综述:最大池化,平均池化,全局最大池化和全局平均池化?区别原来是这样
综述:最大池化,平均池化,全局最大池化和全局平均池化?区别原来是这样
摘要
创建ConvNets通常与池化层并驾齐驱。更具体地说,我们经常看到其他层,例如最大池化。但是他们是什么?为什么有必要,以及它们如何帮助训练机器学习模型?以及如何使用它们?
我们在此博客文章中回答这些问题。
首先,我们将从概念层面看一下池化操作。我们探索了ConvNet的内部工作原理,并通过此分析显示了合并层如何帮助这些模型中生成的空间层次结构。然后,我们继续确定池的四种类型-最大池化,平均池化,全局最大池化和全局平均池化。
随后,我们从理论转向实践:我们展示池化如何在Keras(当今最广泛使用的深度学习框架)中表示。然后,我们通过基于MaxPooling的示例来结束本博客。
什么是池化?
假设您正在训练卷积神经网络。您的目标是对数据集中的图像进行分类。由您的神经网络中的第一卷积层执行的操作可以表示如下:
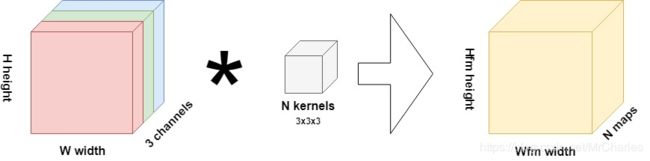
该层的输入是图像,高度为 H,宽度 w ^并具有三个渠道。因此,它们很可能是RGB图像。使用3x3x3内核,对输入图像执行卷积运算,生成N所谓的“特征图”的大小 H f m × W f m H_{f m} \times W_{f m} Hfm×Wfm。一个特征图学习图像中存在的一个特定特征。通过激活,这些特征图有助于训练过程中的结果预测以及新数据的预测。N可以在开始训练过程之前由机器学习工程师进行配置。
在上述示例的情况下,图像为32 x 32像素,第一个卷积操作(假设步长为1,无任何填充)将生成30 x 30像素的特征图;说我们设置N= 64,则将在第一层中生成64个此类地图。
对输入进行下采样
现在让我们退后一步,想一想成功训练ConvNet所要实现的目标。假设我们有一个图像分类器,其主要目标是正确分类图像。
如果我们像人类那样去做,那么我们将同时关注细节和高级模式。
现在,让我们再次看一下特征图的概念。在第一层中,您将基于图像的“具体”方面学习特征图。在此,特征图由图像中的非常低级的元素组成,例如曲线和边缘,也称为细节。但是,我们看不到只有一个卷积层的高级模式。我们需要很多人一起学习这些模式。这也称为建立空间层次结构(Chollet,2017)。良好的空间层次结构从下到上移动时基本上可以汇总数据,就像金字塔一样。这是一个好人与一个坏人:

好的空间层次结构(左)与较差的空间层次结构(右)。
如您所知,在ConvNet的卷积操作中,有一个小块在整个输入图像上滑动,并对当前滑动的图像部分进行逐元素乘法运算(Chollet,2017)。这是一个相对昂贵的操作。难道不能以更简单的方式做到这一点吗?我们真的需要仅由卷积建立层次结构吗?答案是否定的,池化操作证明了这一点。
引入池化
这是池化的一种定义:
池化基本上是“downscaling”从先前图层获得的图像。可以将其与缩小图像以减小其像素密度进行比较。
好吧,缩小比例。但这也可以通过更简单的方式完成:通过执行诸如的硬编码张量操作max,而不是通过学习的变换,我们不需要学习权重的相对昂贵的操作(Chollet,2017)。这样,我们只需花费一小部分成本就能获得一个不错的,可能有用的空间层次结构。
在本博文的其余部分,我们介绍了四种类型的池化操作:
最大池化Max Pooling;
平均池化Average pooling;
全局最大池化Global max pooling;
全局平均池化Global average pooling.
让我们先来看一下Max Pooling。
最大池化
假设这是来自ConvNet的4 x 4像素特征图之一:
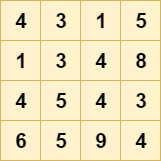
如果要对它进行降采样,则可以使用称为“最大池化”的池化操作(更具体地说,这是二维最大池化)。在此合并操作中,H× W “块”滑过输入数据,其中 H 是高度和 w 宽度。步幅(即在滑动操作过程中步幅)通常等于池的大小,因此其作用等于减小高度和宽度。
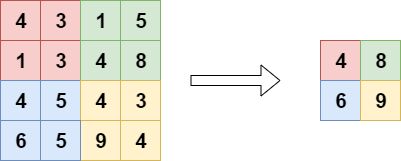
对于每个块或“池”,操作仅涉及计算max,像这样:

对每个池这样做,我们得到了很好的降采样结果,极大地受益于我们需要的空间层次结构:
Max Pooling如何帮助平移不变性
除了便宜地代替卷积层之外,最大池化在ConvNet中非常有用的另一个原因是:平移不变性。
当模型是平移不变的时,则意味着图片中的对象不在哪里都无关紧要;无论如何,它将被识别。例如,如果我将电话放在头部附近或口袋附近,则两次电话都应属于分类的同一个。
可以想象,在模型中实现平移不变性将极大地提高其预测能力,因为您不再需要提供对象恰好位于所需位置的图像。相反,您仅可以提供包含对象的大量图像,并可能获得性能良好的模型。
现在,最大池化如何在神经网络中实现平移不变性?
假设我们有一个1像素的对象,这有点奇怪,因为对象通常是多像素,但这对我们的解释很有帮助。该对象具有最高的对比度,因此会为输入图像中的像素生成较高的值。假设上图红色部分中(0,4)处的4是我们选择的像素。如我们所见,对于最大池化,它仍然包含在输出中。
现在,假设该对象(即4)不在(0,4),而是在(1,3)。它会从模型中消失吗?不会。最大池化层的输出仍将为4。因此,对象位于红色块中的位置并不重要,因为无论如何它都会被“捕获”。
这就是为什么最大池化意味着平移不变性,以及它真正有用的原因,除了相对便宜(计算少)之外。
如果对象是在任何非红色区域中,识别将会发生在那个地方,但只有当没有什么更大的像素值存在的情况下。因此,如果仅提供对象始终位于很小 区域的图片,则最大池化不会产生平移不变性。但是,如果您的数据集变化很大,并且对象位于不同的位置,则最大池化确实会真正有益于模型的性能。
为什么最大池化是最常用的池化操作
接下来,我们将看平均池化,这是另一个池化操作。它可以用作Max Pooling的直接替代。但是,当您查看神经网络理论(例如Chollet,2017)时,您会发现Max Pooling一直都是首选。
为什么会这样呢?
论点相对简单:由于感兴趣的对象可能会产生最大的像素值,因此在某个块中采用最大值比采用平均值会更有趣(Chollet,2017)。
糟糕,现在我已经放弃了平均池的功能
平均池化
池化层的另一种类型是平均池化层。这里,计算每个块的avg而不是max:

如您所见,输出也有所不同-与“最大池化”相比,不是那么极端了:

平均池与最大池化的不同之处在于,它保留了有关块或池中“次重要”元素的大量信息。尽管“最大池化”只是通过选择最大值来丢弃它们,但“平均池化”将它们混合在一起。这在各种情况下有用,其中此类信息很有用。我们将在下一节中看到一个。
为什么要考虑平均池化?
在互联网上,可以找到许多赞成和反对平均池化的论点,通常建议采用最大池化作为替代方案。答案主要是解决上述差异。
例如:
因此,要回答您的问题,我认为平均池比最大池化没有任何明显的优势。但是,在某些情况下,最大池化过滤器中的方差不大,两个池化将给出相同的类型结果。但是在极端情况下,最大池化肯定会提供更好的结果。
但是也:
我还要增加一个论点–最大池化层在保留局部信息方面效果较差。
因此,唯一正确的答案是:它完全取决于您要解决的问题。
如果对象的位置不重要,则“最大池化”似乎是更好的选择。如果是这样,则使用平均池似乎可以实现更好的结果。
全局最大池化
池化层的另一种类型是全局最大池化层。在这里,我们将池大小设置为等于输入大小,以便max将整个输入的都计算为输出值(Dernoncourt,2017):

或者,以不同的方式可视化它:

全局池化可以在多种情况下使用。首先,它可用于减少某些卷积层输出的特征图的维数,以取代分类器中的Flattening甚至有时是Dense层(Christlein,2019)。此外,它还可以用于 word spotting(Sudholt&Fink,2016)。这是由于其允许检测噪声的特性,因此可以“大输出”(例如,上例中的值9)。但是,这也是全局最大池化的缺点之一,与常规方法一样,我们接下来将介绍全局平均池化。
全局平均池化
应用全局平均池化时,池大小仍设置为图层输入的大小,但取最大值而不是最大值:

