info()
save_data(alltime_province, 'alltime_province')
# 世界各国历史数据爬取
country_dict = {key: value for key, value in zip(today_world['id'], today_world['name'])}
start = time.time()
for country_id in country_dict: # 遍历每个国家的编号
try:
# 按照编号访问每个国家的数据地址,并获取json数据
url_2 = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + country_id
r = requests.get(url_2, headers=headers)
json_data = json.loads(r.text)
# 生成每个国家的数据
country_data = get_data(json_data['data']['list'], ['date'])
country_data['name'] = country_dict[country_id]
# 数据叠加
if country_id == '9577772':
alltime_world = country_data
else:
alltime_world = pd.DataFrame([alltime_world, country_data])
print('-' * 20, country_dict[country_id], '成功', country_data.shape, alltime_world.shape,
',累计耗时:', round(time.time() - start), '-' * 20)
time.sleep(10)
except:
print('-' * 20, country_dict[country_id], 'wrong', '-' * 20)
print(alltime_world.shape)
save_data(alltime_world, 'alltime_world')
main()
声明:本博客内容为学习酷客上相关案例后所做总结。