Web基础配置篇(十二): Elasticsearch的安装配置及入门使用
Web基础配置篇(十二): Elasticsearch的安装配置及入门使用
一、概述
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
ES是ElasticSearch的缩写;
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。
一般公司都是用ELK做日志分析,社区搜索之类的,很少单独使用ElasticSearch。但是单独使用ElasticSearch也很广泛,没有ELK的时候都是这样玩的。
比如我的社区网站(https://www.pomit.cn)就用了ElasticSearch做社区搜索,一开始做搜索的时候,曾有三种方案:
-
Mysql的全文搜索,据说很慢,而且我的mysql版本也不支持中文,还要升级。
-
搜索引擎的支持,搜索引擎可以传入keyword、site对网站的某个网页做搜索,但是依赖于搜索引擎的收录情况。特别是百度渣渣,求它收录都难,必应还是蛮快的。但是都不够快。
-
ElasticSearch做社区搜索,需要安装ElasticSearch。用了一段时间,感觉还可以。
首发地址:
品茗IT-首先发布
如果大家正在寻找一个java的学习环境,或者在开发中遇到困难,可以加入我们的java学习圈,点击即可加入,共同学习,节约学习时间,减少很多在学习中遇到的难题。
二、ElasticSearch安装
2.1 下载ElasticSearch
-
elasticsearch可以在Elasticsearch官网 查看下载地址;这个是最新版本的地址。
-
往往我们要的并不是最新版本,可以找到
Not the version you're looking for? View past releases.,点击past releases,进入到这个页面:https://www.elastic.co/cn/downloads/past-releases;选择elasticsearch及版本:
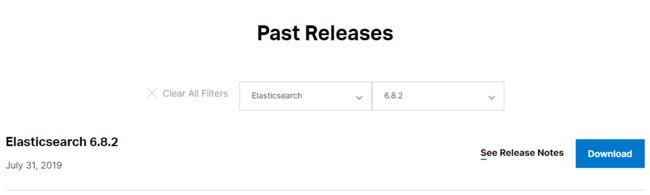
然后点击 Download,选择对应的系统,下载即可。
-
比如我windows下载的是elasticsearch-6.6.2.zip, Linux下载的是elasticsearch-6.6.2.tar.gz。
-
下载完成后,解压文件(window下用winrar/其他解压工具,linux下tar命令)并进入文件夹的bin目录下:
如图所示:

2.2 Windows启动elasticsearch
windows如果是测试就直接启动吧,无需像linux上配置那么多。但是我们用elasticsearch,基本上都是要用它的中文分词功能,所以我们先安装下ik插件吧。
2.2.1 ik分词器插件
进入到bin目录,打开powershell,运行(如果是cmd,就要用elasticsearch-plugin.bat):
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.6.2/elasticsearch-analysis-ik-6.6.2.zip
我这里使用的ik分词器版本是6.6.2,是和elasticsearch的版本一致的,注意下载分词器的版本必须要和elasticsearch的版本保持一致;根据需要可以将6.6.2改成自己elasticsearch的版本就可以使用。
