ID3(Iterative Dichotomiser 3)算法原理 简述
1.信息熵
熵( E n t r o p y Entropy Entropy)这个概念最早起源于物理学,在物理学中是用来度量一个热力学系统的无序程度 ,而在信息学里面,熵是对不确定性的度量。在1948年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化程度的一个度量。
假设变量 X X X 的随机取值为 X X X={ x 1 , x 2 , x 3 . . . , x n x_1,x_2,x_3...,x_n x1,x2,x3...,xn},每一种取到的概率分别是 P x P_x Px= { p 1 , p 2 , p 3 , . . . p n p_1,p_2,p_3,...p_n p1,p2,p3,...pn },则变量 X X X 的熵为:
H ( X ) = − ∑ n = 1 n p i log 2 p i H(X)=-∑_{n=1}^n{p_i\log_2p_i} H(X)=−n=1∑npilog2pi
意思就是一个变量的变化情况越多,那么信息熵越大越不稳定。
2.信息增益
信息增益 ( I G : IG: IG:Information Gain)针对单个特征而言,即看一个特征 t t t,系统有它没有它时信息熵之差。下面是 w e k a weka weka中的一个数据集,关于不同天气是否打球的例子。特征是天气, l a b e l label label是是否打球。
| outlook | temperature | humidity | windy | play |
|---|---|---|---|---|
| sunny | hot | high | FALSE | no |
| sunny | hot | high | TRUE | no |
| overcast | hot | high | FALSE | yes |
| rainy | mild | high | FALSE | yes |
| rainy | cool | normal | FALSE | yes |
| rainy | cool | normal | TRUE | no |
| overcast | cool | normal | TRUE | yes |
| sunny | mild | high | FALSE | no |
| sunny | cool | normal | FALSE | yes |
| rainy | mild | normal | FALSE | yes |
| sunny | mild | normal | TRUE | yes |
| overcast | mild | high | TRUE | yes |
| overcast | hot | normal | FALSE | yes |
| rainy | mild | high | TRUE | no |
共有14个样本,9个正样本(yes)5个负样本(no),信息熵为:
E n t r o p y ( S ) = − 9 14 log 2 9 14 − 5 14 log 2 5 14 = 0.940286 Entropy(S)=-\frac{9}{14}\log_2\frac{9}{14}−\frac{5}{14}\log_2\frac{5}{14}=0.940286 Entropy(S)=−149log2149−145log2145=0.940286
接下来会遍历 o u t l o o k , t e m p e r a t u r e , h u m i d i t y , w i n d y outlook, temperature, humidity, windy outlook,temperature,humidity,windy四个属性,求出用每个属性划分以后的信息熵假设以 o u t l o o k outlook outlook来划分,此时只关心 o u t l o o k outlook outlook这个属性,而不再关心其他属性:
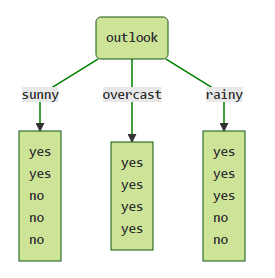
此时的信息熵为:
E n t r o p y ( s u n n y ) = − 2 5 log 2 2 5 − 3 5 log 2 3 5 = 0.970951 Entropy(sunny)=−\frac{2}{5}\log_2\frac{2}{5}−\frac{3}{5}\log_2\frac{3}{5}=0.970951 Entropy(sunny)=−52log252−53log253=0.970951
E n t r o p y ( o v e r c a s t ) = − 4 4 log 2 4 4 − 0 × log 2 0 = 0 Entropy(overcast)=−\frac{4}{4}\log_2\frac{4}{4}−0×\log_20=0 Entropy(overcast)=−44log244−0×log20=0
E n t r o p y ( r a i n y ) = − 2 5 log 2 2 5 − 3 5 log 2 3 5 = 0.970951 Entropy(rainy)=−\frac{2}{5}\log_2\frac{2}{5}−\frac{3}{5}\log_2\frac{3}{5}=0.970951 Entropy(rainy)=−52log252−53log253=0.970951
总的信息熵为
E n t r o p y = ∑ t i = t 0 t n P ( t = t i ) E n t r o p y ( T = t i ) Entropy=∑_{ti=t0}^{t_n}P(t=t_i)Entropy(T=t_i) Entropy=ti=t0∑tnP(t=ti)Entropy(T=ti)
即
