什么是Redis缓存穿透?redis面试题及答案乐分享(附面试题大全)
一、缓存雪崩
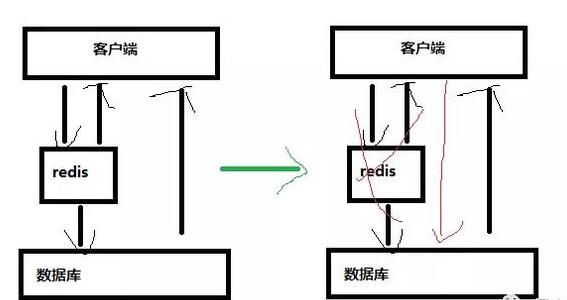
为什么使用缓存?
1.提高性能:缓存查询速度比数据库查询速度快(内存vs硬盘)。
2.提高并发能力:缓存分担了部分请求,支持更高的并发。
redis存储的数据和内存占用是有限的,因此我们才需要对数据设置过期时间,并采用惰性删除+定期删除策略清除过期键,释放内存。如果数据缓存的过期时间是相同的,redis正好把这部分数据清掉或者redis服务器出现故障,缓存失效请求全部走数据库,这种现象就是缓存雪崩。缓存雪崩可能导致数据库被搞垮,导致整个系统直接崩溃。
如何解决缓存雪崩?
- 数据预热,通过缓存reload机制,提前更新缓存,在发生大并发访问之前,手动触发加载缓存不同的key,设置过期时间加上随机数值,让key过期时间分散开来。
- redis挂掉情况:使用redis高可用架构(主从架构+sentinel或redis cluster),保证个别节点或者机器宕掉依然能继续提供服务。
- 当缓存失效后,依赖隔离组件为后端限流降级(hystrix),采用加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
二、缓存穿透
当查询一个一定不存在的数据,由于缓存不命中,去查询数据库也无法查询出结果,因此不会写入到缓存中,这会导致每个查询都去请求数据库,造成缓存穿透。
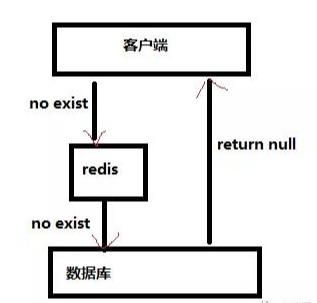
解决方案:
- 布隆过滤对所有的可能查询的参数以hash形式存储,在控制器层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。举例:将真实正确Id在添加完成之后便加入到过滤器当中,每次再进行查询时,先确认要查询的Id是否在过滤器中,如果不在,则说明Id为非法Id。
- 缓存空对象当从数据库查询不到值,就把参数和控制缓存起来,设置一个简短的过期时间(因为缓存是需要内存的,如果有过多空值key,占用内存多),在该时间段如果有携带此参数再次请求,就可以直接返回。可能导致该段时间缓存层和数据库数据不一致,对于需要保持一致性的业务有影响。
三、缓存并发
高并发场景下同时查询大量查询过期的key值,最后查询数据库将缓存结果写到缓存、造成数据库压力过大。
解决方案:互斥锁 对锁不了解的可以查看初始锁的世界文章。
四、缓存和数据库双写一致性
数据库与缓存读写模式策略
写完数据库后是否需要马上更新缓存还是直接删除缓存?