如果这种方式安装太慢,或者失败,可以直接下载elasticsearch-analysis-ik-6.6.2.zip,解压后放到elasticsearch目录下的plugins目录下(我没这样子试),ik的插件是这样的,应该是把jar包都放到plugins下的analysis-ik目录。
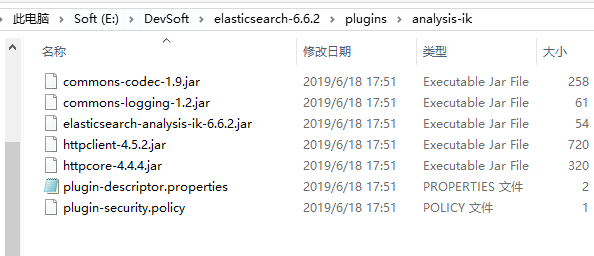
2.2.2 启动
打开powershell或者cmd,进入到elasticsearch的bin目录下,输入命令./elasticsearch:
然后它就运行起来了。
如果是cmd,可能要使用./elasticsearch.bat来运行。
elasticsearch默认在9200端口监听http请求:
-
9200作为Http协议,主要用于外部通讯
-
9300作为Tcp协议,jar之间就是通过tcp协议通讯
-
ES集群之间是通过9300进行通讯
2.3 Linux启动elasticsearch
linux启动类似于Windows上的安装,然而,elasticsearch不允许使用root用户启动,所以要新建个用户来运行elasticsearch。
2.2.1 新建用户
- 新建组:groupadd elsearch
- 新建用户:useradd elsearch -g elsearch
- 改变文件拥有者:chown -R elsearch:elsearch elasticsearch
- root修改elsearch用户密码:
passwd elsearch
2.2.2 ik分词器插件
进入到bin目录,运行:
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.6.2/elasticsearch-analysis-ik-6.6.2.zip
我这里使用的ik分词器版本是6.6.2,是和elasticsearch的版本一致的,注意下载分词器的版本必须要和elasticsearch的版本保持一致;根据需要可以将6.6.2改成自己elasticsearch的版本就可以使用。
如果这种方式安装太慢,或者失败,可以直接下载elasticsearch-analysis-ik-6.6.2.zip,unzip解压后放到elasticsearch目录下的plugins目录,我没这样子试,应该是把jar包都放到plugins下的analysis-ik目录。
2.2.3 启动
配置data路径和logs路径
先配置下elasticsearch的data路径和logs路径吧,也可以不配置,默认与bin目录同级,这样如果哪天你删掉了安装目录,数据文件和日志都丢了。你可以把这两个路径独立出去。
修改elasticsearch.yml文件:
path.data: /home/elsearch/elasticsearch/data/
path.logs: /home/elsearch/elasticsearch/log/
运行
进入到elasticsearch的bin目录下,输入命令./elasticsearch;
也可以用nohup ./elasticsearch &,让elasticsearch后台运行。
然后它就运行起来了。
修改运行参数
也有人说,运行不起来啊,那可能你像我一样都是穷人,用不起2G以上的内存,这时候要修改下elasticsearch目录下的jvm.options文件。
修改jvm.options, 修改-Xms和-Xmx,我这里都设置为512m:
-Xms512m
-Xmx512m
重新启动即可。
我的elasticsearch已经运行了很久了,没开fielddata的情况下,内存稳定在800m-900m之间,能正常进行搜索。
elasticsearch默认在9200端口监听http请求:
-
