SpringJDBC配合Druid数据库连接池,实现对数据库操作
SpringJDBC配合Druid数据库连接池,实现对数据库操作
配置环境
演示编译器使用为intelliJ IDEA。
将需要的jar包导入到项目,在项目中src目录下创建一个lib文件夹,将此项目所需的jar包放入文件夹
以上为实现操作需要的jar包目录。
Jar包放入文件夹后需要右键lib文件夹,点击Add as Library,将jar包导入项目
![]()
配置文件配置
创建*.properties文件,内容填写如下
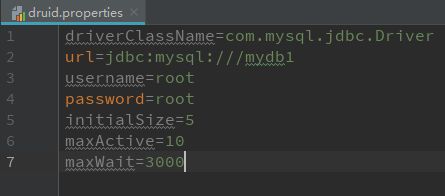
第一行为配置mysql驱动
第二行为数据库连接端口,完整为:jdbc:mysql://localhost:3306/mydb1,红色部分填写本地数据库端口地址,根据自身情况改动。
第三行,第四行为数据库连接的账号密码。
第五行和第六行为数据库连接池最小和最大连接数。
第七行为连接失败最大等待时间。
还有其他配置根据需要自行配置。
创建一个数据库连接工具类
提供静态代码块加载配置文件,初始化连接池对象
提供获取连接方法:通过数据库连接池获取连接
获取连接池的方法
代码如下
public class DBUtill {
private static DataSource ds=null;
static {
try {
Properties pr=new Properties();//创建一个没有默认值的空属性列表。
InputStream is=DruidTest1.class.getClassLoader()
.getResourceAsStream("druid.properties");
//将配置好的配置文件信息读出
pr.load(is);//从输入字节流读取属性列表
ds= DruidDataSourceFactory.createDataSource(pr);//从配置文件读取信息创建数据库连接池对象
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
public DataSource getDataSource(){
return ds;
}
}
使用Spring-JDBC连接数据库
SpringJdbcSpring框架对JDBC的简单封装。提供了一个JDBCTemplate对象简化JDBC的开发
步骤:
1. 导入jar包
2. 创建JdbcTemplate对象。依赖于数据源DataSource
* JdbcTemplate template = new JdbcTemplate(ds);
3. 调用JdbcTemplate的方法来完成CRUD的操作
* update():执行DML语句。增、删、改语句
* queryForMap():查询结果将结果集封装为map集合,将列名作为key,将值作为value 将这条记录封装为一个map集合(注意:这个方法查询的结果集长度只能是1)
* queryForList():查询结果将结果集封装为list集合(注意:将每一条记录封装为一个Map集合,再将Map集合装载到List集合中)
* query():查询结果,将结果封装为JavaBean对象,query的参数:RowMapper。 一般我们使用BeanPropertyRowMapper实现类。可以完成数据到JavaBean的自动封装;new BeanPropertyRowMapper<类型>(类型.class)
* queryForObject:查询结果,将结果封装为对象,一般用于聚合函数的查询
代码编写如下
public static void main(String[] args) {
//1.导入jar包
//2.创建JdbcTemplate对象。依赖于数据源DataSource
DBUtill dbconn=new DBUtill();//创建刚刚定义的工具类对象
JdbcTemplate template=new JdbcTemplate(dbconn.getDataSource());//创建JdbcTemplate对象,依赖于数据源DataSource
String sql="insert into user values(null,?,?)";//定义sql语句
template.update(sql,"bbb","123");//执行sql
}

数据库中成功加入一条数据
总结
- 导入jar包
- 配置配置文件
- 编写工具类
- 实现
相关资源下载
Druid 完整jar包下载https://github.com/alibaba/druid/releases
Spring 完整jar包下载https://repo.spring.io/release/org/springframework/spring/
Mysql-Jdbc jar包下载https://dev.mysql.com/downloads/connector/j/