Hive快速入门系列(2) | Hive的安装部署及基本操作(超简单!)
经过上篇的简单介绍,相信大家已经了解什么是Hive,那么这篇文章讲述的是怎样安装部署Hive。
本系列所用到的安装包博主已经上传到百度云盘中,如有需要的可以自取。下面为链接:
链接:https://pan.baidu.com/s/10ezDJTuZl-qU2sq0hDCinw
提取码:pw12
目录
- 1. Hive安装及配置
- 1.1 解压apache-hive-1.2.1-bin.tar.gz到/opt/module/目录下面
- 1.2 修改apache-hive-1.2.1-bin.tar.gz的名称为hive
- 1.3 修改/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
- 1.4 配置hive-env.sh文件
- 2. Hadoop集群配置
- 2.1 必须启动hdfs和yarn
- 2.2 在HDFS上创建/tmp和/user/hive/warehouse两个目录并修改他们的同组权限可写
- 3. Hive基本操作
- 4. 将本地文件导入Hive案例
- 4.1 数据准备
- 4.2 Hive实际操作
- 5. 遇到的问题
在此仅展示一台机器的安装, Hive的功能基于MapReduce和HDFS,所以在保证Hive能正常运行的前提是MapReduce和HDFS能正常使用!
1. Hive安装及配置
1.1 解压apache-hive-1.2.1-bin.tar.gz到/opt/module/目录下面
[bigdata@hadoop001 software]$ tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/
1.2 修改apache-hive-1.2.1-bin.tar.gz的名称为hive
[bigdata@hadoop001 module]$ mv apache-hive-1.2.1-bin/ hive
1.3 修改/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
[bigdata@hadoop001 conf]$ hive-env.sh.template hive-env.sh
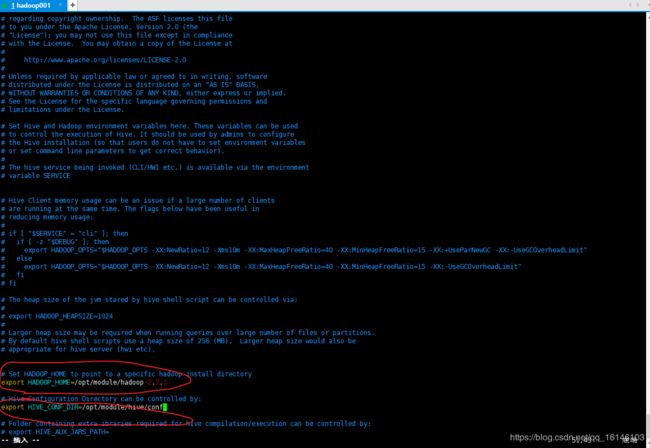
1.4 配置hive-env.sh文件
# 配置HADOOP_HOME路径
export HADOOP_HOME=/opt/module/hadoop-2.7.2
# 配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/opt/module/hive/conf
2. Hadoop集群配置
2.1 必须启动hdfs和yarn
[bigdata@hadoop001 hadoop-2.7.2]$ sbin/start-dfs.sh
[bigdata@hadoop001 hadoop-2.7.2]$ sbin/start-yarn.sh

2.2 在HDFS上创建/tmp和/user/hive/warehouse两个目录并修改他们的同组权限可写
[bigdata@hadoop001 hadoop-2.7.2]$ bin/hadoop fs -mkdir /tmp
[bigdata@hadoop001 hadoop-2.7.2]$ bin/hadoop fs -mkdir -p /user/hive/warehouse
[bigdata@hadoop001 hadoop-2.7.2]$ bin/hadoop fs -chmod g+w /tmp
[bigdata@hadoop001 hadoop-2.7.2]$ bin/hadoop fs -chmod g+w /user/hive/warehouse
// 在这时可能会出现tmp无法操作的情况,这时输入下列命令行即可解决
[bigdata@hadoop001 hadoop-2.7.2]$ hdfs dfs -chmod -R 755 /tmp
3. Hive基本操作
- 1. 启动hive
[bigdata@hadoop001 hive]$ bin/hive
![]()
- 2. 查看数据库
hive> show databases;
![]()
- 3. 打开默认数据库
hive> use default;

- 4. 显示default数据库中的表
hive> show tables;
![]()
- 5. 创建一张表
hive> create table student(id int, name string);
![]()
- 6. 显示数据库中有几张表
hive> show tables;
- 7. 查看表的结构
hive> desc student;

- 8. 向表中插入数据
hive> insert into student values(1000,"ss");
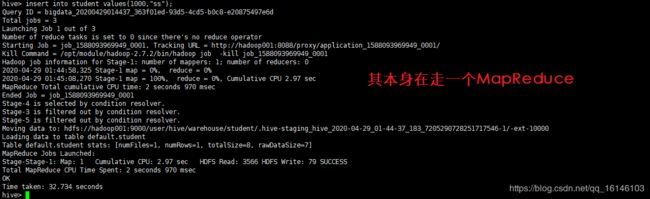
- 9. 查询表中数据
hive> select * from student;
![]()
- 10. 删除已创建的student表
hive> drop table student;
- 11. 退出hive
hive> quit;
说 明 : ( 查 看 h i v e 在 h d f s 中 的 结 构 ) \color{#FF0000}{说明:(查看hive在hdfs中的结构)} 说明:(查看hive在hdfs中的结构)
数据库:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
表:在hdfs中表现所属db目录下一个文件夹,文件夹中存放该表中的具体数据
4. 将本地文件导入Hive案例
4.1 数据准备
在/opt/module/datas这个目录下准备数据
- 1. 在/opt/module/目录下创建datas
[bigdata@hadoop001 module]$ mkdir datas
- 2. 在/opt/module/datas/目录下创建student.txt文件并添加数据
[bigdata@hadoop001 module]$ vim student.txt

4.2 Hive实际操作
- 1. 进入查看hive,删除原有的表
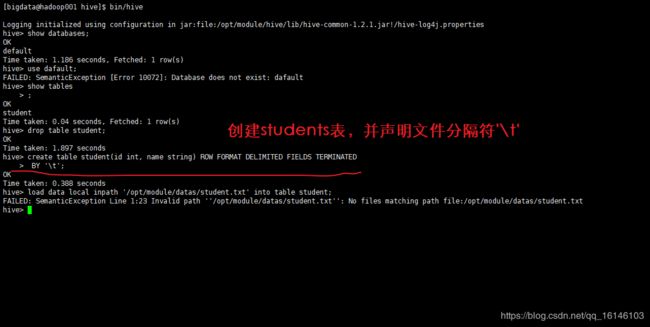
- 2. 加载/opt/module/datas/student.txt 文件到student数据库表中。

5. 遇到的问题
再打开一个客户端窗口启动hive,会产生java.sql.SQLException异常。
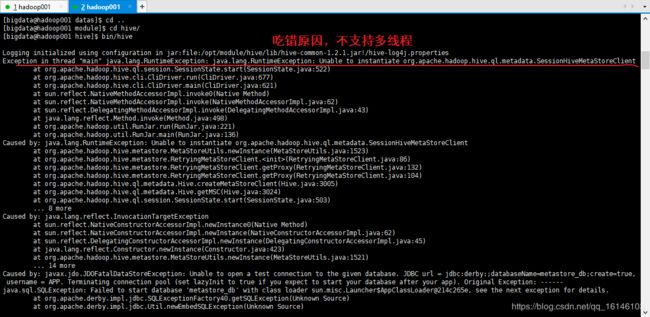
原因: M e t a s t o r e 默 认 存 储 在 自 带 的 d e r b y 数 据 库 中 , 推 荐 使 用 M y S Q L 存 储 M e t a s t o r e ; \color{#FF0000}{Metastore默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore;} Metastore默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore;
本次的分享就到这里了,

看 完 就 赞 , 养 成 习 惯 ! ! ! \color{#FF0000}{看完就赞,养成习惯!!!} 看完就赞,养成习惯!!!^ _ ^ ❤️ ❤️ ❤️
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!