阿里开源通用算法平台 Alink!

整理 | 若名
出品 | AI科技大本营
近日,阿里云计算部门已在 GitHub 上发布了其 Alink 平台的“核心代码”,并上传了一系列算法库,它们支持批处理和流处理,这对支持机器学习任务至关重要。
Alink 是基于 Flink 的通用算法平台,由阿里巴巴计算平台 PAI 团队研发。除了支持阿里自己的平台外,还支持 Kafka,HDFS 和 HBase 等一系列开源数据存储平台。
阿里云计算和机器智能部门表示,开发者和数据分析师可以利用开源代码来构建软件功能,例如统计分析、机器学习、实时预测、个性化推荐和异常检测。而 Alink 提供的一系列算法,可以帮助处理机器学习任务,例如 AI 驱动的客户服务和产品推荐。
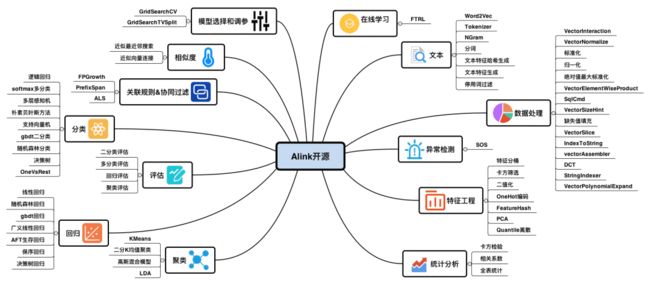
开源算法列表
阿里巴巴集团副总裁、阿里云智能计算平台事业部总裁、高级研究员贾扬清指出,对于寻求大数据和机器学习工具的开发人员而言,Alink 将是一个新的选择。
在他看来,作为中国企业是GitHub上十大贡献者之一,阿里致力于在软件开发周期中尽早与开源社区建立联系。而在 GitHub 上开源 Alink 遵循了这一承诺。
阿里目前已将 Alink 部署到其旗下电子商务平台天猫上。今年“双11”期间,单日数据处理量达到 970PB,每秒处理峰值数据高达 25 亿条,Alink 帮助天猫产品推荐的点击率提高了 4%。
迄今为止,阿里的开发人员在过去八年中为整个开源社区贡献了 180 多个项目,包括云基础架构、机器学习、数据库和网络。阿里巴巴的开放源代码计划包括基于 MySQL 的 AliSQL,容器工具 Pouch 和 JStorm(基于Java的 Apache Storm 版本)。

关于 Alink 的使用问题
Q:能否连接远程 Flink 集群进行计算?
A:通过方法可以连接一个已经启动的 Flink 集群:useRemoteEnv(host, port, parallelism, flinkHome=None, localIp="localhost", shipAlinkAlgoJar=True, config=None)。其中,参数:
-
host 和 port 表示集群的地址;
-
parallelism 表示执行作业的并行度;
-
flinkHome 为 flink 的完整路径,默认使用 PyAlink 自带的 flink-1.9.0 路径;
-
localIp 指定实现 Flink DataStream 的打印预览功能时所需的本机IP地址,需要 Flink 集群能访问。默认为localhost。
-
shipAlinkAlgoJar 是否将 PyAlink 提供的 Alink 算法包传输给远程集群,如果远程集群已经放置了 Alink 算法包,那么这里可以设为 False,减少数据传输。
Q:如何停止长时间运行的Flink作业?
A:使用本地执行环境时,使用 Notebook 提供的“停止”按钮即可。使用远程集群时,需要使用集群提供的停止作业功能。
Q:能否直接使用 Python 脚本而不是 Notebook 运行?
A:可以。但需要在代码最后调用 resetEnv(),否则脚本不会退出。

