【机器学习基础】数学推导+纯Python实现机器学习算法5:决策树之CART算法
目录
CART概述
回归树
分类树
剪枝
Python实现示例:分类树
在数学推导+纯Python实现机器学习算法4:决策树之ID3算法中笔者已经对决策树的基本原理进行了大概的论述。本节将在上一讲的基础上继续对另一种决策树算法CART进行讲解。
CART概述
所谓CART算法,全名叫Classification and Regression Tree,即分类与回归树。顾名思义,相较于此前的ID3算法和C4.5算法,CART除了可以用于分类任务外,还可以完成回归分析。完整的CART算法包括特征选择、决策树生成和决策树剪枝三个部分。
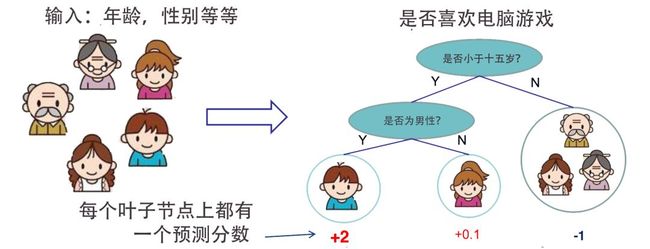
CART是在给定输入随机变量X条件下输出随机变量Y的条件概率分布的学习方法。CART算法通过选择最优特征和特征值进行划分,将输入空间也就是特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出条件概率分布。
CART算法主要包括回归树和分类树两种。回归树用于目标变量为连续型的建模任务,其特征选择准则用的是平方误差最小准则。分类树用于目标变量为离散型的的建模任务,其特征选择准则用的是基尼指数(Gini Index),这也有别于此前ID3的信息增益准则和C4.5的信息增益比准则。无论是回归树还是分类树,其算法核心都在于递归地选择最优特征构建决策树。
除了选择最优特征构建决策树之外,CART算法还包括另外一个重要的部分:剪枝。剪枝可以视为决策树算法的一种正则化手段,作为一种基于规则的非参数监督学习方法,决策树在训练很容易过拟合,导致最后生成的决策树泛化性能不高。
另外,CART作为一种单模型,也是GBDT的基模型。当很多棵CART分类树或者回归树集成起来的时候,就形成了GBDT模型。关于GBDT,笔者将在后续中进行详细讲述,这里不再展开。
回归树
给定输入特征向量X和输出连续型变量Y,一个回归树的生成就对应着输入空间的一个划分以及在划分的单元上的输出值。假设输入空间被划分为M个单元R1,R2…,RM,在每一个单元Rm上都有一个固定的输出值Cm,所以回归树模型可以表示为
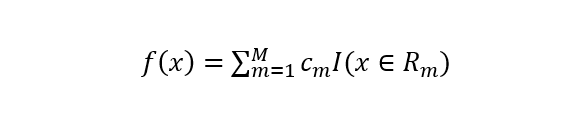
在输入空间划分确定时,回归树算法使用最小平方误差准则来选择最优特征和最优且切分点。具体来说就是对全部特征进行遍历,按照最小平方误差准则来求解最优切分变量和切分点。即求解如下公式
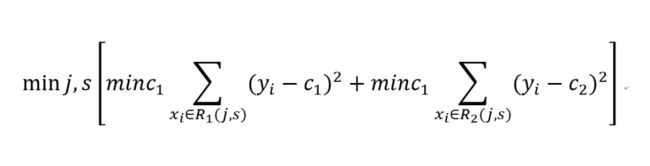
这种按照最小平方误差准则来递归地寻找最佳特征和最优切分点构造决策树的过程就是最小二乘回归树算法。
完整的最小二乘回归树生成算法如下:(来自统计学习方法)

最小二乘回归树拟合数据如下图所示。可以看到,回归树的树深度越大的情况下,模型复杂度越高,对数据的拟合程度就越好,但相应的泛化能力就得不到保证。

分类树
CART分类树跟回归树大不相同,但与此前的ID3和C4.5基本套路相同。ID3和C4.5分别采用信息增益和信息增益比来选择最优特征,但CART分类树采用Gini指数来进行特征选择。先来看Gini指数的定义。
Gini指数是针对概率分布而言的。假设在一个分类问题中有K个类,样本属于第k个类的概率为Pk,则该样本概率分布的基尼指数为
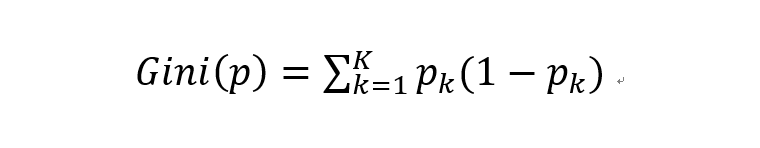
具体到实际的分类计算中,给定样本集合D的Gini指数计算如下
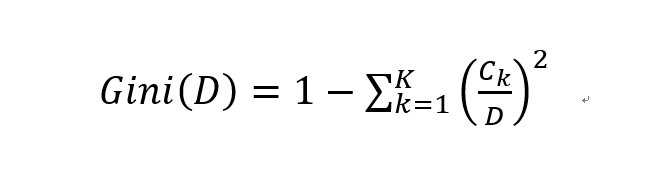
相应的条件Gini指数,也即给定特征A的条件下集合D的Gini指数计算如下