E n t r o p y ( S ∣ o u t l o o k ) = P ( s u n n y ) × E n t r o p y ( s u n n y ) + P ( o v e r c a s t ) × E n t r o p y ( o v e r c a s t ) + P ( r a i n y ) Entropy(S|outlook)=P(sunny)×Entropy(sunny)+P(overcast)×Entropy(overcast)+P(rainy) Entropy(S∣outlook)=P(sunny)×Entropy(sunny)+P(overcast)×Entropy(overcast)+P(rainy)
× E n t r o p y ( r a i n y ) = 0.693536 ×Entropy(rainy)=0.693536 ×Entropy(rainy)=0.693536
E n t r o p y ( S ∣ o u t l o o k ) Entropy(S|outlook) Entropy(S∣outlook)指的是选择属性 o u t l o o k outlook outlook作为分类条件的信息熵,最终属性 o u t l o o k outlook outlook的信息增益为:
I G ( o u t l o o k ) = E n t r o p y ( S ) − E n t r o p y ( S ∣ o u t l o o k ) = 0.24675 IG(outlook)=Entropy(S)−Entropy(S|outlook)=0.24675 IG(outlook)=Entropy(S)−Entropy(S∣outlook)=0.24675
IG:Information Gain(信息增益)
同理可以计算选其他分类属性的信息增益,选择信息增益最大的属性作为分类属性。分类完成之后,样本被分配到3个叶子节点:
| outlook | temperature | humidity | windy | play |
|---|---|---|---|---|
| sunny | hot | high | FALSE | no |
| sunny | hot | high | TRUE | no |
| sunny | mild | high | FALSE | no |
| sunny | cool | normal | FALSE | yes |
| sunny | mild | normal | TRUE | yes |
| outlook | temperature | humidity | windy | play |
|---|---|---|---|---|
| overcast | mild | high | TRUE | yes |
| overcast | hot | normal | FALSE | yes |
| overcast | cool | normal | TRUE | yes |
| overcast | hot | high | FALSE | yes |
| outlook | temperature | humidity | windy | play |
|---|---|---|---|---|
| rainy | mild | high | TRUE | no |
| rainy | mild | normal | FALSE | yes |
| rainy | mild | high | FALSE | yes |
| rainy | cool | normal | FALSE | yes |
| rainy | cool | normal | TRUE | no |
当子节点只有一种 l a b e l label label时分类结束。若子节点不止一种 l a b e l label label,此时再按上面的方法选用其他的属性继续分类,直至结束。
3.ID3算法总结
I G ( S ∣ t ) = E n t r o p y ( S ) − ∑ v a l u e ( T ) ∣ S v ∣ S E n t r o p y ( S v ) IG(S|t)=Entropy(S)−∑_{value(T)}\frac{|Sv|}{S}Entropy(Sv) IG(S∣t)=Entropy(S)−value(T)∑S∣Sv∣Entropy(Sv)
IG: Information Gain(信息增益)
其中 S S S为全部样本集合, v a l u e ( T ) value(T) value(T)属性 T T T的所有取值集合, v v v是 T T T的其中一个属性值, S v S_v Sv是 S S S中属性 T T T的值为 v v v的样例集合, ∣ S v ∣ |Sv| ∣Sv∣为 S v S_v Sv中所含样例数。在决策树的每一个非叶子结点划分之前,先计算每一个属性所带来的信息增益,选择最大信息增益的属性来划分,因为信息增益越大,区分样本的能力就越强。
注意: ID3只能正对nominal attribute,即标称属性
ID3算法有几个缺点:
- 对于具有很多值的属性它是非常敏感的,例如,如果我们数据集中的某个属性值对不同的样本基本上是不相同的,甚至更极端点,对于每个样本都是唯一的,如果我们用这个属性来划分数据集,它会得到很大的信息增益,但是,这样的结果并不是我们想要的。
- ID3算法不能处理具有连续值的属性。
- ID3算法不能处理属性具有缺失值的样本。
由于按照上面的算法会生成很深的树,所有容易产生过拟合现象。
本文参考以下文章:
- https://blog.csdn.net/xlinsist/article/details/51468741
- https://blog.csdn.net/sinat_26917383/article/details/47617801