使用步骤
使用前准备
-
确保使用环境中有Python3,版本>=3.5;
-
需要根据 Python 版本下载对应的 pyalink 包(下载链接参见GitHub);
-
使用 easy_install 进行安装 easy_install [存放的路径]/pyalink-0.0.1-py3.*.egg。需要注意的是:
-
如果之前安装过 pyalink,请先使用 pip uninstall pyalink 卸载之前的版本。
-
如果有多个版本的 Python,可能需要使用特定版本的 easy_install,比如 easy_install-3.7。
-
如果使用 Anaconda,则需要在 Anaconda 命令行中进行安装。
开始使用
阿里推荐通过 Jupyter Notebook 来使用 PyAlink,能获得更好的使用体验。
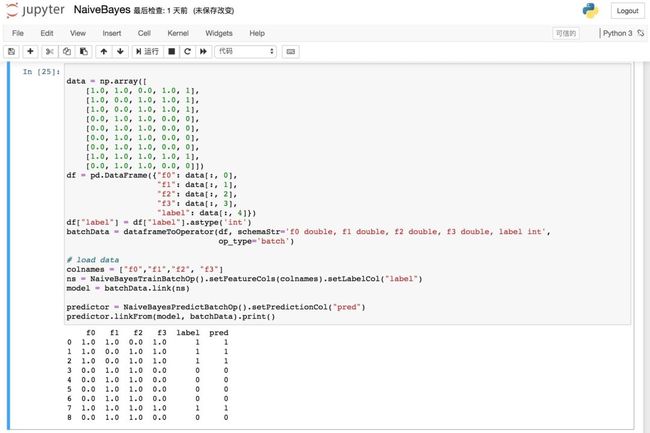
pyAlink
使用步骤
1、在命令行中启动Jupyter:jupyter notebook,并新建 Python 3 的 Notebook 。
2、导入 pyalink 包:from pyalink.alink import *。
3、使用方法创建本地运行环境:useLocalEnv(parallism, flinkHome=None, config=None)。其中,参数 parallism 表示执行所使用的并行度;flinkHome 为 flink 的完整路径,默认使用 PyAlink 自带的 flink-1.9.0 路径;config为Flink所接受的配置参数。运行后出现如下所示的输出,表示初始化运行环境成功:
JVM listening on ***
Python listening on ***
4.开始编写 PyAlink 代码,例如:
source = CsvSourceBatchOp()\
.setSchemaStr("sepal_length double, sepal_width double, petal_length double, petal_width double, category string")\
.setFilePath("http://alink-dataset.cn-hangzhou.oss.aliyun-inc.com/csv/iris.csv")
res = source.select("sepal_length", "sepal_width")
df = res.collectToDataframe()
print(df)编写代码
在 PyAlink 中,算法组件提供的接口基本与 Java API 一致,即通过默认构造方法创建一个算法组件,然后通过 setXXX 设置参数,通过 link/linkTo/linkFrom 与其他组件相连。这里利用 Jupyter 的自动补全机制可以提供书写便利。
对于批式作业,可以通过批式组件的 print/collectToDataframe/collectToDataframes 等方法或者 BatchOperator.execute() 来触发执行;对于流式作业,则通过 StreamOperator.execute() 来启动作业。

如何在集群上运行Alink算法?
1、准备Flink集群
wget https://archive.apache.org/dist/flink/flink-1.9.0/flink-1.9.0-bin-scala_2.11.tgz
tar -xf flink-1.9.0-bin-scala_2.11.tgz && cd flink-1.9.0
./bin/start-cluster.sh2、准备Alink算法包
git clone https://github.com/alibaba/Alink.git
cd Alink && mvn -Dmaven.test.skip=true clean package shade:shade
3、运行Java示例
./bin/flink run -p 1 -c com.alibaba.alink.ALSExample [path_to_Alink]/examples/target/alink_examples-0.1-SNAPSHOT.jar
# ./bin/flink run -p 2 -c com.alibaba.alink.GBDTExample [path_to_Alink]/examples/target/alink_examples-0.1-SNAPSHOT.jar
# ./bin/flink run -p 2 -c com.alibaba.alink.KMeansExample [path_to_Alink]/examples/target/alink_examples-0.1-SNAPSHOT.jar