淘淘商城20_redis的使用02_redis集群的搭建
1. 集群原理
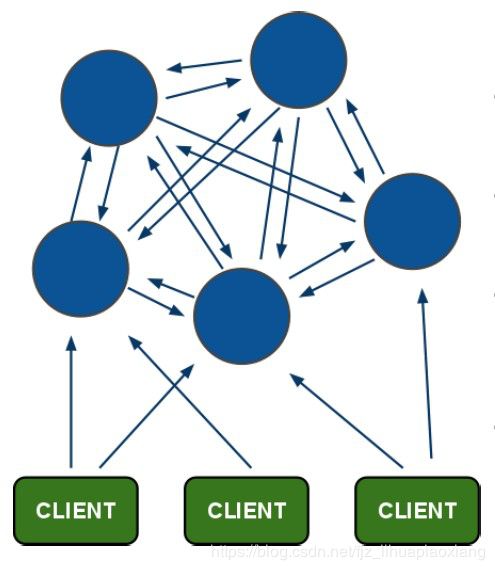
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
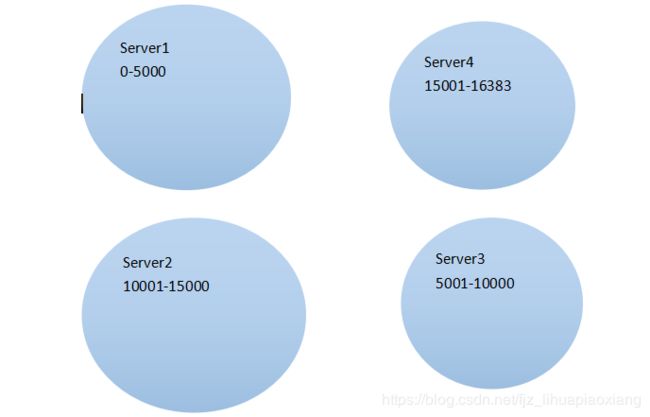
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
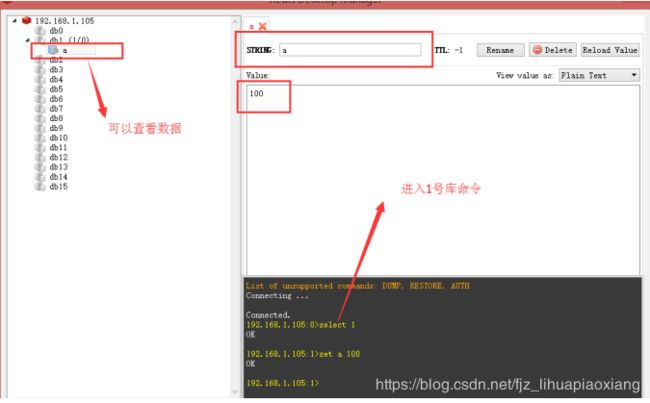
Key:a
计算a的hash值,例如值为100,100这个槽在server1上,所以a应该放到server1.
Key:hello
计算hello的Hash值:10032,此槽在server2上。Hell可以应该存在server2.
2. redis-cluster投票:容错
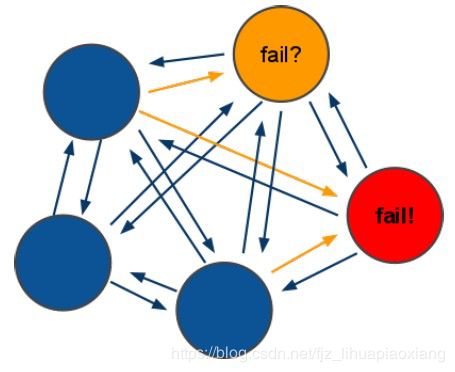
当半数以上的节点挂掉后,从节点就会接手主节点工作,等主节点修好后,从节点继续作为备用
(1)领着投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail)?
a:如果集群任意master挂掉,且当前master(主)没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态. ps : redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败.
b:如果集群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
ps:当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
3. 创建集群
创建有三个节点的集群:有两个节点挂掉才算是超过半数,这三个节点每个节点得有一主一备。需要6台虚拟机。
搭建一个伪分布式的集群,使用6个redis实例来模拟。
3.1 ruby环境
搭建集群环境需要使用到官方提供的ruby脚本。需要安装ruby环境
安装ruby:
yum install ruby
yum install rubygems(包管理工具)
3.2 redis集群管理工具redis-trib.rb依赖ruby环境
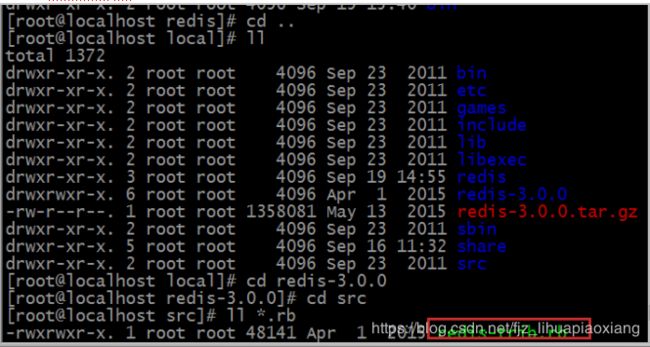
找到redis-trib.rb,这个文件在redis的源码包里,通过下面命令找到
[root@localhost local]# cd redis-3.0.0
[root@localhost redis-3.0.0]# cd src
[root@localhost src]# ll *.rb
[root@localhost src]#
3.3 安装ruby和redis的接口程序
拷贝redis-3.0.0.gem至/usr/local下,这个文件是运行redis-trib.rb文件的ruby包
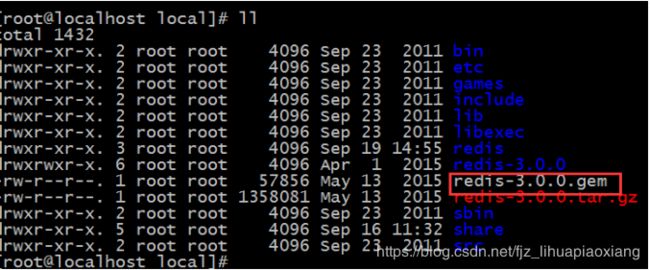
执行:在该目录下执行
gem install redis-3.0.0.gem
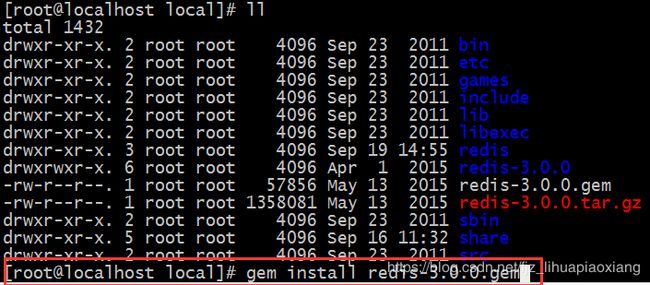
成功后显示

4、集群搭建准备工作
先创建6个redis实例
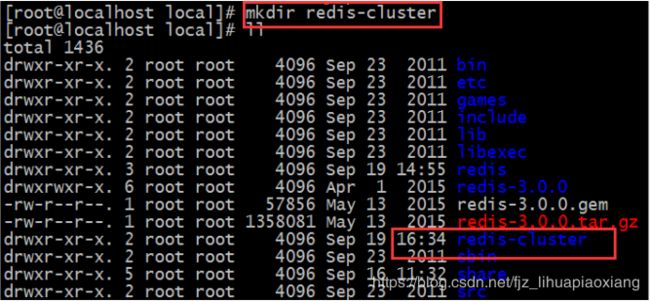
4.1 在local下创建一个目录redis-cluster
[root@localhost local]# mkdir redis-cluster
4.2 复制上面安装好的redis内容
[root@localhostlocal]#cp redis/bin -r redis-cluster/redis01 -p
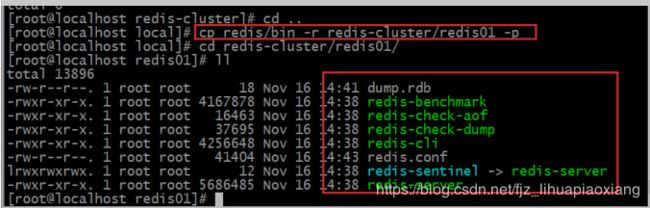
4.3 进入到redis01这个文件夹里
[root@localhost redis-cluster]# cd redis01/
4.4 查看目录
Rdb是redis默认的存储数据的方式,这里的dump.rdb里存放的就是redis的数据.
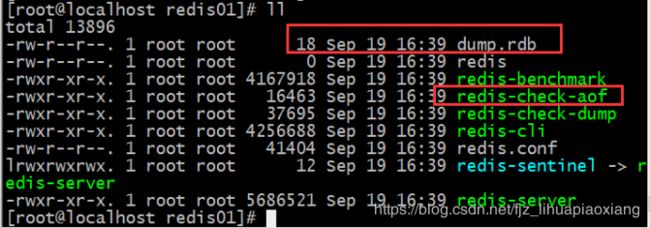
4.5 aof和rdb的区别
redis默认的保存数据的方式有两种:
第一种:是rdb形式,快照的形式,redis默认开启的也是这种方式,这种保存方式是每隔一段时间就会保存一下key值,性能上会高一些。
第二种:是aof方式,这种方式是每隔一秒钟就会保存一次数据,但是这种保存数据的方式性能上会差一些,不推荐使用这种。
4.6 删除dump.rdb
因为我们要搭建集群,要清空里面的所有数据,所以我们要把数据删除了
rm -f dump.rdb
![]()
5. 集群的搭建规划
5.1 6个redis实例,端口号从7001~7006
5.2 修改redis.conf文件
[root@localhost redis01]# vim redis.conf
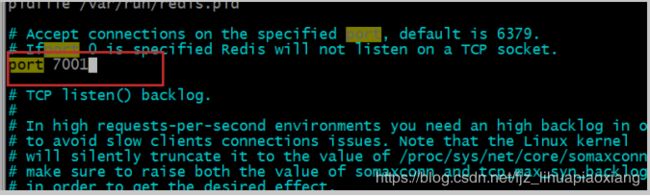
5.3 修改端口号
文件比较大,搜索文字,使用 / 后面要搜索的内容
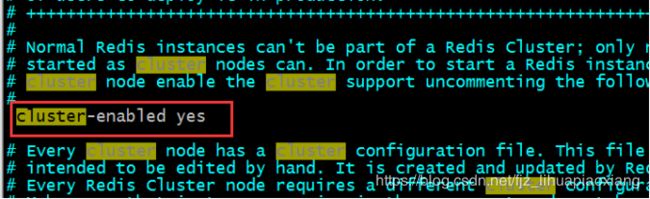
5.4 去掉cluster前的注释,指定要做集群
5.5 保存修改后配置,退出
Esc ----->:wq
5.6 在这个文件夹下复制5个文件
执行命令:
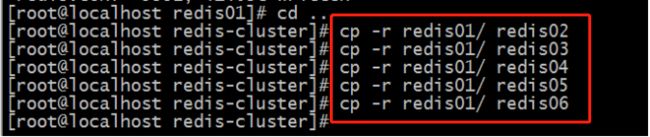
5.7 改每个实例下的端口号
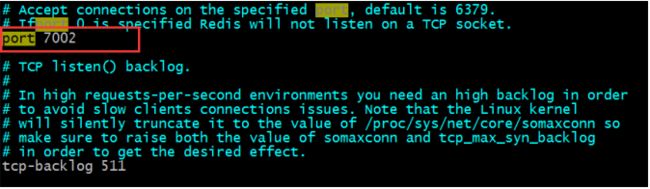
[root@localhost redis-cluster]# vim redis02/redis.conf
![]()
分别改为 7002,7003.....7006,改完以后保存,进入后按 i 就可以修改了
5.8 复制ruby集群脚本到这个文件夹下
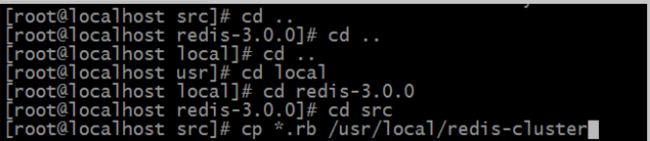
进入redis3.3.0文件夹下的src目录下,复制文件
[root@localhost local]# cd redis-3.0.0
[root@localhost redis-3.0.0]# cd src
[root@localhost src]# cp *.rb /usr/local/redis-cluster
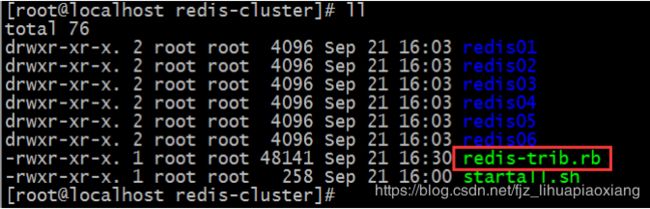
查看结果:
6、 启动每个节点redis服务
6.1 第一种启动方式
分别进入7001、7002、...7006的目录,执行:
./redis-server redis.conf
6.2 第二种启动方式
因为每次都得进入到文件夹中启动服务比较麻烦,可以创建linux脚本来启动服务,创建方式
6.3 执行命令创建脚本
vim startall.sh
![]()
6.4 写脚本
cd redis01
./redis-server redis.conf
cd ..
cd redis02
./redis-server redis.conf
cd ..
cd redis03
./redis-server redis.conf
cd ..
cd redis04
./redis-server redis.conf
cd ..
cd redis05
./redis-server redis.conf
cd ..
cd redis06
./redis-server redis.conf
cd ..
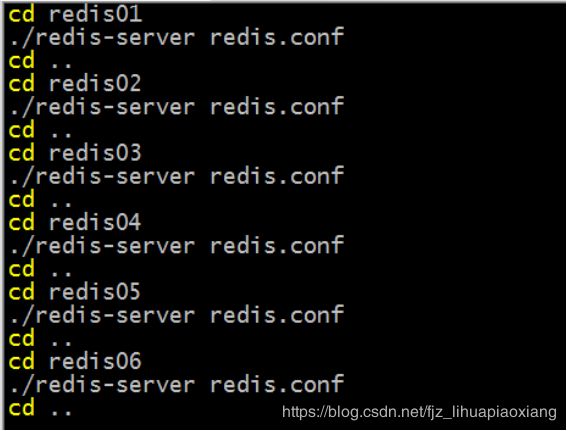
:wq 保存退出
6.5 变为可执行脚本命令
chmod +x startall.sh
![]()
6.6 执行脚本命令
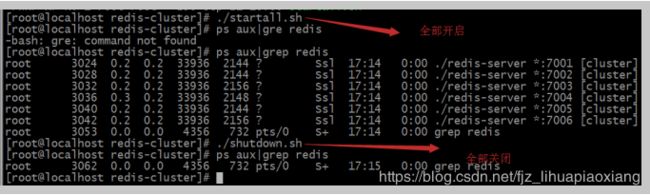
./startall.sh
![]()
6.7 查看redis进程命令
ps aux|grep redis
![]()

7、创建集群
7.1 执行命令
./redis-trib.rb create --replicas 1 192.168.1.105:7001 192.168.1.105:7002 192.168.1.105:7003 192.168.1.105:7004 192.168.1.105:7005 192.168.1.105:7006

注意:
如果执行时报如下错误:
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0
解决方法是删除生成的配置文件nodes.conf,如果不行则说明现在创建的结点包括了旧集群的结点信息,需要删除redis的持久化文件后再重启redis,比如:appendonly.aof、dump.rdb
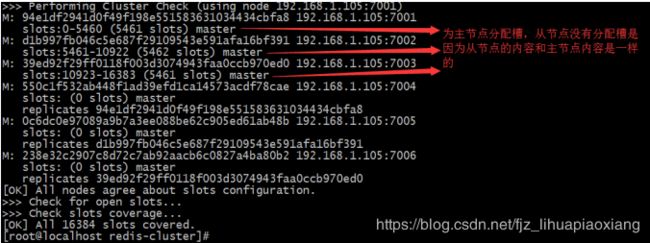
7.2 哈希槽说明
7.3 集群测试
输入连接命令:
连接集群里的任意端口号都可以,但是必须得指定ip地址
[root@localhost redis-cluster]# redis01/redis-cli -h 192.168.1.105 -p 7002 -c

注意:
redis01/redis-cli -h 192.168.1.105 -p 7002 -c ,其中-c表示以集群方式连接redis,-h指定ip地址,-p指定端口号
每次往集群里放数据的时候就会根据key值计算出一个对应的槽,放到对应的节点上,get的时候,会根据key值计算出一个hash值从对应的槽里取出数据。

8、关闭redis服务
不能直接关电脑进行关闭,因为redis的数据都是保存到内存中的,有可能丢失数据,所以我们要写一个脚本关闭redis服务
8.1 单机版关闭方式
进入到redis目录
[root@localhost local]# cd redis
[root@localhost redis]# ll
total 4
drwxr-xr-x. 2 root root 4096 Sep 19 15:40 bin
[root@localhost redis]# bin/redis-cli
127.0.0.1:6379> shutdown
not connected> quit

查看6379单机版redis的进程

8.2 集群redis关闭方式
第一种:直接在命令行里执行
[root@localhost redis]# bin/redis-cli -p 7001 shutdown

第二种:写脚本关闭
执行命令,进入到redis-cluster目录下
[root@localhost redis-cluster]# vim shutdown.sh
![]()
[root@localhost redis-cluster]# vim shutdown.sh
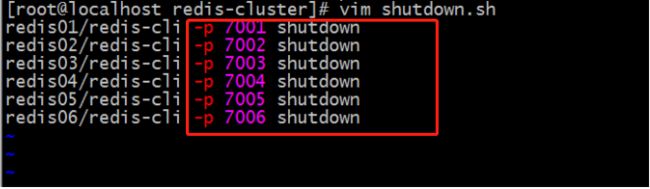
:wq 保存退出
执行
chmod +x shutdown.sh
[root@localhost redis-cluster]# chmod +x shutdown.sh
![]()
执行脚本
./shutdown.sh -------->全部开启
[root@localhost redis-cluster]# ./shutdown.sh -------->全部关闭
9、 redis客户端
自带的图形化客户端,这个客户端有个局限性,只可以连接单机版的redis,不能连接集群版的,我们可以开发的时候用单机版开发,上线以后可以搭建集群的。
使用方法:傻瓜式安装
9.1 连接linux系统:首先的关闭linux上的防火墙
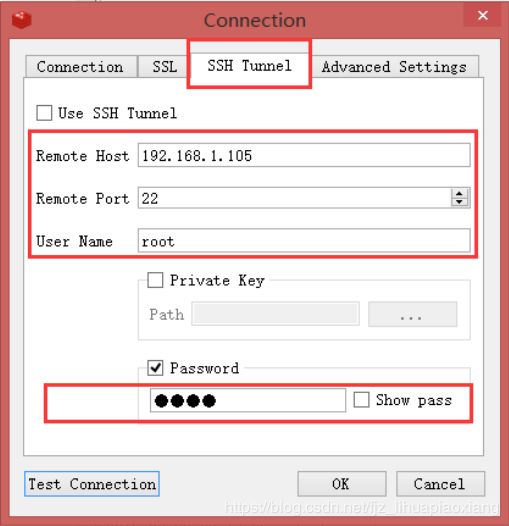
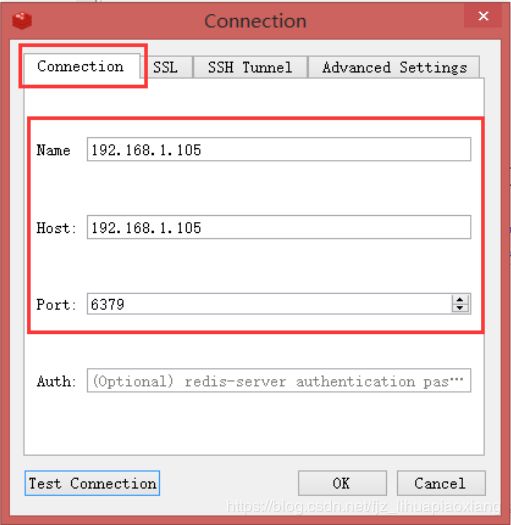
9.2 连接服务器上的redis单机版
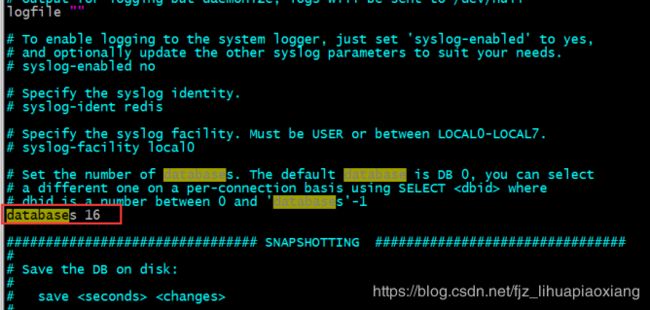
9.3 redis单机版默认有16个库
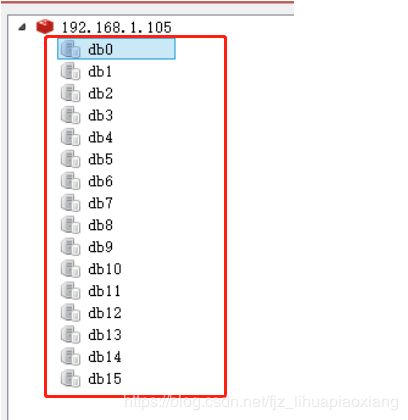
我们可以在redis的配置文件里看到库,也可以修改库的数量,开发时候建议不要改
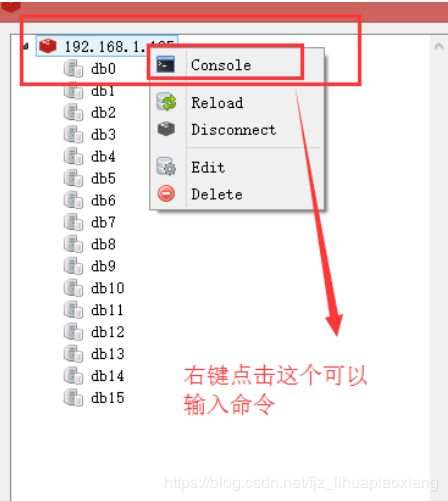
可以输入命令查看库,单机版才有16个库,集群版本只有一个库
输入 / 查找文件名
9.4 常用命令
Select 1 命令: 进入1号库
Set a 100: 可以设置参数