
01、变量Name处理
1.1、处理内容
变量Name中包含的额信息较多,需要进行处理。
(1)提取Mr、Mrss、Mrs等反应身份的信息(都在第一个逗号和第一个点之间的位置)
(2)提取姓氏信息
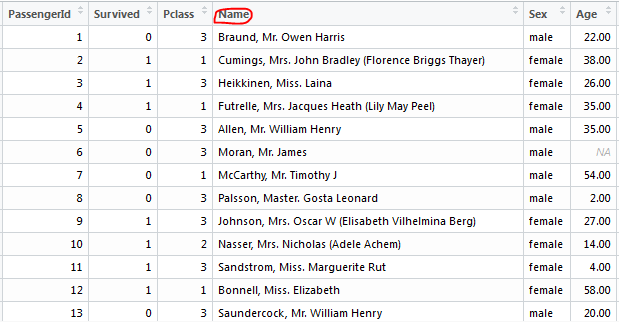
1.2、身份提取
使用gsub函数,根据正则表达式把目标内容提取出来,发现身份有点多
Capt Col Don Dona Dr Jonkheer Lady Major Master Miss Mlle Mme Mr Mrs Ms Rev Sir the Countess
所有做一下处理,把乱七八糟的身份都定义为Rare Title
最后根据Name变量得到的身份情况就是这样的了
| 性别 | Master | Miss | Mr | Mrs | Rare Title |
|---|---|---|---|---|---|
| female | 0 | 264 | 0 | 198 | 4 |
| male | 61 | 0 | 757 | 0 | 25 |
#-------------------------------------------------------------->2、变量Name处理
library(dplyr)
full <- bind_rows(train, test)
#---------------------------------------------------------->2.1、身份提取
full$Title <- gsub('(.*, )|(\\..*)', '', full$Name)
table(full$Sex, full$Title)
#------------------------------------------------------>2.2、乱七八糟的身份处理掉
rare_title <- c('Dona', 'Lady', 'the Countess','Capt', 'Col', 'Don',
'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer')
full$Title[full$Title == 'Mlle'] <- 'Miss'
full$Title[full$Title == 'Ms']<- 'Miss'
full$Title[full$Title == 'Mme']<- 'Mrs'
full$Title[full$Title %in% rare_title] <- 'Rare Title'
table(full$Sex, full$Title)
#------------------------------------------------------>2.3、姓氏提取
full$Surname <- sapply(full$Name,
function(x) strsplit(x, split = '[,.]')[[1]][1])
1.3、姓氏提取
(1)在原始数据集上再新增一列叫Surname的变量
(2)strsplit(x, split = '[,.]'):就是根据逗号点,把Name字段内容分割开
(3)目标对象就是每行的第一个内容

代码操作:
full$Surname <- sapply(full$Name, function(x) strsplit(x, split = '[,.]')[[1]][1])
1.4、小结
对于变量Name的操作,就是新建两列变量,分别为身份变量和姓氏变量
02、家庭信息处理
SibSp变量统计乘客是否有兄弟姐妹/配偶同船
Parch变量统计乘客是否有父母/子女同船
