inceptionv3之迁移学习与图之字幕
一.迁移学习
1.问题
深度学习越来越靠计算与数据驱动,顶会的模型动不动就是几百万标注数据集、异构集群分布式服务框架,像DenseNet、TASKONOMY这种规模真的是可望不可即,没有资源支持就只能在深度学习支路上偏跑。。。但是好在已经训练好的模型的参数,往往经过简单的调整和训练,就可以很好的迁移到其他不同的数据集上,同时也无需大量的算力支撑,便能在短时间内训练得出满意的效果。这便是迁移学习。今年cvpr最佳论文TASKONOMY就是迁移学习。
2.形式
迁移形式主要分为三种:
样本迁移:实际应用中,很难收集到大量的样本数据。而且收集的过程需要消耗大量的人力物力,所以一般情况下来说,往往是完成问题A的训练出的模型有更完善的数据,而问题B的数据量偏小。将任务A中部分适合任务B的数据抽取出来,与其它数据一起针对任务B进行训练。
特征迁移:通过使用之前在大数据集上经过训练的预训练模型,我们可以直接使用相应的结构和权重,将它们应用到我们正在面对的问题上。例如识别小轿车的神经网络中,用于表示车轮车窗的网络参数,可以直接迁移到卡车识别。
模型迁移:在具体操作的时候,将一个预先训练好的神经网络,用新数据集重新训练网络中的一小部分,通常是最后一层或者几层全连接层,卷积层一般不动。从而完成在新数据集上建立的算法任务,即完成了神经网络的迁移学习。我们可以保留训练好的Inception-v3模型中所有的参数,只替换最后一层全连接层。在最后一层全连接层之前的网络称之为瓶颈层(bottleneck)。我们可以理解成将前面固定不动的部分作为一个特征提取器,而后面训练的层作为分类器。类似特征迁移,整个模型的网络结构都被迁移。比如将Inception-V3卷积神经网络模型,迁移到其他图像识别任务。
3.优势
1.更少的标注数据;
2.更短的训练时间;
3.更快的收敛速度;
4.更精准的权重参数。
4.方法
TensorFlow实现Inception V3迁移学习(网上教程很多)

流程:
1.加载Inception-V3模型,读取其中的瓶颈层、输入层张量名称(Tensor)
2.复用卷积池化层,生成图像特征向量(瓶颈层)
3.定义神经网络的前向传播过程
4.定义双层全连接神经网络
5.训练全连接神经网络
如果已按文件夹分好类直接训练就行,没有的话可以用notebook将数据可视化分类。这里推荐一个商品分类数据集,可自己分类训练。
二.图与字幕
使用InceptionV3预训练网络和Beam Search为图像生成自动描述文字。作者写了篇博客,这里简单翻译下。
1.数据集
使用Flickr8k数据集(大小为1 GB)。MS-COCO和Flickr30K是可以使用的其他数据集。Flickr8K拥有6000张训练图像,1000张验证图像和1000张测试图像。每张图片都有5个字幕描述它。MS-COCO数据集与笔记本。
2.图像特征提取
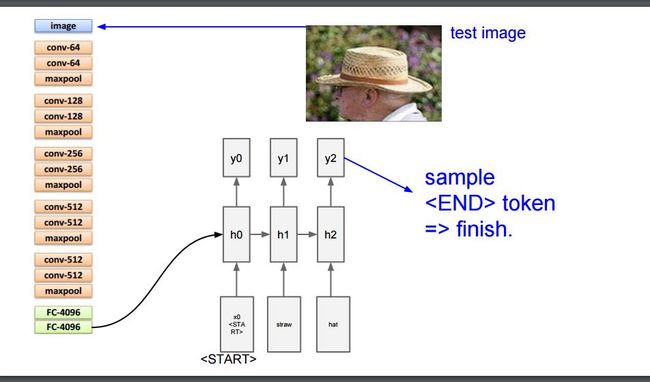
在图像字幕中,CNN用于从图像中提取特征,然后将图与字幕一起输入到RNN中。为了提取特征,使用在Imagenet上训练的模型。作者试用了VGG-16,Resnet-50和InceptionV3。Vgg16拥有近1.34亿个参数,其在Imagenet上的top-5个错误为7.3%。InceptionV3有2100万个参数,其在Imagenet上的top-5个错误是3.46%。Imagenet上的人分类top-5错误率是5.1%。作者用VGG-16作为提取功能的第一个模型。花了一个小时从6000个训练图像中提取特征。这很慢。想象一下,在拥有80,000个训练图像的MS-COCO数据集中提取特征所需的时间。
Resnet-50是作者尝试提取功能的第二个模型。但是没有长时间训练模型,因为InceptionV3具有比Resnet-50更好的精度和几乎相同数量的参数。
最后是因为InceptionV3的耗时。由于与VGG-16相比,它的参数非常少,因此InceptionV3 需要20分钟才能从6000张图像中提取特征。作者还在MS-COCO数据集上运行了这个数据集,其中包含80,000个训练样例,并且花费了2小时45分钟来提取这些功能。
3.训练和超参数
要创建模型,必须将字幕嵌入。作者想尝试使用Word2Vec来获得词汇量的预训练嵌入权重,但它并没有成功。所以,作者通过将嵌入大小设置为300来从中获取一些想法。下图是使用的模型图。

使用的优化程序是RMSprop,批处理大小设置为128。
作者使用VGG-16提取的特征训练模型大约50个周期,并且损失值为2.77。
在使用InceptionV3提取的特征训练模型约35个周期后,得到的损失值为2.8876。
作者将这个模型训练了另外15个周期,损失值不低于2.88。
作者尝试了降低学习速率,改变优化器,改变模型架构,嵌入大小,LSTM单元的数量以及几乎所有其他超参数。就卡住了。
一次偶然的灵感,作者将批量大小从128改为256,损失在第36个周期下降到2.76优于VGG-16(在第35个周期得到了2.8876,只从那里训练了模型)。
每当损失开始变平时,作者会将批量增加一倍,损失又开始减少。达到了2048的批量大小并试图转到4096但是出现了内存错误。
在训练50个周期后,作者得到的最终损失值为1.5987。
改变批量大小的原因是因为如果批量大小,则梯度是实际梯度的近似值。因此,找到一个好的解决方案需要更长的时间。如果将这个模型在128处作为批量大小训练另外100个周期,那么希望损失会减少。
此外,通过训练时间增加批量大小。首先批量大小为128,一个纪元花了大约1000秒。批量大小为2048,每个周期花了343秒。
因此,如果您遇到类似情况,请尝试增加批量大小。不要过多增加批量大小,因为模型将失去泛化能力。参考本文。
4.预测
作者使用了2种方法来预测字幕。
Argmax搜索是提取8256长预测向量中的最大值索引(argmax)并将其附加到结果的位置。直到我们达到或标题的最大长度为止。
def predict_captions(image):
start_word = [""]
while True:
par_caps = [word2idx[i] for i in start_word]
par_caps = sequence.pad_sequences([par_caps], maxlen=max_len, padding='post')
e = encoding_test[image[len(images):]]
preds = final_model.predict([np.array([e]), np.array(par_caps)])
word_pred = idx2word[np.argmax(preds[0])]
start_word.append(word_pred)
if word_pred == "" or len(start_word) > max_len:
break
return ' '.join(start_word[1:-1])
Beam Search是我们进行前k个预测的地方,在模型中再次提供它们,然后使用模型返回的概率对它们进行排序。因此,列表将始终包含前k个预测。最后,我们采用概率最高的那个并经历它直到我们遇到或达到最大字幕长度。
def beam_search_predictions(image, beam_index = 3):
start = [word2idx[""]]
# start_word[0][0] = index of the starting word
# start_word[0][1] = probability of the word predicted
start_word = [[start, 0.0]]
while len(start_word[0][0]) < max_len:
temp = []
for s in start_word:
par_caps = sequence.pad_sequences([s[0]], maxlen=max_len, padding='post')
e = encoding_test[image[len(images):]]
preds = final_model.predict([np.array([e]), np.array(par_caps)])
# Getting the top (n) predictions
word_preds = np.argsort(preds[0])[-beam_index:]
# creating a new list so as to put them via the model again
for w in word_preds:
next_cap, prob = s[0][:], s[1]
next_cap.append(w)
prob += preds[0][w]
temp.append([next_cap, prob])
start_word = temp
# Sorting according to the probabilities
start_word = sorted(start_word, reverse=False, key=lambda l: l[1])
# Getting the top words
start_word = start_word[-beam_index:]
start_word = start_word[-1][0]
intermediate_caption = [idx2word[i] for i in start_word]
final_caption = []
for i in intermediate_caption:
if i != '':
final_caption.append(i)
else:
break
final_caption = ' '.join(final_caption[1:])
return final_caption
最后,这里有一些作者得到的结果。其余的结果都在jupyter笔记本中,您可以通过在最后编写一些代码来生成自己的结果。

