UIPath进阶教程-3-Project Organization
3.1 Understanding the process
FOR or BOR? Deciding between an automation for front office robots (FOR) or back office robots (BOR) is the first important decision that impacts how developers will build the code. The general running framework (robot triggering, interaction, exception handling) will differ. Switching to the other type of robots later may be cumbersome.
For time critical, live, humanly triggered processes (e.g. in a call center) a Robot working side by side with a human (so FOR) might be the only possible answer.
But not all processes that need human input are supposed to run with FOR. Even if a purely judgmental decision (not rule-based) during the process could not be avoided, evaluate if a change of flow is possible - like splitting the bigger process in two smaller sub-processes, when the output of the first sub-process becomes the input for the second one. Human intervention (validation/modifying the output of the first sub-process) takes places in between, yet both sub-processes could be triggered automatically and run unattended, as BORs.
A typical case would be a process that requires a manual step somewhere during the process (e.g. checking the unstructured comments section of a ticket and - based on that - assign the ticket to certain categories).
Generally speaking, going with BOR will ensure a more efficient usage of the Robot load and a higher ROI, a better management and tracking of robotic capacities.
But these calculations should take into consideration various aspects (a FOR could run usually only in the normal working hours, it may keep the machine and user busy until the execution is finished etc.). Input types, transaction volumes, time restrictions, the number of Robots available etc. will play a role in this decision.
This decision is not entirely the developer’s responsibility, but he/she is the most knowledgeable person to evaluate (from the early process assessment stages), what’s possible from the UiPath technical point of view.
3.2 Documenting
Process documentation will guide developer's work, will help in tracking the requests and application maintenance. Of course, there might be lots of other technical documents, but two are critical for a smooth implementation: one for setting a common ground with the business (solution design) another one detailing the RPA developer work (design instructions).
Solution Design Document (SDD) - its main purpose is to describe how the process will be automated using UiPath. This document is intended to convey to the Business and IT departments sufficient details regarding the automated process for them to understand and ultimately approve the proposed solution. Critically, it should not go into low-level details of how the UiPath processes will be developed, as this is likely to cloud the client’s ability to sign off the design with confidence.
Besides describing the automated solution, the SDD should include details of any other deliverables that are required, such as input files, database tables, web services, network folders etc. Other derivatives such as security requirements, scheduling, alerting, management information, and exception handling procedures should also be mentioned.
Process Design Instruction (PDI) - is intended to be a blueprint from which a process can be developed. The low-level information excluded from the SDD for the sake of clarity should be included in the PDI. A PDI needs to be created for all UiPath processes that are to be created and should describe in detail the UiPath process, together with all the elements (components, work queues, credentials, environment variables etc.) that support it.
The logic for working with each type of case should also be included, together with instructions on how to handle different types of exceptions.
3.3 Project Structure
Breaking the process in smaller workflows is paramount to good project design. Dedicated workflows allow independent testing of components while encouraging team collaboration by developing working on separate files
Starting from a generic (and process agnostic) framework will ensure you deal in a consistent and structured way with any process. A framework will help you start with the high-level view, then you go deeper into the specific details of each process.
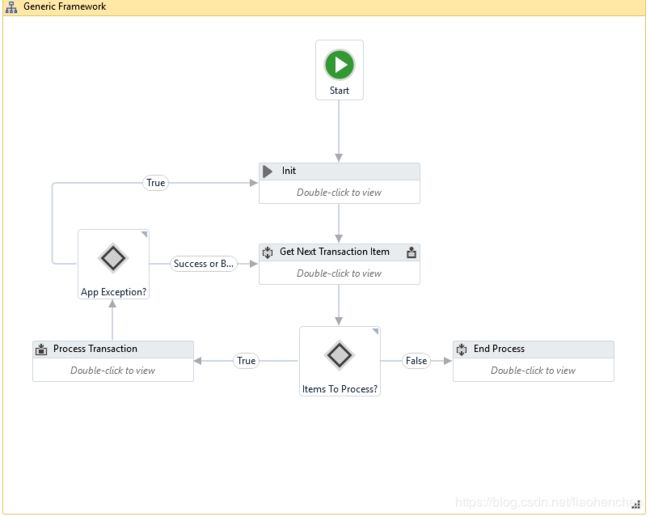
Robotic Enterprise Framework Template proposes a flexible high level overview of a repetitive process and includes a good set of practices described in this guide and can easily be used as a solid starting point for RPA development with UiPath. The template is built on a State Machine structure.
