(教妹学数据库系统)(十二)故障恢复
hello大家好,好久不见!今天我们继续学习《教妹学数据库系统》。教妹学数据库,没见过这么酷炫的标题吧?“语不惊人死不休”,没错,标题就是这么酷炫。
我的妹妹小埋18岁,校园中女神一般的存在,成绩优异体育万能,个性温柔正直善良。然而,只有我知道,众人眼中光芒万丈的小埋,在过去是一个披着仓鼠斗篷,满地打滚,除了吃就是睡和玩的超级宅女。而这一切的转变,是从那一天晚上开始的。
从此之后,小埋经常让我帮她辅导功课。今天她想了解数据库系统中的故障恢复。本篇教程通过我与小埋的对话的方式来谈一谈故障恢复。
故障恢复(failure recovery)
故障发生后,DBMS将数据库恢复到最新的一致性状态
故障(Failure)的类型
事务故障
逻辑错误(LogicalErrors)
- 事务由于内部错误(internalerror)而无法完成,如违反完整性约束(integrityconstraint)
内部状态错误(InternalStateErrors)
- DBMS由于内部状态错误(如死锁)而必须中止活跃事务(activetxn)
系统故障(SystemFailures)
软件故障(SoftwareFailures)
- DBMS实现的bug所导致的故障
硬件故障(HardwareFailures)
-
运行DBMS的计算机发生崩溃(crash),如断电
-
假设系统崩溃不会损坏非易失存储器中的数据
存储介质故障(StorageMediaFailures)
非易失存储器发生故障,损坏了存储的数据
假设数据损坏可以被检测,如使用校验码(checksum)
任何DBMS都无法从这种故障中恢复,必须从备份(archive)中还原(restore)
Buffer Pool Policies
DBMS在故障恢复时会做2种操作
撤销(Undo)
- Undo未完成事务(incomplete txn)对数据库的修改
重做(Redo)
- Redo已提交事务(committed txn)对数据库的修改
DBMS如何支持undo和redo取决于DBMS如何管理缓冲池(bufferpool)
STEAL策略
DBMS是否允许将未提交事务所做的修改写到磁盘并覆盖现有数据?
- STEAL:允许
- NO-STEAL:不允许
FORCE策略
DBMS是否要求事务在提交前必须将其所做的修改全部写回磁盘?
- FORCE:要求
- NO-FORCE:不要求
缓冲池策略(Buffer Pool Policies)

例如:NO-STEAL+FORCE
shadow paging
NO-STEAL ⇒ 未提交事务不可能将其修改写回磁盘 ⇒ 无需undo
FORCE ⇒ 已提交事务已将其修改全部写回磁盘 ⇒ 无需redo
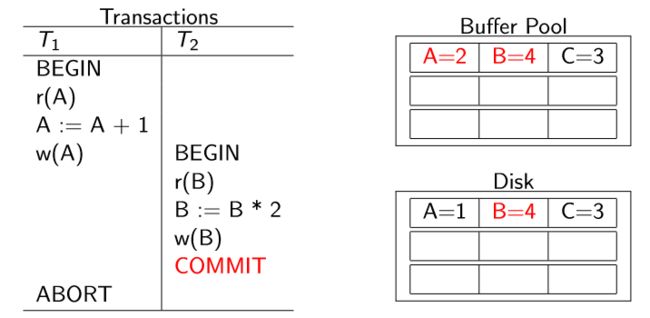
优点: 实现简单
缺点: 缓冲池得能存得下所有未提交事务所做的修改
Write-Ahead Logging(WAL)
预写式日志(WAL)
DBMS在数据文件(datafile)之外维护一个日志文件(logfile),用于记录事务对数据库的修改。
-
假定日志文件存储在稳定存储器(stable stroage)中
-
日志记录(log record)包含undo或redo时所需的信息
DBMS在将修改过的的对象写到磁盘之前,必须先将修改此对象的日志记录刷写到磁盘。
WAL协议(WAL Protocol)
当事务Ti启动时,向日志中写入记录
- tid:Ti的ID(txn ID)
当Ti提交时,向日志中写入记录
- 在DBMS向应用程序返回确认消息之前,必须保证Ti的所有日志记录都已刷写到磁盘
当Ti修改对象A时,向日志中写入记录
- oid:A的ID(object ID)
- before:A修改前的值(undo时用)
- after:A修改后的值(redo时用)
基于WAL的故障恢复
第1部分:事务正常执行时的行为
-
记录日志
-
按照缓冲池策略将修改过的对象写到磁盘
第2部分: 故障恢复时的行为
- 根据日志和缓冲池策略,对事务进行undo或redo
根据日志的事务分类
根据日志将事务分为3类
已提交事务(Committed Txn)
- 既有
不完整事务(Incomplete Txn)
- 只有
已中止事务(AbortedTxn)
-
既有
-
在事务正常执行和故障恢复过程中,如果T所做的修改已全部撤销,则将日志记录
-
已中止事务相当于从未执行过,故不需要undo,更不需要redo
WAL协议的分类
根据缓冲池策略的不同,可以实现3类WAL协议
-
UndoLogging: WAL+STEAL+FORCE
-
RedoLogging: WAL+NO-STEAL+NO-FORCE
-
Redo+UndoLogging: WAL+STEAL+NO-FORCE