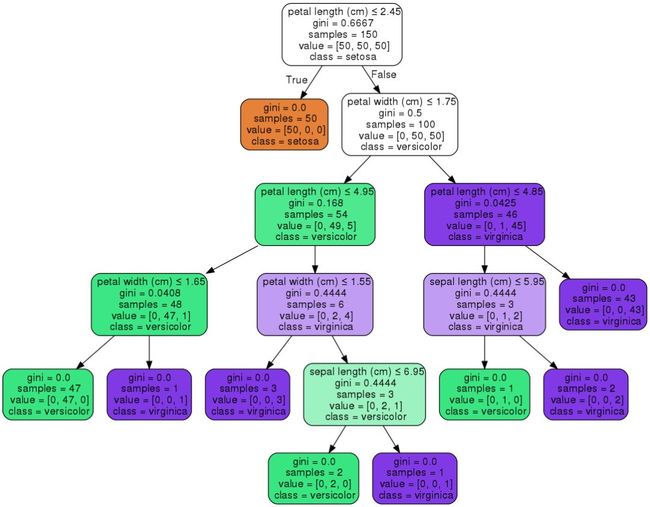
实际构造分类树时,选择条件Gini指数最小的特征作为最优特征构造决策树。完整的分类树构造算法如下:(来自统计学习方法)

一棵基于Gini指数准则选择特征的分类树构造:
剪枝
基于最小平方误差准则和Gini指数准则构造好决策树只能算完成的模型的一半。为了构造好的决策树能够具备更好的泛化性能,通过我们需要对其进行剪枝(pruning)。在特征选择算法效果趋于一致的情况下,剪枝逐渐成为决策树更为重要的一部分。
所谓剪枝,就是将构造好的决策树进行简化的过程。具体而言就是从已生成的树上裁掉一些子树或者叶结点,并将其根结点或父结点作为新的叶结点。
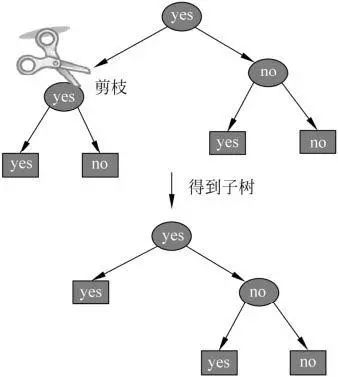
通常来说,有两种剪枝方法。一种是在决策树生成过程中进行剪枝,也叫预剪枝(pre-pruning)。另一种就是前面说的基于生成好的决策树自底向上的进行剪枝,又叫后剪枝(post-pruning)。
先来看预剪枝。预剪枝是在树生成过程中进行剪枝的方法,其核心思想在树中结点进行扩展之前,先计算当前的特征划分能否带来决策树泛化性能的提升,如果不能的话则决策树不再进行生长。预剪枝比较直接,算法也简单,效率高,适合大规模问题计算,但预剪枝可能会有一种”早停”的风险,可能会导致模型欠拟合。
后剪枝则是等树完全生长完毕之后再从最底端的叶子结点进行剪枝。CART剪枝正是一种后剪枝方法。简单来说,就是自底向上对完全树进行逐结点剪枝,每剪一次就形成一个子树,一直到根结点,这样就形成一个子树序列。然后在独立的验证集数据上对全部子树进行交叉验证,哪个子树误差最小,哪个就是最优子树。具体细节可参考统计学习方法给出的剪枝算法步骤,笔者这里不深入展开公式。