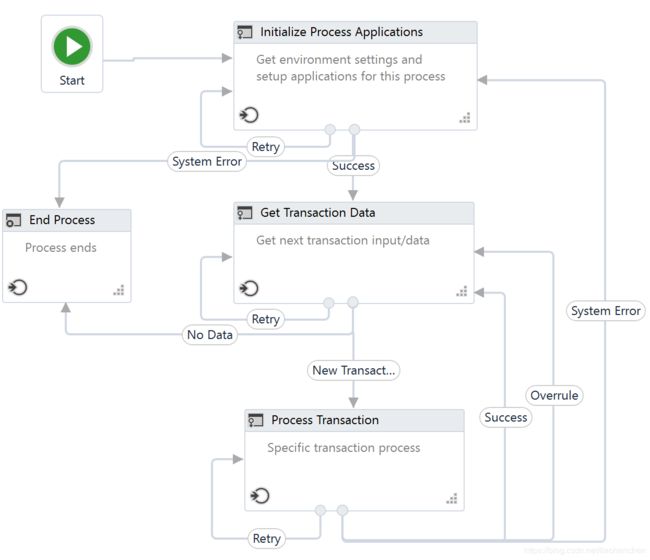
How it works:
The Robot loads settings from the config file and Orchestrator assets, keeping them in a dictionary to be shared across workflows
The Robot logs in to all applications, before each login fetching the credentials
It retries a few times if any errors are encountered, then succeeds or aborts
The Robot checks the input queue or other input sources to start a new transaction
If no (more) input data is available, configure the workflow to either wait and retry or end the process
the UI interactions to process the transaction data are executed
If the transactions are processed successfully, the transaction status is updated and the Robot continues with the next transaction
If any validation errors are encountered, the transaction status is updated and the Robot moves to the next transaction
If any exceptions are encountered, the Robot either retries to process the transaction a few times (if configured), or it marks the item as a failure and restarts
At the end, an email is sent with the status of the process, if configured
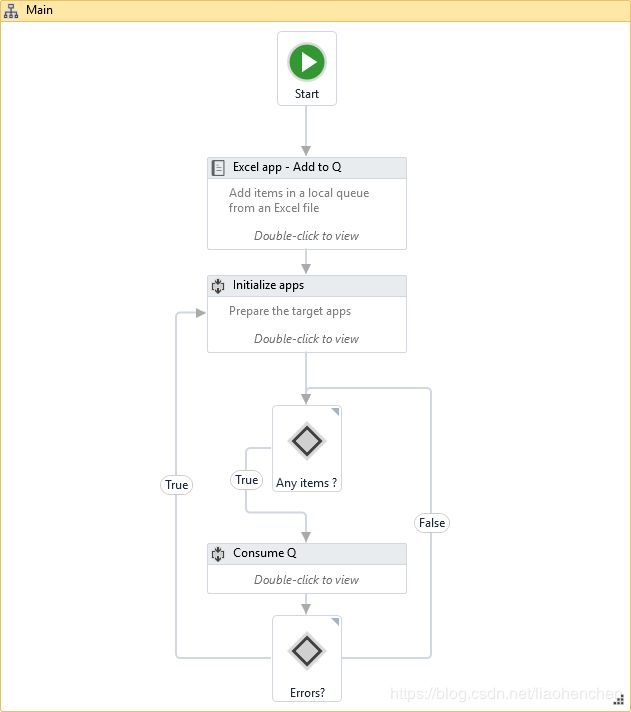
For transaction-based processes (e.g. processing all the invoices from an Excel file) which are not executed through Orchestrator, local queues can be built (using .NET enqueue/ dequeue methods).
Then the flow of the high-level process (exception handling, retrial, recovery) could be easily replicated - easier than by having the entire process grouped under a For Each Row loop.

Going further - to the process specific details, choose wisely the layout type - flowcharts and sequences. Normally the logic of the process stays in flowcharts while the navigation and data processing is in sequences.
By developing complex logic within a sequence, you will end up with a labyrinth of containers and decisional blocks, very difficult to follow and update.
On the contrary, UI interactions in a flowchart will make it more difficult to build and maintain.
Project related files (e.g. email templates) could be organized in local folders.
Note: If placed inside the project folder, during the deployment process, they will be replicated on all the Robot machines.
These folders could be also stored on a shared drive - so all the Robots will connect to the same unique source. This way, the process related files could be checked and maintained by the business users entirely, without support from the RPA team. However, the decision (shared or local folders) is complex and should take into consideration various aspects related to the process and environment: size of the files, frequency of changes, concurrency for editing the same file, security policies etc.
3.4 Source Control
In order to easily manage workflows, we recommend using a Version Control System. UiPath Studio is directly integrated with (TFS & SVN). A tutorial explaining the connection steps and functionalities can be accessed here.
3.5 Context Settings
To avoid hard coding external settings (like file paths, URLs) in the workflows, we recommend keeping them in a config file (.xlsx or .xml or .json) or in Orchestrator assets if they change often.
Generally speaking, the final solution should be extensible - allow variation and changes in input data without developer intervention. For example - lists with customers that are allowed for a certain type of transaction, emails of people to receive notifications etc. - should be stored in external files (like Excel) where business people or other departments can alter directly (add/remove/update).
For any repetitive process, all workflow invocations from the main loop should be marked with the Isolated option to defend against potential Robot crashes (e.g. Out of memory).
3.6 Credentials
No credentials should be stored in the workflow directly, but rather they should be loaded from safer places like local Windows Credential Store or Orchestrator assets. You can use them in workflows via the GetCredential activities.
Integration with some 3rd party password management solutions (e.g CyberArk) will be made possible in the next release of UiPath (2017.1)
3.7 Code Review
A local design authority should be agreed that will govern design control and development best practices. Peer review is essential at regular stages of the development phase to ensure development quality.
At the end of each component and process development task, unit or configuration testing should be performed by the developer (independently or view paired programming approach).
3.8 Automation Maintainability - How to Quality Check Automation
Modularity
Separation of concerns with dedicated workflows allows fine granular development and testing
Extract and share reusable components/workflows between projects
Maintainability
Good structure and development standards
Readability
Standardized process structure encouraging clear development practices
Meaningful names for workflow files, activities, arguments and variables
Flexibility
Keep environment settings in external configuration files/Orchestrator making it easy to run automation in both testing and production environments
Reliability
Exception handling and error reporting
Real-time execution progress update
Extensible
Ready for new use cases to be incorporated
3.9 Testing
The recommended UiPath architecture includes Dev and Test environments that will allow you to test your projects outside the live production systems.
If no test systems are available, or test cases with dummy data are not provided - it’s good to implement in projects a test mode parameter (Boolean) that will be checked before interacting with live applications. This could be received as an asset (or argument) input. When it is set to True - during debug and integration testing, it will follow the test route – not execute the case fully i.e. it will not send notifications, will skip the OK/Save button or press the Cancel/Close button instead, etc. When set to False, the normal Production mode route will be followed.
This will allow you to make modifications and test them in processes that work directly in live systems.
3.10 Error Handling
Two types of exceptions may happen when running an automated process: somewhat predictable or totally unexpected. Based on this distinction there are two ways of addressing exceptions, either by explicit actions executed automatically within the workflow, or by escalating the issue to human operators
Exception propagation can be controlled by placing susceptible code inside Try/Catch blocks where situations can be appropriately handled. At the highest level, the main process diagram must define broad corrective measures to address all generic exceptions and to ensure system integrity.
Contextual handlers offer more flexibility for Robots to adapt to various situations and they should be used for implementing alternative techniques, cleanup or customization of user/log messages. Take advantage of the vertical propagation mechanism of exceptions to avoid duplicate handlers in catch sections by moving the handler up some levels where it may cover all exceptions in a single place.
Enough details should be provided in the exception message for a human to understand it and take the necessary actions. Exception messages and sources are essential. The source property of the exception object will indicate the name of the activity that failed (within an invoked workflow). Again, naming is vital - a poor naming will give no clear indication about the component that crashed.

3.11 Keep it clean
In the process flow, make sure you close the target applications (browsers, apps) after the Robots interact with them. If left open, they will use the machine resources and may interfere with the other steps of automation.
Before publishing the project, take a final look through the workflows and do some clean-up:
remove unreferenced variables, delete temporary Write Line outputs, delete disabled code, make sure the naming is meaningful and unique, remove unnecessary containers (Right-click > Remove sequence).
The project name is also important – this is how the process will be seen on Orchestrator, so it should be in line with your internal naming rules. By default, the project ID is the initial project name, but you can modify it from the project.json file.
Additionally, the description of the project is also important, which is also visible in Orchestrator, and might help you differentiate between processes, especially in multi-user environments.