WAL Undo Logging
基于Undo Logging的事务正常执行时的行为
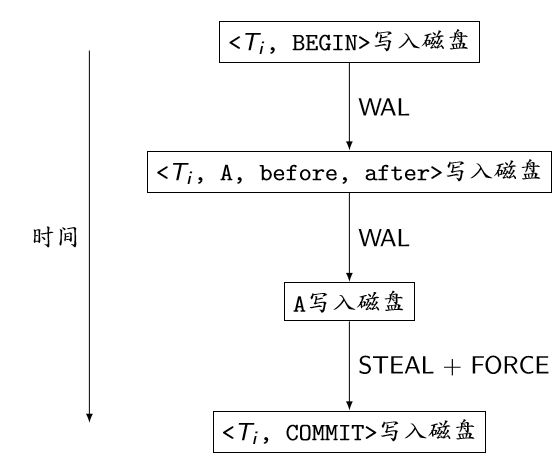

基于Undo Logging的故障恢复
已提交事务(Committed Txn): 不需要恢复
- FORCE=⇒已提交事务所做的修改已全部写入磁盘
不完整事务(Incomplete Txn): 全部undo
- STEAL=⇒不完整事务所做的一部分修改可能已经写入磁盘
从后(最后一条记录)向前(第一条记录)扫描日志。根据每条日志记录的类型执行相应的动作。


WAL Redo Logging

事务正常执行时的行为
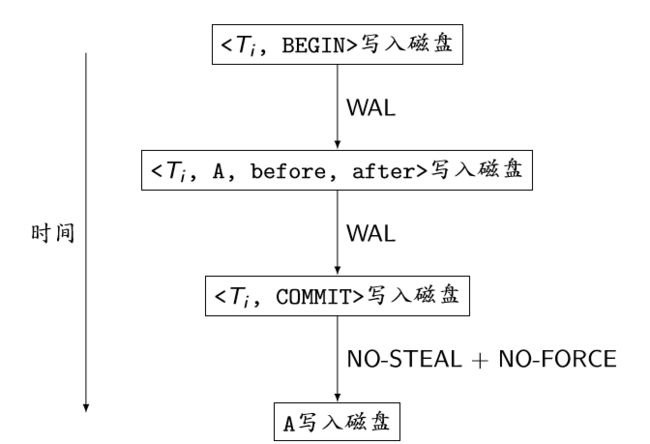

基于Redo Logging的事务正常执行时的行为

基于Redo Logging的故障恢复
已提交事务(CommittedTxn): 全部redo
- NO-FORCE ⇒ 已提交事务所做的修改可能尚未全部写入磁盘
不完整事务(IncompleteTxn): 不需要恢复
- NO-STEAL ⇒ 不完整事务所做的任何修改都未写入磁盘




WAL Redo+Undo Logging


已提交事务(CommittedTxn): 全部redo
- NO-FORCE ⇒ 已提交事务所做的修改可能尚未全部写入磁盘
不完整事务(IncompleteTxn): 全部undo
- STEAL ⇒ 不完整事务所做的一部分修改可能已经写入磁盘
基于Redo+UndoLogging的故障恢复方法
Redo阶段: redo已提交事务
- 与基于RedoLogging的故障恢复方法相同
Undo阶段: undo不完整事务
- 与基于UndoLogging的故障恢复方法相同
先redo,再undo



缓冲池策略的比较

组提交(GroupCommit)
每条日志记录单独刷写(flush)到磁盘的I/O开销太大。
在内存中设置日志缓冲区(logbuffer),将日志记录写到日志缓冲区,然后成批刷写到日志文件。
- 日志缓冲区满时刷写
- 定时刷写
Checkpoints
- WAL的问题
- 日志永远在变大
- 故障恢复时需要扫描日志,恢复时间越来越长
- 检查点(Checkpoints)
DBMS定期设置检查点(checkpoint)
- 将日志刷写到磁盘
- 根据缓冲池策略,将脏页(dirtypage)写到磁盘
- 故障恢复时只需扫描到最新的检查点
- 模糊检查点(FuzzyCheckpoints)
检查点开始: 向日志中写入
- T1,T2,…,Tn是检查点开始时的活跃事务(active txn)
- 活跃事务是尚未提交或中止的事务
检查点中间: 根据缓冲池策略,将脏页(dirtypage)写到磁盘
- 如果采用STEAL,则将全部脏页写到磁盘
- 否则,只将已提交事务所做的修改写到磁盘
检查点结束: 向日志中写入,并将日志刷写到磁盘
- 如果采用NO-FORCE,则写完全部脏页后即可结束检查点
- 否则,在T1,T2,…,Tn全部提交后,才能结束检查点
Redo阶段
不完整的检查点只有开始没有结束,在检查点的过程中遇到系统故障,是无用的。
日志中最新的完整检查点
<BEGINCHECKPOINT(T1,T2,...,Tn)>
...
< ENDCHECKPOINT >
需要redo的最早的事务一定属于{T1,T2,…,Tn}。
从日志记录



Undo阶段
日志中最新的完整检查点
<BEGINCHECKPOINT(T1,T2,...,Tn)>
...
<ENDCHECKPOINT>
需要undo的最早的事务一定属于{T1,T2,…,Tn}。
扫描到T1,T2,…,Tn中最早的事务Ti的日志记录

总结
咱们玩归玩,闹归闹,别拿学习开玩笑。
本篇介绍了故障恢复,缓冲池策略、WAL协议和检查点。最常用的缓冲池策略是STEAL+NOFORCE,学习时要加深理解和记忆。