(1)创建一个新变量Fsize,统计船上乘客的家庭人员
(2)家庭成员和生存关系
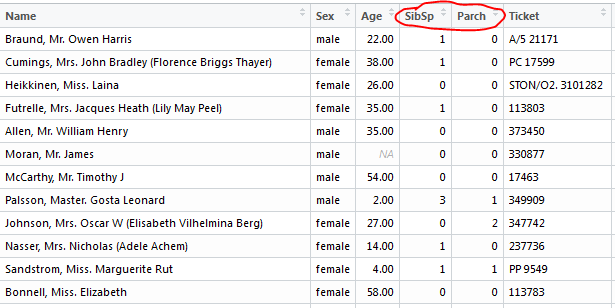
0表示存活;1表示死亡
所以数据统计表明,还是单身活得久
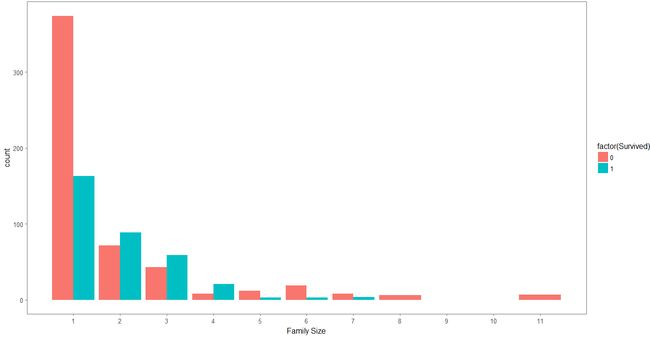
把家庭成员数量为1的设置为singleton
把家庭成员数量在2、3、4之间的设置为Small
把家庭成员数量大于4的设置为Large
中间很大一块蓝色就是单身汉的存活希望~~~
#--------------------------------------->3、家庭探究
full$Fsize <- full$SibSp + full$Parch + 1
full$Family <- paste(full$Surname, full$Fsize, sep='_')
#SibSp: Number of siblings/spouses aboard有多少兄弟姐妹/配偶同船
#Parch:Number of parents/children aboard有多少父母/子女同船
library(ggplot2)
library(ggthemes)
ggplot(full[1:891,], aes(x = Fsize, fill = factor(Survived))) +
geom_bar(stat='count', position='dodge') +
scale_x_continuous(breaks=c(1:11)) +
labs(x = 'Family Size') +
theme_few()
full$FsizeD[full$Fsize == 1] <- 'singleton'
full$FsizeD[full$Fsize < 5 & full$Fsize > 1] <- 'small'
full$FsizeD[full$Fsize > 4] <- 'large'
mosaicplot(table(full$FsizeD, full$Survived), main='Family Size by Survival', shade=TRUE)
接下来看看cabin变量和embarked变量的情况
03、船舱cabin变量
(1)缺失值问题
(2)信息提取:A、B、C等级船舱

3.1、缺失值
cabin变量一看就很多缺失值,但是VIM处理结果显示cabin变量没有缺失值。
经检验,cabin空格的地方时有数值的,不是NA
full$Cabin[1]
[1] ""
full$Age[6]
[1] NA

3.2、船舱等级信息提取
(1)使用函数strsplit(x, NULL)把C85这样的船舱信息分割成C、8、5三个部分
(2)创建一个新变量desk,表示船舱等级信息
full$Deck<-factor(sapply(full$Cabin, function(x) strsplit(x, NULL)[[1]][1]))
04、港口embarked变量
4.1、基础信息
(1)embarked变量信息基本完整,除62行和830行数值为“ ”
(2)所以把这两条信息去掉,探究港口和票价之间的关系
| embarked | C | Q | S |
|---|---|---|---|
| num | 270 | 123 | 914 |
三类港口,C和S登船人较多,C港口的一等舱票价很高,最高的达500美元以上。
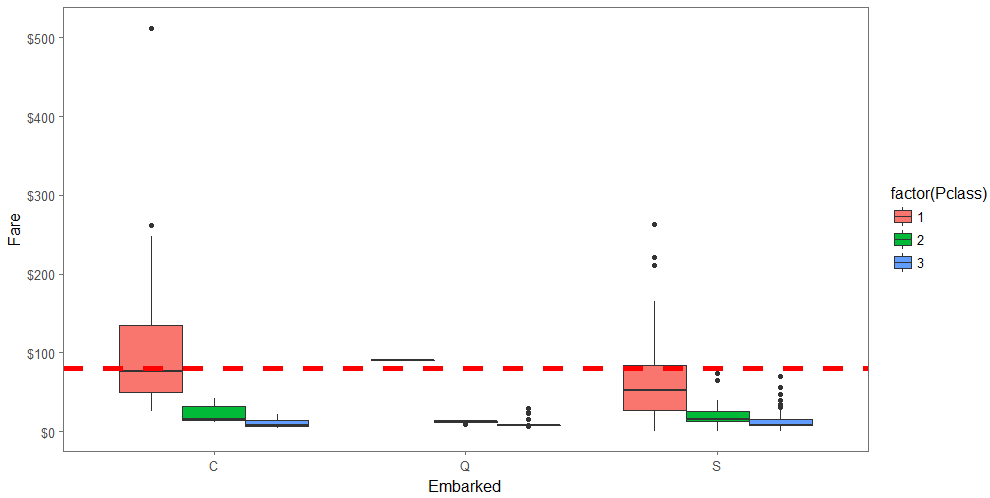
full[c(62, 830), 'Embarked'] #Port of embarkation
embark_fare <- full %>%filter(PassengerId != 62 & PassengerId != 830)
library(scales)
ggplot(embark_fare, aes(x = Embarked, y = Fare, fill = factor(Pclass))) +
geom_boxplot() +
geom_hline(aes(yintercept=80),
colour='red', linetype='dashed', lwd=2) +
scale_y_continuous(labels=dollar_format()) +
theme_few()
4.2、C港口票价分布
由于C港口票价比较高,所以单独看一下C港口各等级的票价分布
船舱等级、港口与票价
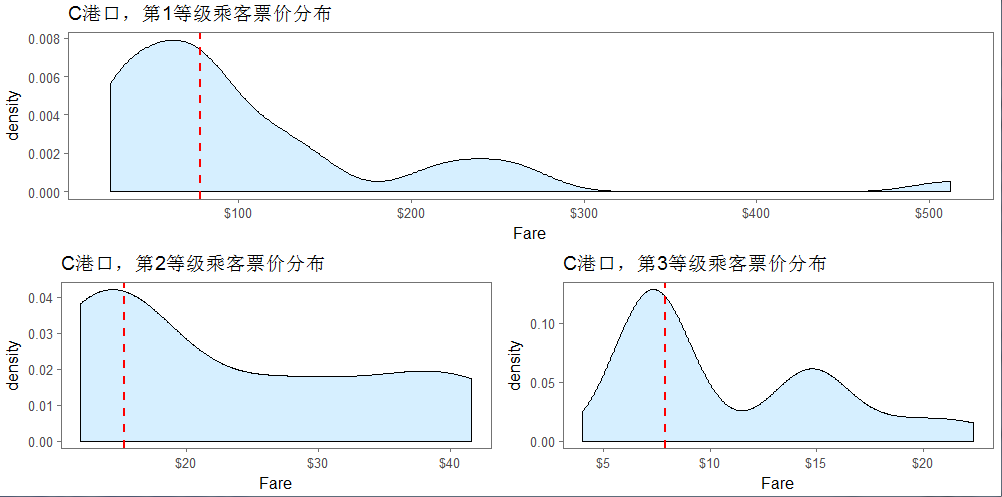
a<-ggplot(full[full$Pclass == '3' & full$Embarked == 'C', ], aes(x = Fare)) +
geom_density(fill = '#99d6ff', alpha=0.4) +
geom_vline(aes(xintercept=median(Fare, na.rm=T)),
colour='red', linetype='dashed', lwd=1) +
ggtitle("C港口,第3等级乘客票价分布")+
scale_x_continuous(labels=dollar_format()) +
theme_few()
b<-ggplot(full[full$Pclass == '2' & full$Embarked == 'C', ], aes(x = Fare)) +
geom_density(fill = '#99d6ff', alpha=0.4) +
geom_vline(aes(xintercept=median(Fare, na.rm=T)),
colour='red', linetype='dashed', lwd=1) +
ggtitle("C港口,第2等级乘客票价分布")+
scale_x_continuous(labels=dollar_format()) +theme_few()
c<-ggplot(full[full$Pclass == '1' & full$Embarked == 'C', ], aes(x = Fare)) +
geom_density(fill = '#99d6ff', alpha=0.4) +
geom_vline(aes(xintercept=median(Fare, na.rm=T)),
colour='red', linetype='dashed', lwd=1) +
ggtitle("C港口,第1等级乘客票价分布")+
scale_x_continuous(labels=dollar_format()) +theme_few()
grid.newpage() ##新建页面
pushViewport(viewport(layout = grid.layout(2,2))) ####将页面分成2*2矩阵
vplayout <- function(x,y){
viewport(layout.pos.row = x, layout.pos.col = y)
}
print(c, vp = vplayout(1,1:2)) ###将(1,1)和(1,2)的位置画图c
print(b, vp = vplayout(2,1)) ###将(2,1)的位置画图b
print(a, vp = vplayout(2,2)) ###将(2,2)的位置画图a