9200作为Http协议,主要用于外部通讯
-
9300作为Tcp协议,jar之间就是通过tcp协议通讯
-
ES集群之间是通过9300进行通讯
三、Elasticsearch使用
3.1 几个概念
3.1.1 Index
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
3.1.2 Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
3.1.3 Type
Document 可以分组, Type是虚拟的逻辑分组,用来过滤 Document。
Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
3.2 新建index和Type
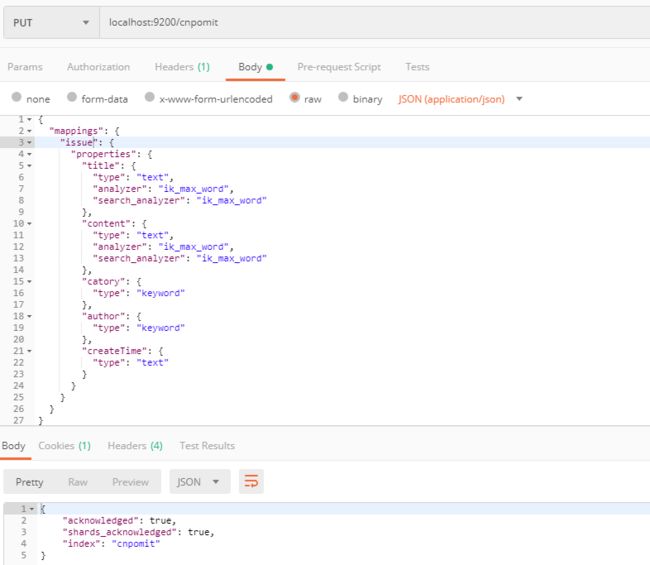
如果我们的Elasticsearch是开放的,那我们可以使用postman这种http工具去操作Elasticsearch。比如新建可以使用postman这样来新建index和type:
使用put请求Elasticsearch的地址,后面紧跟要建立的index:localhost:9200/cnpomit:
put报文体要用json发送:
{
"mappings": {
"issue": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"catory": {
"type": "keyword"
},
"open": {
"type": "integer"
},
"author": {
"type": "keyword"
},
"createTime": {
"type": "text"
}
}
}
}
}
这里的请求:
- type为issue;
- index为cnpomit;
- title和content字段使用ik做分词器;
- catory和author的类型是keyword,表示无需分词;
- open的类型是integer,表示是整型。
- createTime是文本。
请求结果如图所示:
如果不方便使用postman,比如线上的elasticsearch是不对外开放的,这时候可以使用curl来新建:
curl -H "Content-Type:application/json" -X PUT '127.0.0.1:9200/cnpomit' --data '
{
"mappings": {
"issue": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"catory": {
"type": "keyword"
},
"open": {
"type": "integer"
},
"author": {
"type": "keyword"
},
"createTime": {
"type": "text"
}
}
}
}
}
'
下面的请求就不指明使用的postman还是curl。
3.3 查看新建的index
使用get请求Elasticsearch的地址:localhost:9200/cnpomit,可以查看cnpomit的结构。
也可以使用localhost:9200/_mapping?pretty=true,查看所有的index。
3.4 修改index
如果我们建了index之后,发现少了某个字段,可以这样修改:
使用put请求Elasticsearch的地址:localhost:9200/cnpomit/_mapping/issue:
put报文体要用json发送:
{
"properties": {
"role": {
"type": "integer"
}
}
}
这里的请求,在cnpomit的issue里增加role字段。
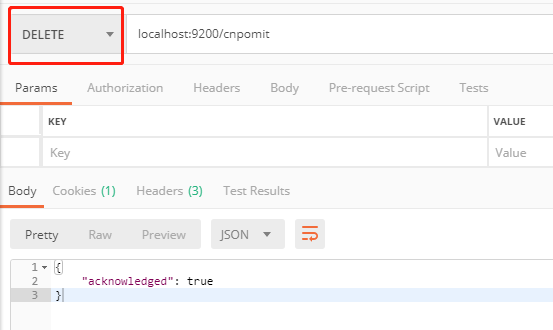
3.5 删除index
使用delete请求Elasticsearch的地址:localhost:9200/cnpomit,可以删除cnpomit, 慎用。
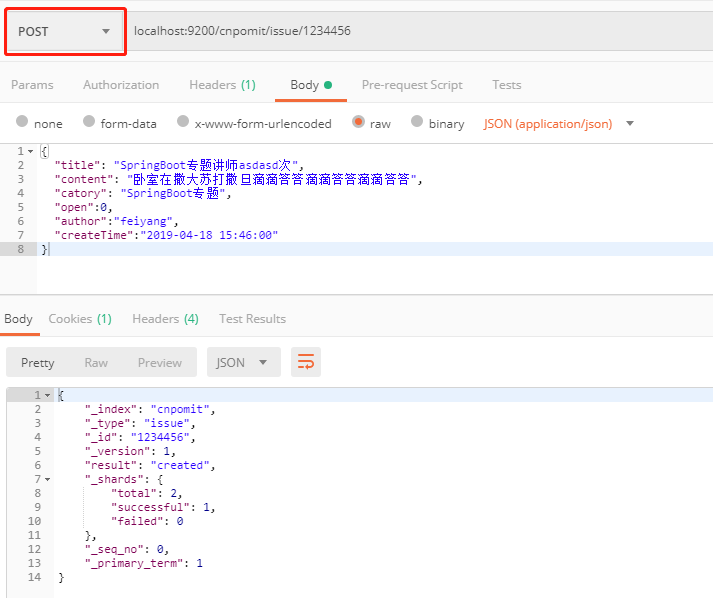
3.6 插入记录
使用post或者put请求Elasticsearch的地址:localhost:9200/cnpomit/issue/1234456:
post报文体要用json发送:
{
"title": "SpringBoot专题讲师asdasd次",
"content": "卧室在撒大苏打撒旦滴滴答答滴滴答答滴滴答答",
"catory": "SpringBoot专题",
"open":0,
"author":"feiyang",
"createTime":"2019-04-18 15:46:00"
}
这里的请求,是向cnpomit的issue里增加一条记录,这条记录:
- id是1234456。
- post报文体是内容。
如图所示:
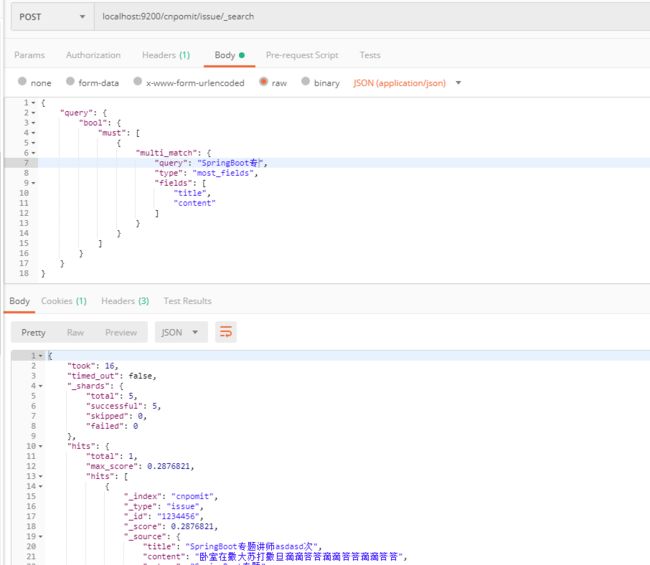
3.7 查看记录
使用get或者post请求Elasticsearch的地址:localhost:9200/cnpomit/issue/_search:
如果不带报文体,返回所有数据。如果携带报文体,则按照报文体的条件进行查看(Elasticsearch查询语法很多,按需去网站查就行了,Spring-data-elasticsearch提供了简单的查询的封装)。
如下图所示,查询title和content带“SpringBoot专”的结果:
报文体为:
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "SpringBoot专",
"type": "most_fields",
"fields": [
"title",
"content"
]
}
}
]
}
}
}
或者
{
"query": {
"multi_match": {
"query": "SpringBoot专",
"type": "most_fields",
"fields": [ "title", "content" ]
}
}
}
如果只是查询某个字段,分词不分词都行。可以这样写:
{
"query": {
"match": {
"author": "feiyang"
}
}
}
3.8 更新记录
和新建记录一样,之间修改内容,重发一遍即可。
3.9 删除记录
使用delete请求Elasticsearch的地址:localhost:9200/cnpomit/issue/1234456,可以删除1234456这条记录。注意,是delete请求。
品茗IT-博客专题:https://www.pomit.cn/lecture.html汇总了Spring专题、Springboot专题、SpringCloud专题、web基础配置专题。
快速构建项目
Spring项目快速开发工具:
一键快速构建Spring项目工具
一键快速构建SpringBoot项目工具
一键快速构建SpringCloud项目工具
一站式Springboot项目生成
Mysql一键生成Mybatis注解Mapper
Spring组件化构建
SpringBoot组件化构建
SpringCloud服务化构建
喜欢这篇文章么,喜欢就加入我们一起讨论Java Web吧!
