Oracle性能优化
在物理层面上提高Oracle性能
从内存中获取数据要快于从磁盘中获取。
对于内存来说,2个重要因素会影响性能,1,可用内存大小2,如何管理、分配和使用这些内存。
Oracle的内存主要包括2部分,SGA和PGA。二者既可以在Oracle启动时进行加载,也可以在数据库使用时进行设置。
修改SGA
SGA是指System Global Area,即系统全局区。系统全局区是共享的内存结构。其存储的信息是数据库的公用信息,例如,数据库的控制信息。无论多少个用户连接到当前数据库,都会共享SGA提供的内存。因此,SGA也被称为共享全局区。SGA主要由以下部分构成:共享池、缓冲区、大型池、java池和日志缓冲区。
查看当前数据库的SGA状态
show parameter sga;
sga_max_size是为SGA分配的最大内存。默认情况下,sga_max_size的值为164M,而sga_target_size为0
查看SGA的具体分配情况
select * from v$sgastat;
共享池
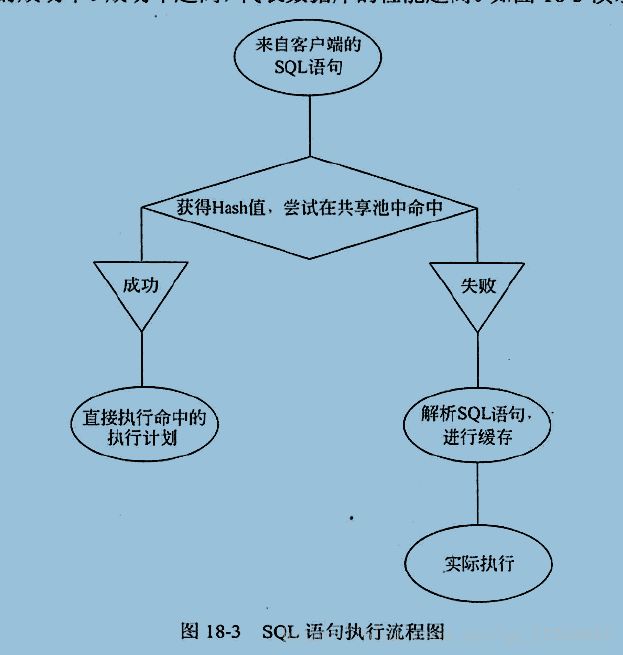
共享池是SGA中对性能影响最明显的部分。SQL语句的执行过程如下:
1、进行语法分析,验证SQL语句是否合法。
2.语义分析。主要判断对象是否合法。
3.执行其他较为复杂的步骤,如检查用户权限、语句优化等
共享池是将预处理过的SQL语句(也就是执行计划)进行缓存。缓存的标识是根据SQL语句所形成的Hash值。(一条sql语句,其Hash值绝对唯一)。当服务器接收到一条sql语句时,按照Hash算法获得hash值,然后根据hash值在共享池中查找是否已经有预处理过的sql语句,如果有则直接进行数据库操作,否则将执行语法分析。因此,对于共享池来说,存在着命中率的概念,也就是直接从共享池中获得执行计划的成功率。成功率越高,代表数据库的性能越高。
查看当前数据库的命中率
select namespace,gets,gethits,gethitratio,pins,pinhits,pinhitratio from v$librarycache;

需要特别关注的是sql area,其gethitratio即为sql语句解析时,直接获得解释计划的命中率;另外,pinhitratio是执行命中率,为了获得当前数据库在sql执行时的命中率,可以将所有namespace中命中次数之和除以总的执行次数。
select sum(pinhitratio)/sum(pinhits) fro v$librarycache;
对于共享池来说,如果命中率低于95%,如其中的SQL area get hitrate,就应当尝试增加共享池的大小来获得更高的性能。
修改SGA
因为Oracle 10g可以自行管理SGA各部分内存,因此,修改SGA内存大小,可以通过修改参数sga_max_size与sga_target来实现。
alter system set sga_max_size=1000m scop=spfile;
alter system set sga_target=1000m scop=spfile;
alter system命令用于修改系统属性;scop=spfile则将该参数反映到数据库启动文件中。一旦数据库重启,该参数将立即生效。
并非SGA所分配的内存越大越好。首先,一台数据库服务器的内存有限,而服务器的内存还要分配给其他资源;另外,SGA分配内存过大,维护该空间的开销也会相应增大。
修改PGA
PGA是指Process Global Area,即进程全局区。每位客户端用户连接到Oracle服务器,均会由服务器分配一定内存来保持连接,并将在该内存中实现用户私有操作。所有用户连接的内存集合便形成了Oracle数据库的PGA。
Oracle 10g提供了PGA内存的自动管理。参数pga_aggregate_target可以指定PGA内存的最大值。当参数pga_aggregate_target大于0时,Oracle将自动管理pga内存,并且各进程的所占PGA之和,不大于pga_aggregate_target所指定的值。
show parameter pga;
select * from v$pgastat;
Oracle默认的24M大小的PGA显然不能满足要求,修改PGA大小如下:
alter System set pga_aggregate_target=200M scope=both;
scope=both用于同事修改当前环境与启动文件spfile
