无损数据压缩算法的历史
引言
有两种主要的压缩算法: 有损和无损。有损压缩算法通过移除在保真情形下需要大量的数据去存储的小细节,从而使文件变小。在有损压缩里,因某些必要数据的移除,恢复原文件是不可能的。有损压缩主要用来存储图像和音频文件,同时通过移除数据可以达到一个比较高的压缩率,不过本文不讨论有损压缩。无损压缩,也使文件变小,但对应的解压缩功能可以精确的恢复原文件,不丢失任何数据。无损数据压缩被广泛的应用于计算机领域,从节省你个人电脑的空间,到通过web发送数据。使用Secure Shell交流,查看PNG或GIF图片。
无损压缩算法可行的基本原理是,任意一个非随机文件都含有重复数据,这些重复数据可以通过用来确定字符或短语出现概率的统计建模技术来压缩。统计模型可以用来为特定的字符或者短语生成代码,基于它们出现的频率,配置最短的代码给最常用的数据。这些技术包括熵编码(entropy encoding),游程编码(run-length encoding),以及字典压缩。运用这些技术以及其它技术,一个8-bit长度的字符或者字符串可以用很少的bit来表示,从而大量的重复数据被移除。
历史
直到20世纪70年代,数据压缩才在计算机领域开始扮演重要角色,那时互联网变得更加流行,Lempel-Ziv算法被发明出来,但压缩算法在计算机领域之外有着更悠久的历史。发明于1838年的Morse code,是最早的数据压缩实例,为英语中最常用的字母比如"e"和"t"分配更短的Morse code。之后,随着大型机的兴起,Claude Shannon和Robert Fano发明了Shannon-Fano编码算法。他们的算法基于符号(symbol)出现的概率来给符号分配编码(code)。一个符号出现的概率大小与对应的编码成反比,从而用更短的方式来表示符号。
两年后,David Huffman在MIT学习信息理论并上了一门Robert Fano老师的课,Fano给班级的同学两个选项,写一篇学期论文或者参加期末考试。Huffman选择的是写学期论文,题目是寻找二叉编码的最优算法。经过几个月的努力后依然没有任何成果,Huffman决定放弃所有论文相关的工作,开始学习为参加期末考试做准备。正在那时,灵感爆发,Huffman找到一个与Shannon-Fano编码相类似但是更有效的编码算法。Shannon-Fano编码和Huffman编码的主要区别是构建概率树的过程不同,前者是自下而上,得到一个次优结果,而后者是自上而下。
早期的Shannon-Fano编码和Huffman编码算法实现是使用硬件和硬编码完成的。直到20世纪70年代互联网以及在线存储的出现,软件压缩才被实现为Huffman编码依据输入数据动态产生。随后,1977年Abraham Lempel 和 Jacob Ziv发表了他们独创性的LZ77算法,第一个使用字典来压缩数据的算法。特别的,LZ77使用了一个叫做slidingwindow的动态字典。1778年,这对搭档发表了同样使用字典的LZ78算法。与LZ77不同,LZ78解析输入数据,生成一个静态字典,不像LZ77动态产生。
法律问题
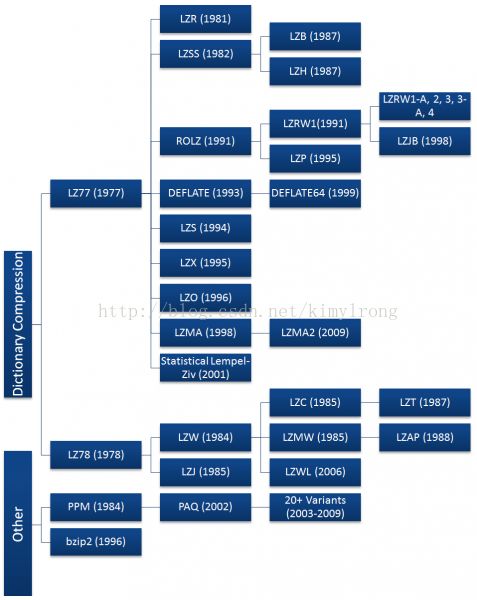
LZ77和LZ78都快速的流行开来,衍生出多个下图中所示的压缩算法。其中的大多数已经沉寂了,只有那么几个现在被大范围的使用,包括DEFLATE,LZMA以及LZX。绝大多数常用的压缩算法都衍生于LZ77,这不是因为LZ77技术更好,只是由于Sperry在1984年申请了LZ78衍生算法LZW的专利,从而发展受到了专利的阻碍,Sperry开始因专利侵权而起诉软件提供商,服务器管理员,甚至是使用GIF格式但没有License的终端用户。
