Modern Microprocessors A 90-Minute Guide
译者的话
文章标题说是一篇90分钟的简介,在我看来,90分钟不一定能够读完,但是内容相当的精彩,完全值得读上180分钟:在提高单核的性能上:作者从处理器的频率出发,分析处理器为什么要引入流水线,为什么会出现超标量流水器,为什么需要乱序执行,为什么需要分支预测,流水线的深度是否越深越好,处理器的发射宽度是否越宽越好,是否乱序执行一定比顺序执行要好,业界主流CPU厂商是如何做的?
继而分析了为什么单核的性能不能无限提升(POWER WALL),什么时候需要SIMD?然后分析了同时多线程SMT和多核在提升处理器性能方面的对比,同时又分析了cache对处理器的作用以及性能的影响。
文章的亮点在于引入问题自然,分析问题从正反两个方面对比说明,同时结合业界实际说明理论的应用情况,就像作者说的,是一个简要的,不拖泥带水的,快节奏的介绍现今处理器微架构主要设计的文章。
花了两个周末,终于把这篇文章翻译完了,希望对你有帮助,有不足的地方也希望大家评论指出。
原文链接:http://www.lighterra.com/papers/modernmicroprocessors/
本文是一个简要的,不拖泥带水的,快节奏的介绍现今处理器微架构主要设计的文章。
现在的机器人还都是非常初级的,只能够理解简单的指令,比如"往左",“往右”,或者"造车"
— John Sladek
文章目录
- 译者的话
- More Than Just Megahertz(不仅仅是赫兹)
- Pipelining & Instruction-Level Parallelism
- Deeper Pipelines – Superpipelining
- Multiple Issue – Superscalar
- Explicit Parallelism – VLIW
- Instruction Dependencies & Latencies
- Branches & Branch Prediction
- Eliminating Branches with Predication
- Instruction Scheduling, Register Renaming & OOO
- The Brainiac Debate
- The Power Wall & The ILP Wall
- What About x86?
- Threads – SMT, Hyper-Threading & Multi-Core
- More Cores or Wider Cores?
- Data Parallelism – SIMD Vector Instructions
- Memory & The Memory Wall
- Caches & The Memory Hierarchy
- Cache Conflicts & Associativity
- Memory Bandwidth vs Latency
- Acknowledgments
好吧,你可能是一个计算机专业的毕业生,也许作为学位课程的一部分你学习过硬件课程,但也许这已经是几年前的事了,现在你也没记住多少关于处理器设计的一些细节。
特别的,你可能对与现今处理器的一些快速变化的话题没有太多的关注…
- 流水线(超变量superscalar,乱序执行OOO,超长指令字VLIW,分枝预测branch prediction,假设predication)
- multi-core and simultaneous multi-threading (SMT, hyper-threading)
多核和同时多线程(SMT,又称超线程) - SIMD vector instructions (MMX/SSE/AVX, AltiVec, NEON)
单指令多数据的向量指令 - 缓存或者内存结构
不要怕!这篇文章将会快速带你跟上时代的节奏。在任何时候,你都可以像专业人士般参与讨论顺序执行,乱序执行,超线程,多核,缓存组织等话题。
但是请注意: 这篇文章是简要的,点到为止。它不拖泥带水,节奏相当的快,好吧,我们开始…
More Than Just Megahertz(不仅仅是赫兹)
第一个要弄清楚的话题是处理器的时钟速度和它的性能之间的关系: 它们不是一回事。下面是90年代后期处理器的一些测试结果
| SPECint95 | SPECfp95 | ||
|---|---|---|---|
| 195 MHz | MIPS R10000 | 11.0 | 17.0 |
| 400 MHz | Alpha 21164 | 12.3 | 17.2 |
| 300 MHz | UltraSPARC | 12.1 | 15.5 |
| 300 MHz | Pentium II | 11.6 | 8.8 |
| 300 MHz | PowerPC G3 | 14.8 | 11.4 |
| 135 MHz | POWER2 | 6.2 | 7.6 |
Table 1 – Processor performance circa 1997.
200MHz的MIPS R1000处理器,300MHz的UltraSPARC 处理器,以及400 MHz 的Alpha 21164处理器在运行大多数程序上,速度相当,但是它们在时钟频率上却相差了两倍。300 MHz 的Pentium II处理器和其它处理器在整型计算上速度相差不大,但是在浮点数运算上,比如数字密集型的科学计算,却是其它处理器速度的一半。同样是300 MHz 的PowerPC G3处理器在整型代码计算上在某种程度上比其它处理器快,但是和前三个相比,其浮点数运算速度却慢很多。在另一个极端,一个只有135 MHz的IBMPower2处理器的浮点数运算速度与400 MHz的Alpha21164差不多,但对于普通的整数程序来说,它的速度仅为后者的一半。
为什么会出现这样的情况?显然,不仅仅只有时钟速度,还有更多影响程序速度的因素:但归根结底,我们关心的是处理器每个时钟周期能够完成的工作量。这就引入了下面的流水线和指令并行的话题。
Pipelining & Instruction-Level Parallelism
通常,我们简单的认为:指令在处理器内部是依照先后顺序执行的,但这并不是实际情况。事实上,自从80年代中期后,指令在处理器内部就不是依照先后顺序执行的了,而是多条指令同时部分执行。
考虑一条指令的实际执行顺序:首先取码,接着译码,然后被某个功能单元进行执行,最后将结果写会某个地方。采用这样的方式,一个处理器可能需要4个时钟周期来处理一条指令。( Cycles Per Instruction, CPI=4)
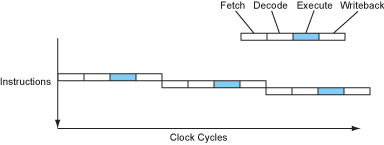
Figure 1 – The instruction flow of a sequential processor.
现代处理器以流水线的形式将这些步骤进行重叠,就像工厂的组装线。当某条指令在执行时,下一条指令在译码阶段,下下条指令在取码阶段。
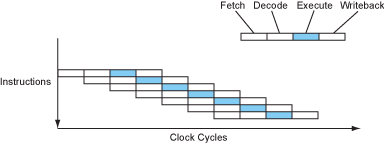
Figure 2 – The instruction flow of a pipelined processor.
现在处理器差不多可以在一个时钟周期完成1条指令了(CPI=1). 这是在不改变时钟速度的情况下实现了4倍加速。非常不错,是吧?
从硬件的角度来看,流水线的每个stage包含一些组合的逻辑,比如访问寄存器或一些高速缓存。流水线的各级通过门闩(latches)进行分隔,通过时钟信号来同步各个stage,这样,所有的门闩都可以在同一时刻拿到各个stage产生的结果。看起来好像是时钟像水泵一样,源源不断的向流水线输出指令。
在每个时钟周期的开始,某条部分运行过的指令的数据和控制信息被保存在流水线的门闩中,这些信息组成了流水线下一个stage的逻辑电路的输入部分。在整个时钟周期期间,信号通过该stage的组合逻辑电路进行传播,恰好在该时钟周期的末尾阶段产生输出,被下一个流水线门闩捕获。

Figure 3 – A pipelined microarchitecture.
既然每条指令的结果在执行stage结束后就可以得到了,那么下一条指令应该就可以立刻使用这个结果,而不是等待该结果在指令的写回(writeback )stage被写到目标寄存器才使用。为了实现这个目的,处理器内部添加了一些用于转发的线路,通常称它们为bypasses, 这些转发线路将结果导回流水线。
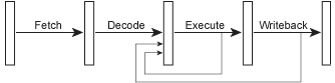
Figure 4 – A pipelined microarchitecture with bypasses.
尽管流水线的stage看起来简单,但是最重要的一点是:execute stage其实是由几个不同的逻辑电路组成的,这些逻辑电路组成了处理器执行各种操作的功能单元(functional units):如整型计算,浮点数计算,分支预测,内存读取等。
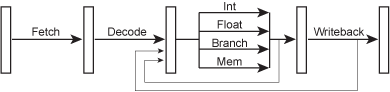
Figure 5 – A pipelined microarchitecture in more detail.
早期的 RISC 处理器,如IBM的801研究原型机,基于斯坦福的 MIPS R2000 ,以及源于伯克利RISC工程的最初的SPARC,都实现了一个不同于上面展示的简单的5级流水线;同时,主流的80386,68030和VAX的CISC处理器主要采用顺序执行的工作方式。这是因为采用流水线来执行RISC更简单,RISC的精简指令集意味着其指令多数都是简单的寄存器间的操作,而采用复杂指令集的x86,68k或者VAX因为指令较复杂,采用流水线来执行则比较困难。
Deeper Pipelines – Superpipelining
既然时钟速度受限于流水线中最长,最慢的stage, 那么组成这些stage的逻辑门电路可以再进一步的分解,特别是对于那些较长的stage,这样,就将较长的流水线转换为了包含数目更多,长度较短的更深的超级流水线。这样处理器将可以以较高的时钟速度运行。当然,完成每条指令现在将会花费更多的时钟周期,但是处理器仍然可以每个时钟周期完成一条指令,并且现在每秒钟会有更多的时钟周期,那么处理器在每秒中完成的指令将会更多,因而性能更高。
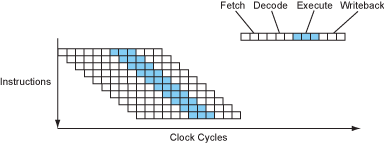
Figure 6 – The instruction flow of a superpipelined processor.