异常情况(数据库无法启动)
Oracle 10g启动时,加载的启动参数文件主要有2种:spfiledsid.ora和initsid.ora。其中sid为实例名,二者的加载顺序为:首先尝试获取spfilesid.ora,如果获取失败,则使用initsid.ora文件启动。Oracle启动参数不当引起的启动失败,证明spfilesid.ora文件中的参数配置出错,而该文件是一个二进制文件,不能手动修改。
此时,利用指定启动参数文件initsid.ora的方式重启。除非在Oracle中修改了系统参数,并将系统参数保存至该文件,否则,该文件将一直保持初始设置。该文件的路径一般位于$(oracle)/database下。不同Oracle版本。可能会有差异。可以搜索获得
指定参数文件启动数据库的sql命令
startup pfile=d:/oracle/database/inittst.ora;
启动后数据库的系统参数已经恢复到Oracle的默认配置。
索引的使用
索引就像一本字典的目录一样。
索引的创建与使用
create index 索引名称 on 表名(列名);
没有索引的查询:
select * from test_objects t where t.object_name='stud'
花费时间为146单位
创建索引
create index idx_object on test_objects(object_name);
执行查询
select * from test_objects t where t.object_name='stud'
花费时间2个单位
索引的开销
并非所有数据表都适合建立索引。这是因为索引的创建需要较大的开销,为一个表创建索引只是开销的一部分,当表中的数据发生改变时,需要维护索引,针对数据的增删改,所进行的具体操作也不相同。
索引提高查询效率,不仅仅在于数据库会自动按照顺序进行搜寻,另一方面是索引的按块维护策略。索引类似于字典的目录,不仅仅按照字母顺序排列,还进行分页处理。
当插入数据时,维护表索引的步骤也大体相同。一般插入数据将导致较大的索引维护开销,当然,开销的大小收插入数据的排序决定的。如果新纪录的索引列值处于末尾。那开销不大。
删除数据时,并不会将对应索引条目删除,而是添加了一个‘删除’标识,标识该索引不能用。
修改数据时,维护索引相当于进行了一次删除和插入操作。
综述:索引虽然提高查询效率非常强大,但是以创建和维护索引的开销为代价。
索引的使用场景
1.数据量较小的表
执行全表搜索的时间已经可以忽略,使用索引并不能提高查询速度,反而要为维护索引付出代价。
2。有着频繁数据变更的表不宜使用索引
优化SQL语句
sql语句的命中率
由于sql语句忽略大小写,所以同样的sql语句,因为大小写不同,产生的hash值不同,所以命中率就低。
使用传参方式的sql语句可以提高命中率
select * from tmp_user_objects where object_name=?
exists与in
exists用于判断存在性,in则判断匹配性
二者的执行计划完全一致。表明,利用in查询,已经被Oracle自动优化为exists查询
一般情况下exists快于in,所以推荐exists
not exists 快于 not in,推荐not exists
where条件的合理利用
分组查询时,先where过滤再分组优于先分组再having过滤
利用with子句重用查询
当重用一些已经获得的结果集时使用with
不使用with
select * fron (select employee_id,avg(salary) avg_salary from salary group by employee_id) t where t.avg_salary>(select avg(avg_salary) from (select employee_id,avg(salary) avg_salary from salary group by employee_id));
使用with
with employee_avg_salary as (select employee_id,avg(salary) avg_salary from salary group by employee_id)
select * from employee_avg_salary t where t.avg_salary>(select avg(avg_salary) from employee_avg_salary)