同时,UNIX压缩工具使用了一个叫LZC的LZW算法微调整版本,之后由于专利问题而被弃用。其他的UNIX开发者也开始放弃使用LZW。这导致UNIX社区采用基于DEFLATE的gzip和基于Burrows-Wheeler Transform的bzip2算法。长远来说,对于UNIX社区这是有好处的,因为gzip和bzip2格式几乎总是比LZW有更好的压缩比。围绕LZW的专利问题已经结束,因为LZW的专利2003年就到期了。尽管这样,LZW算法已经很大程度上被替代掉了,仅仅被使用于GIF压缩中。自那以后,也有一些LZW的衍生算法,不过都没有流行开来,LZ77算法仍然是主流。
另外一场法律官司发生于1993,关于LZS算法。LZS是由Stac Electronics开发的,用于硬盘压缩软件,如Stacker。微软在开发影片压缩软件时使用了LZS算法,开发的软件随着MS-DOS 6.0一起发布,声称能够使硬盘容量翻倍。当Stac Electronics发现自己的知识财产被使用后,起诉了微软。微软随后被判专利侵权并赔偿Stac Electronics1亿2000万美元,后因微软上诉因非故意侵权而减少了1360万美元。尽管Stac Electronics和微软发生了一个那么大的官司,但它没有阻碍Lempel-Ziv算法的开发,不像LZW专利纠纷那样。唯一的结果就是LZS没有衍生出任何算法。
Deflate的崛起
自从Lempel-Ziv算法被发表以来,随着对存储需求的不断增长,一些公司及其他团体开始使用数据压缩技术,这能让他们满足这些需求。然而,数据压缩并没有被大范围的使用,这一局面直到20世纪80年代末期随着互联网的腾飞才开始改变,那时数据压缩的需求出现了。带宽限额,昂贵,数据压缩能够帮助缓解这些瓶颈。当万维网发展起来之后人们开始分享更多的图片以及其它格式的数据,这些数据远比文本大得多,压缩开始变得极其重要。为了满足这些需求,几个新的文件格式被开发出来,包括ZIP,GIF,和PNG。
Thom Henderson通过他的公司发布了第一个成功的商业存档格式,叫做ARC,公司名为为System Enhancement Associates。ARC在BBS社区尤为流行,这是因为它是第一个既可以打包又可以压缩的程序,此外还开放了源代码。ARC格式使用一个LZW的衍生算法来压缩数据。一个叫做Phil Katz的家注意到了ARC的流行并决定用汇编语言来重写压缩和解压缩程序,希望改进ARC。他于1987发布了他的共享软件PKARC程序,不久被Henderson以侵犯版权为由起诉。Katz被认定为有罪,并被迫支付版权费用以及其它许可协议费用。他之所以被认定侵权,是由于PKARC是明显抄袭ARC,甚至于一些注释里面的错别字都相同。
Phil Katz自1988年之后就因许可证问题不能继续出售PKARC,所以1989年他创建了一个PKARC的修改版,就是现在大家熟知的ZIP格式。由于使用了LZW,它被认为专利侵权的,之后Katz选择转而使用新的IMPLODE算法,这种格式于1993年再次被修改,那时Kata发布了PKZIP的2.0版本,那个版本实现了DEFLATE算法以及一些其它特性,如分割容量等。这个ZIP版本也是我们现在随处可见的格式,所有的ZIP文件都遵循PKZIP 2.0格式,尽管它年代久远。
GIF格式,全称Graphics Interchange Format,于1987年由CompuServe创建,允许图像无失真地被共享(尽管这种格式被限定每一帧最多256种颜色),同时减小文件的大小以允许通过数据机传输。然而,像ZIP格式一样,GIF也是基于LZW算法。尽管专利侵权,Unisys没有办法去阻止GIF的传播。即使是现在,20年后的今天,GIF仍然被使用着,特别是它的动画能力。
尽管GIF没有办法被叫停,CompuServe需找一种不受专利束缚的格式,并于1994年引入了Portable Network Graphics (PNG) 格式。像ZIP一样,PNG使用DEFLATE算法来处理压缩。尽管DELLATE的专利属于Katz,这个专利并不是强性制的,正是这样,PNG以及其它基于DEFLATE的格式避免了专利侵权。尽管LZW在压缩历史的初期占据霸主位置,由于Unisys公司的好诉讼作为,LZW慢慢的淡出主流,大家转而使用更快更高效的DEFLATE算法。现在DEFLATE是使用得最多的算法,有些压缩世界里瑞士军刀的味道。
除了用于PNG和ZIP格式之外,计算机世界里DEFLATE也被频繁的用在其它地方。例如gzip(.gz)文件格式也使用了DEFLATE,gzip是ZIP的一个开源版本。其它还包括HTTP, SSL, 以及其它的高效压缩网络传输数据的技术。
遗憾的是,Phil Katz英年早逝,没能看到他的DEFLATE算法统治计算机世界。有几年的时间他酗酒成性,生活也于20世纪90年代末期开始支离破碎,好几次因酒驾或者其它违法行为而被逮捕。Katz于2000年4月14号被发现死于一个酒店的房间,终年37岁。死因是酒精导致的严重胰腺出血,身旁是一堆的空酒瓶。
当前的一些归档软件
ZIP以及其它基于DEFLATE的格式一直占据主导地位,直到20世纪90年代中期,一些新的改进的格式开始出现。1993年,Eugene Roshal发布了一个叫做WinRAR的归档软件,该软件使用RAR格式。最新的RAR结合了PPM和LZSS算法,前面的版本就不太清楚了。RAR开始在互联网分享文件方面成为事实标准,特别是盗版影像的传播。1996年一个叫bzip2d的Burrows-Wheeler Transform算法开源实现发布,并很快在UNIX平台上面流行开来,大有对抗基于DEFLATE算法的gzip格式。1999年另外一个开源压缩程序发布了,以7-Zip或.7z的格式存在,7-Zip应该是第一个能够挑战ZIP和RAR霸主地位的格式,这源于它的高压缩比,模块化以及开放性。这种格式并不仅限于使用一种压缩算法,而是可以在bzip2, LZMA, LZMA2, 和 PPMd算法之间任意选择。最后,归档软件中较新的一个格式是PAQ*格式。第一个PAQ版本于2002年由Matt Mahoney发布,叫做PAQ1。PAQ主要使用一种叫做context mixing的技术来改进PPM算法,context mixing结合了两个甚至是多个统计模型来产生一个更好的符号概率预测,这要比其中的任意一个模型都要好。
压缩技术
有许多不同的技术被用来压缩数据。大多数技术都不能单独使用,需要结合起来形成一套算法。那些能够单独使用的技术比需要结合的技术通常更加有效。其中的绝大部分都归于entropy编码类别下面,但其它的一些技术也挺常用,如Run-Length Encoding和Burrows-Wheeler Transform。
Run-Length Encoding
Run-Length Encoding是一个非常简单的压缩技术,把重复出现的多个字符替换为重复次数外加字符。单个字符次数为1。RLE非常适合数据重复度比较高的数据,同一行有很多像素颜色相同的渐进图片,也可以结合Burrows-Wheeler Transform等其它技术一起使用。
下面是RLE的一个简单例子:
输入: AAABBCCCCDEEEEEEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA输出: 3A2B4C1D6E38A
Burrows-Wheeler Transform
Burrows-Wheeler Transform是1994年发明的技术,目的是可逆的处理一段输入数据,使得相同字符连续出现的次数最大化。BWT自身并不做任何的压缩操作,仅简单地转化数据,让Run-Length Encoder等压缩算法可以更有效的编码。
BWT算法很简单:
- 创建一个字符串数组。
- 把输入字符串的所有排列组合塞入上述字符串数组。
- 按照字符顺序为字符串数组排序。
- 返回数组的最后一列。
BWT通常处理有很多交叉重复字符的长字符串时效果很好。下面是一个有着理想输入的例子,注意&是文件结束符:
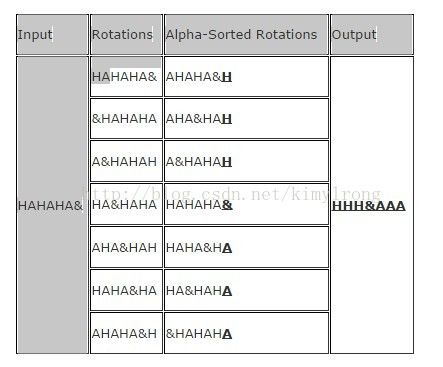
因为交换相同的符号到一起,输入数据在BWT处理之后得到优化后的结果,另外一个算法可以对该结果进行压缩,比如RLE会得到"3H&3A"。尽管这个例子得到了一个较优的结果,不过现实世界中的数据它不总是这样。
Entropy Encoding
数据压缩中,平均来说为了表示一个字符或短语,Entropy意味着所需要的最少bit数。一个基本的entropy编码器包括一个分析模型以及一套编码。输入文件被解析,并产生一个由字符出现概率组成的统计模型。然后,编码器可以利用该统计模型去决定该给每一个字符多少个bit,从而使得最常用的字符用最短的编码,反之最不常用的字符用最长的编码。
Shannon-Fano Coding
这是最早的压缩技术,于1949年由Claude Shannon和Robert Fano发明。这个技术的其中一个步骤是产生一个代表字符出现概率的二叉树。字符以这样一种方式排序,出现得越频繁的字符越靠近树的顶端,越不常见的越靠近树的底部。
一个字符对应的编码通过搜索Shannon-Fano来获得,此外,左分支后面加0,右分支加1。例如,"A"是两个左节点后接一个右节点,那么对于的编码为"0012"。Shannon-Fano coding不总是能够产生最优的编码,主要是由于二叉树是自下而上构建的。由于这个原因,使用的较多的还是对于任意输入都能够得到最优编码的Huffman coding。
产生Shannon-Fano编码的算法很简单:
- 解析输入,统计每一个字符出现的频率。
- 根据是上述频率计算字符的概率。
- 依据概率对字符降序排序。
- 为每一个字符生成一个叶节点(LeafNode)
- 把字符列表分为左右两部分,使得左边的概率与右边的概率大致相当。
- 左节点加编码"0",右节点加编码"1"。
- 对两棵子树重复的步骤5和6,直到所有的字符节点都成为叶子节点。
Huffman Coding
Huffman Coding是另外一个entropy coding的例子,与Shannon-Fano Coding非常的相似,只是为了产生最优编码二叉树是自上而下构建的。
生成Huffman编码的算法前面的三个步骤与Shannon-Fano完全相同:
- 解析输入,统计每一个字符出现的频率。
- 根据是上述频率计算字符的概率。
- 依据概率对字符降序排序。
- 为每一个字符生成一个叶节点(LeafNode),节点包含概率信息P,把节点存入一个队列Queue。
- While (Nodes in Queue > 1)
- 从队列里面取出概率最小的两个节点。
- 给左节点分配编码"0",右节点分配编码"1"。
- 创建一个新的节点,其概率为上面步骤中的两个节点之和。
- 把两个节点中的第一个设置为新建节点的左节点,第二个节点为新建节点的右节点。
- 把新建节点存入队列
- 最后一个节点就是二叉树的根节点。
Arithmetic Coding
1979年该算法在IBM被开发出来,当时IBM正在调研一些压缩算法,以期用于它们的大型机上。如果单论压缩比,Arithmetic coding确实是一个最优的entropy coding技术,通常压缩比方面Arithmetic Coding要比Huffman Coding表现得更好。然而,它却也比其它技术复杂得多。
不像其它技术会把字符概率构建成一棵树,arithmetic coding把输入转化为一个0到1之间的有理数,输入字符的个数记为base,里面每一个不同的字符都分配一个0到base之间的值。然后,最后转化为二进制得到最终的结果。结果也可以通过把base恢复为原来的base值,替换为对应字符而得到原输入值。
一个基本的计算arithmetic code算法如下:
- 计算输入数据里面不同字符的个数。这个数字记为base b(比如 base 2代表2二进制)。
- 按字符出现的顺序分别给每一个字符分配一个0到b之间的值。
- 使用步骤2中德值,把输入中的字符替换为对应的数字(编码)。
- 把步骤3中得到的结果从b进制转化为2进制。
- 如果解码需要的话,记录输入的字符总个数。
下面是一个编码操作的例子,输入为"ABCDAABD":
- 找到共有4个不同的字符输入, base = 4, length = 8。
- 按出现顺序为不同的字符赋值: A=0, B=1, C=2, D=3。
- 用编码替换字符,得到“0.012300134”,注意最前面的"0."是为了得到小数而加上去的。最后的4表示base=4。
- 把“0.012300134”从4进制转化为2进制,得到“0.011011000001112”。最后的2表示base=2。
- 在结果中标识输入的总字符数为8。
假设字符为8个bit表示,输入共需要64个bit空间,然而对应的arithmetic coding只有15个bit,压缩比为24%,效果显著。这个例子展示了arithmetic coding是如何良好的压缩固定字符串的。
压缩算法
Sliding Window Algorithms
LZ77
LZ77发表于1977年,是名副其实的压缩算法开山之作。它首次引入'sliding window'的概念,相较几个主要的压缩算法,压缩比都有非常明显的提高。LZ77维护了一个字典,用一个三元组来表示offset,run length和分割字符。offset表示从文件起始位置到当前Phase的起始位置的距离,run length记录当前Phase有多少个字符,分割符仅用于分割不同的Phase。Phase就是offset到offset+length之间的子串减掉分隔符。随着文件解析的进行,基于sliding window字典会动态的变化。例如,64MB的sliding window意味着四点将包含64M的输入数据的信息。
给定一个输入为"abbadabba",那么输出可能像"abb(0,1,'d')(0,3,'a')",如下图所示:
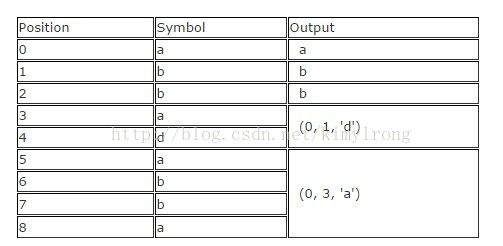
尽管上述的替换看起来比原数据还要大,当输入数据更大一些的时候,效果会比较好。
LZR
LZR是LZ77的修改版本,于1981年由Michael Rodeh发明。这个算法目标是成为LZ77的一个线性时间替换算法。然而,编码后Udell指针可能指向文件的任意offset,意味着需要耗费可观的内存。加之压缩比表现也差强人意(LZ77好得多),LZR算是一个不成功的LZ77衍生算法。
DEFLATE
DEFLATE于1993年由Phil Katz发明,是现代绝大多数压缩任务的基石。它仅仅结合了两种算法,先用LZ77或LZSS预处理,然后用Huffman编码,快速的得到不错的压缩结果。
DEFLATE64
DEFLATE64是DEFLATE的一个有专利的扩展,把字典的大小提高到64K(名字随之),从而允许在sliding window里面有更大的距离。相比于DEFLATE,DEFLATE64在性能和压缩比方面都有提高。然而,由于DEFLATE64的专利保护以及相较DEFLATE并没有特别明显的提高,DEFLATE64很少被采用。相反一些开源算法如LZMA被大量的使用。
LZSS
LZSS,全称Lempel-Ziv-Storer-Szymanski,于1982年由James Storer发表。LZSS相较LZ77有所提高,它能检测到一个替换是否真的减小了文件大小。如果文件大小没有减小,不再替换输入值。此外,输入段被(offset, length)数据对替换,其中offset表示离输入起始位置的bytes数量,length表示从该位置读取了多少个字符。另外一个改进是去除了"next character"信息,仅仅使用offset-length数据对。
下面是一个输入为" these theses"简单的例子,结果为" these(0,6)s",仅仅节省了一个Byte,不过输入数据大的时候效果会好得多。
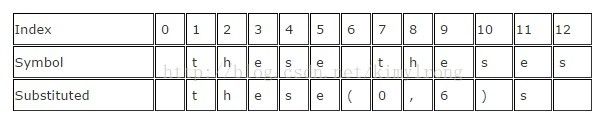
LZSS依然被用在许多使用广泛的归档格式中,其中最知名的是RAR。LZSS有时也被用于网络数据压缩。
LZH
LZH发明于1987年,全称为"Lempel-Ziv Huffman"。它是LZSS的一个衍生算法,利用Huffman coding压缩指针,压缩效果有微小的提高。然而使用Huffman coding带来的提高实在是很有限,相较于使用Huffman coding带来的性能损失,不足为取。
LZB
LZB同样发明于1987年,同样是LZSS的衍生算法。如LZH一样,LZB也致力于通过更加有效的编码指针以达到更好的压缩效果。它的做法是随着sliding window变大,逐步的增大指针的数量。它的压缩效果确实比LZSS和LZH要好,不过因为额外的编码步骤,速度上比LZSS慢得多。
ROLZ
ROLZ全称"Reduced Offset Lempel-Ziv",它的目标是提高LZ77的压缩效果,通过限制offset的大小,从而减少为offset-length数据对编码的数据量。这项LZ77的衍生技术于1991年首次出现在Ross Williams的LZRW4算法里面。其它的实现包括BALZ,QUAD,和 RZM。高度优化的ROLZ能够达到接近LZMA的压缩比,不过ROLZ不太流行。
LZP
LZP全称"Lempel-Ziv + Prediction"。它是ROLZ算法的一个特殊案例,offset减小到1。有几个衍生的算法使用不同的技术来实现或加快压缩速度,或提高压缩比的目标。LZW4实现了一个数字编码器达到了最好的压缩比,不过牺牲了部分速度。
LZRW1
Ron Williams于1991年发明了这个算法,第一次引入了Reduced-Offset Lempel-Ziv compressiond的概念。LZRW1能够达到很高的压缩比,同时保持快速有效。Ron Williams也发明另外几个基于LZRW1改进的衍生算法,如LZRW1-A, 2, 3, 3-A, 和4。
LZJB
Jeff Bonwick于1998年发明了Lempel-Ziv Jeff Bonwick算法,用于Solaris操作系统的Z文件系统(ZFS)。它被认为是LZRW算法的一个衍生算法,特别是LZRW1,目标是改进压缩速度。既然它是被用于操作系统,速度显得尤为重要,不能因为压缩算法的原因而使得磁盘操作成为瓶颈。
LZS
Lempel-Ziv-Stac算法于1994年由Stac Electronics发明,用于磁盘压缩软件。它是LZ77的一个修改版本,区分了输出的文字符号与offset-length数据对,此外还移除了分隔符。功能上来说,LZS与LZSS算法很相似。
LZX
LZX算法于1995年由Jonathan Forbes和Tomi Poutanen发明,用于Amiga计算机。LZX中X没有什么特殊的意义。Forbes于1996年把该算法出售给了微软,并且受雇于微软,那那儿该算法被继续优化并用于微软的cabinet(.CAB)格式。这个算法也被微软用于压缩Compressed HTML Help (CHM) 文件,Windows Imaging Format (WIM) 文件,和 Xbox Live Avatars。
LZO
LZO于1996年由Markus发明,该算法的目标是快速的压缩和解压缩。它允许调整压缩级别,并且在最高级别下仍仅需64KB额外的内存空间,同时解压缩仅需要输入和输出的空间。LZO功能上非常类似LZSS,不过是为了速度,而非压缩比做的优化。
LZMA
Lempel-Ziv Markov chain Algorithm算法于1998年首次发表,是随着7-Zip归档软件一起发布的。大多数情况下它比bzip2, DEFLATE以及其它算法表现都要好。LZMA使用一系列技术来完成输出。首先时一个LZ77的修改版本,它操作的是bitwise级别,而非传统上的bytewise级别,用于解析数据。LZ77算法解析后的输出经过数字编码。更多的技术可被使用,这依赖于具体的LZMA实现。相比其它LZ衍生算法,LZMA在压缩比方面提高明显,这要归功于操作bitewise,而非bytewise。
LZMA2
LZMA2是LZMA的一个增量改进版本,于2009年在7-Zip归档软件的一个更新版本里面首次引入。LZMA2改进了多线程处理功能,同时优化对不可压缩数据的处理,这也稍微提高了压缩效果。
Statistical Lempel-Ziv
Statistical Lempel-Ziv是于2001年由Sam Kwong博士和Yu Fan Ho博士提出的一个概念。基本的原则是数据的统计分析结果可以与LZ77衍生算法结合起来,进一步优化什么样的编码将存储在字典中。
Dictionary Algorithms
LZ78
LZ78于1978年由Lempel和Ziv发明,缩写正是来源于此。不再使用sliding window来生成字典,输入数据要么被预处理之后用来生成字典,或者字典在文件解析过程中逐渐形成。LZ78采用了后者。字典的大小通常被限定为几兆的大小,或者所有编码上限为几个比特,比如8个。这是出于减少对内存要求的考量。算法如何处理正是LZ78的各个衍生算法的区别所在。
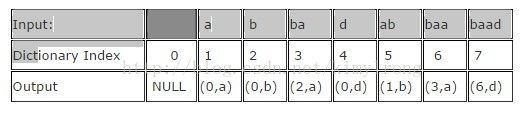
解析文件的时候,LZ78把新碰到的字符或者字符串加到字典中。针对每一个符号,形如(dictionary index, unknown symbol)的字典记录会对应地生成。如果符号已经存在于字典中,那么将从字典中搜索该符号的子字符串以及其后的其它符号。最长子串的位置即为字典索引(Index)。字典索引对应的数据被设置为最后一个未知子串。如果当前字符是未知的,那么字典索引设置为0,表示它是单字符对。这些数据对形成一个链表数据结构。
形如"abbadabbaabaad"的输入,将会产生"(0,a)(0,b)(2,a)(0,d)(1,b)(3,a)(6,d)"这样的输出。你能从下面的例子里面看到它是如何演化的:
LZW
LZW于1984年由Terry Welch发明,全称为Lempel-Ziv-Welch。它是LZ78大家族中被用得最多的算法,尽管被专利严重的阻碍了使用。LZW改进LZ78的方法与LZSS类似。它删除输出中冗余的数据,使得输出中不再包含指针。压缩之前它就在字典里面包含了每一个字符,也引入了一些技术改进压缩效果,比如把每一个语句的最后一个字符编码为下一个语句的第一个字符。LZW在图像转换格式中较为常见,早期也曾用于ZIP格式里面,也包括一些其他的专业应用。LZW非常的快,不过相较于一些新的算法,压缩效果就显得比较平庸。一些算法会更快,压缩效果也更好。
LZC
LZC,全称Lempel-Ziv Compress,是LZW算法的一个微小修改版本,用于UNIX压缩工具中。LZC与LZW两者的区别在于,LZC会监控输出的压缩比。当压缩比超过某一个临界值的时候,字典被丢弃并重构。
LZT
Lempel-Ziv Tischer是LZC的修改版,当字典满了,删除最不常用的的语句,用新的记录替换它。还有一些其它的小改进,不过现在LZC和LZT都不常用了。
LZMW
于1984年由Victor Miller和Mark Wegman发明,LZMW算法非常类似于LZT,它也采用了替换最不常用语句的策略。然而,不是连接字典中相似的语句,而是连接LZMW最后被编码的两个语句并且存储为一条记录。因此,字典的容量能够快速扩展并且LRUs被更频繁的丢弃掉。LZMW压缩效果比LZT更好,然而它也是另外一个这个时代很难看到其应用的算法。
LZAP
LZAP于1988年由James Storer发明,是LZMW算法的修改版本。AP代表"all prefixes",以其遍历时在字典里面存储单个语句,字典存储了语句的所有排列组合。例如,如果最后一个语句为"last",当前语句是"next",字典将存储"lastn","lastne","lastnex",和 "lastnext"。
LZWL
LZWL是2006年发明的一个LZW修改版本,处理音节而非字符。LZWL是专为有很多常用音节的数据集而设计的,比如XML。这种算法通常会搭配一个前置处理器,用来把输入数据分解为音节。
LZJ
Matti Jakobsson于1985年发表了LZJ算法,它是LZ78大家族中唯一一位衍生于LZW的算法。LZJ的工作方式是,在字典中存储每一个经过预处理输入中的不同字符串,并为它们编码。当字典满了,移除所有只出现一次的记录。
Non-dictionary Algorithms
PPM
通过抽样来预测数据是一项统计建模技术,使用输入中的一部分数据,来预测后续的符号将会是什么,通过这种算法来减少输出数据的entropy。该算法与字典算法不一样,PPM预测下一个符号将会是什么,而不是找出下一个符号来编码。PPM通常结合一个编码器来一起使用,如arithmetic编码或者适配的Huffman编码。PPM或者它的衍生算法被实现于许多归档格式中,包括7-Zip和RAR。
bzip2
bzip2是Burrows-Wheeler Transform算法的一个开源实现。它的操作原理很简单,不过却在压缩比和速度之间达到了一个平衡,表现良好,这让它在UNIX环境上很流行。首先,使用了一个Run-Length编码器,接下来,Burrows-Wheeler Transform算法加入进来,然后,使用move-to-front transform以达到产生大量相同符号的目标,为接下来的另一个Run-Length 编码器做准备。最后结果用Huffman编码,将一个消息头与其打包。
PAQ
PAQ于2002年由Matt Mahoney发明,是老版PPM的一个改进版。改进的方法是使用一项叫做context mixing的革命性技术。Context mixing是指智能地结合多个(PPM是单个模型)统计模型,来做出对下一个符号的更好预测,比其中的任何一个模型都要好。PAQ是最有前途的技术之一,它有很好的压缩比,开发也很活跃。自它出现后算起,有超过20个衍生算法被发明出来,其中一些在压缩比方面屡破记录。PAQ的最大缺点是速度,这源于使用了多个统计模型来获得更好的压缩比。然而随着硬件速度的不断提升,它或许会是未来的标准。PAQ在应用方面进步缓慢,一个叫PAQ8O的衍生算法可以在一个叫PeaZip的Windows程序里面找到,PAQ8O支持64-bit,速度也有较大提升。其它的PAQ格式仅仅用于命令行程序。
原文链接