或者,再次以不同的方式可视化时:

它们通常用于替换分类器中的全连接层或密集连接层。取而代之的是,模型以卷积层结束,该卷积层生成与目标类数量一样多的特征图,并对每个特征集应用全局平均池化,以便将每个特征图转换为一个值(Mudau,nd)。由于特征图可以识别输入数据中的某些元素,因此最后一层中的图可以有效地学习以“识别”该体系结构中特定类的存在。通过将由全局平均池化生成的值输入到Softmax激活函数中,您可以再次获得所需的多类概率分布。
而且,由于“分类器”对“特征提取器”的固有性(nativeness )(它们都是卷积的,而不是dense layer),这种方法可能会提高模型性能,并且由于没有参数需要学习,可用于减少过拟合.
Keras API中的池层
现在让我们看一下Keras如何在其API中表示池化层。
最大池化
Max Pooling具有一维,二维和三维形式(Keras,nd)。一维变量可以与Conv1D层一起使用,因此可以用于时间数据:
keras.layers.MaxPooling1D(pool_size=2, strides=None, padding='valid', data_format='channels_last')
在此,可以通过设置池大小为整数值pool_size,跨度和填充,并可以设置数据格式。使用大步None距pool_size(如果保留默认值,则为大步距),可以定义池在输入上“跳跃”多少;在默认情况下减半。使用填充时,如果由于池和输入大小之间的不兼容性而导致边缘保留下来,我们可能会考虑这些边缘。最后,数据格式告诉我们有关数据集的渠道策略(首先是渠道还是最后是渠道)的信息。
Max Pooling也可用于2D数据,可与Conv2D一起用于空间数据(Keras,nd):
keras.layers.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
该API确实非常相似,除了pool_size。可以将其定义为整数值(例如pool_size = 3),但将在(3, 3)内部将其转换为整数。显然,您也可以设置一个元组,从而在池的形状上具有更大的灵活性。
3D Max Pooling可用于空间或时空数据(Keras,nd):
keras.layers.MaxPooling3D(pool_size=(2, 2, 2), strides=None, padding='valid', data_format=None)
在这里,同样的情况适用于pool_size:它既可以设置为整数值,也可以设置为三维元组。
平均池化
对于平均池,该API与最大池化没有什么不同,因此,除了API表示法(Keras,nd)之外,我在这里不再重复其他内容:
keras.layers.AveragePooling1D(pool_size=2, strides=None, padding='valid', data_format='channels_last')
keras.layers.AveragePooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
keras.layers.AveragePooling3D(pool_size=(2, 2, 2), strides=None, padding='valid', data_format=None)
全局最大池化
由于全局池化的独特结构(池形状等于输入形状),它们在Keras API中的表示非常简单。例如,对于全局最大池化(Keras,nd):
keras.layers.GlobalMaxPooling1D(data_format='channels_last')
keras.layers.GlobalMaxPooling2D(data_format='channels_last')
keras.layers.GlobalMaxPooling3D(data_format='channels_last')
在这里,唯一要配置的是data_format,它告诉我们有关数据中维顺序的信息,可以是channels_last或channels_first。
全局平均池化
对于全局平均池化化(Keras,nd)可以观察到同样的情况:
keras.layers.GlobalAveragePooling1D(data_format='channels_last')
keras.layers.GlobalAveragePooling2D(data_format='channels_last')
keras.layers.GlobalAveragePooling3D(data_format='channels_last')
Keras的Conv2D和合并示例
现在我们知道了池化层以及它们在Keras中的表示方式,我们可以举个例子。在此示例中,我们将向您展示之前创建的模型,以展示稀疏分类交叉熵的工作原理。因此,在这里没有为您显示创建模型的所有步骤。
但是我们要做的是向您展示应用池化的片段。这里是:
# Create the model
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(no_classes, activation='softmax'))
本质上,这是我们模型的架构。使用Sequential API,您可以看到我们添加了Conv2D图层,然后添加了具有(2, 2)池大小的MaxPooling2D图层-每次都有效地将输入减半。有助于提高模型的泛化能力。
Charles@Sunway, 3rd, April,2020