Python实现示例:分类树
根据上一节ID3决策树的代码形式,笔者继续以CART分类树为例进行实现。
首先定义Gini指数的计算函数:
def gini(nums):
probs = [nums.count(i)/len(nums) for i in set(nums)]
gini = sum([p*(1-p) for p in probs]) return gini
读入数据并计算标签的Gini指数:
df = pd.read_csv('./example_data.csv', dtype={'windy': 'str'})
gini(df['play'].tolist())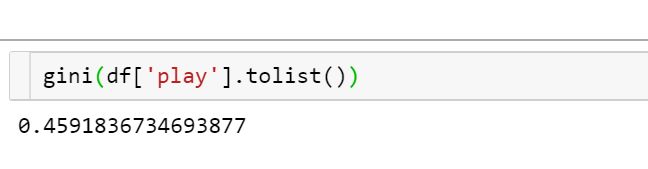
定义根据特征分割数据框的函数:
def split_dataframe(data, col):
'''
function: split pandas dataframe to sub-df based on data and column.
input: dataframe, column name.
output: a dict of splited dataframe.
'''
# unique value of column
unique_values = data[col].unique() # empty dict of dataframe
result_dict = {elem : pd.DataFrame for elem in unique_values} # split dataframe based on column value
for key in result_dict.keys():
result_dict[key] = data[:][data[col] == key] return result_dict
根据温度特征对数据进行划分: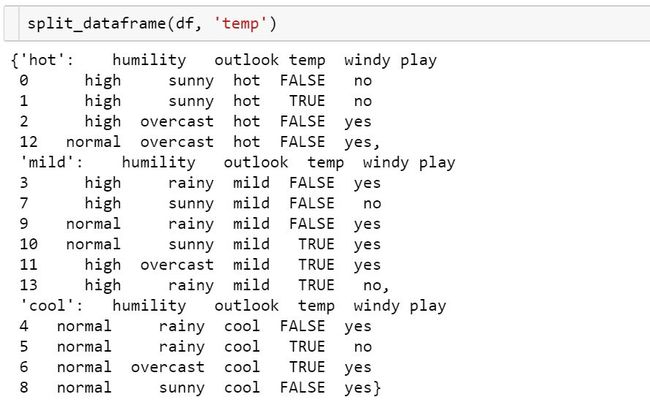
然后根据Gini指数和条件Gini指数计算递归选择最优特征,定义函数如下:
def choose_best_col(df, label):
'''
funtion: choose the best column based on infomation gain.
input: datafram, label
output: max infomation gain, best column,
splited dataframe dict based on best column.
'''
# Calculating label's gini index
gini_D = gini(df[label].tolist()) # columns list except label
cols = [col for col in df.columns if col not in [label]] # initialize the max infomation gain, best column and best splited dict
min_value, best_col = 999, None
min_splited = None
# split data based on different column
for col in cols:
splited_set = split_dataframe(df, col)
gini_DA = 0
for subset_col, subset in splited_set.items(): # calculating splited dataframe label's gini index
gini_Di = gini(subset[label].tolist()) # calculating gini index of current feature
gini_DA += len(subset)/len(df) * gini_Di if gini_DA < min_value:
min_value, best_col = gini_DA, col
min_splited = splited_set return min_value, best_col, min_splited
计算示例如下:

最后定义CART分类树的构建过程:
class CartTree:
# define a Node class
class Node:
def __init__(self, name):
self.name = name
self.connections = {}
def connect(self, label, node):
self.connections[label] = node
def __init__(self, data, label):
self.columns = data.columns
self.data = data
self.label = label
self.root = self.Node("Root")
# print tree method
def print_tree(self, node, tabs):
print(tabs + node.name)
for connection, child_node in node.connections.items():
print(tabs + "\t" + "(" + connection + ")")
self.print_tree(child_node, tabs + "\t\t")
def construct_tree(self):
self.construct(self.root, "", self.data, self.columns)
# construct tree
def construct(self, parent_node, parent_connection_label, input_data, columns):
min_value, best_col, min_splited = choose_best_col(input_data[columns], self.label)
if not best_col:
node = self.Node(input_data[self.label].iloc[0])
parent_node.connect(parent_connection_label, node)
return
node = self.Node(best_col)
parent_node.connect(parent_connection_label, node)
new_columns = [col for col in columns if col != best_col]
# Recursively constructing decision trees
for splited_value, splited_data in min_splited.items():
self.construct(node, splited_value, splited_data, new_columns)执行代码生成CART分类树:

以上就是CART分类树的构建过程,关于CART后剪枝算法部分的实现笔者后续会继续在GitHub上更新,完整代码文件和数据可参考我的GitHub地址:
https://github.com/luwill/machine-learning-code-writing
参考资料:
李航 统计学习方法
https://github.com/heolin123/id3/blob/master
往期精彩:
数学推导+纯Python实现机器学习算法3:k近邻
数学推导+纯Python实现机器学习算法2:逻辑回归
数学推导+纯Python实现机器学习算法1:线性回归

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑获取一折本站知识星球优惠券,复制链接直接打开:https://t.zsxq.com/yFQV7am本站qq群1003271085。加入微信群请扫码进群: