python机器学习简易过程
python机器学习简易过程
-
明确目标(Ideation):明确想要去证明的问题,定义hypothesis
-
数据预处理(preprocess):处理错误数据;处理missing数据;处理量纲问题;处理数据组织格式;the level of the details 与当前问题不符
-
数据理解(exploration):发现各属性之间的关系;发现数据的分布;发现离群点;可视化数据
-
建立模型(modeling)
数据类型:1.Categorical :性别,血型,评级 等固定的具有某些可选项的属性 ,在pandas中使用Categoricals类型表示 2.Continuous:连续的变量,在pandas中 用integer float表示 3. 离散变量:number of business location ,number of children 4.时序数据:
1. pandas读取数据并清洗
data clean(Nan值和 单一值 重复数据和相关特征 )
- 通过hist查看不存在Nan值的数值特征是否使用mean值填充 进而判断是否应该使用mean填充(hist中尖锐峰值)
- 查看重复数据是否target相同 判断产生重复数据原因
- 使用drop_dumplicates 以及 trainData.T.drop_dumplicates删除关联特征 以及重复样本
- 查看数据是否shuffle 如果未经shuffle基本会存在leakage 查看方法为 绘制target 和target_mean 的曲线 观察不同样本的target 和target_mean的关系
train.isnull().any() 查看是否有NaN值
train.isnull().sum(axis=0) 查看每一列的NaN值
train.isnull().sum(axis=1) 查看每一行的NaN值
良/恶性肿瘤判断
读取数据:
data=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data')
从网站中读取数据,因为该网站数据默认没有数据头,读取结果展示前5行为
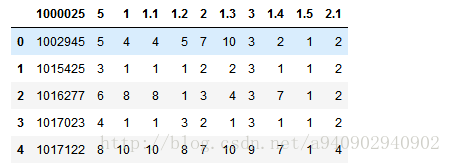
对此可以通过设置column_name
column_name=['Sample code number','Clump Thickness','Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Nomal Nucleoli','Mitoses','Class']
data=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data',names=column_name)

注:对于header属性有三种情况,当默认不设置header同时没有给出names的时候,默认第一行作为header,相当于header=0;当不设置header,同时给出names时,这是header的取值实际为header=null;当设置header=0,并且给出names值时,这是相当于原来数据有header,但是不使用原来的header名称,使用给出的names名称替换header名称。
可以看到在这里给数据加上了index,因为在pandas中假设文件中并没有特定的列是作为index而存在的,如果文件中存在index,可以通过index_col来设定。
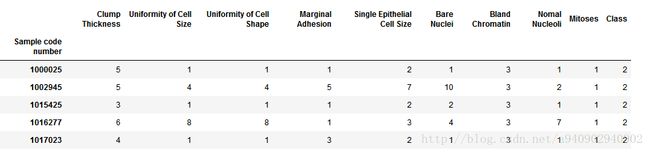
data=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data',names=column_name,index_col=0)
结果如下:
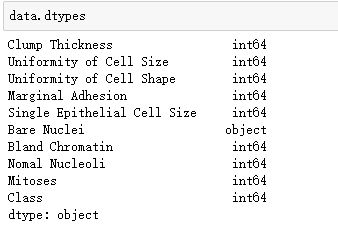
可以通过 data.dtypes查看数据的类型
如果默认类型与之后处理数据所需类型不同,则可在读取时指定数据类型
data=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data',names=column_name,index_col=0,dtype={'Bland Chromatin':np.int64})
如果数据本身具有header,那么在读取数据的时候需要设置header=0,如果不设置则pandas默认第一行就是数据。(在没有header的时候可以通过names属性设置,具有headers但是与我们的需求不符,也可设置header=0跳过header,同时设置names,重设header属性名)
很多时候在数据中存在采集不完整的情况,例如如果数据中未采集到的数据用?替代,在读入pandas后需要对这些数据进行处理。
data=data.replace(to_replace='?',value=np.nan)
将?全部替换成nan
data=data.dropna(how='any')
然后将出现nan值的所有条目都删除,dropna主要由两个属性 axis 以及 how,axis=0,表示删除行 axis=1表示删除列 how=any表示只要有就删除 how=all表示全部都是nan才删除。
###2.训练样本测试样本
from sklearn.cross_validation import train_test_split
X_train,X_test,Y_train,Y_test=train_test_split(data[column_name[1:10]],data[column_name[10]],test_size=0.25,random_state=33)
使用cross_validation进行训练样本和测试样本的划分
###3.样本预处理
# 从sklearn.preprocessing导入StandardScaler
from sklearn.preprocessing import StandardScaler
# 标准化数据,保证每个维度的特征数据方差为1,均值为0,使得预测结果不会被某些维度过大的特征值而主导
ss = StandardScaler()
# fit_transform()先拟合数据,再标准化
X_train = ss.fit_transform(X_train)
# transform()数据标准化
X_test = ss.transform(X_test)
这里说一下 fit_transform以及transform的区别
根据官方API

fit_transform其实是fit和transform两步的结合 首先计算出mean和std,然后正则化数据,而


其实就相当于第一步的fit_transform,更进一步可看如下例子:
data = [[0, 0], [0, 0], [1, 1], [1, 1]]
>>> scaler = StandardScaler()
>>> print(scaler.fit(data))
StandardScaler(copy=True, with_mean=True, with_std=True)
>>> print(scaler.mean_)
[ 0.5 0.5]
>>> print(scaler.transform(data))
[[-1. -1.]
[-1. -1.]
[ 1. 1.]
[ 1. 1.]]
>>> print(scaler.transform([[2, 2]]))
[[ 3. 3.]]
其实整个过程就是先fit获得数据的mean和std,然后利用这两个属性进行transform数据,而前文代码中之所以第一个使用fit_transform,第二个使用transform,是因为先对train用fit_transformer(),包括拟合fit找到xMin,xMax,再transform归一化根据train集合的xMin,xMax,对test集合进行归一化transform.
(如果test中的某个值比之前的xMin还要小,依然用原来的xMin;同理如果test中的某个值比之前的xMax还要大,依然用原来的xMax.所以,对test集合用同样的xMin和xMax,有可能不再映射到【0,1】)
#4.特征提取
特征提取就是逐条将原始数据转化为特征向量的形式,这个过程同时伴随着对数据特征的量化表示,原始数据的种类有很多种,除了数字化的信号数据,例如图像,还有很多符号化的文本数据,无法将符号化的文本直接进行计算任务。需要预先将文本量化为特征向量。有些符号表示的数据特征已经相对的结构化,对于这类数据可以使用DictVectorizer对特征进行抽取和量化。
以泰坦尼克号数据为例
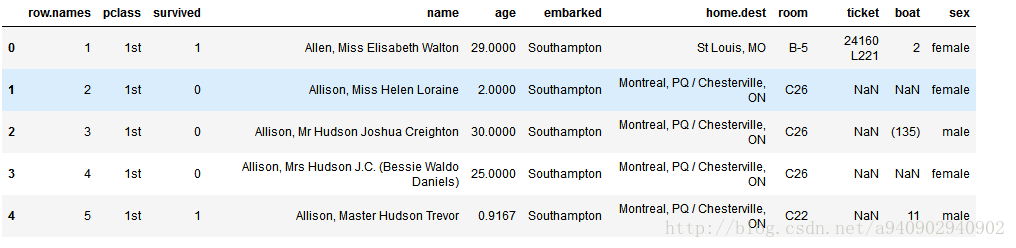
对该数据进行特征提取得到结果如下:

由此可见对于数值型的数据,其转化的vector依旧保持原始的label,而对于pclass这种string类型的数据,数据具有多少种可选结果 其vector就会对应多少个label,在这里被分程pclass=1st,pclass=2ed,pclass=3rd,同理对于sex也是如此。
再举一个例子,看看数据究竟发生了什么变化
measurements = [
... {'city': 'Dubai', 'temperature': 33.},
... {'city': 'London', 'temperature': 12.},
... {'city': 'San Francisco', 'temperature': 18.},
... ]
>>> from sklearn.feature_extraction import DictVectorizer
>>> vec = DictVectorizer()
>>> vec.fit_transform(measurements).toarray()
array([[ 1., 0., 0., 33.],
[ 0., 1., 0., 12.],
[ 0., 0., 1., 18.]])
vocabulary_ 属性表示label名称以及对应的位置
get_feature_names() 表示获取label名称
由此可以看出前三行分别是city=Dubai,city=London,city=San Francisco ,最后一行是temperature
注意,在这里的vec.fit_transform并没有将temperature进行正则化,

可以看出这个函数是建立建立数据的特征名到索引的映射并将数据进行转化,并不包含正则化的过程。