1.概述
是一个可以并行执行任务的线程池。可以处理一个可递归划分的任务并获取结果(分而治之的思想,父任务等待子任务执行完成并组装结果)。因为是多线程去执行任务,可以充分利用多核,提高cpu的利用率。那么他如何做构建管理任务队列,多线程如何去处理任务,以及他的应用场景和性能瓶颈是什么?通过下面原理以及源码我们来进一步了解。
2.Fork/Join介绍
为分治算法的并行实现。
Result solve(Problem problem) {
if (problem is small)
directly solve problem
else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
}fork操作会启动一个新的任务。而join则是等待该任务阻塞完成。
如果问题较大。我们只需要将问题分解。fork出去,然后通过join等待结果,最后计算结果返回。这里有个问题就是大部分任务做的事情就是分解任务,然后等待子任务执行。
3.数据结构
1.会创建一个Worker线程池,每个线程用来处理队列中的任务。
2.所有的任务都是一个轻量级可执行的类(ForkJoinTask)。任务的方法就在工作线程运行的时候被调用处理。
工作窃取
对于CPU,重要的可能就是进程和线程的调度。但是对于上层,考虑的应该是如何充分利用线程资源。这就需要进行合理的任务(工作量)调度。
对于工作窃取调度策略实现如下:
- 每个线程都有自己的任务队列。
- 队列是一个双端队列,可以 前后取
- Fork的子任务只会被丢进所在线程的队列
- 工作线程通过LIFO获取任务
- 任务队列没有任务,会尝试随机窃取一个队列的任务执行。FIFO
- 工作线程调用join的时候,线程并不会阻塞,而是会去处理其他队列的任务。直到当前任务执行完成,返回结果
- 如果工作线程没有任务处理(自己队列无任务,并且没有窃取到任务),会让其让出资源。阻塞线程。等待后续激活。对于工作线程会有一个顶层线程去激活它。
工作线程获取自己队列任务和窃取别人任务的方式不同。这能减少竞争。
fork采用LIFO,这保证了队列头部任务都会是更大的任务,尾部是分解出来的子任务。窃取采用FIFO,窃取更大的任务有助于本次窃取的性价比很高。
如上所述,ForkJoinPool有一个WorkQueue数组。每个数组的元素是一个双端队列(Dqueue)。WorkQueue主要用来存储需要执行的任务。
需要注意的一点是,线程对应的WorkQueue在数组的下标都是奇数。那么大家会问,偶数索引对应的WorkQueue是什么。其实是用来存储直接向ForkJoinPool提交的(外部提交)任务。
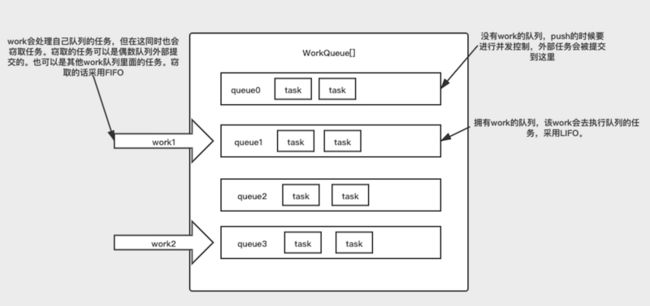
双端队列
需要考虑的是队列的并发控制。
双端队列采用数组的形式,维护了一个top和base的指针。push、pop、take操作都会通过移动指针去维护。对于push和pop都是同一个线程去执行。所以不会有并发问题。take窃取过程可能会有多线程操作。所以需要加锁。
那么核心问题就是解决队列元素不足时pop、push和take的冲突。
通过volatile的top和base指针。我们可以计算出队列元素数量。显然当数量大于1的时候。不冲突。
对于pop操作会先递减top:if(--top) >= base) …
对于take操作先递增base:if(++base < top) …
我们只需要比较这两个索引来检测是否会导致队列为空。对于pop,如果可能导致为空,加锁再判断。然后根据结果进行对应逻辑。如果是take。直接回退。不需要二次判断。
4.跟踪源码
通过上面介绍,我们了解线程如何获取任务。要进一步了解我们就需要深入到源代码中。首先我们用一个测试程序来进行分析。
public class ForkJoinCalculator {
private ForkJoinPool pool;
public ForkJoinCalculator() {
// 也可以使用公用的 ForkJoinPool:
// pool = ForkJoinPool.commonPool()
pool = new ForkJoinPool();
}
public long sumUp(long[] numbers) {
return pool.invoke(new SumTask(numbers, 0, numbers.length - 1));
}
private static class SumTask extends RecursiveTask {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
protected Long compute() {
// 当需要计算的数字小于6时,直接计算结果
if (to - from < 6) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
// 否则,把任务一分为二,递归计算
} else {
int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}
public static void main(String[] args) {
long[] numbers = LongStream.rangeClosed(1, 1000).toArray();
ForkJoinCalculator calculator = new ForkJoinCalculator();
System.out.println(calculator.sumUp(numbers)); // 打印结果500500
}
} SumTask的继承关系
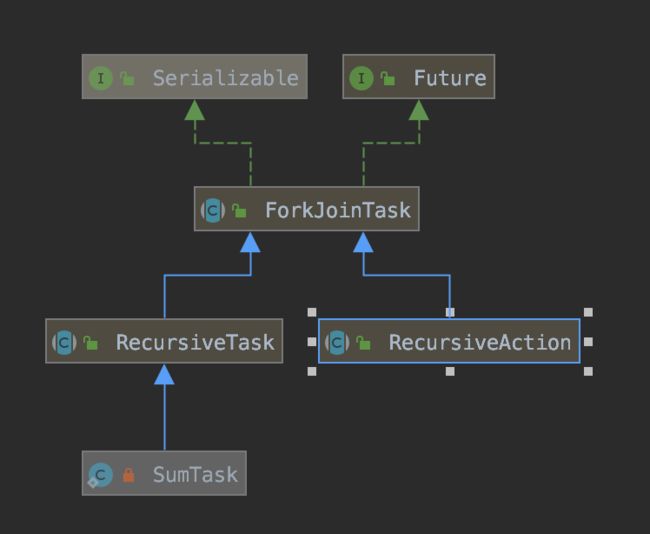
ForkJoinTask就是队列的任务。扩展了Future。有两个抽象的实现。
RecuriveTask是带返回值的。RecuriveAction是无返回值的。我们根据需求实现即可。
compute方法就是任务执行时回调用的方法。一般在这里我们会根据逻辑对任务进行分解和计算。
ForkJoinPool#invoke
public T invoke(ForkJoinTask task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task.join();
} 首先会调用externalPush方法,将任务丢进队列。
然后调用join方法。获取返回结果。
externalPush方法
final void externalPush(ForkJoinTask task) {
WorkQueue[] ws; WorkQueue q; int m;
int r = ThreadLocalRandom.getProbe();
int rs = runState;
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 &&
U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask[] a; int am, n, s;
if ((a = q.array) != null &&
(am = a.length - 1) > (n = (s = q.top) - q.base)) {
int j = ((am & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);
U.putOrderedInt(q, QTOP, s + 1);
U.putIntVolatile(q, QLOCK, 0);
if (n <= 1)
signalWork(ws, q);
return;
}
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
externalSubmit(task);
}这个方法主要逻辑就是将任务加入队列。如果队列数组为空或者获取到的队列当前不可用。会调用externalSubmit方法。否则获取到该队列。加锁。将任务丢到队列的头部(top),修改top。
externalSubmit则是externalPush的完整版。对于各种特殊情况。比如第一次初始化。
signalWork方法
final void signalWork(WorkQueue[] ws, WorkQueue q) {
long c; int sp, i; WorkQueue v; Thread p;
while ((c = ctl) < 0L) { // too few active
if ((sp = (int)c) == 0) { // no idle workers
if ((c & ADD_WORKER) != 0L) // too few workers
tryAddWorker(c);
break;
}
if (ws == null) // unstarted/terminated
break;
if (ws.length <= (i = sp & SMASK)) // terminated
break;
if ((v = ws[i]) == null) // terminating
break;
int vs = (sp + SS_SEQ) & ~INACTIVE; // next scanState
int d = sp - v.scanState; // screen CAS
long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred);
if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs; // activate v
if ((p = v.parker) != null)
U.unpark(p);
break;
}
if (q != null && q.base == q.top) // no more work
break;
}
}这个方法主要用来创建和唤醒worker
这里遇到了ctl我们说明一下,他将一个64位分为了四段。每段16位。由高到低分别为AC,TC,SS,ID
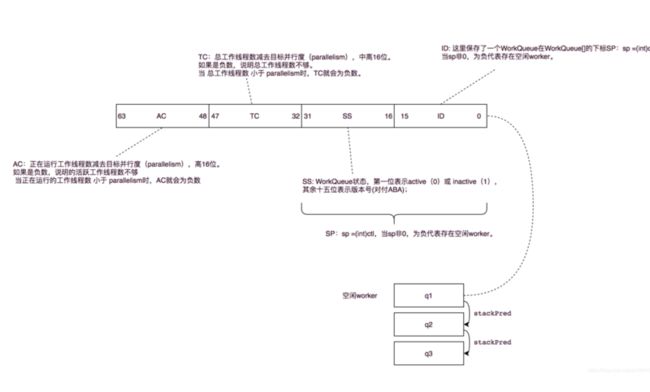
图片引用自https://blog.csdn.net/u010841...
AC为负说明,活跃的worker没有到达预期数量,需要激活或者创建。
1.没有空闲的worker并且worker太少的话会创建,具体是调用tryAddWorker方法。
2.如果有空闲worker,获取到空闲worker,解除worker阻塞。并且更新sp。
通过SS我们可以进行判断是否存在空闲的worker。ID用来定位该worker对应队列的下标。
创建和注册worker逻辑相对容易就不多做解释。
线程执行任务
final void runWorker(WorkQueue w) {
w.growArray(); // allocate queue
int seed = w.hint; // initially holds randomization hint
int r = (seed == 0) ? 1 : seed; // avoid 0 for xorShift
for (ForkJoinTask t;;) {
if ((t = scan(w, r)) != null)
w.runTask(t);
else if (!awaitWork(w, r))
break;
r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // xorshift
}
}首先调用scan去窃取一个任务。
Scan逻辑如下:
- 随机获取一个队列,尝试窃取
- 如果窃取到任务,并且当前任务所在队列为active,出队返回,如果是inactive,尝试激活它
- 如果没有继续循环遍历队列。
- 直到遍历完所有的队列。还没有窃取到任务的话,修改状态为未激活,并将当前workerqueue挂在栈顶。等待去激活它。
什么时候回激活工作线程:
- 提交任务的时候会有singlework去尝试激活。
- 窃取任务的时候,发现该队列有任务,但是该队列未激活。则去激活它。
runTask方法
窃取到任务之后会调用该方法。通过调用doExec去执行。
final void runTask(ForkJoinTask task) {
if (task != null) {
scanState &= ~SCANNING; // mark as busy
(currentSteal = task).doExec();
U.putOrderedObject(this, QCURRENTSTEAL, null); // release for GC
execLocalTasks();
ForkJoinWorkerThread thread = owner;
if (++nsteals < 0) // collect on overflow
transferStealCount(pool);
scanState |= SCANNING;
if (thread != null)
thread.afterTopLevelExec();
}
}执行完窃取任务之后,会执行本地队列的任务。彻底执行完成后会继续上述操作。
如果没有窃取到任务,并且本地队列也没有待执行的任务。那么会调用awaitWork。
awaitWork方法
这个方法其实我没有细看,但是这个方法的逻辑对于性能影响比较大。
按道理来讲如果,没有任务。还让该线程自旋的话,对cpu会有一些浪费,甚至在任务不足的时候窃取会导致任务的竞争。
所以我们需要根据线程活跃已经数量状况。选择性的终止worker或者阻塞worker。
如果当前线程数达到数量,并且活跃超过两个,并且当前在栈顶,释放当前线程。
fork方法
public final ForkJoinTask fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
} 如果当前线程为工作线程,直接将任务丢进队列
否则丢到公共线程池的队列。
join方法
主要是调用dojoin方法。
如果当前线程为工作线程,并且该任务在当前线程top位置,则执行该任务。如果执行完成。则返回。
如果未完成,调用awaitJoin方法。通过任务的状态status判断任务的执行状态。
如果非工作线程。那么阻塞该线程等待任务完成。
awaitJoin方法
这个方法逻辑相对复杂一点。
final int awaitJoin(WorkQueue w, ForkJoinTask task, long deadline) {
int s = 0;
if (task != null && w != null) {
ForkJoinTask prevJoin = w.currentJoin;
U.putOrderedObject(w, QCURRENTJOIN, task);
CountedCompleter cc = (task instanceof CountedCompleter) ?
(CountedCompleter)task : null;
for (;;) {
if ((s = task.status) < 0)
break;
if (cc != null)
helpComplete(w, cc, 0);
else if (w.base == w.top || w.tryRemoveAndExec(task))
helpStealer(w, task);
if ((s = task.status) < 0)
break;
long ms, ns;
if (deadline == 0L)
ms = 0L;
else if ((ns = deadline - System.nanoTime()) <= 0L)
break;
else if ((ms = TimeUnit.NANOSECONDS.toMillis(ns)) <= 0L)
ms = 1L;
if (tryCompensate(w)) {
task.internalWait(ms);
U.getAndAddLong(this, CTL, AC_UNIT);
}
}
U.putOrderedObject(w, QCURRENTJOIN, prevJoin);
}
return s;
}记录当前任务为currentJoin。
1.如果为CountedCompleter,则调用helpComplete。
2.否则通过w.tryRemoveAndExec。这个方法的作用:如果当前任务在当前队列。执行并移除它。
3.如果当前队列任务为空或者调用join的任务没有在当前队列。调用helpStealer方法。
4.另一种策略为阻塞当前线程,让新的线程去执行该任务
helpStealer方法
1.找到偷窃当前任务的队列。其中v就是找到的队列。
if ((v = ws[i = (h + k) & m]) != null) {
if (v.currentSteal == subtask) {
j.hint = i;
break;
}
checkSum += v.base;
}2.如果当偷窃当前任务的队列存在任务,那么循环从窃取队列base获取任务帮助其执行。
执行过程中,如果join的任务执行完,会返回。否则一直处理。如果当前队列有新任务产生,也会直接返回
if (v.base == b) {
if (t == null) // stale
break descent;
if (U.compareAndSwapObject(a, i, t, null)) {
v.base = b + 1;
ForkJoinTask ps = w.currentSteal;
int top = w.top;
do {
U.putOrderedObject(w, QCURRENTSTEAL, t);
t.doExec(); // clear local tasks too
} while (task.status >= 0 &&
w.top != top &&
(t = w.pop()) != null);
U.putOrderedObject(w, QCURRENTSTEAL, ps);
if (w.base != w.top)
return; // can't further help
}
}3.如果窃取队列没有任务要执行。那么他会根据窃取队列的currentJoin重复执行上述逻辑。注意如果在执行的过程中发现两个队列的currentSteal和currentJoin不是目标任务,会重新寻找目标任务的队列。
这里其实有个核心的思想,就是针对目标任务。只要和目标任务有关就会帮助执行,否则跳出来重新寻找和目标任务有关的队列。直到目标任务执行完成。
5.ForkJoinPool和ThreadPoolExecutor
这两个都是juc里面的线程池。但是实现原理有很大的区别FJ使用工作窃取算法。通过多个队列可以减少并发。而TP则是单个队列。
通过上面代码。我们知道FJ使用递归的思想,可以在任务执行的过程中将任务分解。而使用TP的时候,如果分解出来大量的任务,会导致更多的队列竞争。
FJ对于大量的任务,可以充分利用资源,减少竞争,并且通过窃取算法。实现任务的负载均衡。可以说FJ完全是通过工作窃取来驱动任务完成的。
但是对于较少的任务。多队列以及线程频繁的窃取会导致性能的急剧下降。
还有就是对于阻塞时间比较久的任务。我们可能更适合使用TP,毕竟阻塞会占用线程资源。我们需要更多的线程去处理任务。并且阻塞会降低队列的竞争。
参考文章
http://gee.cs.oswego.edu/dl/p...
https://blog.csdn.net/u010841...