- 如果数据库更新值和更新到缓存是一样的无需经过任何的计算,可以立即更新缓存,如果写多读少的场景也不适合这种方案。
- 如果数据保存缓存需要复杂的关联计算,无需立即更新缓存,等查询的时候在进行更新。
一般的策略是当更新数据时,先删除缓存,再更新数据库,而不是更新缓存,等要查询的时候才把最新的数据更新到缓存。
常见数据库与缓存双写情况导致数据不一致的场景和解决方案。
- 场景一:用户原来有50块,购买了一条毛巾20,要更新余额为30,数据库更新为30,删除缓存但是失败了。意味着数据库是30,而缓存还是50,这导致数据库和缓存不一致解决方案:先删除缓存,如果删除成功再去更新数据库,就算数据库更新失败了,再次读取数据库缓存到redis数据还是一致的。
- 场景二:高并发的情况下,如果A删除完缓存,A在去更新数据库,在更新的过程后,B来查询数据,发现缓存没有,就从数据库获取并缓存,后面A更新成功,就会出现缓存和数据库不一致。解决方案:使用队列,购票场景,更新车票库存,先把票id丢到队列里去,当更新完后在从队列里去除,在更新票数的过程中,如果有查票库存请求先去缓存里看下有没有数据,如果没有,可以先去队列里看是否有用户在做更新,如果有也把查票库存请求发送到队列里去,然后同步等待缓存更新完成。如果发现队列里有一个查询请求了,那么就不要放新的查询操作进去了,用一个while(true)循环去查询缓存,循环个200MS左右,如果缓存里还没有则直接取数据库的旧数据。高并发解决注意点: 1.读请求时间堵塞 读请求进行非常轻度的异步化,每个读请求必须在超时间内返回,该方案最大的风险在于可能数据更新很频繁,导致队列中挤压了大量的更新操作在里面,然后读请求会发生大量的超时,导致大量的请求直接走数据库,像遇到这种情况,一般要做好足够的压力测试,如果压力过大,需要根据实际情况添加机器。 2.请求并发量过高 压力测试要做好,模拟各种真实场景,并发量在最高的时候QPS多少,如何扛不住可以多加机器,同时读写服务器比例要设置好。 3. 多服务实例部署的请求路由 服务部署了多个实例,要保证执行数据更新操作和执行缓存更新操作的请求都通过nginx服务器路由到相同的服务器实例上。 4.热点数据的路由问题,导致请求 读热点数据的请求非常高,全部发给同一机器的同一队列里,造成该服务器压力过大,因为只能更新数据才会清空缓存,才会导致读写并发。
保证数据一致的方案:
1. databus
Databus是一个低延迟、可靠的、支持事务的、保持一致性的数据变更抓取系统。由LinkedIn于2013年开源。Databus通过挖掘数据库日志的方式,将数据库变更实时、可靠的从数据库拉取出来,业务可以通过定制化client实时获取变更并进行其他业务逻辑。搭建过程简述:下载ojdbc6.jar然后复制放在sandbox-repo/com/oracle/ojdbc6/11.2.0.2.0/,然后重命名ojdbc6-11.2.0.2.0.jar,构建需要gradle支持。
2. 阿里的canal监听binglog进行更新。
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
如何使用redis做一个消息队列?

redis知识查缺补漏---面试题
- 一个字符串类型的值能存储最大容量是521M。
- 为什么redis需要把所有数据放在内存中?为了达到最大的读写速度将数据都读到内存中,并通过异步方式将数据写入磁盘。所以redis具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘I/O速度会严重影响redis的性能。在内存越来越便宜的今天,redis将会越来越受欢迎。如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
- Redis支持的数据类型?String字符串:格式: set key valuestring类型是二进制安全的。redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。常规key-value缓存应用;常规计数:微博数,粉丝数等。string类型是Redis最基本的数据类型,一个键最大能存储512MB。 Hash(哈希)格式: hmset name key1 value1 key2 value2Redis hash 是一个键值(key=>value)对集合。Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。 List(列表)Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)格式: lpush name value在 key 对应 list 的头部添加字符串元素格式: rpush name value在 key 对应 list 的尾部添加字符串元素格式: lrem count value在key对应 list 中删除 count 个和 value 相同的元素格式: llen name 返回 key 对应 list 的长度使用场景:微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。 Set(集合)格式: sadd name valueRedis的Set是string类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。比如:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。 zset(sorted set:有序集合)格式: zadd name score valueRedis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。场景:在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息,适合使用 Redis 中的 SortedSet 结构进行存储。
- Redis集群方案什么情况下会导致整个集群不可用?有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用。
- Redis支持的Java客户端都有哪些?官方推荐用哪个?Redisson、Jedis、lettuce等等,官方推荐使用Redisson。
- redis和redisson有什么关系?Redisson是一个高级的分布式协调Redis客服端,能帮助用户在分布式环境中轻松实现一些Java的对象 (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publish / Subscribe, HyperLogLog)。
- Jedis与Redisson对比有什么优缺点?Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持;Redisson实现了分布式和可扩展的Java数据结构,和Jedis相比,功能较为简单,不支持字符串操作,不支持排序、事务、管道、分区等Redis特性。Redisson的宗旨是促进使用者对Redis的关注分离,从而让开发者能够将精力更集中地放在处理业务逻辑上。
- redis有哪些架构?各自的特点?单机版

特点:简单
缺点: 内存容量有限 处理能力有限 无法高可用
主从复制
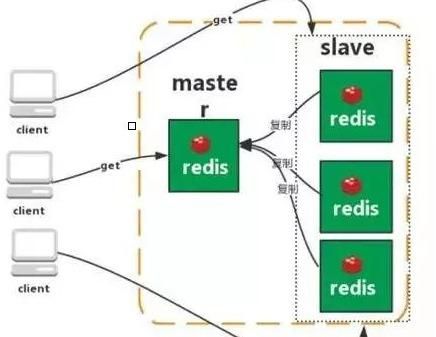
Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。 只要主从服务器之间的网络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步 给从服务器,从而一直保证主从服务器的数据相同。
特点:master/slave角色 master/slave数据相同 降低master读压力转交salve分担。
缺点:无法保证高可用 没有解决 master写的压力
哨兵模式:

Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。其中三个特性:
监控(Monitoring):Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification):当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover):当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:保证高可用 监控各个节点 自动故障迁移
缺点:主从模式切换需要时间可能会丢数据 没有解决master写的压力。
集群(proxy)型

Twemproxy是一个 Twitter 开源的一个 redis 和 memcache 快速/轻量级代理服务器;Twemproxy是一个快速的单线程代理程序,支持 Memcached ASCII 协议和 redis 协议。
特点:多种hash算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur、Jenkins 支持失败节点自动删除 后端sharding分片逻辑对业务透明,业务方的读写方式和操作单个redis一致。
缺点:增加了新的proxy,需要维护其高可用 failover 逻辑需要自己实现,其本身不能支持故障的自动转移可扩展性差,进行扩缩容都需要手动干预。
集群直连型:
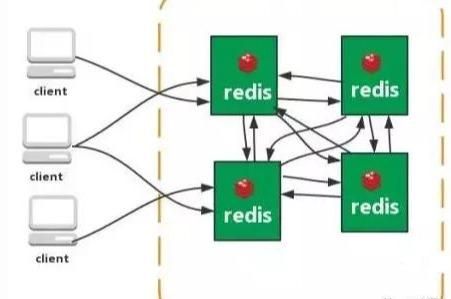
从redis 3.0之后版本支持redis-cluster集群,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
特点: 1.无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
2.数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布
3.可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
4.高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
5.实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master 的角色提升。
缺点:资源隔离性较差,容易出现相互影响的情况和数据通过异步复制,不保证数据的强一致性。
9.redis集群如何选择数据库?
redis集群目前无法做数据库选择,默认在0数据库。
10. redis集群之间如何复制的?最大节点个数是多少?
异步复制 16384个
11. redis 内存如何做优化?
能用散列表存储就优先选择,占用的内存小。如果要保持用户的基本信息,直接用散列保存,不要为每个属性单独设key。
12.redis回收使用的是什么算法?
LRU算法
13.redis回收进程如何工作的?
一个客户端运行了新的命令,添加了新的数据。Redis检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
一个新的命令被执行,等等。
所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
14.redis如何做大量数据插入?
redis2.6开始redis-cli支持pipe model模式,提供大量数据的插入。
15.redis为什么要分区?
分区可以让redis管理更大的内存,redis将可以使用所有机器的内存。如果没有分区,最多只能使用一台机器的内存。分区使redis的计算能力通过简单地增加计算机得到成倍提升,redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
16.redis分区方案有哪些?
客户端分区:在客户端已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。
代理分区:客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些redis实例,然后根据redis的响应结果返回客户端。redis和memcache的一种代理实现就是twemproxy。
查询路由(query routing):客户端随机地请求任意一个redis实例,然后由redis将请求转发给正确的redis节点。redis cluster实现了一个混合形式的查询路由,并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的节点。
17.redis分区有什么缺点?
涉及多个key的操作通常不会被支持。如不能直接使用交集指令对俩个集合求交集,因为集合存储的redis实例可能不同。
操作多个key不能使用redis事务。
分区使用的粒度是key,不能使用一个非常长的排序key存储一个数据集。(The partitioning granularity is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set.)
当使用分区的时候,数据处理会非常复杂。例如为了备份必须从不同的redis实例和主机同时收集rdb/apf文件。
分区时动态扩容或缩容可能非常复杂。redis集群在运行时增加或者删除redis节点,能做到最大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区则不支持这种特性,可以使用预分片技术来解决。
18.redis持久化数据和缓存如何做扩容?
如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。
如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
19.分布式redis是前期做还是后期规模上来再做?为什么?
Redis是如此的轻量(单实例只使用1M内存),为防止以后的扩容,最好就是一开始就启动较多实例。即便你只有一台服务器,一开始就让Redis以分布式的方式运行,使用分区,在同一台服务器上启动多个实例。
一开始就多设置几个Redis实例,例如32或者64个实例,对大多数用户来说这操作起来可能比较麻烦,但是从长久来看做这点牺牲是值得的。
当你的数据不断增长,需要更多的Redis服务器时,你需要做的就是仅仅将Redis实例从一台服务迁移到另外一台服务器而已(而不用考虑重新分区的问题)。一旦你添加了另一台服务器,你需要将你一半的Redis实例从第一台机器迁移到第二台机器。
20.Twemproxy是什么?
Twemproxy是Twitter维护的(缓存)代理系统,代理Memcached的ASCII协议和Redis协议。它是单线程程序,使用c语言编写,运行起来非常快。它是采用Apache 2.0 license的开源软件。Twemproxy支持自动分区,如果其代理的其中一个Redis节点不可用时,会自动将该节点排除(这将改变原来的keys-instances的映射关系,所以你应该仅在把Redis当缓存时使用Twemproxy)。Twemproxy本身不存在单点问题,因为你可以启动多个Twemproxy实例,然后让你的客户端去连接任意一个Twemproxy实例。Twemproxy是Redis客户端和服务器端的一个中间层,由它来处理分区功能应该不算复杂,并且应该算比较可靠的。
21.支持一致性哈希的客户端有哪些?
redis-rb predis
22.redis是单线程的,如何提高多核cpu的利用率?
可以在同一个服务器部署多个redis的实例,当成不同的服务器来使用。在某些时候,无论如何一个服务器是不够的,所以你想使用多个cpu,可以考虑分片(shard)。
23.一个redis实例最多能存放多少的keys?list、set、sorted set最多能存放多少元素?
一个redis至少能存2亿5千万的keys。任何list、set、sorted set都可以存放232个元素。redis的存储极限主要还是取决于系统的可用内存值。
24.redis常见性能问题和解决方案?
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次。
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内。
(4) 尽量避免在压力很大的主库上增加从库。
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3...
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
25.redis如何实现延迟任务?
我们知道zset本质就是set结构上加了排序功能,当添加或者修改元素,会按照score值进行排序。如果score代表是执行时间的时间戳,某个时间加入到zset集合中就会排序,然后写一个死循环不断取第一个key值,如果当前时间戳大于key的时间戳就取出来消费删除,这样就可以执行延迟任务的目的,而且不需要遍历整个zset,造成性能浪费。

本文主要介绍了redis一些比较经典的面试题,通过这些题目有助于大家更好的理解redis。如果觉得还不错的小伙伴请关注我,后面持续会推出好文。
如果小伙伴们还想要其他面试题和资料的话,欢迎关注公众号:



努力不一定有结果,但是不努力一定不会有结果。