Alpha架构非常认同这个想法,这就是为什么早期的Alpha处理器在那个年代都拥有非常深的流水线,非常高的时钟速度。现在,处理器都努力将每个stage的延迟控制在几个门电路延迟的水准,一般12-25个门电路深度的延迟,再加上锁存器那块3-5个门电路的延迟。多数处理器都有较深的流水线
| Pipeline Depth | Processors |
|---|---|
| 6 | UltraSPARC T1 |
| 7 | PowerPC G4e |
| 8 | UltraSPARC T2/T3, Cortex-A9 |
| 10 | Athlon, Scorpion |
| 11 | Krait |
| 12 | Pentium Pro/II/III, Athlon 64/Phenom, Apple A6 |
| 13 | Denver |
| 14 | UltraSPARC III/IV, Core 2, Apple A7/A8 |
| 14/19 | Core i2/i3 Sandy/Ivy Bridge, Core i4/i5 Haswell/Broadwell |
| 15 | Cortex-A15/A57 |
| 16 | PowerPC G5, Core i*1 Nehalem |
| 18 | Bulldozer/Piledriver, Steamroller |
| 20 | Pentium 4 |
| 31 | Pentium 4E Prescott |
Table 2 – Pipeline depths of common processors.
x86处理器通常比同时代的RISC类型的处理器拥有较深的流水线,因为它们需要做额外的工作来解码复杂的x86指令。UltraSPARC T1/T2/T3 Niagara处理器是个例外, UltraSPARC T1只有6级流水线深度,T2/T3也只有8级流水线深度,这样做的目的是为了让核更小(后面会介绍更多)。
Multiple Issue – Superscalar
既然流水线的execute stage是一系列的不同的功能单元组成的,每个功能单元处理相对应的任务,这看上去在吸引我们去尝试着并行运行多个指令,每条指令采用各自的功能单元。要做到这样,必须改进取码和译码阶段,这样我们可以并行的译码并且将它们发送到执行资源哪里。
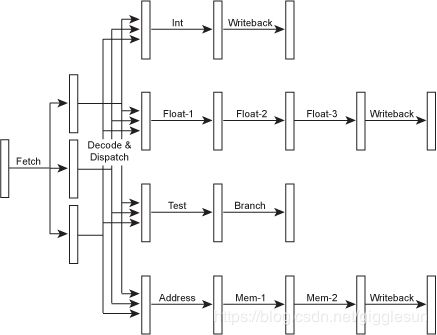
Figure 7 – A superscalar microarchitecture.
当然,对于各个功能单元,我们既然有了独立的流水线,它们当然也可以有不同数目的stages。这将允许简单的指令更快的执行完毕,减少延迟(我们马上会讲到这)。既然这样的处理器拥有不同的流水线深度,我们通常将处理器中执行整型运算指令的流水线深度叫做处理器的流水线深度,这也差不多是处理器中最短的流水线了,因为内存或者浮点数相关的流水线通常还有几个额外的stage。因此,我们一个10级流水线深度的处理器通常会用10个stage来处理整型指令,12或13个stage来处理内存指令,14或15个stage来处理浮点数指令。当然也会有一些流水线内部或者不同流水线间的旁路(bypasses),我们这里为了简单,在上面的图中都忽略不提。
在上面的例子中,处理器可能一个时钟周期内发射3条不同的指令,比如1个整型,1个浮点数,1个内存指令。我们有可能加入更多的功能单元,这样处理器1个时钟周期内可以执行2个整型,或2个浮点数,或2个内存指令,或者其它数目的指令个数,只要应用程序需要就行。
在一个超标量处理器内部,指令执行的流程如下图所示:
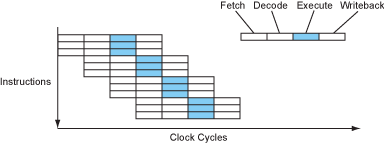
Figure 8 – The instruction flow of a superscalar processor.
这看起来好极了!现在每个时钟周期内有3条指令被执行完成(CPI=0.33,or IPC=3,也写作ILP=3,即 instruction-level parallelism)。处理器每个时钟周期内能够同时发射,执行或完成的指令个数我们称之为处理器宽度。
注意到发射宽度少于功能单元的个数,这是典型的。功能单元的个数必须较多,因为不同的代码顺序拥有不同的混合的指令。理想情况下每个时钟周期执行3条指令,但是那些指令并不会总是1条整型指令,一条浮点指令,1条内存操作指令,所以我们需要超过3个功能单元。
IBM POWER1是PowerPC之前的,第一个主流的超标量处理器。多数的RISC处理器很快采用了超标量技术,比如SuperSPARC, Alpha 21064等。Intel 甚至成功创建了超标量的x86处理器,也就是最初的Pentium ,但是复杂的x86指令集对他们来说是个大难题(后面会提到更多相关的内容)
当然,没有什么可以阻止一个处理器同时拥有较深的流水线以及多指令发射机制,所以处理器可以在同时是超流水线和超标量的(superpipelined and superscalar)。
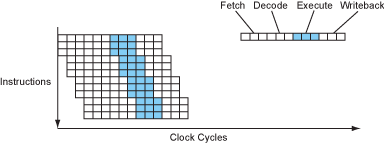
Figure 9 – The instruction flow of a superpipelined-superscalar processor.
今天,差不多所有的处理器都是超流水线,超标量的,所以我们通常简称为超标量的。严格的说,超流水线只是拥有更深的流线线而已。
现代处理器的宽度各不相同,如下表所示
| Issue Width | Processors |
|---|---|
| 1 | UltraSPARC T1 |
| 2 | UltraSPARC T2/T3, Scorpion, Cortex-A9 |
| 3 | Pentium Pro/II/III/M, Pentium 4, Krait, Apple A6, Cortex-A15/A57 |
| 4 | UltraSPARC III/IV, PowerPC G4e |
| 4/8 | Bulldozer/Piledriver, Steamroller |
| 5 | PowerPC G5 |
| 6 | Athlon, Athlon 64/Phenom, Core 2, Core i1 Nehalem, Core i2/i*3 Sandy/Ivy Bridge, Apple A7/A8 |
| 7 | Denver |
| 8 | Core i4/i5 Haswell/Broadwell |
Table 3 – Issue widths of common processors.
处理器中实际的功能单元的个数和类型取决于它的目标市场。一些处理器拥有更多的浮点运算资源,如IBM的POWER系列,一些拥有更多的整型预算资源,如Pentium Pro/II/III/M,也有的处理器将大量的资源用来处理SIMD向量指令,如PowerPC G4/G4e,绝大多数处理器采取平衡的中间立场来安排不同功能单元的个数。
Explicit Parallelism – VLIW
如果不考虑向后兼容,指令集单元可以显式的将那些将要并行执行的指令组合成一条指令。采用这种方法,在指令分发阶段,就不必进行复杂的指令间依赖检查,这可以让处理器更容易设计,更小,更简单的提高处理器的时钟速度。
在这种类型的处理器中,指令是小的子指令的集合,因此,这些指令本身是非常长的,通常有128比特或者更长,这也是这个指令名字的来源VLIW(very long instruction word)。每条长指令包含多个并行操作的信息。
一个VLIW 类型的处理器的指令流和超标量的指令流看起来差不多,只不过它的译码/分发stage非常简单,只作用于当前组的子指令。
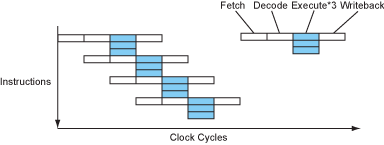
Figure 10 – The instruction flow of a VLIW processor.
除了简化调度逻辑之外,VLIW处理器与超标量处理器非常相似。特别是从编译器的角度来看(后面会详细谈到)
值得注意的是,大多数VLIW类型的处理器内部都是无锁的。也就是说它们内部不对指令间的依赖进行检查,如果发生缓存不中,除了暂停整个处理器,没有办法去暂停某个具体的指令。因此,编译器需要在相互依赖的指令间插入几个空指令来填补这之间的空白。这某种程度上让编译器变复杂了,因为它做了一些超标量处理器在运行时做的活,尽管如此,添加到编译器的代码是很少的,但是却可以节省宝贵的处理器资源。
现在还没有VLIW类型的处理器像主流处理器那样成功商用,但是Intel的IA-64架构的Itanium(安腾)处理器,现在正在研发阶段。它曾经被视为x86的替代者。Intel称IA-64是一个划时代(“EPIC”:“explicitly parallel instruction computing”)的显式并行指令计算设计,但是从本质上来说,它属于VLIW类型的设计,只不过它采用了更精巧的分组设计来保证长期的兼容性和分支预测的组缺陷。GPU中的可编程着色器有时是采用VLIW设计的,因为它中间有很多DSP。Transmeta类型的处理器也是采用VLIW设计的。
Instruction Dependencies & Latencies
采用深的流水线和多发射可以走多远呢? 如果一个5级流水线可以取得5倍速度,为什么不创建一个20级的流水线你?如果每次执行4条指令的超标量方式是好的,为什么不采用每次发射8条呢?同样,为什么不创建一个50级流水线,每个时钟周期发射20条指令的处理器呢?
下面,我们考虑如下两条指令
a = b * c;
d = a + 1;
第二条指令依赖第一条,处理器只有在第一条指令执行完毕,运算出结果后,才能执行第二条指令。这是一个严肃的问题,因为相互依赖的指令不能够并行执行,在这种情况下,多发射是不可能的。
如果第一条指令是一个简答的整型加法,那么采用单发射的具有流水线的处理器可能也是不错的,因为整型加法指令执行很快,并且第一条指令的结果可以通过旁路的方式及时的送到第二条指令的执行阶段。但是如果是乘法,它的执行阶段就需要好几个时钟周期来完成,当第二条指令进行到执行stage时,第一条指令的结果不可能可以得到。因此,处理器需要通过插入气泡的方式(处理器空转)来暂停第二条指令的执行直到第一条指令的结果出来。
延迟 “latency”这个单词有时可能让人困惑。这里,我说的延迟是从编译器角度出发的。一些硬件工程师认为延迟是指令执行所需要的时钟周期的个数,也就是流水线的stage的个数。所以从硬件工程师的角度,简单的整型指令有5个时钟周期的延迟,吞吐量是1,然而从编译器的角度来看,它们的延迟是1,是因为它们的结果在下个时钟周期就可以使用。从编译器的角度来讨论“latency”是非常普遍的,一般在硬件的说明文档中用到的就是这个延迟。
当一条指令进入execute stage和当它的结果可以被其它指令使用的时钟周期数目称为指令延迟。流水线越深,stage数目会越多,因而延迟更大。因此,一个非常深的流水线不如较短的流水线效率高,因为较深的流水线由于指令间的相互依赖,会填充很多空指令。
从编译器的角度来看,现代处理器一般的延时范围为:从整型操作的单个时钟周期到浮点数加法的3-6个时钟周期(乘法稍长些),在到整型除法的12个时钟周期以上。
内存加载带来的延迟特别容易带来问题,一方面是因为它们通常发生在代码执行的早期时候,这将很难用有效的指令来填补它们带来的延迟;同样重要的另一方面是它们在某种程度上来说是不可预测的:加载延迟根据缓存是否命中差别很大。(后面我们会谈到缓存)
Branches & Branch Prediction
流水线中的另外一个关键问题是分支预测。考虑如下的代码
if (a > 7) {
b = c;
} else {
b = d;
}
,编译后汇编码如下:
cmp a, 7 ; a > 7 ?
ble L1
mov c, b ; b = c
br L2
L1: mov d, b ; b = d
L2: ...
现在考虑一个具有流水线的处理器正在执行上面的代码序列。当执行到第2行的条件分支时,处理器必然已经将接下来的几个指令进行了取码和译码。但是到底是哪几个指令呢?它是应该对if 分支对应的指令(第3,4行)进行取码和译码呢,还是应该对else分支对应的第5行指令进行取码和译码呢?直到条件分支到达execute stage时,处理器都不会知道该怎么做,这在一个较深的流水线处理器上,已经是好几个时钟周期了开外了。处理器等不起:处理器平均每六条指令就会遇到一条分支预测指令,如果每次都去等好几个时钟周期,那么起初采用流水线获得的大部分性能优势将不复存在。
所以处理器必须赌一把。处理器将会顺着它猜测的路径投机的进行取码和译码,当然,在分支预测的结果出来之前,它不会真的将指令执行的结果写回到寄存器。坏的情况下,如果赌输了,已经执行的指令将会被取消,执行这些指令的时钟周期就浪费掉了。但是如果赌对了,处理器将能够继续全速运行。
关键问题是处理器依据什么来赌?有两种选择,第一种是编译器来给某个分支做标记,告诉处理器选哪个分支,我们通常称这为静态分支预测。理想情况下要是指令格式中能够有个标志位能够来存储预测信息,作为预测的依据,但是对于较老的处理器架构中,不可能有这个选项,所以可以采用通用的惯例来作为判断的依据:比如向后的分支预测为真,向前的分支预测为假。更重要的是,这种方法要求编译器非常智能,这样我们才能依赖它做出正确的决策,这在循环分支判断中很容易但是对于其它分支预测可能会很困难。
另外一种选择时让处理器在运行时做预测。通常情况下,这种方案是使用一个处理器中内置的分支预测表来进行的:这个表包含了最近分支的地址以及用1比特来标记上次是否执行了这个分支。在实际中,大多数处理器用2比特来标记,这样某次不采用这个分支的情形不会改变正常的分支预测的结论。${code}当然,这个动态变化的分支预测表占据了处理器上宝贵的空间,尽管如此,考虑到分支预测的重要性,这也是值得的。
不幸的是,即使采用最好的的分支预测技术,预测结果有时也是错的。在预测错误的情况下,一个较深的流水线中将会有许多指令需要被取消,我们称这位错误预测惩罚(mispredict penalty)。Pentium Pro/II/III是个好例子,它有12级流水线,它的mispredict penalty是10-15个时钟周期,即使有一个非常好的,可以达到90%正确率的分支预测器,mispredict penalty 也意味着处理器30%的性能损失掉了。换句话说,Pentium Pro/II/III处理器1/3的时间干的不是有效的工作,而是一直再说“啊,走错了”。
现代处理器将更多的硬件资源用来进行分支预测以此来提高预测准确性,减少预测失败带来的损失。很多处理器不是孤立的记录某次分支的预测方向,而是把它放在之前的几个分支的场景中进行考虑,这就是二级适应性预测器。有一些保留一个更全局的分支执行历史,而不是单独的某个分支历史,尝试采用这种方法来修正分支预测,即使这些分支在代码上相距很远。这叫做gshare或gselect 预测器。最高级的处理器通常实现多个分支预测器,然后选出对单个分支预测最好的预测器,依据此进行分支预测。
尽管如此,即使最好的处理器拥有最智能的分支预测器,也只能达到95%的分支预测准确性。由于分支预测失败,仍然会失去相当多的性能。道理很简单:较深的流水线自然会受到分支预测收益递减的影响,因为越深的流水线,那么预测的距离将会更远,更有可能会出错,出错后惩罚也会更大。
Eliminating Branches with Predication
条件分支有这么多的问题提,要是能够将它们全部去掉就好了。显然,我们不能将成语中的if语句全部删除,那么相应的分支怎么可能被去掉?在分支使用的方式中可以找到答案。
再考虑下上面的例子。5条指令中,有2条是分支指令,分支指令中有一条又是无条件分支。如果我们能够在mov指令中做一些标记,告诉下一条语句只有在某些情况下才执行,那么将可以简化代码。
cmp a, 7 ; a > 7 ?
mov c, b ; b = c
cmovle d, b ; if le, then b = d
这里,引进了一个新指令comvle, 表示"conditional move if less than or equal"。这条指令向正常指令那样执行,但是它只在条件为真时才会将结果写回寄存器。这种指令称为预言指令,因为它的执行被一个预言指令控制着。
有了这个新的预言move指令,减少了两条指令,并且都是代价较大的分支指令。另外,通过总是执行第一个mov指令只有在需要的时候才将它的结果覆写的这种巧妙的方式,指令的并行化大幅提升了,第1,2行现在可以并行执行,相比以前提升了50%(2个时钟周期相对于之前的三个时钟周期)。最重要的是,分支预测失败后承担错误预测惩罚的情形消除了。
当然,如果if和else代码块较长,那么使用预言的方式将意味着比用分支预测的方式需要执行更多的指令(if和else两块的指令),因为处理器实际上执行了两个路径上的指令。是否应该多执行一些指令来避免分支预测是一个困难的决定,对于非常小或者非常大的代码块,很容易下决定,但是对于中等大小的代码块,中间复杂的权衡利弊需要优化人员考虑。
Alpha 架构的处理器在最初的时候有条件move指令,MIPS, SPARC 和 x86服务器稍后也加入了对这条指令的支持。在IA-64处理器中,Intel全部放开,几乎在每一条指令中都支持了预言,希望借此能够大幅减少内部循环中的分支预测问题,特别是,对于不可预测的分支,比如编译器和操作系统内核。有趣的是,手机和平板中的处理器采用ARM架构,它是第一个完全采用预言指令集的架构。更有趣的是,早期的ARM处理器中只采用了非常短的流水线,它的错误预测惩罚因此相对比较小。
Instruction Scheduling, Register Renaming & OOO
如果分支预测和长延迟的指令会造成流水线中产生气泡,那么也许这些处理器的空转可以用来做其它工作。要实现这个想法,程序中的指令必须重排序,这样当某条指令在等待时,其它指令可以被执行。例如,可以在程序的较远处找到一些指令,将他们放在上面那个乘法例子的两条指令中间。
有两种方法可以实现这种方法。一种方法是通过硬件在运行时进行指令重排。实现动态指令重排意味着指令分发的逻辑必须改进,使之可以查看多个分组的指令然后将它们乱序分发,达到最大限度的利用处理器功能单元的目的。不用惊讶,这就是传说中的乱序执行了,也简称为OOO(有时写作OoO或OOE)。
如果处理器乱序执行指令,那么它必须记住这些乱序指令间的依赖。这也可以通过不使用原生系统自定义的寄存器,而是通过使用一些重命名的寄存器的方法来简化问题。比如,一个将某个寄存器内容写到内存的指令,后面跟着一个从其它内存块读值到该寄存器的操作,它们有不同的值,我们不必要使用同一个物理寄存器。更进一步,如果这些不同的指令对应到不同的物理寄存器,那么它们就可以并行运行了,这就是OOO执行的核心了。因此,处理器必须随时动态持有当前运行的所有指令以及它们使用的物理寄存器的对应关系。这个过程就称之为寄存器重命名。一个额外的好处是,处理器现在可以利用一个更多的真实寄存器来将代码最大程度并行化。
上面提到的这些依赖分析,寄存器重命名,乱序执行(OOO)使处理器的逻辑变得更复杂了,更难设计,芯片面积更大,更耗电。这些额外的逻辑特别耗电是因为这些晶体管一直工作着,不像功能单元那样有时候还能闲下来,甚至不通电。另一方面,乱序执行可以保证软件不必重新编译也可以运行在新处理器上,使用新处理器的某些优势,当然不是所有的优势。
另一种方法是让编译器来重排指令,这通常称为静态指令重排或者编译器指令重排。重排后的指令流就可以提供给简单设计的有序、多发射执行的处理器,这依赖于编译器要能够将最好的指令流喂给处理器。这避免了复杂的乱序执行逻辑,将让设计处理器轻松很多,处理器能耗也更低,面积也更小,这意味着在同一片芯片区域可以放更多的核,额外的缓存。
采用编译器重排指令是采用软件方法的方式,这和采用硬件支持乱序执行的方式相比,还有其他的优势。编译器比硬件可以看到程序程序更远的地方,它可以同时对多条执行路径进行推测而不是仅仅一条,这在分支不可预测时采用硬件的方式是个大问题。另一方面,大家都不指望处理器是全能的,所以处理器不必什么都是完没的。要是没有乱序执行的硬件,当编译器不能正确预测一些事情的时候,比如缓存不中,流水线将会挂起等待。
多数早期的超标量处理器采用的设计方式是有序的,比如SuperSPARC, hyperSPARC, UltraSPARC, Alpha 21064 & 21164, the original Pentium。早期采用乱序设计的处理器有MIPS R10000, Alpha 21264,以及整个带保留栈的POWER/PowerPC系列。如今,除了UltraSPARC III/IV, POWER6 和 Denver处理器外,几乎所有高性能处理器都采用乱序执行的方式。多数耗电低,性能低的处理器,比如Cortex-A7/A53 和 Atom,都是采用执行的设计方案,因为乱序执行的方式需要消耗很多的电能但是能够获得的性能提升却相对太小。
The Brainiac Debate
一个肯定会被问到的问题的是:代价不菲的乱序执行是否真的有必要,或者编译器是否能够足够好的编排代码而不需要硬件来进行乱序执行?这在历史上称为聪明人对速度狂魔的争论(the brainiac:意指乱序执行需要非常灵巧聪明的设计芯片,因而成为聪明人; speed-demon :意指有序执行不需要设计复杂的芯片,芯片运行速度非常快,因而简称为速度狂魔)。
聪明人方案位于智能机器设计的末端,包含有很多的乱序执行的硬件,期望从代码中挤出最后一滴的指令并行性,即使这要花费数量在百万级的半导体和数年的努力设计也在所不辞;相反,速度狂魔方案是简单和小巧的,依赖于精巧的编译器,愿意牺牲一些指令集的并行性从而换取简单设计带来的好处。历史的说,采用速度狂魔方案的处理器通常时钟频率更高,只是因为这样的处理器更简洁,这也是速度狂魔名字的来源,但是现今这种情况不再存在了,因为处理器的时钟频率被电源和散热问题限制住了。
毫无疑问,乱序执行的硬件应该尽可能的让更多指令集并行的能力释放出来,因为在运行期一些编译器不能够预测的事情是确定的,比如缓存不中。另一方面,一个简单的有序执行的处理器芯片将会更小巧,耗能更少,这意味着你可以在同一块集成电路板上放更多有序执行的芯片,而不是更少,更大的乱序执行的芯片。那么,你喜欢拥有那种集成电路呢:4个强大的聪明的芯片,还是有8个简单的有序执行的芯片。
事实上,关于到底哪个更好的辩论,人们现在还在热烈的进行着。事实上,乱序执行的代价和好处以前好像都被夸大了。从代价来说,在90年代后期,适当的流水线分发和寄存器重命名可以让乱序执行的处理器获得与简单设计处理器相比有竞争力的时钟速度,并且近些年精巧的工程技术可以减少乱序执行带来的电源开销,留下的只是占用面积大这一问题。这是处理器架构师在工程实践中取得杰出成就的证明。
然而,不幸的是,提升处理器乱序执行的努力的结果是令人失望的,只取得了相对小的提升,和有序执行设计取得的提升相比,大概只有有序执行提升幅度的20%-40%。引用乱序执行方面的先锋人物,同时也是Pentium Pro/II/III处理器中的一位主要设计师Andy Glew的一句话,“乱序执行的肮脏的小秘密是,我们通常并没有太多的乱序执行”。乱序执行也不能提供之前我们期望的“编译独立”的性能优势,在乱序执行更好的处理器上重新编译依然可以大幅提升运行速度。
当回到我们之前说的“聪明人”对“速度狂魔”的辩论时,很多芯片提供商一会在“聪明人”的道路上走了很远,一会又改变主意,换到“速度狂魔”的这一边来。

Show Lineage: None x86 MIPS SPARC POWER/PowerPC Alpha ARM x86 & ARM
Figure 11 – Brainiacs vs speed-demons.
比如,DEC,最开始的两代Alpha产品主要采用“速度狂魔”的方式,在第三代产品上又转换为“聪明人”方式。MIPS也是这样的。Sun则相反,在它们的第一代超标量SPARC处理器时,采用的是“聪明人”方案,在最近的设计中则采取了“速度狂魔”的方案。POWER/PowerPC 阵营最近也抛弃了“聪明人”方案,尽管POWER/PowerPC中的保留栈确实提供了在不同功能单元间乱序执行的能力,针对同一个功能单元的指令队列,仍然严格是有序执行的。作为对比,ARM处理器一直都从低电源,低性能的嵌入式世界在向聪明人方案靠拢,但是一直保留着以手机为中心的策略,因此它不会将它的时钟频率提得过高。
Intel是所有处理器中最有意思的。现代x86处理器由于x86架构的限制,不得不尽力做到更加“聪明人”,Pentium Pro 完全采用这种方案。接着发生了和AMD竞争谁先到达1GHz的事情,AMD在2000以微小的优势取得胜利。Intel因此不惜一切提高它们处理器的时钟频率,Pentium 4 采用解耦的x86微架构方案,牺牲了一些指令集的并行,采用多达20级流水线的方案,尽力做到“速度恶魔”,先后做到了2GHz和3GHz。最近的一版更是采用31级流水线,速度达到了3.8GHz。同时,对于IA-64 Itanium处理器(上面没有列出),Intel又坚定的选用“聪明人”方案,采用的是非常简单的设计,完全依赖编译器重排。面对IA-64的失败、Pentium 4的高耗能和发热问题、以及时钟频率更慢的(大概2GHz左右)AMD Athlon处理器在真实世界中上完全优于 Pentium 4的事实,Intel再一次改变了策略,更新了旧的Pentium Pro/II/III “聪明人”的设计方案,得到了 Pentium M和后继的Core系列处理器,取得了伟大的成功。
The Power Wall & The ILP Wall
奔腾4严重的电源和发热问题说明了时钟频率是有极限的。电源的使用量比处理器时钟频率的增长速度更快,对于任何水平的芯片技术,如果提升时钟频率20%,那么这一般会使电源的使用量增加50%或更多,这是因为不仅仅半导体多开关了20%,而是因为电压也要相应的提高,从而可以驱动信号沿着半导体更快的传播,从而可靠的达到缩短的时钟周期的要求,确保整个电路都可以工作在更快的时钟频率上。虽然电源使用量和时钟频率增长呈线性关系,但是电压和时钟频率增长呈平方关系,在非常高的时钟频率下,产生“三重打击”。
更坏的是,因为除了一般的开关电源,也有一些泄露的电源,因为即使某个半导体断电了,当前流过它的电源不会完全减到0。就像增大电压好的,有用的一面,那些泄露的电源随着电压的增高也上升了。如果这还不算太坏,泄露的电源通常也随着温度的上升而上升,这是因为硅片内部更多更热,能量更高的电子不断增加的运动造成的。
最终的结果是,今天,将处理器的时钟速度提高30%,将需要双倍的电能,产生双倍的热量

Figure 12 – The heatsink of a modern desktop processor, with front fan removed.
在某个点前增加电源功率是okay的,但当到达改点后,当前是大概150-200瓦,那么电源和发热问题将会变得不可控。即使芯片可以运行在那么高的时钟频率,但因为不可能提供那么多的电源,以及散热能力,这在工业上也是不可行的。这称为power wall。
将注意力过分集中于时钟频率的处理器,比如Pentium 4,IBM 的POWER6 和最新的AMD的Bulldozer, 很快就撞到了power wall,他们发现不可能进一步将时钟频率像他们之前期望的那样向前推动,导致他们被时钟频率较慢但是更智能的采用了更多指令集并行的处理器所打败。
因此,简单提高时钟频率不是最好的策略。对于那些便携式移动设备,比如笔记本,平板电脑和手机,更不能够简单提高时钟频率,它们会更早的到达电源的power wall, 对于高端笔记本,这个power wall是大概50 W,超轻笔记本是15W,平板是10W,手机小于5W, 主要是因为电池的容量限制和它们普遍采用的无风扇冷却方案。
那么,既然主要采用提高时钟频率的方案有问题,那么主要采用“聪明人”方案呢?不幸的是,也不能够。追求更多的并行度也有明确的限制,因为,不幸地是,一般的程序因为读取延迟,缓存不中,分支预测和指令间依赖等因素的影响,并没有良好的并行度。这种对现有指令间并行的限制称为 ILP wall
将重点完全放在ILP的处理器,比如早期的POWER,SuperSPARC 和 MIPS R10000处理器,很快就发现它们获取额外并行度的能力是有限的,同时增加的复杂度又严重限制了它们提升时钟频率的能力,导致它们被那些看起来更笨,不那么注重指令集并行,但是时钟频率更快的处理器打败。
一个4发射的超标量流水器需要4条独立的指令(这些指令需要在每个时钟周期都没有指令间依赖,延迟等问题)才能完全并行。在实际情况中这是不可能做到的,特别是如果读延迟需要3-4个时钟周期的话。当前,对于主流的单线程程序,真正指令间并行度最高是大概每个时钟周期2-3条指令。事实上,那些跑SPECint 基准测试的现代处理器的平均指令间并行度是每个时钟周期不到2条指令,并且这些SPECint 基准测试程序在某种程度上比真实世界中那些大型的程序更简单,更适合并行运行。某些种类的应用确实存在更高的并行性,比如科学计算大妈,但他们不能代表主流的程序。也有一些类型的代码,比如"pointer chasing"类的,要想达到每个时钟周期1条指令都非常困难,对于这些程序,关键问题是内存问题,这是另一堵墙了,memory wall。
What About x86?
那么x86怎么能够适应上面的这些呢?Intel和AMD在过去的35年里面,是怎样做到采用一种架构,经历了处理器这么多的发展期,却依然保持竞争力的呢?
对于最初的采用超标量的x86 Pentium处理器,它在工程上是个杰作,同时,它的缺点也很清晰:就是复杂混乱的x86指令集。处理器采用这种解决复杂指令的模式,同时内部寄存器也不多,这就意味着很少的指令因为潜在的依赖关系可以并行运行。对x86阵营来说,要和RISC架构竞争,它们必须找到一种方法来处理好它们的x86指令集。
NexGen和Intel的工程师大概在差不多同样的时间各自独立的找到了解决方案。解决方案是动态的将x86指令集解码为简单的像RISC类似的微指令,这些微指令因而可以接下来运行在更快的,类似RISC风格的,带有寄存器重命名,乱序执行的超标量处理器上。微指令通常称为μops, (读作 “micro-ops”)。现在大多数x86指令都会被解码为1到3条微指令,更复杂的x86对应更多数目的微指令。
对于这些解耦的超标量x86处理器,寄存器重命名绝对是非常重要的,因为x86架构在32位模式下只有8个微薄的寄存器,64位模式有16个。这和RISC架构不同,RISC架构下通过寄存器重命名的方式提供更多的寄存器只有些许的影响。尽管如此,x86通过一种更为巧妙的寄存器重命名方法,将RISC的全部技巧都带到了x86世界,除了两点,一个是高级静态指令重排(因为微指令位于x86指令后面,编译器不太可见),另一点是采用大寄存器集来避免内存访问的。
x86的基本工作模式如下:
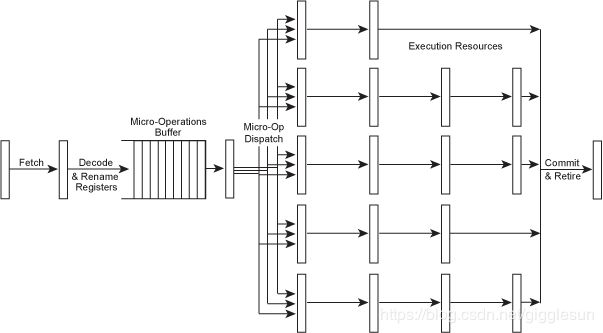
Figure 13 – A “RISCy x86” decoupled microarchitecture.
NexGen 的Nx586 和Intel 的Pentium Pro (又称为 P6)处理器是首批采用解耦的x86微指令架构的处理器,现在几乎所有的现代x86处理器都使用了这项技术。当然,在内部核心流水线,功能单元等确切的设计方面它们各不一样,就像各式各样的RISC处理器一样,但是它们将x86指令转换为类似RISC指令的微指令这一基本观点是一致的。
一些最近的x86处理器甚至将转换好的微指令放到一个小的缓存中,或者甚至专门设计了一个 "L0"级的微指令缓存,目的是避免将重复的x86指令反复翻译,节省时间和电能。这就是为什么 Core i2/i3 Sandy/Ivy Bridge处理器在前面的超流水线中介绍的流水线深度是14或19级,当运行在L0缓存上是14级,运行在L1指令缓存(不得不解码x86指令然后转换为微指令)时是19级。
x86指令的取码、译码与内部RISC类似的微指令的分发和执行的这一解耦,使我们定义x86处理器的宽度优点困难,同时由于处理器内部经常又将这些微指令组合到一块以方便追踪,这使宽度的概念更模糊。类似Core i4/i5 Haswell/Broadwell处理器,在译码阶段每时钟周期处理多达5条x86指令,产生最多4条组合的微指令,这些微指令然后存在了L0缓存,在这里最多每时钟周期可以取出4条组合微指令,然后寄存器重命名,然后放入重排区,在这里每时钟周期可以发射最多8条未组合的微指令到相应的功能单元,在这里它们在不同的流水线里执行,直到执行完毕,然后最多4条组合的微指令可以被提交,最终大功告成。那么Haswell/Broadwell处理器的宽度是多少呢?从核心来说它是一条8发射的处理器,如果这8条微指令以某种合适的方式组合,它每时钟周期可以取出,发射,执行完成8条未组合的微指令(一条未经组合的微指令和简单的RISC指令是对等的),但是即使一些专家也不同意称它们的宽度为8,因为从组合指令的方面来看,4发射也是说得通的;同时,从最初x86指令的角度来看,我们也可以说它是5发射的。当然,这种宽度问题主要是理论上的,因为在真实世界中,没有那个处理器可以在运行真实世界的代码时取得如此高的指令并行度。
RISC风格的x86系列处理器中,最有意思的一个是Transmeta Crusoe处理器,它将x86指令内部转换为VLIW形式的指令,而不是超标量形式,采用软件在运行时来做这种转换,看起来就像Java虚拟机一样。这种方法可以让处理器本身是简单的VLIW,不需要解耦的x86处理器中复杂x86指令的解码和寄存器重命名硬件,也不需要任何的超标量分发或乱序执行的逻辑。基于软件方案的x86转换和基于硬件的转换相比,确实降低了系统的性能,但是带来的好处是非常精简的芯片,芯片的运行速度快、发热少、耗能低。一个600 MHz Crusoe的处理器可以匹敌一个 运行在低功耗模式下(300 MHz)的500 MHz的Pentium III处理器,然而使用的电源和产生的热量都是后者的很小一部分。这使它非常适合那些电池使用时间非常重要的笔记本和手持电脑。如今,当然,x86处理器也有转为低功耗设计的变体,比如 Pentium M 和后续的Core系列,它使Transmeta风格的基于软件的方法变得不那么需要了,但是Transmeta风格的方法目前正被用在NVIDIA的Denver ARM处理器上,同样是为了高性能,低功耗。
Threads – SMT, Hyper-Threading & Multi-Core
就像前文已经提及的,由于大多数程序本身并没有良好的并行性,通过超标量运行来挖掘指令并行能力的方法效果并不好。因为这个因素,即使最好的乱序执行的超标量处理器,配上最智能的编译器,在运行主流的真实程序时,由于读取延迟,缓存不中,指令依赖和分支预测等问题,也不会超过每个时钟周期执行平均2-3条指令的水平。同一个时钟周期发射很多指令最多只在少量的周期出现,大量的周期还是运行的非常低的指令并行的代码,所以很难取得最好性能。
如果不能在正在运行的程序中获得其它可独立运行的指令,还有一种潜在的可独立运行指令的资源:其它运行的程序,或者同一程序内不同的线程。同时多线程(SMT: Simultaneous multi-threading ) 是一种采用类似线程级并行的处理器设计技术。
同样,这个技术的主要思想和用有用指令来填充流水线中的气泡相同,但是这次不是采用同一份代码中的较远处的指令,而是采用运行在该处理器核心上的其它程序的指令。所以,一个SMT类型的处理器在系统的其它部分看起来就像是多个独立的处理器,就像一个真正的多处理器系统。
当然,一个真正的多处理器系统也可以同时执行多个线程-只不过一个处理器中运行一个线程。这也适用于那些一个芯片内有2个或多个核的多核处理器,当然,这和传统的多处理器系统没什么区别。相反,一个SMT类型的处理器只有一个物理核心,但是系统看上去却有两个或多个逻辑核心。这让SMT核心在芯片面积,制造代价,能源消耗和散热方面和一般的多核处理器相比更高效。当然,一个多核处理器的每个核心也可以采用SMT设计。
从硬件的角度来看,实现SMT需要复制处理器中存储每个线程运行状态的各个部件,比如程序计数器,系统可见的寄存器,TLB中存储的内存映射等等。幸运的是,这些部件只是整个处理器硬件很小的一部分。真正大且复杂的部分,比如解码器和分发逻辑,功能单元,缓存等,都是各个线程可以共享的。
当然,处理器必须在任何时候记录着那条指令,那个重命名寄存器属于那个线程,这些看起来复杂,其实只给处理器添加和很小的复杂性。所以,相对于10%左右的处理器复杂性开销,以及可以忽略的增加的半导体数量,以及生产成本,现在处理器可以同时运行多个线程,极有可能大大提高处理器功能单元的利用率和每时钟周期内运行的指令数量,因此提升了整体的性能。
SMT处理器的运行流程如下图所示:
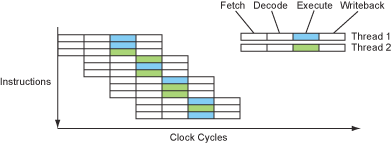
Figure 14 – The instruction flow of an SMT processor.
这看起来非常不错。现在我们把之前那些气泡用运行着的多个线程填充起来了,我们可以证明在单线程处理器中添加更多的功能单元是可行的,开始真正的走进多指令问题的核心。在某种情形下,这可能对提高单线程程序的性能有副作用,特别是那些指令并行友好的代码。
那么,我们可以使用20发射的方式吗?不幸地是,回答是NO。
分析SMT的性能是一项棘手的任务。首先,SMT创建在要么有很多程序同时在运行,要么只有一个包含多个线程在运行的程序这一假设上的。目前在多处理器系统上的经验告诉我们,这不总是成立的。在实际中,至少对于台式机,笔记本,平板电脑,手机和小型机等,很少有多个程序同时在运行的情形,所以最常见的情况是只有一个任务运行在机器上。
一些应用,像数据库系统,图像和视频处理,音频处理,3D图像渲染以及科学计算,确实有明显的高并行性,我们也很容易去发掘这些并行性,但是不幸的是,即使这些程序,在编写的时候也没有采用多线程的方式去使用多个线程,以此来利用多个处理器。另外,这些很容易并行化程序,因为它们内在就有并行的特性,主要其实被内存带宽限制了,而不是被处理器(图形处理,音频处理,简单的科学计算的代码),因此添加一个线程或者处理器其实并不能带来太多的帮助,除非我们也能显著的提升内存的带宽。更糟糕的是,很多其他类型的应用,比如网页浏览器,多媒体设计工具,预言翻译器,硬件模拟器以及其它类似的,它们并不是采用并行的方式编写的,它们当然因此也不能充分利用多处理器。
最重要的是,SMT类型的处理器中的线程都共享同一个处理器核心,同一块缓存区域,这和真正的多处理器或多核的系统相比有很明显的性能劣势。在SMT类型的处理器的流水线中,如果某个线程饱和的占用了其它线程也需要的功能单元,那么其它线程实际上都被暂停了,即使它们只需要用以下该功能单元。因此,平衡所有线程的运行非常重要,最有效的使用SMT的是那些含有高度混合代码的应用程序,线程不会经常同时竞争同样的硬件资源。同样,线程在竞争缓存空间时会产生更坏的结果,这比让一个线程拥有所有的线程空间还糟糕。特别是对于那些临界区的大小和缓存大小高度相关的软件,比如硬件模拟器,虚拟机和高质量视频编码器等。
最坏的情况是,如果不特别处理,或者对某些程序即使进行了特别处理,SMT的性能可能实际上比单线程的采用传统上下文切换方式进行线程切换的程序性能更差。另一方面,那些主要被内存时延(不是内存带宽)影响的程序,比如数据库系统,3D图像渲染,和其它含有许多通用目的代码的程序,可以从SMT中获得非常大的好处,因为SMT提供了一种在读取延迟和缓存不中时以往闲置时间的方式。因此,SMT表现出了一种非常复杂的,应用相关的性能图像。这对市场人员来说是个挑战,有的时候你要说它就像两个处理器一样快,有时你又说它和两个一般的处理器差不多,有时你又说它甚至不如一个单独的处理器。
Pentium 4是业界第一个采用SMT技术的处理器,Intel称之为“超线程”。它的最初设计可以支持2个线程同时运行(早期的版本因为有bug没有开启这个功能)。根据应用程序的不同,从SMT额外获得的加速在-10%到30%之间。后续的Intel处理器在重新回到“聪明人”方式的Pentium M 和 Core 2,重新回到多核设计期间,没有采用SMT。这一时期,许多SMT系列设计的处理器也取消了 (比如Alpha 21464, UltraSPARC V),在一段时间内,SMT好像不那么受欢迎了。SMT重新回归是在POWER5处理器,这是一个2线程的SMT设计,同时也是多核的(每个core两个线程,每个芯片两个core, 所以一个处理器可以最多有4个线程)。Intel的Core i系列也是2线程SMT设计的,因此一个四核的Core i处理器是一个8线程的处理器。在线程并行方面,Sun是走在最前沿的,它的UltraSPARC T1 Niagara处理器提供8个简单的有序执行的core, 每个core采用4线程SMT的方式设计,也就是说在一块芯片上支持32个线程。后续的UltraSPARC T2增加到了每个core有8个线程,再之后的UltraSPARC T3增加到了16个cores,也就是T3总共支持128个线程。
More Cores or Wider Cores?
考虑到SMT可以将线程级并行的转化为指令级并行,同时对于指令级并行友好的程序,SMT比单线程的性能更好,你可能会问,人们为什么还要创建多核的处理器,同等条件的SMT设计的处理器不是更好吗?
好吧,这不是看起来那么简单。因为非常宽的超标量设计(同一个核支持很多个线程,因此这个核的面积要比一般的核要宽很多)在处理器空间和时钟频率的扩展性方面很差。一个关键的问题是多发射、分发逻辑复杂度和发射宽度呈平方关系,因为所有n个备选指令需要都要和剩下的备选指令进行比较。考虑到顺序限制或其它发射规则,可以减少比较的次数,但是比较次数的数量级仍然是n2 ,也就是说,5发射的处理器比4发射的发射逻辑电路要多50%,6发射的差不多是2倍,7发射的差不多是3倍,8发射的4是倍(仅仅增加了2倍的发射宽度),依此类推。另外,一个非常宽的超标量设计的需要多端口的寄存器文件和缓存,来保证它们的同时访问。所有的这些都要求不仅仅增加处理器的大小,也要大量的增加集成电路内部长距离导线的数量,这给提高处理器时钟频率带来了很大的限制。所以一个10发射的处理器可能比一两个5发射的处理器占用面积更大,也更慢,我们梦想的20发射的SMT设计的处理器由于集成电路设计的限制也是不可能实现的。
尽管如此,因为SMT和多核处理器的优势都很大程度上依赖应用程序本身,那么对于不同程度的SMT和多核,一个更广泛的设计可能仍然是合理的。让我们来探索一些可能性。
今天,一个典型的SMT设计包含一个较宽的执行内核和乱序执行逻辑,具体包括多个译码器,大且复杂的超标量分发逻辑等。因此,SMT核心一般占用的面积较大。利用同样大小的面积,可能可以放好几个简单的,单发射,有序执行的core。事实上,一个乱序执行的超标量SMT设计的内核占用的面积可能可以放下6个简单的内核。
现在,考虑到指令间并行和线程间并行的收益因为不同的原因都有减少,我们之前也讲过SMT从本质上是将线程并行转换为指令并行,但是也请记住宽的超标量设计处理器的面积,设计难度,功耗都是随着处理器宽度是呈非线性扩展的。一个显然的问题是,那么哪儿是最优点(sweet spot)? 处理器的内核应该设计为多宽的才能在ILP和TLP间取得平衡?现在,人们在尝试着许多不同的方法。


Figure 15 – Design extremes: Core i*2 “Sandy Bridge” vs UltraSPARC T3 “Niagara 3”.
一方面,我们有Intel的Core i*2 Sandy Bridge处理器,它有4个大的,宽的,6发射,乱序的,采用“聪明人”方案的内核,每一个都运行着两个线程,也就是说总共可以支持8个线程。另一方面,我们有Sun/Oracle’s UltraSPARC T3 Niagara 3处理器,它有16个小的,简单的,2发射,有序执行的内核,每个运行8个线程,最多可以支持128个线程,尽管这些线程和刚说过的Sandy Bridge的线程要忙。上面两块芯片都处于同时代(2011年早期),都包含大约1亿条半导体,都是按照同样的比例尺画的。可以发现,右侧那些简单的,有序的核相比真是小好多!
那么,到底哪种方式好些呢? 这个问题没有简单的答案,又一次,这和应用非常相关。对于那些有很多活跃的,但是受限于内存延时的线程的应用(比如数据库系统,3D图像渲染),简单的核心会更好,因为大的,宽的核心将会把大部分的时间都花在内存等待上。对于大多数程序,又因为没有足够多的活跃线程来让这是可行的,在这种情况下,单线程的性能更重要, 所以含有少量的内核,但是大的,宽的,更聪明的内核是更合适的。
当然,在这两种极端情况中间有很多可能的情况我们还没有分析。比如,IBM的POWER7处理器,和上面的两个极端处理器系列是同时代的,同样内部有10亿个晶体管,它们形成了8核,每核4个线程的SMT处理器,不像Intel的Core i*2 Sandy Bridge处理器那么极端,也保持了一定的乱序执行度。AMD 的Bulldozer处理器采用了一个更加不同寻常的方式,前段采用共享式的SMT类型的核心,后端采用非共享式的独立多核的整型执行单元,同时后端有采用SMT类型的浮点计算单元,在这里SMT和多核处理器的界限非常模糊。

Figure 16 – Xeon Haswell with 18 brainiac cores, the best of both worlds?
今天(2015年),感谢摩尔定律,我们在一块芯片上可以有好几十亿个晶体管,极端的“聪明人”式的设计的处理器上可以支持很多的核。Intel的 Xeon Haswell处理器是服务器版的Core i*4 Haswell处理器,使用了57亿个晶体管打造了18个核,每个核都采用了极限的8发射设计,并且每个核还采用了2线程的SMT设计。同时IBM的POWER8 处理器使用了44亿个晶体管,对比 POWER7,它的内部设计更倾向于“聪明人”式了,它有12个核心,每个核心采用8线程的SMT设计。当然,这些大的,“聪明”的内核是否有效的利用了那些晶体管是另外一个问题了。
由于小内核(多核处理器)其单位面积的性能是最优的,大内核处理器单线程的性能又是最高的这种情况,也许未来会出现某种异构的设计:处理器内部有一个或两个大的,宽的,复杂的core, 加上大量的小的,窄的,简答的core。在许多方面来说,这样的设计是合理的,高并行的程序可以从众多小核中而不是少量的大核中获益;单线程的,顺序的程序又可以从大的,宽的,复杂的核心中获取超强的性能,即使这些大的核占用了4倍小核的面积才能提供2倍的小核的单线程的性能。
Sony PlayStation 3使用的IBM的Cell处理器,可以说是第一个采用这样的方式设计的芯片,但是不幸地是,它因为小的简单的核和大核的指令集不兼容,有严重的可编程性问题,同时,这些小的核只有有限的主内存访问权限,使得它们看起来像是特殊的协处理器,而不是一般的CPU核。一些现代的ARM处理器也采用了这样的异构方式,几个大的核心周围伴随着几个小的简单的核心,不是为了最大化多核的性能,而是机或者平板的使用量很小的时候(比如休眠),可以使这些大的,非常耗电的核心可以断电,从而增加电池使用时长,这种策略ARM称为"big.LITTLE"。
当然,如果我们拥有所有的晶体管的控制权,那么把一些次级的功能集成到CPU的主板,比如那些I/O和网络处理的功能,专用的视频编码、解码硬件,或者这个整个低端的GPU。这种集成在我们非常需要减少芯片的数量,占用的空间或者花费时非常重要,而不是那么在意将CPU主板和其它功能分开时,我们可以有更多的core, 更好的性能。这种集成对于手机,平板,以及小的,低性能的笔记本非常适合,这样的异构设计我们通常称为system-on-chip,板上系统,简称为SoC.
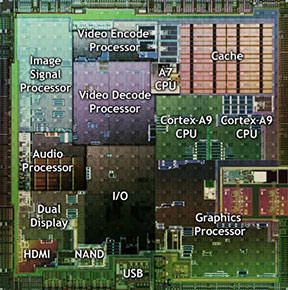
Figure 17 – A typical SoC: NVIDIA Tegra 2.
Data Parallelism – SIMD Vector Instructions
除了指令集并行和线程级并行,在许多程序中,还有另外一种并行:数据并行。数据并行的思路是找到某种方法让一条指令可以同时应用到多条数据,而不是向指令并行那样寻求多条指令并行运行。
这通常叫做SIMD(单指令,多数据:single instruction, multiple data)。更多的时候,它被叫做向量运算。超级计算机经常使用向量计算,里面的向量长度非常长。因为运行在超级计算机的科学性的程序非常适宜使用向量计算。
今天,采用向量计算的超级计算机已经被多核设计的处理器给替代了,在多核处理器里面,每个处理单元可以当做一个CPU。那么为什么我们还要重提向量计算?
在很多情况下,特别是图形,视频,和多媒体应用中,程序需要在一小组类似的数值上运行同样的指令。比如,一个图形处理的应用程序可能希望在这个小组的数据上都加上一个8比特的数,这个8比特的数据代表一个像素的红,绿,蓝色,或者透明度。
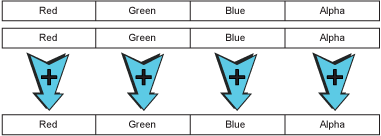
Figure 18 – A SIMD vector addition operation.
这里的加法和普通的32位数的加法几乎一样,除了第八位的进位不向前传递。同样,如果所有的8比特都是1话,加1运算这里也不希望让所有的位都变成0,而是仍然为255,这被称为饱和计算。换句话说,最高位的进位不会向前进位,而是让所有的8位比特都变成1。所以上面展示的向量加法其实就是一种修改版的32位加法运算。
从硬件的角度来看,支持这些向量指令并不难,现有的寄存器就可以使用,很多情况下现有的整型或浮点型计算的功能单元也可共用。一些其他打包和解包的指令也可以添加进来,像字节移动,一些起到类似预测作用的位掩码等。稍微用点心,一个小的向量指令集就可以带来意想不到的加速效果。
当然,没有必要停留在32位的向量上。如果正好有64位的寄存器,一些浮点数运算的寄存器通常是64位的,它们也可以用来支持64位的向量计算,因此可以将并行双倍加速。SPARC VIS 和 x86 MMX是这样做的。另外如果可以定义全新的寄存器,它们甚至可以支持更多位的向量运算,带着这样的想法:x86的SSE指令集中加入了8个新的128位的寄存器,后来改成了16个64位的寄存器,紧接着在AVX指令集中又扩容到了256位;POWER/PowerPC AltiVec提供了一个全新的含有32个128位寄存器的指令集。另外一种扩容寄存器的方法是将它们成对使用,每对寄存器在SIMD向量指令中当做一个单独的操作对象:ARM NEON处理器就是采用的这样的方法,它的寄存器既可以当成32个64位寄存器使用,也可以当成16个128位寄存器使用。
自然的,寄存器中的数据也可以采用其他的方式来划分,而不仅仅是采用8bit为一字节的方式,比如,采用16bit的整型来进行高精度图形处理,或者将浮点数作为科学计算的单元。在AltiVec, NEONv2等采用了最新版本的SSE/AVX指令中,可以将一个4路并行运行的浮点数乘法或加法转变成一条单独的,完全流水线的指令。
对于那些存在数据并行并且很容易抽取出来的程序来说,SIMD的向量指令可以产生令人惊奇的加速效果。最初适合采用SIMD向量指令的程序大多都在图像和视频处理领域,当然一些其它适合的程序也包括音频处理,语音识别,3D图像渲染和其它科学计算相关的代码。对于其它的软件,比如编译器或数据库系统,加速效果相对较小,也许可能根本就没有加速。
不幸的是,除了一些很少见的情况,让编译器在处理一般的源码时能够自动使用向量指令是非常困难的。主要的问题是因为程序员写代码时倾向于将所有的代码都线性化,这让编译器很难知道两个给定的操作是否是独立的可并行的。虽然在这方面正在缓慢的取得进展,但是现在我们基本上还是要手动重写一些代码才能利用向量指令(除了在科学计算代码中一些简单的基于数组的循环外)
幸运的是,重写你最喜欢的操作系统的图片和音视频库中关键地方的一小块代码,对其它应用也有广泛的影响。今天,许多操作系统都采用这种方法提高了它们的主要库函数,所以最终所有的多媒体和3D图形应用都确实能够用上这些高效的向量指令,这是抽象在计算机中取得的又一次成功。
几乎所有架构的处理器现在都加入了SIMD向量扩展支持,包括SPARC (VIS), x86 (MMX/SSE/AVX), POWER/PowerPC (AltiVec) 和 ARM (NEON)。在这些架构中,只有一些最近的处理器才支持这些指令,这就会有前向兼容性问题,特别是在x86中,SIMD向量指令的发展非常随意,它们的大概顺序是:MMX, 3DNow!, SSE, SSE2, SSE3, SSE4, AVX, AVX2。
Memory & The Memory Wall
之前提过,对于流水线式的处理器,延迟是个非常大的问题,特别是从内存中读数据时的延迟,这占据了所有指令1/4的运行时间。
读数据通常发生在代码的开始,所有其它的指令都依赖这些被读进来的数据。这导致所有其它指令都必须暂停等待,让获取大规模的指令并行非常困难。或许事情比第一次看上去的还糟糕,因为在实际中,大多数超标量处理器每时钟周期最多只能发射一条或者两条load指令。
内存访问的核心问题是创造一个快速的内存系统是非常困难的,一方面是因为收到物理固有极限的限制,比如光速,当一个信号传到内存然后传回时,必然有延迟,另一方面,因为组成内存单元的小的电容器相对慢的充电和放电速度。这些自然规律我们不能改变,我们必须学习它们的规律,找到利用它们的方法。
比如,主内存的访问延迟,使用现在的SDRAM的话,它的CAS延迟是11,一般是24个内存系统总线的时钟周期:1个周期发送地址到DIMM,RAS-to-CAS中行延迟11个周期,列延迟11个周期,最后1个周期将第一小块数据发送给处理器或E-cache, 接下来的数据块会在接下来的几个周期传递完毕。在一个多处理器的系统中,可能需要更多的总线时钟周期来做到不同处理器间的缓存同步。然后我们还必须考虑到处理器上也有相应一些时钟周期开销:比如检查处理器内部的缓存,如果缓存不中,将地址发送到内存控制单元,当数据从内存回到控制单元后会被送到相应的处理器。幸运的是,这些都是内部较快的CPU时钟周期,而不是内存总线时钟周期,但是它们仍然占据大约20个左右的CPU时钟周期。
假设一个典型的800 MHz的SDRAM内存系统(DDR3-1600),假设有一个2.4GHz的处理器,那么这需要(1+11+11+1)* 2400/800 + 20 = 92 个CPU时钟周期来访问主存。是的,你看,好慢!当处理器是2.8GHz时,需要104个时钟周期来访问主存,3.2GHz时,需要104个时钟周期,3.6GHz时,需要128个时钟周期,4.0GHz时,需要140个时钟周期。
考虑到DDR SDRAM内存系统可以在其时钟信号的上升沿和下降沿都传输数据,那么真实的内存系统总线的时钟周期是其所标称的一半,而控制信号是根据内存系统总线的时钟周期进行调节的。那么对于一个DDR的内存系统来说,它和non-DDR的内存系统,它们的时延时一样的,即使DDR内存系统的带宽是non-DDR系统的两倍。
旧型号的处理器更差,因为它们的内存控制器不在处理器内部,而是在集成电路的母板上,这就增加了2个母板系统总线的时钟周期用来进行内存地址和数据在母板芯片与处理器之间的传输。由于母板系统总线的时钟速度当时仅有200MHz或者更低,而不是800MHz, 所以2个母板系统总线的时钟周期差不多对应20多个CPU时钟周期。一些处理器尝试通过增加处理器与母板之间的前端总线(FSB:frontside bus)速度的方法来减轻这个问题。另一个现代处理器都用到的办法是将内存控制器集成到处理器内部,这样原先的2个总线周期就转化为了2个CPU周期。 UltraSPARC IIi 和 Athlon 6是首先采用这种方法的主流处理器,Intel加入这个阵列比较晚,直到Core i系列才这么做。
不幸的是,不管采用 DDR SDRAM内存还是处理器内部的内存控制器,内存延迟仍然是一个主要的问题。处理器和内存速度慢慢的相差越来越大的这个问题被称为内存墙( memory wall)。这一段时间内,这个问题是排在处理器设计者面前唯一重要的问题。尽管目前这个问题已经稍微减轻了,因为处理器的时钟频率因为电源和发热的限制( power wall)不像之前爬升的那么快了。
虽然如此,内存墙仍然是一个非常大的问题。
Caches & The Memory Hierarchy
现代处理器通过caches解决了内存墙的问题。Cache就是一块位于处理器内部或者附近的小儿快的内存。它的作用是保存主存的一小块,当处理器想要获得主存的一小块特点内存时,如果数据就在cache中,可以通过cache更快的获取。
一般的,处理器内部,在每个核内部,有小而快的重要的L1 caches,它的大小在8-64k, 同时有离核较远但仍然在处理器内部的L2 cache,它的大小稍大,一般几百KB到几MB, 也可能有一个更大的但慢很多的L3 cache等。这些处理器内部的cache, 和处理器外部的cache(称为E-cache, external cache),以及主存(RAM),它们一块构成了一个内存层次结构:后一个level的都比见一个的大但是速度要慢。在内存层次结构的最底层,是虚拟内存(paging/swapping),虚拟内存通过和文件系统采用换页的方式是得真个主存的空间看起来像是有无穷大。
就像在一个图书馆的书桌前看书…你可能桌上放在两三本打开的书,获取它们的信息是很快的,只需要看一看就好了,但是桌子上同时放不小更多的书,即使你可以在一个大桌子上放100本书,但是获取某一本的信息花的时间也会边长一些因为你必须起身走动了。作为替代,你在桌子的一角堆了10多本书,获取它们的信息也很慢,因为你必须探身伸手去打开查看。每次你打开一本,你必须把桌上已经打开的一本放回去来为新打开的腾一点空间。最后,当你想看一本不在桌子上打开着,也不在边上的书堆中的书的时候,你必须起身到图书馆的书架中去找,这非常慢。但是图书馆是这么大,意味着你可以访问成千上万的书,远比你可以放在桌上的多。
一个典型的内存层次结构向下面这样:
| Level | Size | Latency | Physical Location |
|---|---|---|---|
| L1 cache | 32 KB | 4 cycles | inside each core |
| L2 cache | 256 KB | 12 cycles | beside each core |
| L3 cache | 6 MB | ~21 cycles | shared between all cores |
| L4 E-cache | 128 MB | ~58 cycles | separate eDRAM chip |
| RAM | 4+ GB | ~117 cycles | SDRAM DIMMs on motherboard |
| Swap | 100+ GB | 10,000+ cycles | hard disk or SSD |
Table 4 – The memory hierarchy of a modern desktop/laptop: Core i*4 Haswell.
即使手机也会有这样的内存层次结构:
| Level | Size | Latency | Physical Location |
|---|---|---|---|
| L1 cache | 64 KB | 4 cycles | inside each core |
| L2 cache | 1 MB | ~20 cycles | beside the cores |
| L3 cache | 4 MB | ~107 cycles | beside the memory controller |
| RAM | 1 GB | ~261 cycles | separate SDRAM chip |
| Swap | N/A | N/A | paging/swapping not used on iOS |
Table 5 – The memory hierarchy of a modern phone: Apple A8 in the iPhone 6.
最让人赞叹的是这些层次中的caches起到了非常好的作用:它们使整个内存系统速度上看起来就像L1 cache那么快,容量上看起来像主存那么大。一个现代的主要的L1 cache的时延只有2到4个处理器时钟周期,这比访问主存要快几十倍,并且L1 cache的命中率达到90%。所以90%的时间,访问内存都只需要花几个时钟周期。
Cache之所以能够取得这样惊人的命中率,是由于程序的工作方式决定的。多数的程序都体现出了时间局部性和空间局部性,时间局部性是指当程序访问了一块内存后,很有可能它会在不久之后再次访问这块内存,空间局部性是指程序很可能在不久之后访问这块内存周边的内存。根据时间局部性,计算机将最近访问的数据都放到缓存中,根据空间局部性,数据是以块的方式一次性从内存传输到缓存中的。
从硬件的角度来看,cache就像一个两列的表格,一列是内存地址,一列是数据块。当然,在实际中,cache只需要保存地址的高端部分的值,因为低端部分的地址用来索引,查找是通过低端的索引来找到cache行,然后通过高端的部分,这里称为tag来匹配具体的数据,当找到匹配的tag,说明cache命中,相应的数据就会送到处理器核心中去。
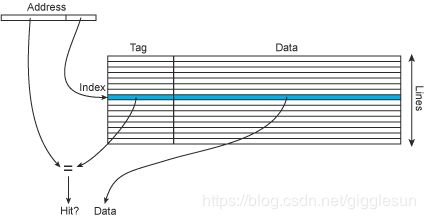
Figure 19 – A cache lookup.
物理内存地址和虚拟内存地址都可以用来作为cache查找。就像计算机中的其它情况,它们各有优缺点。采用虚拟地址可能会引起其它问题,因为不同的程序采用同样的虚拟地址来映射到不同的物理地址,那么如果有上下文切换,那么cache必须被刷新。另一方面,如果使用物理地址,意味着必须进行虚拟到物理地址的转换才能进行cache查找,这样将会使每次的查找变慢。一个常用的技巧是使用虚拟地址来进行cache索引,采用物理地址来进行打tag。这样虚拟到物理的查找(TLB查找)和cache的索引可以并行进行,索引当进行tag比较时,物理地址已经获得了。采用这种方式的cache称为virtually-indexed physically-tagged cache。
处理器中各级缓存的大小和速度对处理器的性能非常重要。其中最为重要的是主要的L1数据cache和L1指令cache。有的处理器用小的L1缓存(Pentium 4E Prescott, Scorpion 和 Krait 采用 16k L1的 caches :I-cache 和 D-cache各16k,早期的Pentium 4s 和 UltraSPARC T1/T2/T3更小,只有8k),大多数处理器采用32k,少数的处理器采用64k,比如Athlon, Athlon 64/Phenom, UltraSPARC III/IV, Apple A7/A8,偶尔有128k的,比如Denver的I-cache是128k,D-cache是64k的。
对于现代处理器的L1 D-cache,读取延迟通常是3-4个时钟周期,这取决于处理器的时钟速度,有时也可能更短(UltraSPARC III/IV只需要2个时钟周期,是由其采用更少时钟周期的流水线的原因,早期的处理器也只要2个时钟周期,这是由于其时钟速度较慢,流水线更短的原因)。增加一个时钟周期,比如从3到4,从4到5,看起来好像一个很小的变化,但是对性能却有严重的影响,最终用户很少注意到这些也不理解这些。正常情况来说,我们日常使用的指针解引用代码,处理器的读入延迟是影响其性能的重要因素。
现代处理器都有一个大容量的二级或者三级的在处理器内部的cache,它们通常由所有的核共享。这个cache也很重要,但是它的最佳大小取决于运行的程序和程序的工作指令集(working set),有时,2MB或者8MB的L3 cache对某些应用程序来说,性能差别不大,但是对某些应用程序却影响很大。考虑到相对小的L1 cache已经占据了芯片面积的很大一部分,你可以想一下一个更大的L2或者L3 cache要占据多少面积,尽管如此,cache也是我们和memory wall进行斗争所必需的。通常,较大的L2/L3 cache占据了处理器差不多一半的区域,以致于我们在芯片的图片中,我们可以肉眼看到它们,它们的特征是相对简单的结构重复了很多次,相对比,处理器的逻辑电路和内存控制部分则闲的杂乱很多。
Cache Conflicts & Associativity
理想情况下,cache应该保存将来最有可能用到的数据。因为cache不可以预知未来,那么最好的方法是保存最近用到的数据。
不幸的是,严格保存最近用到的数据意味着来自内存任何地方内存的数据可能被放到任意的一条cache line。因此cache可能包含着最近用到的n KB数据,这对于利用局部性原理非常重要,但是却不利于快速访问数据,访问cache将需要检查每一条cache line,看它是否可以匹配,这在有数百条cache line的现代处理器中是非常慢的。
然而,cache系统通常只允许来自某个实际内存地址的数据占据一个,或者cache中的几个位置。因此,在访问cache时,只需做一次或者几次检查就可以了。这种方法也有缺点,这意味着cache其实没有严格存储最近访问到的数据,因为几个真实内存中不同的位置将会映射到cache中的同一个cache line。当这几个真实的位置中的两个或多个需要被差不多同时访问时,这种场景通常称为cache conflict.
Cache 冲突可能造成最坏的性能问题,因为当一个程序反复的访问映射到同一块cache line的不同内存地址时,那么cache必须一直从内存中写数据和读数据,因此会遭受严重的内存访问延迟(可能100个CPU周期或者更多)。这种情况称为cache失效,因为cache没有取得任何效果,反而起到了副作用。尽管有明显的时间和空间局部性,cache在这种情况下却不能够利用这种特性。
为了解决这种问题,更复杂的cache将可以将可以允许将不同地方的数据放到cache中,而不是只能放在一个地方。一个地方的数据可以放到缓存中位置的个数称为associativity. Associativity这个词来自cache查找通常是通过关联association 来进行的,也就是说,一个特定的地址关联一个特定的cache的位置。
就像上面描述的那样,最简单和最快的cache允许一个cache line和一个特定内存的数据对应:每个实际数据通过 address % size这样的公式对应到cache行(只需要address的最低位就可以找到cache行了),这通常称为direct-mapped cache. 在direct-mapped cache中内存地址的低端几位一样就会映射到同一个cache line,这就会产生cache conflict。
一个允许数据可以根据其地址在cache中占据2个可选区域中的一个的cache系统称为2 way set-associative. 同样,一个4-way set-associative的cache系统将提供4个可选区域,8-way的提供8个可选区域,依此类推。Set-associative caches和direct-mapped cache的工作方式基本相同,除了一点,在Set-associative caches中有多个2列的表,它们可以并行的被索引和比较tag来检查是否匹配。
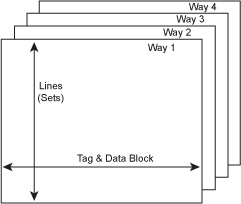
Figure 20 – A 4-way set-associative cache.
每个表,或者说是way, 也可能有一个标志位来决定当一个新的数据行要进到cache中时,其中那个最少用的cache line将被换出,或者采用其它类似的idea来进行。
通常,set-associative caches可以解决direct-mapped caches中经常发生的cache conflicts的问题。添加更多的way可以避免更多的冲突。不幸的是,如果way越多,查找就越慢,因为在一次访问中要做更多操作。即使这些比较时并行进行的,如果缓存命中,需要用额外的逻辑电路来选择合适的命中的cache, 也需要更新每个way的标志位。也需要更多的芯片面积,因为cache数据中的相当一部分被tag信息而不是数据信息消耗了。这些因素中的任何一个都对访问时间有不好的影响。因此,一个2-way set-associative cache比direct-mapped cache要慢但是更聪明,4-way或8-way的更聪明也更慢。
在大多数现代处理器中,I-cache通常可以是有很多way的set-associative 的cache,因为它的延迟被处理器流水线早期stage的取指令和缓存指令掩盖了。D-cache则不一样,它可以是某种程度的set-associative ,但是不能是很多way的set-associative,因为它必须减少加载延迟。现在大多数处理器都倾向于采用4-way set-associative cache, 但是也有少量2-way set-associative,比如Athlon, Athlon 64/Phenom, PowerPC G5 和Cortex-A15/A5处理器,也有一些采用更多way的,比如 PowerPC G4e, Pentium M和Core系列都是8-way的。作为前往遥远的内存前的最后一次努力,较大的L2/L3 cache(有时称为"last-level cache"或LLC)通常都是很多way的set-associative cache, 也许多达12或16-way。而处理器外部的E-cache通常采用direct-mapped的方式以获得大小和实现的灵活度。
Cache的概念也扩展到了软件系统。比如,操作系统采用主存来cache住文件系统以此来加速文件I/O, 网页浏览器cache住最近访问的页面,图片和JavaScript文件以避免你重复访问这些站点,网页cache服务器(通常叫做proxy cache或者CDN)cache住远端web服务器的内容到一个本地的服务器。对于主存和虚拟存储(paging/swapping),它们可以看做一个智能的,高度associative的cache,就像我们上面提到的理想的cache.毕竟,虚拟存储是由较智能的软件(系统内核)来管理的。
Memory Bandwidth vs Latency
内存是以块为单位传输的,缓存不中是让CPU运行变慢的最严重的因素,那么内存块的传输速度非常重要。内存系统的传输速度称为带宽。这和它的延迟有什么区别呢?
一个好的比喻是高速公路…比如你想开车到100英里外的地方。通过增加车道,每小时可以通行的车辆数目加倍了(带宽),但是你的行驶时间(延迟)不会减少。如果你想做的是增加每秒钟通过的车辆数,那么添加更多的车道(宽的传输总线)是问题的答案,如果你想做的是减少某辆车从A开到B的时间,那么你要么提高速度限制,高速公路的限速和车速(总线速度和内存速度),或者减少距离,或者在本地建一个购物中心(缓存),这样就没必要开到市区购物了。
当应用到内存系统时,我们应该平衡考虑延迟和带宽。低延迟的设计对于那些指针解引用的代码更好,比如编译器或者数据库系统,同时高带宽的系统对于那些简单,线性访问的程序,比如图形处理和科学代码。当然,增加带宽相对比较容易,要么简单的增加更多的内存块同时增加系统总线的宽度,这可以容易的将带宽加倍或者变成4倍。事实上,许多高端系统采用这样的方法来提高性能,但是这也有缺点,比如,宽的总线意味着母板更贵,内存添加到系统的限制更严格(必须成对或以4个一组的方式添加),内存系统的配置更复杂。
不幸的是,内存延迟比起带宽更难改进,就像一句谚语说的:“你不能贿赂上帝”。(物理极限的存在)。即便如此,过去的几年里,也有一些在内存延迟上的改进,主要在同步时钟的DRAM(SDRAM)内存,它和内存总线的时钟周期相同。SDRAM的主要优点是它支持内存系统的流水线,因为SDRAM的内部计时部分和其分支结构都开放给了系统,系统因而可以利用这些。这有效的减少了内存延迟因为它允许在旧的内存访问没结束时就开始一个新的内存访问,因此减少了旧的异步DRAM系统中的等待时间。
上面的方法除了减少延迟,也可以潜在的增加带宽,因为在SDRAM系统中,多个内存请求可能在任一时间同时存在,它们可以被处理器采用高效的,完全流水线的方式处理。 采用流水线可以大幅提高内存带宽,一个SDRAM内存系统通常是同时代异步内存系统带宽的2到3倍,同时它的延迟也只是稍微的高一点,并且采用的时差不多的内存技术。
那么将来内存技术的提高,以及更多级别的cache,可以让我们抵挡memory wall,同时带宽可以扩展到更多水平以满足更多核的需求吗?或者我们很快就会遇到内存的瓶颈,不管是带宽还是时延方面,处理器微架构或者核的数目方面不管做出什么改变,内存系统总是最关键的因素?我们可以拭目以待,同时预测未来肯定不会那么容易,但是也有很多理由可以让我们保持乐观。
Acknowledgments
这篇文章的整体风格,特别的关于处理器的“指令流”和微架构图表那部分的风格,是源于以下几部分的组合:一篇1989年著名的ASPLOS论文,作者是Norman Jouppi 和 David Wall, Shlomo Weiss 和 James Smith的书POWER & PowerPC,以及Hennessy和Patterson的两本著名的教科书:Computer Architecture: A Quantitative Approach 和 Computer Organization and Design.
在我看来,也许你可以找到许多关于本文的材料,它们应该看起来都差不多,但是我认为上面列举的四个材料毫无疑问是最好的,如果你想深入学习这个主题,它们是最好的起点。